基于Scrapy的B站爬虫
基于Scrapy的B站爬虫
最近又被叫去做爬虫了,不得不拾起两年前搞的东西。
说起来那时也是突发奇想,想到做一个B站的爬虫,然后用的都是最基本的Python的各种库。
不过确实,实现起来还是有点麻烦的,单纯一个下载,就有很多麻烦事。
这回要快速实现一个爬虫,于是想到基于现成的框架来开发。
Scrapy是以前就常听说的一个爬虫框架,另一个是PySpider。
不过以前都没有好好学过框架。
这回学习了一波,顺便撸出来一个小Demo。
这个Demo功能不多,只能爬取B站的视频列表,不过主要在于学习、记录、交流,不在于真的要爬B站。。
然后代码都在GitHub了:
https://github.com/wangzb96/Scrapy-Based-Crawler-for-Bilibili
爬虫的定义
爬虫的定义有以下两点:
- 自动爬取网络资源 (html、json、...)
- 模拟浏览器行为
第一点是常规的定义,第二点是进阶版的定义,因为如果爬虫要持久稳定地爬取数据,那么就要模拟真人使用浏览器的行为,模拟得越像越好,越不容易被封。
爬虫的流程
- 页面分析
- 工具
- 谷歌浏览器
- 360极速浏览器
- 问题
- 哪些数据需要爬取?
- 这些数据存放在什么文件上?
- 这些文件的链接是什么?
- 链接的生成规则是什么?
- 存放在其他页面文件
- 通过某种简单的规则生成 (如递增的数字)
- 工具
- 获取链接
- 通过解析网页文件得到链接
- 通过模版生成不同的链接
- 下载资源
requestsasyncio
- 页面解析
jsonbs4.BeautifulSouppyquery.PyQueryre
- 数据存储
- 文件
- 数据库
Scrapy框架介绍
Scrapy是一个用于实现爬虫的Python框架,它将爬虫运行过程抽象成几个组件,如图:
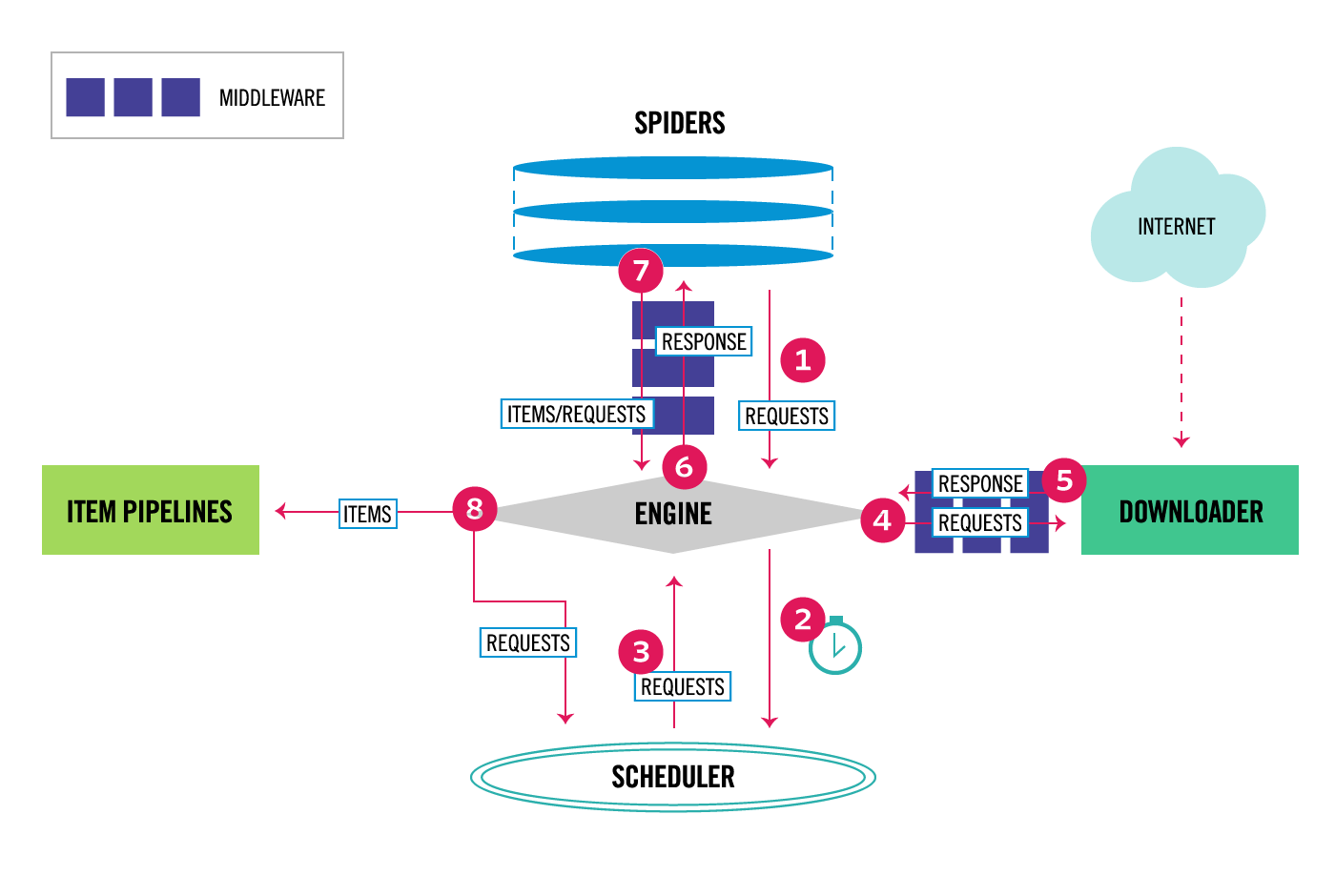
其中主要包括:
- Engine (不需要用户实现)
- 驱动组件运行
- Scheduler (不需要用户实现)
- 接收请求
- 调度请求
- 返回请求
- Downloader (不需要用户实现)
- 请求网络资源
- 返回响应
- Spider (需要用户实现)
- 返回初始请求
- 页面解析
- 返回Item对象
- 返回新请求
- Item Pipeline (需要用户实现)
- Item对象清洗
- Item对象验证
- Item对象保存
- Middleware (需要用户实现)
- Downloader Middleware
- Spider Middleware
- 在组件运行的一些子过程中执行额外操作
当应用Scrapy实现爬虫时,由于Scrapy已经实现了Engine、Scheduler、Downloader等组件,所以用户无需实现这些组件,用户主要要实现Spider,以及按需实现Item Pipeline、Middleware,另外还需要实现Item类。
基于Scrapy的B站爬虫实现
以下介绍一个B站美食区视频列表爬虫实现的案例。
开始一个Scrapy项目
首先在命令行或终端中输入:
scrapy startproject scrapy_bilibili
Scrapy会在当前目录下生成如下的目录:
- scrapy_bilibili
- scrapy_bilibili
- spiders
- __init__.py
- __init__.py
- items.py
- pipelines.py
- middlewares.py
- settings.py
- spiders
- scrapy.cfg
- scrapy_bilibili
其中斜体的是文件夹,我们把加粗的文件夹设置成项目的根目录。
B站美食区视频列表页面分析
B站美食区的链接地址是固定的:
https://www.bilibili.com/v/life/food/?#/all/default/0
进去后里面有个视频列表,我们使用360极速浏览器分析:
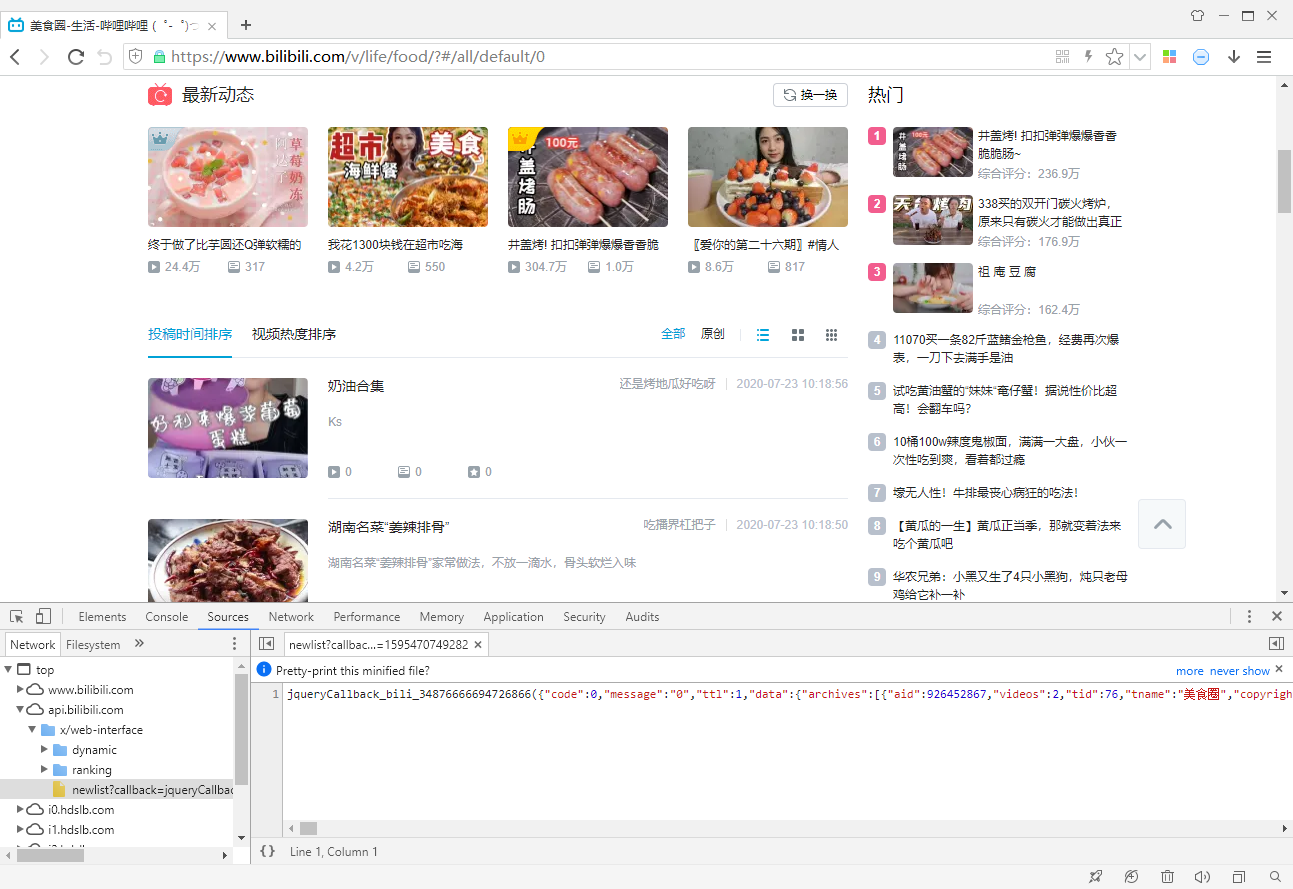
分析后,发现一个“newlist”链接:
https://api.bilibili.com/x/web-interface/newlist?rid=76&type=0&ps=100&pn=1
点开后,可以看到这个链接返回了一个json文件,里面记录了视频列表及其中每一个视频的信息,包括视频的标题、id、播放量等:
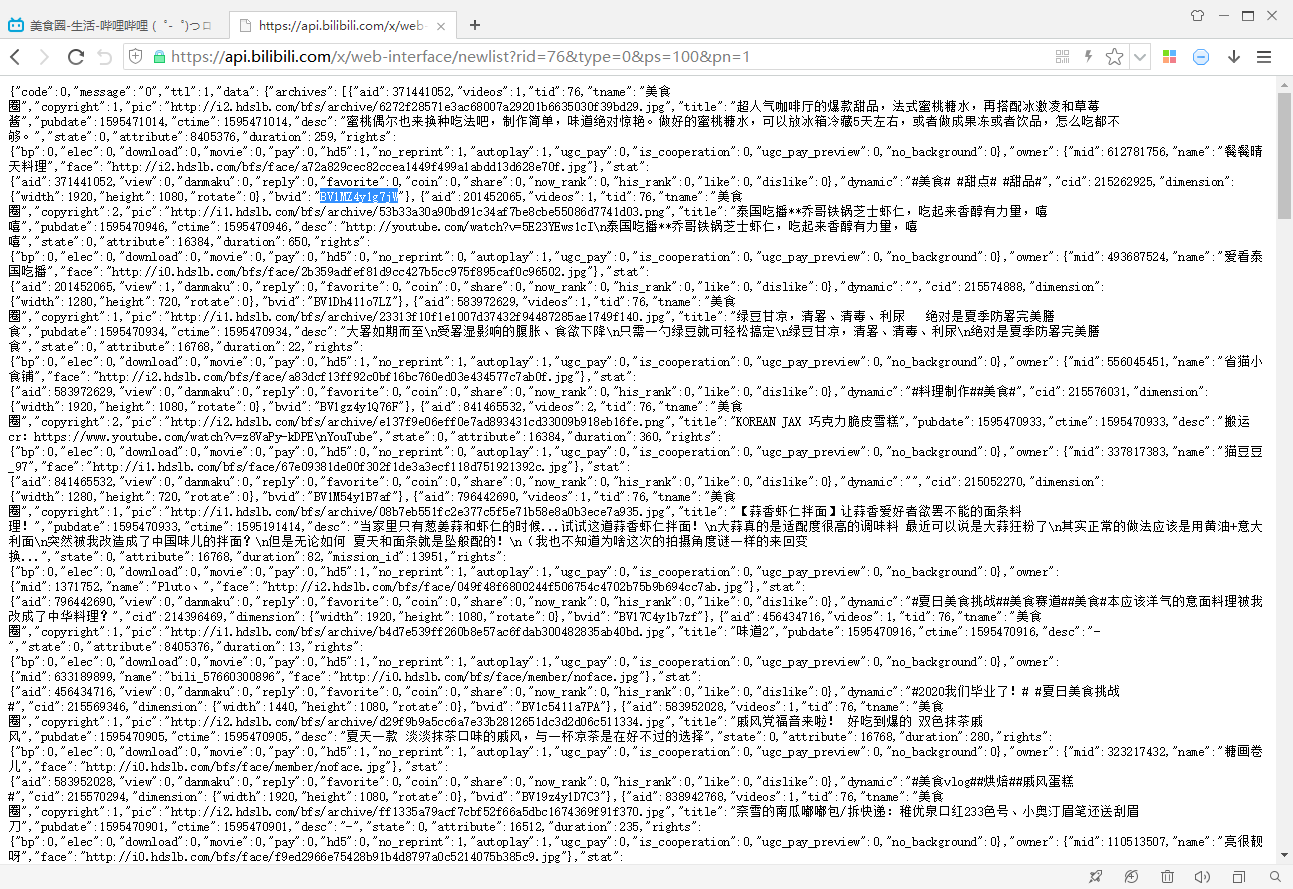
分析一下这个链接的参数,rid是美食区的id,type是按日期排序还是按热度排序,pn表示第几页,ps表示每页视频数量。
然后观察B站的视频页面:
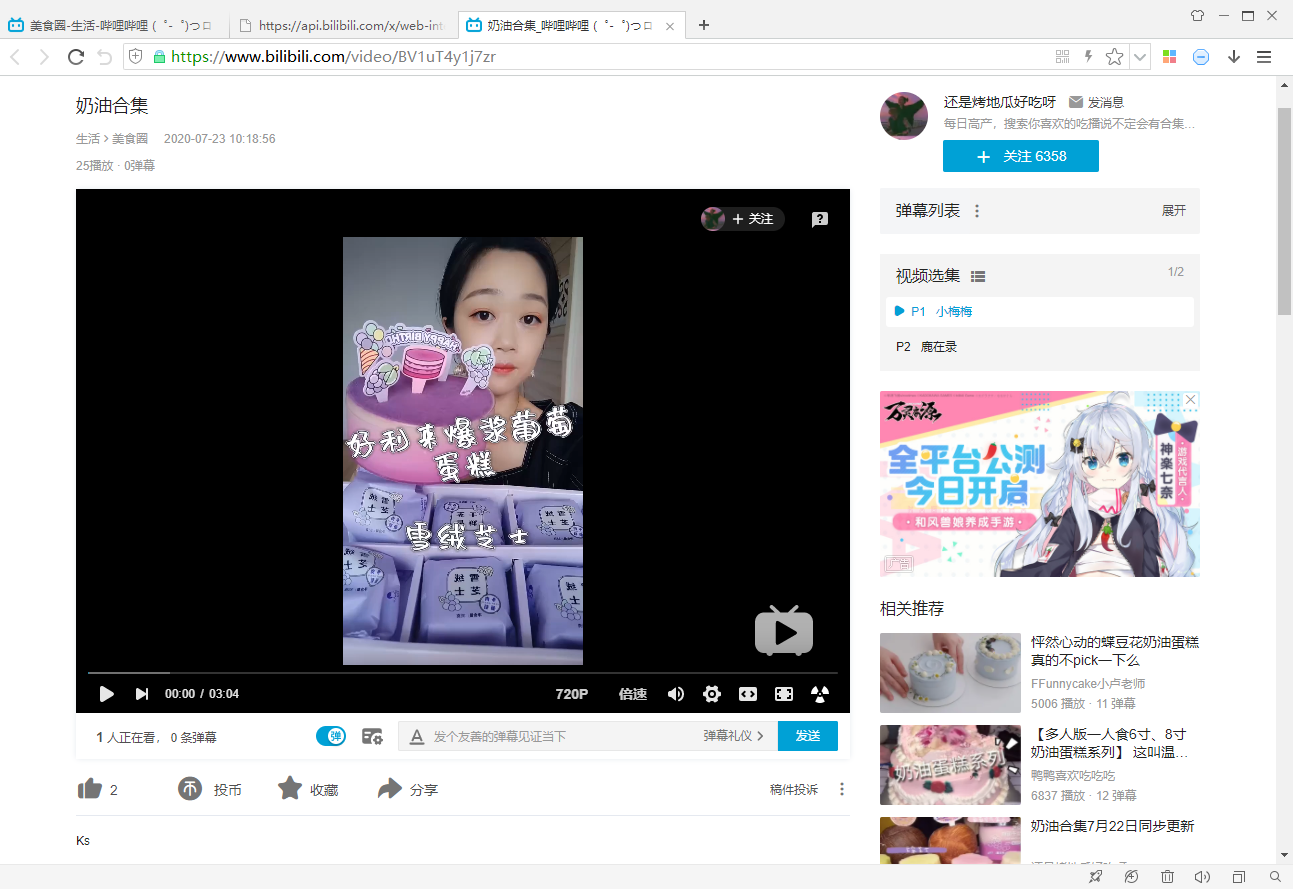
发现视频页面的链接地址是由固定模版生成的:
https://www.bilibili.com/video/{bvid}
其中bvid是每个视频的id,可以通过“newlist”链接获得。
如果要爬取视频页面信息,那么应用以上方法分析一下就可以了。
B站视频列表Item类实现
Scrapy的Item类,在概念上相当于C/C++的结构体、Java的POJO。
这里简单起见,我们将视频列表json文件中每个元素感兴趣的信息均存放在一个Item对象中,代码如下:
点击查看详情
from scrapy import Item, Fieldclass BilibiliVideoListItem(Item):# 视频信息aid = Field() # 视频IDbvid = Field() # 视频IDtid = Field() # 区pic = Field() # 封面title = Field() # 标题desc = Field() # 简介duration = Field() # 总时长,所有分P时长总和videos = Field() # 分P数pubdate = Field() # 发布时间view = Field() # 播放数danmaku = Field() # 弹幕数reply = Field() # 评论数like = Field() # 点赞数dislike = Field() # 点踩数coin = Field() # 投币数favorite = Field() # 收藏数share = Field() # 分享数cid = Field() # 标签ID# UP主信息mid = Field() # UP主IDname = Field() # 昵称face = Field() # 头像
B站Spider类实现
Spider类是实现爬虫的关键。
首先返回初始链接,这里我们直接返回“newlist”第一页的链接;
然后实现页面解析逻辑,由于返回的页面是json文件,我们直接将它转成Python对象,之后依次取出感兴趣的属性,最后封装成Item对象就可以了;
再之后要返回新的请求对象,这里直接返回下一页链接,并且判断是否已将所有视频都爬取了。
点击查看详情
from scrapy import Spider, Requestfrom scrapy_bilibili.items import BilibiliVideoListItemfrom util import json2objclass BilibiliSpider(Spider):# Spider名字name = 'BilibiliSpider'# 视频列表链接模版 (三个参数)url_fmt = r'https://api.bilibili.com/x/web-interface/newlist?' \r'rid={rid}&type=0&ps={ps}&pn={pn}'def __init__(self, *args, rid: int=None, ps: int=None, **kwargs):"""初始化Args:rid: 区ID,默认76,表示美食区ps: 视频列表每页视频数量,默认100"""super().__init__(*args, **kwargs)if rid is None: rid = 76if ps is None: ps = 100self.rid = ridself.ps = ps# 视频列表链接模版 (一个参数)self.url = self.url_fmt.format(rid=rid, ps=ps, pn='{}')# 初始链接self.start_urls = [self.url.format(1)]def parse(self, response):"""页面解析"""url = response.urlpn = int(url.rsplit('=', 1)[-1]) # 视频列表页码page = response.body.decode('UTF-8') # 响应对象中的json文件obj = json2obj(page) # 转成Python对象data = obj['data']count = data['page']['count'] # 该区当前视频总数archives = data['archives']for i in archives:aid = i['aid']bvid = i['bvid'].strip()tid = i['tid']pic = i['pic'].strip()title = i['title'].strip()desc = i['desc'].strip()duration = i['duration']videos = i['videos']pubdate = i['pubdate']stat = i['stat']view = stat['view']danmaku = stat['danmaku']reply = stat['reply']like = stat['like']dislike = stat['dislike']coin = stat['coin']favorite = stat['favorite']share = stat['share']cid = i['cid']owner = i['owner']mid = owner['mid']name = owner['name'].strip()face = owner['face'].strip()# 封装成Item对象item = BilibiliVideoListItem(aid=aid,bvid=bvid,tid=tid,pic=pic,title=title,desc=desc,duration=duration,videos=videos,pubdate=pubdate,view=view,danmaku=danmaku,reply=reply,like=like,dislike=dislike,coin=coin,favorite=favorite,share=share,cid=cid,mid=mid,name=name,face=face,)yield itemif pn*self.ps<count: # 如果当前爬取的视频数量少于视频总数url = self.url.format(pn+1) # 下一页的页码req = Request(url, callback=self.parse) # 下一页的请求对象yield req
其中用到的一个函数json2obj的实现如下:
点击查看详情
import jsondef json2obj(s: str, enc: str=None):"""json字符串 -> Python对象Args:s: 输入的json字符串enc: 字符串编码格式,默认UTF-8Returns:Python对象"""if enc is None: enc = 'UTF-8'return json.loads(s, encoding=enc)
B站Pipeline类实现
接下来要将获取到的Item对象去重并存入数据库。
这里我们使用Redis(Windows系统下用Memurai代替)中的Set来实现去重功能,我们用Set存储视频的bvid,当一个新的Item对象传入进来,判断其bvid是否已在Set中,如果已在则丢弃,如果不在则更新Set,并将Item对象存入数据库。
数据库采用MongoDB,每次存数据需要传递一个字典或列表对象,所以我们将Item对象转换成字典对象,并存入数据库中。
点击查看详情
from database import MongoDataBasefrom container import Redisclass BilibiliPipeline:def __init__(self):"""初始化"""# 数据库对象self.dataBase = MongoDataBase()# 数据表对象,负责数据保存self.datas = self.dataBase.getDatas('bilibili', 'video_list')# 缓存对象self.redis = Redis(cp=True)# 集合对象,负责数据去重self.set = self.redis.getSet('bilibili_video_list')def process_item(self, item, spider):"""处理Item对象对Item对象用Redis的Set进行去重,然后存入MongoDB。"""bvid = item['bvid'] # 视频IDif bvid not in self.set: # 如果视频ID不在集合中self.set.insert(bvid) # 视频ID加入集合self.datas.insert(dict(item)) # Item对象转成字典存入数据库return item
其中,container的实现如下:
点击查看详情
from typing import Generatorimport redisclass Container:def __len__(self) -> int:"""返回容器中元素个数"""return self.size()def __contains__(self, *args, **kwargs) -> bool:"""判断元素是否存在于容器中"""return self.has(*args, **kwargs)def __iter__(self) -> Generator:"""迭代访问容器中的所有元素"""return self.iter()def size(self) -> int:"""返回容器中元素个数"""passdef has(self, *args, **kwargs) -> bool:"""判断元素是否存在于容器中"""passdef iter(self) -> Generator:"""迭代访问容器中的所有元素"""passclass Set(Container):def insert(self, *args, **kwargs):"""插入一个元素"""passdef delete(self, *args, **kwargs):"""删除一个元素"""passdef inserts(self, *args, **kwargs):"""插入多个元素"""passdef deletes(self, *args, **kwargs):"""删除多个元素"""passclass Redis:def __init__(self, cp: bool=None, cs: int=None, *args, **kwargs):"""初始化Args:cp: 是否使用连接池,默认否cs: 连接池的最大连接数,默认8"""kwargs['decode_responses'] = True # 使Redis默认返回字符串if cp:if cs is None: cs = 8cp = redis.ConnectionPool(max_connections=cs)kwargs['connection_pool'] = cpself.redis = redis.Redis(*args, **kwargs)def getSet(self, key: str):"""返回集合容器Args:key: 集合的名字"""return Redis.Set(self.redis, key)class Container:def __init__(self, redis, key: str):self.redis = redisself.key = keyself.pipeline = Nonedef getRedis(self):if self.pipeline: return self.pipelinereturn self.redisdef getPipeline(self):if self.pipeline: return Falseself.pipeline = self.redis.pipeline()return Truedef execute(self):if self.pipeline:r = self.pipeline.execute()self.pipeline = Nonereturn rclass Set(Container, Set):def __init__(self, redis, key: str):super().__init__(redis, key)def size(self):return self.getRedis().scard(self.key)def has(self, x):return self.getRedis().sismember(self.key, x)def iter(self):return self.getRedis().smembers(self.key)def insert(self, x):return self.inserts(x)def delete(self, x):return self.deletes(x)def inserts(self, x, *args):return self.getRedis().sadd(self.key, x, *args)def deletes(self, x, *args):return self.getRedis().srem(self.key, x, *args)
database的实现如下:
点击查看详情
import pymongoclass DataBase:def getDatas(self, *args, **kwargs):"""返回数据表对象"""passclass Datas:def insert(self, *args, **kwargs):"""插入一个数据"""passdef delete(self, *args, **kwargs):"""删除一个数据"""passdef update(self, *args, **kwargs):"""更新一个数据"""passdef inserts(self, *args, **kwargs):"""插入多个数据"""passdef deletes(self, *args, **kwargs):"""删除多个数据"""passdef updates(self, *args, **kwargs):"""更新多个数据"""passdef find(self, *args, **kwargs):"""查找数据"""passclass MongoDataBase(DataBase):def __init__(self, *args, **kwargs):"""初始化"""self.mongo = pymongo.MongoClient(*args, **kwargs)def getDatas(self, db_key: str, datas_key: str):"""返回数据表对象Args:db_key: 数据库名字datas_key: 数据表名字"""return MongoDataBase.MongoDatas(self.mongo[db_key][datas_key])class MongoDatas(DataBase.Datas):def __init__(self, datas):self.datas = datasdef insert(self, d):return self.datas.insert_one(d)def delete(self, c):return self.datas.delete_one(c)def update(self, c, d):return self.datas.update_one(c, d)def inserts(self, d):return self.datas.insert_many(d)def deletes(self, c):return self.datas.delete_many(c)def updates(self, c, d):return self.datas.update_many(c, d)def find(self, *args, **kwargs):r = self.datas.find(*args, **kwargs)for i in r:del i['_id'] # 删除_id属性yield i
最后要在scrapy_bilibili/scrapy_bilibili/settings.py中设置一下Pipeline:
点击查看详情
ITEM_PIPELINES = {'scrapy_bilibili.pipelines.BilibiliPipeline': 100,}
运行爬虫
好不容易实现了爬虫,接下来就来跑一跑吧。
命令行或终端输入:
scrapy crawl BilibiliSpider
如果要传入参数,则可以输入:
scrapy crawl BilibiliSpider -a rid=17
注意要切换到项目的根目录,并且保证Redis和MongoDB的服务都已经开启了。
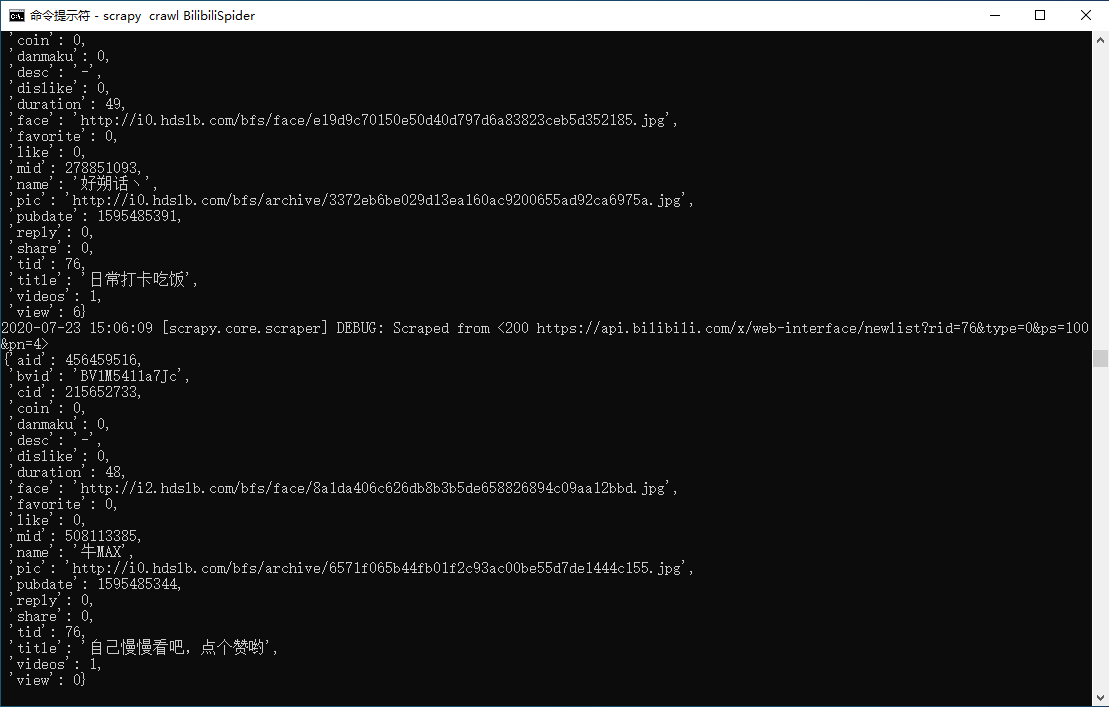
控制台正在疯狂输出...
过了十分钟,我们来看看Redis和MongoDB的情况:
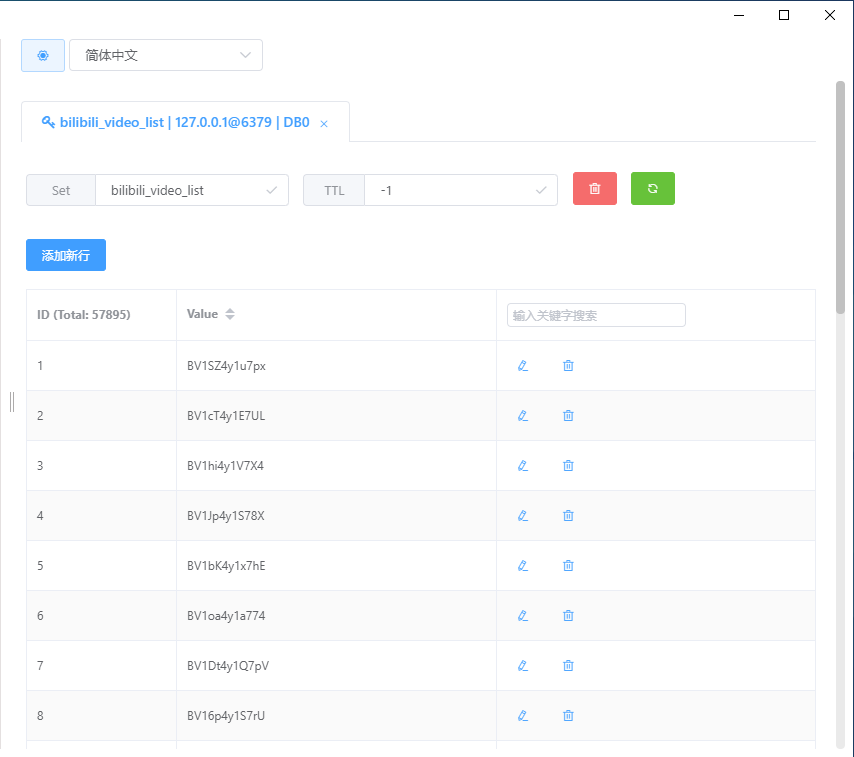
上面是Redis的情况,下了5万多条数据,然后下面是MongoDB的情况:

整体情况顺利。
基于Scrapy的B站爬虫的更多相关文章
- 基于scrapy框架的分布式爬虫
分布式 概念:可以使用多台电脑组件一个分布式机群,让其执行同一组程序,对同一组网络资源进行联合爬取. 原生的scrapy是无法实现分布式 调度器无法被共享 管道无法被共享 基于 scrapy+redi ...
- 一个基于Scrapy框架的pixiv爬虫
源码 https://github.com/vicety/Pixiv-Crawler,功能什么的都在这里介绍了 说几个重要的部分吧 登录部分 困扰我最久的部分,网上找的其他pixiv爬虫的登录方式大多 ...
- 基于Scrapy的交互式漫画爬虫
Github项目地址 前言 该项目始于个人兴趣,本意为给无代码经验的朋友做到能开箱即用 阅读此文需要少量Scrapy,PyQt 知识,全文仅分享交流 摘要思路,如需可阅读源码,欢迎提 issue 一. ...
- python基于scrapy框架的反爬虫机制破解之User-Agent伪装
user agent是指用户代理,简称 UA. 作用:使服务器能够识别客户使用的操作系统及版本.CPU 类型.浏览器及版本.浏览器渲染引擎.浏览器语言.浏览器插件等. 网站常常通过判断 UA 来给不同 ...
- Python分布式爬虫打造搜索引擎完整版-基于Scrapy、Redis、elasticsearch和django打造一个完整的搜索引擎网站
Python分布式爬虫打造搜索引擎 基于Scrapy.Redis.elasticsearch和django打造一个完整的搜索引擎网站 https://github.com/mtianyan/Artic ...
- 爬虫学习之基于Scrapy的爬虫自动登录
###概述 在前面两篇(爬虫学习之基于Scrapy的网络爬虫和爬虫学习之简单的网络爬虫)文章中我们通过两个实际的案例,采用不同的方式进行了内容提取.我们对网络爬虫有了一个比较初级的认识,只要发起请求获 ...
- 基于Python,scrapy,redis的分布式爬虫实现框架
原文 http://www.xgezhang.com/python_scrapy_redis_crawler.html 爬虫技术,无论是在学术领域,还是在工程领域,都扮演者非常重要的角色.相比于其他 ...
- 基于scrapy爬虫的天气数据采集(python)
基于scrapy爬虫的天气数据采集(python) 一.实验介绍 1.1. 知识点 本节实验中将学习和实践以下知识点: Python基本语法 Scrapy框架 爬虫的概念 二.实验效果 三.项目实战 ...
- 基于Scrapy框架的Python新闻爬虫
概述 该项目是基于Scrapy框架的Python新闻爬虫,能够爬取网易,搜狐,凤凰和澎湃网站上的新闻,将标题,内容,评论,时间等内容整理并保存到本地 详细 代码下载:http://www.demoda ...
随机推荐
- redis基础一
2.修改redis.conf的配置文件有两个地方 a.将daemonize设置成true支持后台启动 b.将redis的数据库文件保存到 下面的目录 3.启动redis服务器 4.操作redis ,给 ...
- eclipse 导入下载或拷贝的java Web项目时报错 ,或者是报错Unbound classpath container: 'JRE System Library
在Problems里报错Description Resource Path Location Type Unbound classpath container: 'JRE System Library ...
- java.sql.SQLException: The server time zone value '�й���ʱ��' is unrecognized
idea数据库连接字符串需要添加一些参数: ?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai ...
- mybatis关于Criteria的一点小坑。。。
目录 在用Criteria时,相关代码如下: final RolePermissionExample example = new RolePermissionExample(); example.cr ...
- 记一道CTF隐写题解答过程
0x00 前言 由于我是这几天才开始接触隐写这种东西,所以作为新手我想记录一下刚刚所学.这道CTF所需的知识点包括了图片的内容隐藏,mp3隐写,base64解密,当铺解密,可能用到的工具包括bin ...
- Spring IoC @Autowired 注解详解
前言 本系列全部基于 Spring 5.2.2.BUILD-SNAPSHOT 版本.因为 Spring 整个体系太过于庞大,所以只会进行关键部分的源码解析. 我们平时使用 Spring 时,想要 依赖 ...
- day23 作业
day23 作业 目录 day23 作业 1.把登录与注册的密码都换成密文形式 2.文件完整性校验(考虑大文件) 3.注册功能改用json实现 4.项目的配置文件采用configparser进行解析 ...
- 解决android studio 文本乱码问题
下面图片,部分字体,有一些中文字符无法显示,可选择提交保存,立即可看到效果,不喜欢就再换一个合适的字体.
- 正则表达式以及sed,awk用法 附带案例
则表达式 基本正则 ^ $ [ ] [^] . * \{n,m\} \{n,\} \(ro\)\{2\} \(\) 扩展正则 egrep grep - ...
- Python math 、cmath
1.math dir(math) 2.cmath 复数运算