BiMPM:Bilateral Multi-Perspctive Matching for Natural Language Sentences
导言
本论文的工作主要是在 'matching-aggregation'的sentence matching的框架下,通过增加模型的特征(实现P与Q的双向匹配和多视角匹配),来增加NLSM(Natural language sentence matching)的accuracy
Relation work
在NLSM中,主要有两个DL的框架:
Siamese框架:
介绍:在该框架中,相同的神经网络编码器(例如,CNN或RNN)被单独地应用于两个输入句子,使得P和Q两个句子中的两个被编码到同一嵌入空间中的句子向量中。 然后,仅基于两个句子向量做出匹配决策。
优点: a、共享参数使模型更小更容易训练,b、句子矢量可用于可视化,也可以用到句子聚类和其他目的
缺点:两个句子之间没交互,可能丢失重要信息matching-aggregation 框架
介绍:先对P和Q两个句子进行跟小粒度的匹配(word or contextual vectors),再对他们匹配的结果进行聚集,最后做出决策。
优点:抽取更多的两个句子交互性的特征
缺点:a、仅有word-by-word的匹配,粒度单一 b、P和Q匹配方向单一,只有P←Q的匹配;BiMPM创新点:
在matching-aggregation基础上,a、增加P→Q和P←Q连个方向的匹配 b、在每个方向增加不同视角的匹配;
Our model essentially belongs to the“matching-aggregation”framework. Given two sentences P and Q, our model first encodes them with a bidirectional Long Short-Term Memory Network (BiLSTM). Next, we match the two encoded sentences in two directions P→Q and P←Q. In each matching direction, let’s say P→Q, each time step of Q is matched against all time-steps of P from multiple perspectives.
模型介绍
Overview
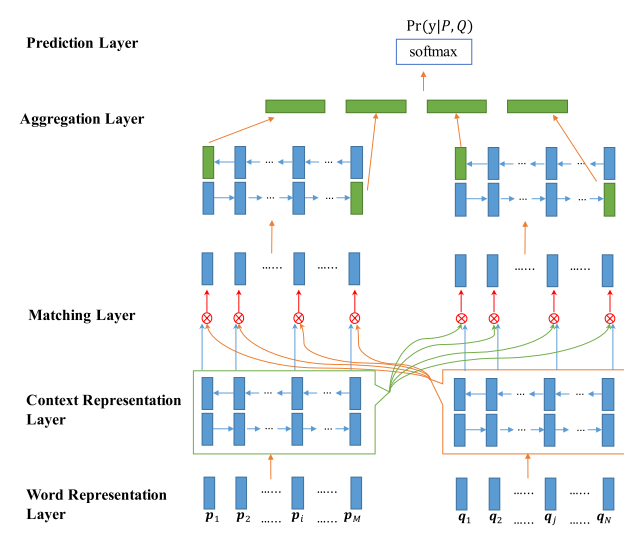
BiMPM模型的目标是学习条件概率分布:
\]
模型一共5个部分组合而成:
Word Representation Layer: 输入的vector由word vector 与 character vector 拼接成
Context Representation Layer: 使用Bi-LSTM对P或Q的每个time-step进行上下文词嵌入(contextual embedding)进行编码。
Matching Layer: 使用cosine相似度函数,对经Context Representation层后,P中每个time-step 的contextual embedding与Q的所有(all)time-step进行多个(4个)视角的相似度计算(即P←Q相似度匹配),输出 matching vector。反之,反方向P→Q的相似度匹配亦然。
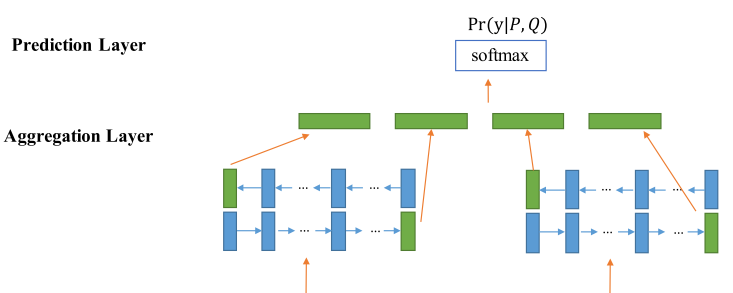
Aggregation Layer: 针对Matching Layer输出P或Q每个 time-step的matching vector,用Bi-LSTM进行相似度的聚集成固定长度(fixed-matching)的matching vector,并仅仅将Bi-LSTM两个方向最后一个(last) time-step 的 fixed-matching matching vector 作为该层输出,P与Q分别各输出两个fixed-matching matching vector 。
Prediction Layer: 两层全连接层对4个fixed-matching matching vector 进行总结‘consume’,并用Softmax函数作为输出。
Word Representation Layer
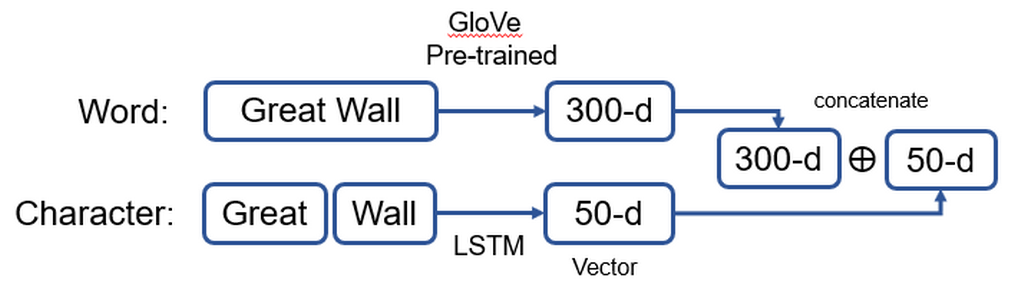
为了增加更多的特征信息,该层输入的词向量采用word +character的形式,增加输入不同粒度的信息。
word vector:
维度:300-d
来源:GloVe 预训练的词向量 or word2veccharacter vector:
维度:50-d
来源:用LSTM在其他NLSM任务中训练,初始化为20-d,经过LSTM后输出50-d输出:将word vector 连接 character vector 句子,该层的输出为 P:\(p_i\) 和 句子 Q:\(q_i\)
#https://github.com/pengshuang/Text-Similarity/blob/master/models/BiMPM.py
if self.args.use_char_emb:
# (batch, seq_len, max_word_len) -> (batch * seq_len, max_word_len)
seq_len_p = kwargs['char_p'].size(1)
seq_len_h = kwargs['char_h'].size(1)
char_p = kwargs['char_p'].view(-1, self.args.max_word_len)
char_h = kwargs['char_h'].view(-1, self.args.max_word_len)
# 用LSTM 将(max_word_len, char_dim)维输出为 (char_hidden_size)维vector
# (batch * seq_len, max_word_len, char_dim)-> (1, batch * seq_len, char_hidden_size)
_, (char_p, _) = self.char_LSTM(self.char_emb(char_p))
_, (char_h, _) = self.char_LSTM(self.char_emb(char_h))
#
# (batch, seq_len, char_hidden_size)
char_p = char_p.view(-1, seq_len_p, self.args.char_hidden_size)
char_h = char_h.view(-1, seq_len_h, self.args.char_hidden_size)
# (batch, seq_len, word_dim + char_hidden_size)
# torch.cat是将两个张量(tensor)拼接在一起,cat是concatnate的意思,即拼接,联系在一起。
# 若矩阵为2维矩阵,按维数0(行)拼接,#按维数1(列)拼接
p = torch.cat([p, char_p], dim=-1)
h = torch.cat([h, char_h], dim=-1)
Context Representation Layer
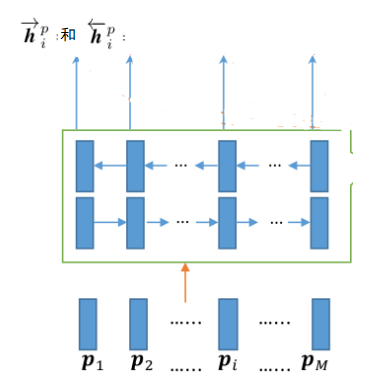
用Bi-LSTM对 P 或 Q 对输入每个time-step(\(p_i\) 和 \(q_i\) )的进行上下文词嵌入编码(contexture embedding coding),即抽出上下文特征信息。
输入:每个time-step ( \(p_i\) 和 \(q_i\) )
输出:每个time-step( \(\overrightarrow{h^p_i}\) 、 \(\overleftarrow{h^p_i}\) 和 \(\overrightarrow{h^q_i}\) 、 \(\overleftarrow{h^q_i}\))
句子 P 的\(p_i\)上下文词嵌入编码:
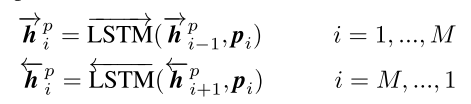
句子 Q 的\(q_i\)上下文词嵌入编码:
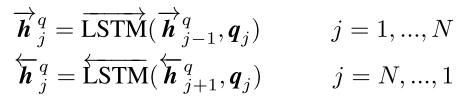
示意图:
Matching Layer (创新点)
Matching Layer 中主要负责 P 与 Q 之间 cosine 相似度的匹配计算。其中,主要创新点有两个(BiMPM:bilateral multi-perspective matching):
0、consine相似度匹配函数
在此,对Matching Layer 中,定义了cosine相似度匹配函数 \(f_m\) ,计算两个向量的相似度,公式如下:
\]
其中\(f_m\)为\(cosine\) 函数,\(W\)为可训练参数,\(W\in R^{l\times d}\)(\(W\)的维度是\(l\times d\),\(l\)为视角数,\(d\)为输入向量的维度)。\(m \in [m_1,...,m_k,...,m_l]\),并且 \(m_k\)表示第\(k\)个视角的相似度值,具体为:
\]
1、bilateral
- 双向相似度匹配。除了之前相关工作,只有 P 每个 time-step 与 Q 中所有 time-step 的,P←Q的单向相似度匹配外,增加了只有 Q 每个 time-step 与 P 中所有 time-step 的相似度匹配。即增加了P→Q方向的双向相似度匹配,即双向的相似度匹配。增加了P与Q的相似度的特征信息。
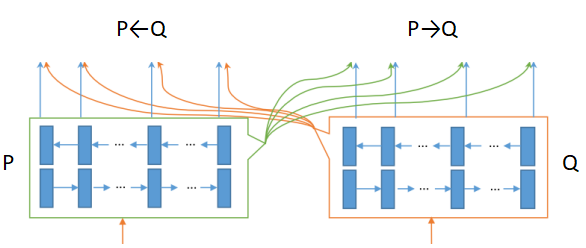
2、multi-perspective
- 多视角相似度匹配。即在P←Q和P→Q中,有单一的每个 time-step 与另一个句子所有(all) time-step相似度匹配,变成每个 time-step 与另一个句子的Full-Matching(所有 time-step 总体相似度)/ Maxpooling-Matching(每个time-step 相似度中最大值) /Attentive-Matching(加权平均 time-step的相似度)/Max-Attentive-Matching 等四个不同视角相似度的匹配。(ps:括号里面为个人理解,不是直译,仅供参考。)
在此,以 \(P ← Q\) 的 foward 方向 \(\overrightarrow{P}\) ← \(\overrightarrow{Q}\) 和 backward 方向 \(\overleftarrow{P}\) ← \(\overleftarrow{Q}\) 为例,分别对Full-Matching、Maxpooling-Matching、Attensive-Matching、Max-Attensive-Matching作简要说明。\(P → Q\) 的 \(\overrightarrow{P}\) → \(\overrightarrow{Q}\) 和 \(\overleftarrow{P}\) → \(\overleftarrow{Q}\) 两个方向上的同理可得。(ps: \(\overrightarrow{P}\) 指 P 在Bi-LSTM的foward放向的 time-step,\(\overleftarrow{P}\) 指 P 在Bi-LSTM 二点backward放向的 time-step .)
- Full-Matching: 句子P中,每一个time-step \({\overrightarrow h}_i^p\) 都与 句子Q中,foward方向最后一个time-step 输出\({\overrightarrow h}_N^q\),进行相似度匹配计算,公式表示为:
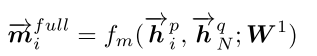
并且,\(\overrightarrow{P}\) ← \(\overrightarrow{Q}\) 的 Full-Matching 的图示为:
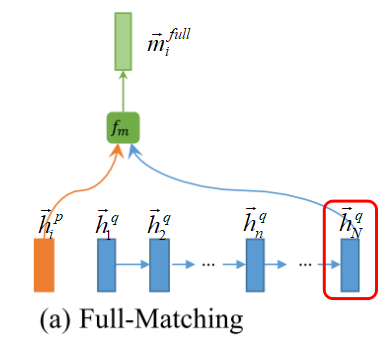
另外, \(\overrightarrow{P}\) ← \(\overrightarrow{Q}\) 的 Full-Matching 公式,则表示为:
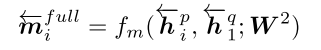
为此,我个人理解为P 中每一个方向(foward/backward)的time-step,都与Q中所有time-step上文或下文(因为foward和backward相似度分开计算的)信息,做一个相似度匹配的计算。这是一个Q全文信息的视角。
- Maxpooling-Matching: 句子P中,每一个 time-step \({\overrightarrow h}_i^p\) 都与 句子Q中,foward方向每一个time-step \({\overrightarrow h}_i^q\),进行相似度计算$ {\overrightarrow m}_i$,并且经过Max-pooling 选取所有 time-step 相似度最大值 \({\overleftarrow m}_i^{max}\),公式表示为:
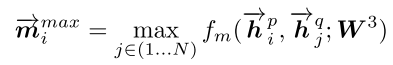
并且,\(\overrightarrow{P}\) ← \(\overrightarrow{Q}\) 的 Max-Matching 的图示为:
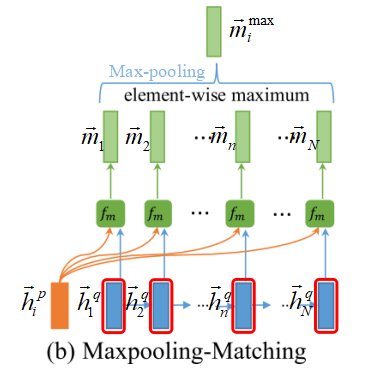
另外, \(\overrightarrow{P}\) ← \(\overrightarrow{Q}\) 的 Max-Matching 公式,则表示为:
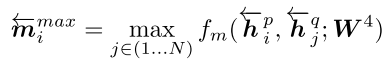
同样,我个人理解为P 中每一个方向(foward/backward)的time-step,采用Max-pooling选择Q中所有time-step上文或下文相似度最高的信息。这是一个Q最大相似度的视角。
- Attentive-Matching: 句子P中,每一个 time-step \({\overrightarrow h}_i^p\) 都与句子Q中,foward方向所有time-step的加权平均(attentive) \({\overrightarrow h}_i^{mean}\)(权重为cosine距离),进行相似度计算 \({\overrightarrow m}_i^{att}\) 。其中,
\({\overrightarrow h}_i^{mean}\) 的计算公式为:
\(.\)
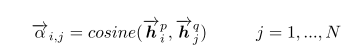
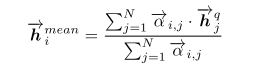
因此,\({\overrightarrow m}_i^{att}\)的相似度计算则为:
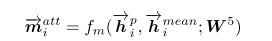
并且,\(\overrightarrow{P}\) ← \(\overrightarrow{Q}\) 的 Attentive-Matching 的图示为:
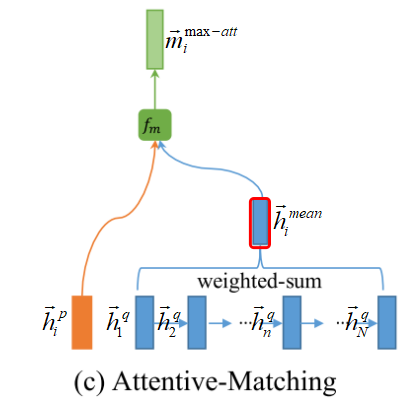
另外, \(\overrightarrow{P}\) ← \(\overrightarrow{Q}\) 的 Attentive-Matching 公式,则表示为:
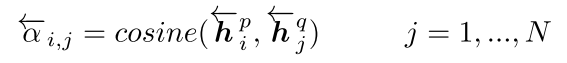
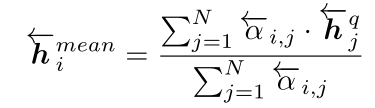
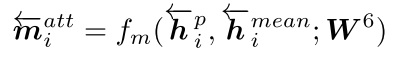
为此,我个人理解为P 中每一个方向(foward/backward)的time-step,与Q中所有time-step上文或下文加权平均值的\({\overrightarrow h}_i^{mean}\),做一个相似度匹配的计算。这是一个Q平均相似度的视角。
- Max-Attensive-Matching: 句子P中,每一个 time-step \({\overrightarrow h}_i^p\) 都与句子Q中,foward方向所有time-step的最大attentive的 \({\overrightarrow h}_i^{max}\),进行相似度计算\({\overrightarrow m}_i^{max-att}\)。(ps:与Max-pooling有点区别,Max-pooling选择所有经\(f_m\)计算后\({\overrightarrow m}_i\)中的最大值,其cosine相似度有可训练参数W参与计算。而这里,是纯粹\({\overrightarrow h}_i^q\) 与\({\overrightarrow h}_i^q\) 的cosine距离\({\overrightarrow m}_{i,j}\)(其cosine相似度没W参与计算),选择\({\overrightarrow m}_{i,j}\)对应最大的\({\overrightarrow h}_i^q\),再计算出其相似度\({\overrightarrow m}_i^{max-att}\))。另外,Max-Attensive-Matching 的公式与Attensive-Matching 极为相近,区别是\({\overrightarrow h}_i^{mean}\) 变成 \({\overrightarrow h}_i^{max}\) ,而\({\overrightarrow h}_i^{max}\)计算公式为:
\underset{j \in (1...N)}{\max}({\overrightarrow \alpha}_{i,j})) \]
而\(\overrightarrow{P}\) ← \(\overrightarrow{Q}\) 的 Max-Attentive-Matching 的图示为:
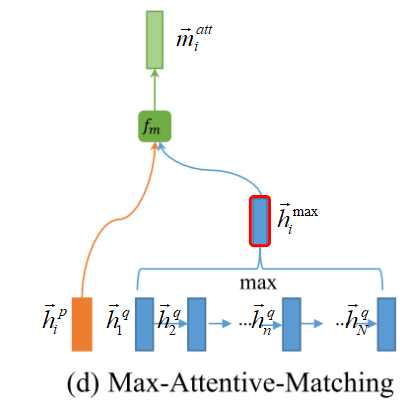
为此,我个人理解为P 中每一个方向(foward/backward)的time-step,与Q中所有time-step上文或下文加权平均值的\({\overrightarrow h}_i^{max}\),做一个相似度匹配的计算。这是一个Q每个time-step最大cosine距离相似度的视角。
3、BiMPM与之前Matching-Aggregation之间Matching Layerde的对比
总来的说,BiMPM的Matching Layer与之前的Matching-Aggregation匹配框架相比较:
匹配方向的创新:
之前:单向匹配:\(P ← Q\)(\(\overrightarrow{P}\) ← \(\overrightarrow{Q}\) 和 \(\overleftarrow{P}\) ← \(\overleftarrow{Q}\) )
BiMPM:双向匹配: \(P ← Q\)(\(\overrightarrow{P}\) ← \(\overrightarrow{Q}\) 和 \(\overleftarrow{P}\) ← \(\overleftarrow{Q}\) )和 \(P→Q\)(\(\overrightarrow{P}\) → \(\overrightarrow{Q}\) 和 \(\overleftarrow{P}\) → \(\overleftarrow{Q}\) )!匹配视觉的创新:
之前:单一视觉: Full-Matching
BiMPM:多种视觉: Full-Matching/ Maxpooling-Matching /Attentive-Matching/Max-Attentive-Matching每个time-step输出的matching vector形式
之前:2个matching-vector concatenate。\(\overrightarrow{P}\) ← \(\overrightarrow{Q}\) 和 \(\overleftarrow{P}\) ← \(\overleftarrow{Q}\) 各单个视角的 matching vector 作 concatenate。
BiMPM:8个matching-vector concatenate。\(\overrightarrow{P}\) ← \(\overrightarrow{Q}\) 和 \(\overleftarrow{P}\) ← \(\overleftarrow{Q}\) (或\(\overrightarrow{P}\) → \(\overrightarrow{Q}\) 和 \(\overleftarrow{P}\) → \(\overleftarrow{Q}\) )各4个视角的 matching vector 作 concatenate。
Aggregation Layer & Prediction Layer
该层将上层输出相似度向量matching-vector \(m_i\),按Bi-LSTMde foward 和backward作信息聚合/特征提取,并将foward 和backward的最后time-step 的 fixed-length matching-vector 输出至2层全连接层的 Prediction Layer 中,最后采用 softmax 作分类。如图示,其中,图中4个绿色的vector为 fixed-length matching-vector:
实验与总结
- Paraphrase Identification实验
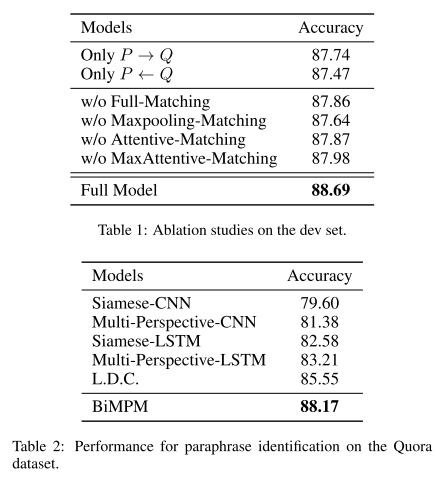
1、BiMPM在NLSM中有效:在Paraphrase Identification实验中,BiMPM的Acc能高于之前state-of-art 2.6%。但对于实际应用,要考虑即训练难度和inference速率。
2、双向和四种视角都对BiMPM有部分促进作用。
- Naural Language实验
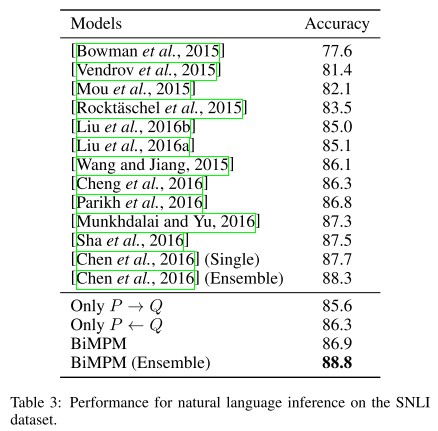
1、BiMPM在inference任务中效果一般,甚至在相对与state-of-art还有差距。
2、虽然BiMPM在Ensemble情况下Acc最高,但也只搞0.5%,个人认为有待商榷。
- Answer Sentence Selection实验
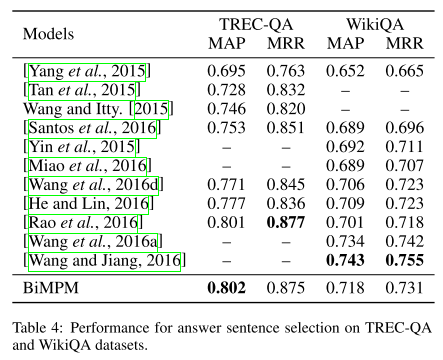
1、BiMPM在针对不同些数据集效果不同。
- 总体收获:
1、该模型给我最大的思路是,针对提升NLP任务的性能提升,可以从增加正向逆向与增视角信息的方面考虑(但还是有点炼丹学)。 2、cosine函数作为Matching Layer的输出,可以将其与sigmoid和tanh激活函数作简单比较,这里包含可训练参数W的cosine函数已经可以看作相似度的激活函数。它将P与Q信息投影至一个相似度空间,然后经过Aggregation Layer作相似度的信息聚合,经全连接层分类。
BiMPM:Bilateral Multi-Perspctive Matching for Natural Language Sentences的更多相关文章
- 《Bilateral Multi-Perspective Matching for Natural Language Sentences》(句子匹配)
问题: Natural language sentence matching (NLSM),自然语言句子匹配,是指比较两个句子并判断句子间关系,是许多任务的一项基本技术.针对NLSM任务,目前有两种流 ...
- Bilateral Multi-Perspective Matching for Natural Language Sentences---读书笔记
自然语言句子的双向.多角度匹配,是来自IBM 2017 年的一篇文章.代码github地址:https://github.com/zhiguowang/BiMPM 摘要 这篇论文主要 ...
- Convolutional Neural Network Architectures for Matching Natural Language Sentences
interaction n. 互动;一起活动;合作;互相影响 capture vt.俘获;夺取;夺得;引起(注意.想像.兴趣)n.捕获;占领;捕获物;[计算机]捕捉 hence adv. 从此;因 ...
- 《Convolutional Neural Network Architectures for Matching Natural Language Sentences》句子匹配
模型结构与原理 1. 基于CNN的句子建模 这篇论文主要针对的是句子匹配(Sentence Matching)的问题,但是基础问题仍然是句子建模.首先,文中提出了一种基于CNN的句子建模网络,如下图: ...
- Parsing Natural Scenes and Natural Language with Recursive Neural Networks-paper
Parsing Natural Scenes and Natural Language with Recursive Neural Networks作者信息: Richard Socher richa ...
- 《Enhanced LSTM for Natural Language Inference》(自然语言推理)
解决的问题 自然语言推理,判断a是否可以推理出b.简单讲就是判断2个句子ab是否有相同的含义. 方法 我们的自然语言推理网络由以下部分组成:输入编码(Input Encoding ),局部推理模型(L ...
- 如何将 Cortana 与 Windows Phone 8.1 应用集成 ( Voice command - Natural language recognition )
随着 Windows Phone 8.1 GDR1 + Cortana 中文版的发布,相信有很多用户或开发者都在调戏 Windows Phone 的语音私人助理 Cortana 吧,在世界杯的时候我亲 ...
- Natural language style method declaration and usages in programming languages
More descriptive way to declare and use a method in programming languages At present, in most progra ...
- Natural Language Processing with Python - Chapter 0
一年之前,我做梦也想不到会来这里写技术总结.误打误撞来到了上海西南某高校,成为了文科专业的工科男,现在每天除了膜ha,就是恶补CS.导师是做计算语言学的,所以当务之急就是先自学计算机自然语言处理,打好 ...
随机推荐
- Python之介绍、基本语法、流程控制
本节内容 Python介绍 发展史 Python 2 or 3? 安装 Hello World程序 变量 用户输入 模块初识 .pyc是个什么鬼? 数据类型初识 数据运算 表达式if ...else语 ...
- networkX.core_number(graph)
今天在学习别人特征工程的时候,看到这样一个函数,max_kcore = pd.DataFrame(list(nx.core_number(graph).items()), columns=[" ...
- Apache Avro & Avro Schema简介
为什么需要schema registry? 首先我们知道: Kafka将字节作为输入并发布 没有数据验证 但是: 如果Producer发送了bad data怎么办? 如果字段被重命名怎么办? 如果数据 ...
- 为什么大家都在用Fiddler?
在我们做接口测试的时候,经常需要验证发送的消息是否正确,或者在出现问题的时候,查看手机客户端发送给server端的包内容是否正确,就需要用到抓包工具.常用的抓包工具有fiddler.wireshark ...
- eclipse的使用小技能
eclipse的使用小技能 文章来源:http://blog.csdn.net/ljfbest/article/details/7465003 关于eclipse的使用方面,其实有些东西都是小技巧的东 ...
- Ethical Hacking - Web Penetration Testing(8)
SQL INJECTION WHAT IS SQL? Most websites use a database to store data. Most data stored in it(userna ...
- OSCP Learning Notes - Exploit(5)
Java Applet Attacks Download virtual machines from the following website: https://developer.microsof ...
- .NET 使用sock5做代理(不是搭建服务端)
在日常开发中经常会遇到这些需求,爬取数据,都知道现在通常用python爬取是很方便的,但是免不了还有很多伙伴在用NET来爬取,在爬取数据的时候我们知道需要使用代理服务器,如果不用代理,你的IP很有可能 ...
- Spring RestTemplate 的介绍和使用-入门
RestTemplate是什么? 传统情况下在java代码里访问restful服务,一般使用Apache的HttpClient.不过此种方法使用起来太过繁琐.spring提供了一种简单便捷的模板类来进 ...
- 【日常摘要】- RabbitMq实现延时队列
简介 什么是延时队列? 一种带有延迟功能的消息队列 过程: 使用场景 比如存在某个业务场景 发起一个订单,但是处于未支付的状态?如何及时的关闭订单并退还库存? 如何定期检查处于退款订单是否已经成功退款 ...