Linux安装ElasticSearch7.X & IK分词器
前言
安装ES之前,请先检查JDK版本,es使用java编写,强依赖java环境。JDK安装过程略。
安装步骤
1.下载地址
2.解压elasticsearch-7.2.0-linux-x86_64.tar.gz到/usr/local/目录:
- tar -zxvf elasticsearch-7.2.0-linux-x86_64.tar.gz -C /usr/local/
3.进入解压后的elasticsearch目录:
1) 新建data目录:
- mkdir data
2) 修改config/elasticsearch.yml:
- vim config/elasticsearch.yml
取消下列项注释并修改:
- #集群名称
- cluster.name: xxx
- #节点名称
- node.name: node-1
- #数据和日志的存储目录
- path.data: /usr/local/elasticsearch-7.2.0/data
- path.logs: /usr/local/elasticsearch-7.2.0/logs
- #设置绑定的ip,设置为0.0.0.0以后就可以让任何计算机节点访问到了
- network.host: 0.0.0.0
- #默认端口
- http.port: 9200
- #设置在集群中的所有节点名称
- cluster.initial_master_nodes: ["node-1"]
修改完毕后,:wq 保存退出
3) 修改es占用jvm空间分配(默认2G,正式服根据实际情况配置)
- #进入config目录下
cd /usr/local/elasticsearch-7.2.0/config
#打开jvm.options
vim jvm.options
#设置占用空间(注意m、g小写)
-Xms200m- -Xmx200m
4.用户权限问题
由于es可以输入且执行脚本,为了系统安全,不允许使用root启动,添加一个新用户:
- #添加用户和设置密码
- adduser es
- passwd es
- #授权 /usr/local/elasticsearch-7.2.0目录下的文件拥有者为 es
- chown es /usr/local/elasticsearch-7.2.0/ -R
5.解决会出现的问题
1) 解决 max virtual memory areas vm.max_map_count [65530] is too low
原因:max_map_count这个参数就是允许一个进程在VMAs(虚拟内存区域)拥有最大数量,VMA是一个连续的虚拟地址空间,当进程创建一个内存映像文件时VMA的地址空间就会增加,当达到max_map_count了就是返回out of memory errors
- // 修改下面的文件 里面是一些内核参数
- vim /etc/sysctl.conf
- //在末尾添加以下配置
- vm.max_map_count=655360
添加完保存,然后执行
- sysctl -p
- //-p 从指定的文件加载系统参数,如不指定即从/etc/sysctl.conf中加载
2) 解决 max file descriptors [65535] for elasticsearch process is too low, increase to at least [65536]
原因:最大文件打开数量太小,出现此错误
- #vim编辑此文件
- vim etc/security/limits.conf
- #在末尾加上:
- es soft nofile 65536
- es hard nofile 65536
- es soft nproc 4096
- es hard nproc 4096
6.后台启动es
- #切换登录es账户
- su es
- #前台启动,关闭命令行或者退出,应用就会关闭
- cd /usr/local/elasticsearch-7.2.0/bin
- sh elasticsearch
- #后台启动,退出时,应用仍在后台运行
- ./elasticsearch -d
- #查看进程
- ps -ef|grep elasticsearch
- #关闭进程
- kill -9 端口号
7.查看
页面访问 xx.xx.xx.xx:9200,出现如下信息,则代表安装成功。
- {
- "name" : "node-1",
- "cluster_name" : "xxx",
- "cluster_uuid" : "8SZOAD43Q4uiSaWFMrKSyQ",
- "version" : {
- "number" : "7.2.0",
- "build_flavor" : "default",
- "build_type" : "tar",
- "build_hash" : "508c38a",
- "build_date" : "2019-06-20T15:54:18.811730Z",
- "build_snapshot" : false,
- "lucene_version" : "8.0.0",
- "minimum_wire_compatibility_version" : "6.8.0",
- "minimum_index_compatibility_version" : "6.0.0-beta1"
- },
- "tagline" : "You Know, for Search"
- }
8.安装IK分词器插件
1) 官方下载地址:点击这里跳转
下载对应es版本的ik分词器zip

2) 创建ik文件夹,并将下载好的zip文件包解压,放入到ik文件夹
- #进入es安装目录下的plugins下,创建ik文件夹
- cd /elasticsearch-7.2.0/plugins
- mkdir ik
- #将下载好的zip包放入ik文件夹下,执行解压
- unzip elasticsearch-analysis-ik-7.2.0.zip
3) 重启es服务
- #切换成有权限的es用户
- su es
- #杀掉进程,重启
ps -ef | grep elastic- kill -9 端口号
- ./elsaticsearch-7.2.0/bin/elasticsearch -d
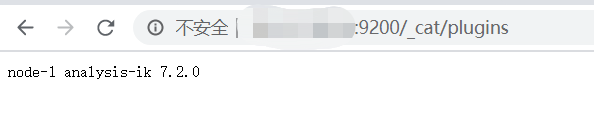
4) 验证
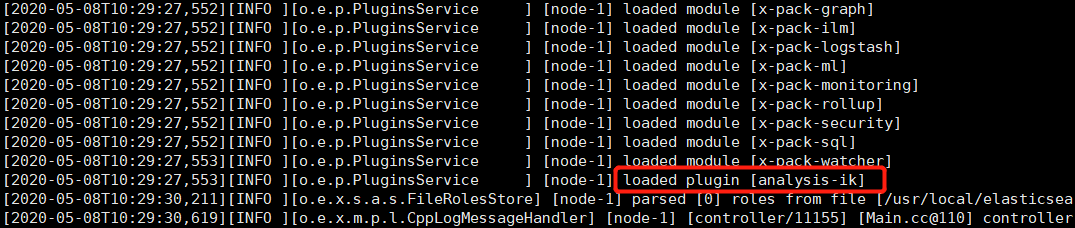
http://xx.xx.xx.xx:9200/_cat/plugins
补充扩展
Elasticsearch 7.x配置用户名密码访问 开启x-pack验证
Linux安装ElasticSearch7.X & IK分词器的更多相关文章
- Windows上安装ElasticSearch7的IK分词器
首先IK分词器和ES版本一定要严格对应,下面是版本对照表 IK分词器下载地址 https://github.com/medcl/elasticsearch-analysis-ik/releases 我 ...
- (2)ElasticSearch在linux环境中集成IK分词器
1.简介 ElasticSearch默认自带的分词器,是标准分词器,对英文分词比较友好,但是对中文,只能把汉字一个个拆分.而elasticsearch-analysis-ik分词器能针对中文词项颗粒度 ...
- docker上安装elasticsearch和ik分词器插件和header,实现分词功能
docker run -di --name=tensquare_es -p 9200: -p 9300:9300 elasticsearch:5.6.8 创建elasticsearch容器(如果版本不 ...
- ElasticSearch(六):IK分词器的安装与使用IK分词器创建索引
之前我们创建索引,查询数据,都是使用的默认的分词器,分词效果不太理想,会把text的字段分成一个一个汉字,然后搜索的时候也会把搜索的句子进行分词,所以这里就需要更加智能的分词器IK分词器了. 1. i ...
- IK分词器的安装与使用IK分词器创建索引
之前我们创建索引,查询数据,都是使用的默认的分词器,分词效果不太理想,会把text的字段分成一个一个汉字,然后搜索的时候也会把搜索的句子进行分词,所以这里就需要更加智能的分词器IK分词器了. 1. i ...
- Solr:Slor初识(概述、Windows版本的安装、添加IK分词器)
1.Solr概述 (1)Solr与数据库相比的优势 搜索速度更快.搜索结果能够按相关度排序.搜索内容格式不固定等 (2)Lucene与Solr的区别 Lucene提供了完整的查询引擎和索引引擎,目的是 ...
- Docker下安装Elasticsearch、ik分词器、kibana
1:使用docker拉取Elasticsearch镜像 docker pull elasticsearch:7.12.0(不加版本号默认是最新版本) 2:查看是否成功下载镜像 docker image ...
- [Linux]Linux下安装和配置solr/tomcat/IK分词器 详细实例一.
在这里一下讲解着三个的安装和配置, 是因为solr需要使用tomcat和IK分词器, 这里会通过图文教程的形式来详解它们的安装和使用.注: 本文属于原创文章, 如若转载,请注明出处, 谢谢.关于设置I ...
- [Linux]Linux下安装和配置solr/tomcat/IK分词器 详细实例二.
为了更好的排版, 所以将IK分词器的安装重启了一篇博文, 大家可以接上solr的安装一同查看.[Linux]Linux下安装和配置solr/tomcat/IK分词器 详细实例一: http://ww ...
随机推荐
- 嵌入式设备上卷积神经网络推理时memory的优化
以前的神经网络几乎都是部署在云端(服务器上),设备端采集到数据通过网络发送给服务器做inference(推理),结果再通过网络返回给设备端.如今越来越多的神经网络部署在嵌入式设备端上,即inferen ...
- 2019牛客暑期多校训练营(第一场)A Equivalent Prefixes
传送门 题意: 先输入一个n,代表两个数组里面都有n个数,然后让你从中找到一个p<=n,使其满足(1<=l<=r<=p<=n)可以让在(l,r)这个区间内在两个数组中的的 ...
- Codeforces Round #677 (Div. 3)【ABCDE】
比赛链接:https://codeforces.com/contest/1433 A. Boring Apartments 题解 模拟即可. 代码 #include <bits/stdc++.h ...
- 【noi 2.6_90】滑雪(DP)
题意:输出最长下降路径的长度. 解法:f[i][j]表示结尾于(i,j)的最长的长度.由于无法确定4个方位已修改到最佳,所以用递归实现. 1 #include<cstdio> 2 #inc ...
- Educational Codeforces Round 88 (Rated for Div. 2) E、Modular Stability 逆元+思维
题目链接:E.Modular Stability 题意: 给你一个n数,一个k,在1,2,3...n里挑选k个数,使得对于任意非负整数x,对于这k个数的任何排列顺序,然后用x对这个排列一次取模,如果最 ...
- URAL - 1635 哈希区间(或者不哈希)+dp
题意: 演队在口试中非常不幸.在42道考题中,他恰好没有准备最后一道题,而刚好被问到的正是那道题.演队坐在教授面前,一句话也说不出来.但教授心情很好,给了演队最后一次通过考试的机会.他让这个可怜的学生 ...
- Codeforces Round #651 (Div. 2) C. Number Game (博弈,数学)
题意:对于正整数\(n\),每次可以选择使它变为\(n-1\)或者\(n/t\) (\(n\ mod\ t=0\)且\(t\)为奇数),当\(n=1\)时便不可以再取,问先手赢还是后手赢. 题解:首先 ...
- OpenStack服务默认端口号
在某些部署中,例如已设置限制性防火墙的部署,您可能需要手动配置防火墙以允许OpenStack服务流量. 要手动配置防火墙,您必须允许通过每个OpenStack服务使用的端口的流量.下表列出了每个Ope ...
- const,volatile,static,typdef,几个关键字辨析和理解
1.const类型修饰符 const它限定一个变量初始化后就不允许被改变的修饰符.使用const在一定程度上可以提高程序的安全性和可靠性.它即有预编译命令的优点也有预编译没有的优点.const修饰的变 ...
- 图片转tfrecords
import numpy as np import tensorflow as tf import time import os import cv2 from sklearn.utils impor ...