改造xxl-job的客户端日志文件生成体系
为什么要改造XXL-JOB原有的日志文件生成体系
xxl-job原本自己的客户端日志文件生成策略是:一个日志记录就生成一个文件,也就是当数据库存在一条日志logId,对应的客户端就会生成一个文件,由于定时任务跑批很多,并且有些任务间隔时间很短,比如几秒触发一次,这样的结果就是客户端会生成大量的文件,但是每个文件的内容其实不多,但大量的单独文件相比会占用更多的磁盘,造成磁盘资源紧张,长久以来,就会触发资源报警,所以,如果不想经常去清理日志文件的话,那么将零碎的文件通过某种方式进行整合就显得迫切需要了。
本文篇幅较长,代码涉及较多啦~
改造后的日志文件生成策略
基本描述
减少日志文件个数,其实就是要将分散的日志文件进行合并,同时建立外部索引文件维护各自当次日志Id所对应的起始日志内容。在读取的时候先通过读取索引文件,进而再读取真实的日志内容。
下面是日志文件描述分析图:
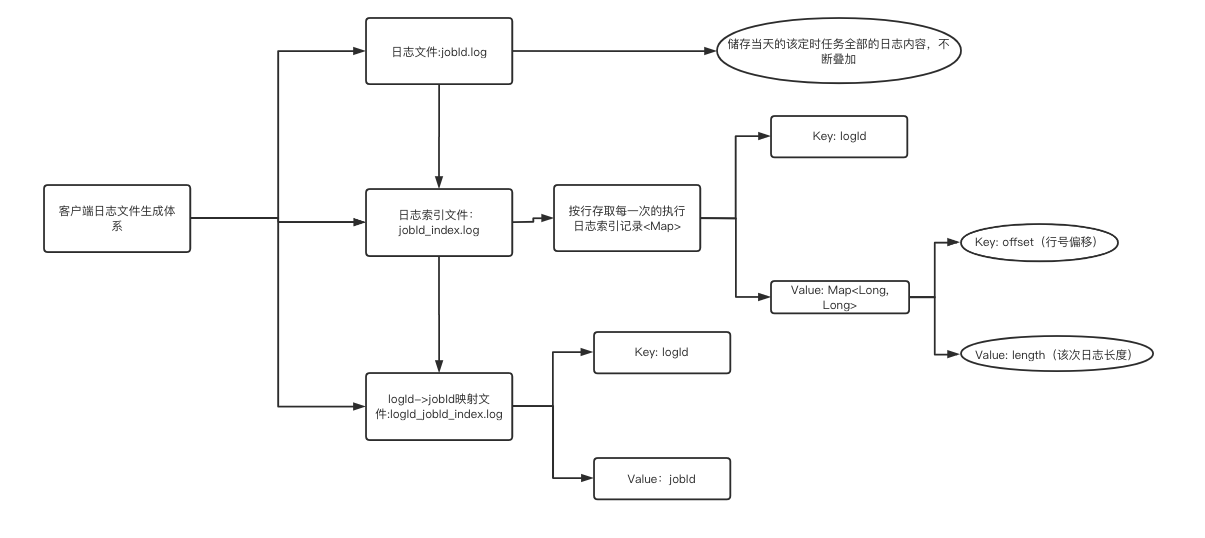
对于一个执行器,在执行器下的所有的定时任务每天只生成一个logId_jobId_index.log的索引文件,用来维护日志Id与任务Id的对应关系;
对于一个定时任务,每天只生成一个jobId.log的日志内容文件,里面保存当天所有的日志内容;
对于日志索引文件jobId_index.log,用来维护日志内容中的索引,便于知道jobId.log中对应行数是属于哪个logId的,便于查找。
大致思路就是如此,可以预期,日志文件大大的减少,磁盘占用应该会得到改善.
笔者改造的这个功能已经在线上跑了快接近一年了,目前暂未出现问题,如有需要可结合自身业务进行相应的调整与改造,以及认真测试,以防未知错误。
代码实操
本文改造是基于XXL-JOB 1.8.2 版本改造,其他版本暂未实验
打开代码目录xxl-job-core模块,主要涉及以下几个文件的改动:
- XxlJobFileAppender.java
- XxlJobLogger.java
- JobThread.java
- ExecutorBizImpl.java
- LRUCacheUtil.java
XxlJobFileAppender.java
代码中部分原有未涉及改动的方法此处不再粘贴。
package com.xxl.job.core.log;
import com.xxl.job.core.biz.model.LogResult;
import com.xxl.job.core.util.LRUCacheUtil;
import org.apache.commons.io.FilenameUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.util.StringUtils;
import java.io.*;
import java.text.DecimalFormat;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.HashMap;
import java.util.Map;
import java.util.regex.Pattern;
/**
* store trigger log in each log-file
* @author xuxueli 2016-3-12 19:25:12
*/
public class XxlJobFileAppender {
private static Logger logger = LoggerFactory.getLogger(XxlJobFileAppender.class);
// for JobThread (support log for child thread of job handler)
//public static ThreadLocal<String> contextHolder = new ThreadLocal<String>();
public static final InheritableThreadLocal<String> contextHolder = new InheritableThreadLocal<String>();
// for logId,记录日志Id
public static final InheritableThreadLocal<Integer> contextHolderLogId = new InheritableThreadLocal<>();
// for JobId,定时任务的Id
public static final InheritableThreadLocal<Integer> contextHolderJobId = new InheritableThreadLocal<>();
// 使用一个缓存map集合来存取索引偏移量信息
public static final LRUCacheUtil<Integer, Map<String ,Long>> indexOffsetCacheMap = new LRUCacheUtil<>(80);
private static final String DATE_FOMATE = "yyyy-MM-dd";
private static final String UTF_8 = "utf-8";
// 文件名后缀
private static final String FILE_SUFFIX = ".log";
private static final String INDEX_SUFFIX = "_index";
private static final String LOGID_JOBID_INDEX_SUFFIX = "logId_jobId_index";
private static final String jobLogIndexKey = "jobLogIndexOffset";
private static final String indexOffsetKey = "indexOffset";
/**
* log base path
*
* strut like:
* ---/
* ---/gluesource/
* ---/gluesource/10_1514171108000.js
* ---/gluesource/10_1514171108000.js
* ---/2017-12-25/
* ---/2017-12-25/639.log
* ---/2017-12-25/821.log
*
*/
private static String logBasePath = "/data/applogs/xxl-job/jobhandler";
private static String glueSrcPath = logBasePath.concat("/gluesource");
public static void initLogPath(String logPath){
// init
if (logPath!=null && logPath.trim().length()>0) {
logBasePath = logPath;
}
// mk base dir
File logPathDir = new File(logBasePath);
if (!logPathDir.exists()) {
logPathDir.mkdirs();
}
logBasePath = logPathDir.getPath();
// mk glue dir
File glueBaseDir = new File(logPathDir, "gluesource");
if (!glueBaseDir.exists()) {
glueBaseDir.mkdirs();
}
glueSrcPath = glueBaseDir.getPath();
}
public static String getLogPath() {
return logBasePath;
}
public static String getGlueSrcPath() {
return glueSrcPath;
}
/**
* 重写生成日志目录和日志文件名的方法:
* log filename,like "logPath/yyyy-MM-dd/jobId.log"
* @param triggerDate
* @param jobId
* @return
*/
public static String makeLogFileNameByJobId(Date triggerDate, int jobId) {
// filePath/yyyy-MM-dd
// avoid concurrent problem, can not be static
SimpleDateFormat sdf = new SimpleDateFormat(DATE_FOMATE);
File logFilePath = new File(getLogPath(), sdf.format(triggerDate));
if (!logFilePath.exists()) {
logFilePath.mkdir();
}
// 生成日志索引文件
String logIndexFileName = logFilePath.getPath()
.concat("/")
.concat(String.valueOf(jobId))
.concat(INDEX_SUFFIX)
.concat(FILE_SUFFIX);
File logIndexFilePath = new File(logIndexFileName);
if (!logIndexFilePath.exists()) {
try {
logIndexFilePath.createNewFile();
logger.debug("生成日志索引文件,文件路径:{}", logIndexFilePath);
} catch (IOException e) {
logger.error(e.getMessage(), e);
}
}
// 在yyyy-MM-dd文件夹下生成当天的logId对应的jobId的全局索引,减少对后管的修改
String logIdJobIdIndexFileName = logFilePath.getPath()
.concat("/")
.concat(LOGID_JOBID_INDEX_SUFFIX)
.concat(FILE_SUFFIX);
File logIdJobIdIndexFileNamePath = new File(logIdJobIdIndexFileName);
if (!logIdJobIdIndexFileNamePath.exists()) {
try {
logIdJobIdIndexFileNamePath.createNewFile();
logger.debug("生成logId与jobId的索引文件,文件路径:{}", logIdJobIdIndexFileNamePath);
} catch (IOException e) {
logger.error(e.getMessage(), e);
}
}
// filePath/yyyy-MM-dd/jobId.log log日志文件
String logFileName = logFilePath.getPath()
.concat("/")
.concat(String.valueOf(jobId))
.concat(FILE_SUFFIX);
return logFileName;
}
/**
* 后管平台读取详细日志查看,生成文件名
* admin read log, generate logFileName bu logId
* @param triggerDate
* @param logId
* @return
*/
public static String makeFileNameForReadLog(Date triggerDate, int logId) {
// filePath/yyyy-MM-dd
SimpleDateFormat sdf = new SimpleDateFormat(DATE_FOMATE);
File logFilePath = new File(getLogPath(), sdf.format(triggerDate));
if (!logFilePath.exists()) {
logFilePath.mkdir();
}
String logIdJobIdFileName = logFilePath.getPath().concat("/")
.concat(LOGID_JOBID_INDEX_SUFFIX)
.concat(FILE_SUFFIX);
// find logId->jobId mapping
// 获取索引映射
String infoLine = readIndex(logIdJobIdFileName, logId);
String[] arr = infoLine.split("->");
int jobId = 0;
try {
jobId = Integer.parseInt(arr[1]);
} catch (Exception e) {
logger.error("makeFileNameForReadLog StringArrayException,{},{}", e.getMessage(), e);
throw new RuntimeException("StringArrayException");
}
String logFileName = logFilePath.getPath().concat("/")
.concat(String.valueOf(jobId)).concat(FILE_SUFFIX);
return logFileName;
}
/**
* 向日志文件中追加内容,向索引文件中追加索引
* append log
* @param logFileName
* @param appendLog
*/
public static void appendLogAndIndex(String logFileName, String appendLog) {
// log file
if (logFileName == null || logFileName.trim().length() == 0) {
return;
}
File logFile = new File(logFileName);
if (!logFile.exists()) {
try {
logFile.createNewFile();
} catch (Exception e) {
logger.error(e.getMessage(), e);
return;
}
}
// start append, count line num
long startLineNum = countFileLineNum(logFileName);
logger.debug("开始追加日志文件,开始行数:{}", startLineNum);
// log
if (appendLog == null) {
appendLog = "";
}
appendLog += "\r\n";
// append file content
try {
FileOutputStream fos = null;
try {
fos = new FileOutputStream(logFile, true);
fos.write(appendLog.getBytes("utf-8"));
fos.flush();
} finally {
if (fos != null) {
try {
fos.close();
} catch (IOException e) {
logger.error(e.getMessage(), e);
}
}
}
} catch (Exception e) {
logger.error(e.getMessage(), e);
}
// end append, count line num,再次计数
long endLineNum = countFileLineNum(logFileName);
Long lengthTmp = endLineNum - startLineNum;
int length = 0;
try {
length = lengthTmp.intValue();
} catch (Exception e) {
logger.error("Long to int Exception", e);
}
logger.debug("结束追加日志文件,结束行数:{}, 长度:{}", endLineNum, length);
Map<String, Long> indexOffsetMap = new HashMap<>();
appendIndexLog(logFileName, startLineNum, length, indexOffsetMap);
appendLogIdJobIdFile(logFileName, indexOffsetMap);
}
/**
* 创建日志Id与JobId的映射关系
* @param logFileName
* @param indexOffsetMap
*/
public static void appendLogIdJobIdFile(String logFileName, Map indexOffsetMap) {
// 获取ThreadLocal中变量保存的值
int logId = XxlJobFileAppender.contextHolderLogId.get();
int jobId = XxlJobFileAppender.contextHolderJobId.get();
File file = new File(logFileName);
// 获取父级目录,寻找同文件夹下的索引文件
String parentDirName = file.getParent();
// logId_jobId_index fileName
String logIdJobIdIndexFileName = parentDirName.concat("/")
.concat(LOGID_JOBID_INDEX_SUFFIX)
.concat(FILE_SUFFIX);
// 从缓存中获取logId
boolean jobLogIndexOffsetExist = indexOffsetCacheMap.exists(logId);
Long jobLogIndexOffset = null;
if (jobLogIndexOffsetExist) {
jobLogIndexOffset = indexOffsetCacheMap.get(logId).get(jobLogIndexKey);
}
if (jobLogIndexOffset == null) {
// 为空则添加
StringBuffer stringBuffer = new StringBuffer();
stringBuffer.append(logId).append("->").append(jobId).append("\r\n");
Long currentPoint = getAfterAppendIndexLog(logIdJobIdIndexFileName, stringBuffer.toString());
indexOffsetMap.put(jobLogIndexKey, currentPoint);
indexOffsetCacheMap.save(logId, indexOffsetMap);
}
// 不为空说明缓存已经存在,不做其他处理
}
/**
* 追加索引文件内容,返回偏移量
* @param fileName
* @param content
* @return
*/
private static Long getAfterAppendIndexLog(String fileName, String content) {
RandomAccessFile raf = null;
Long point = null;
try {
raf = new RandomAccessFile(fileName, "rw");
long end = raf.length();
// 因为是追加内容,所以将指针放入到文件的末尾
raf.seek(end);
raf.writeBytes(content);
// 获取当前的指针偏移量
/**
* 偏移量放入到缓存变量中:注意,此处获取偏移量,是获取开始的地方的偏移量,不能再追加内容后再获取,否则会获取到结束
* 时的偏移量
*/
point = end;
} catch (IOException e) {
logger.error(e.getMessage(), e);
} finally {
try {
raf.close();
} catch (IOException e) {
logger.error(e.getMessage(), e);
}
}
return point;
}
/**
* 追加索引日志,like "345->(577,10)"
* @param logFileName
* @param from
* @param length
* @param indexOffsetMap
*/
public static void appendIndexLog(String logFileName, Long from, int length, Map indexOffsetMap) {
int strLength = logFileName.length();
// 通过截取获取索引文件名
String prefixFilePath = logFileName.substring(0, strLength - 4);
String logIndexFilePath = prefixFilePath.concat(INDEX_SUFFIX).concat(FILE_SUFFIX);
File logIndexFile = new File(logIndexFilePath);
if (!logIndexFile.exists()) {
try {
logIndexFile.createNewFile();
} catch (IOException e) {
logger.error(e.getMessage(), e);
return;
}
}
int logId = XxlJobFileAppender.contextHolderLogId.get();
StringBuffer stringBuffer = new StringBuffer();
// 判断是添加还是修改
boolean indexOffsetExist = indexOffsetCacheMap.exists(logId);
Long indexOffset = null;
if (indexOffsetExist) {
indexOffset = indexOffsetCacheMap.get(logId).get(indexOffsetKey);
}
if (indexOffset == null) {
// append
String lengthStr = getFormatNum(length);
stringBuffer.append(logId).append("->(")
.append(from).append(",").append(lengthStr).append(")\r\n");
// 添加新的索引,记录偏移量
Long currentIndexPoint = getAfterAppendIndexLog(logIndexFilePath, stringBuffer.toString());
indexOffsetMap.put(indexOffsetKey, currentIndexPoint);
} else {
String infoLine = getIndexLineIsExist(logIndexFilePath, logId);
// 修改索引文件内容
int startTmp = infoLine.indexOf("(");
int endTmp = infoLine.indexOf(")");
String[] lengthTmp = infoLine.substring(startTmp + 1, endTmp).split(",");
int lengthTmpInt = 0;
try {
lengthTmpInt = Integer.parseInt(lengthTmp[1]);
from = Long.valueOf(lengthTmp[0]);
} catch (Exception e) {
logger.error("appendIndexLog StringArrayException,{},{}", e.getMessage(), e);
throw new RuntimeException("StringArrayException");
}
int modifyLength = length + lengthTmpInt;
String lengthStr2 = getFormatNum(modifyLength);
stringBuffer.append(logId).append("->(")
.append(from).append(",").append(lengthStr2).append(")\r\n");
modifyIndexFileContent(logIndexFilePath, infoLine, stringBuffer.toString());
}
}
/**
* handle getFormatNum
* like 5 to 005
* @return
*/
private static String getFormatNum(int num) {
DecimalFormat df = new DecimalFormat("000");
String str1 = df.format(num);
return str1;
}
/**
* 查询索引是否存在
* @param filePath
* @param logId
* @return
*/
private static String getIndexLineIsExist(String filePath, int logId) {
// 读取索引问价判断是否存在,日志每生成一行就会调用一次,所以索引文件需要将同一个logId对应的进行合并
String prefix = logId + "->";
Pattern pattern = Pattern.compile(prefix + ".*?");
String indexInfoLine = "";
RandomAccessFile raf = null;
try {
raf = new RandomAccessFile(filePath, "rw");
String tmpLine = null;
// 偏移量
boolean indexOffsetExist = indexOffsetCacheMap.exists(logId);
Long cachePoint = null;
if (indexOffsetExist) {
cachePoint = indexOffsetCacheMap.get(logId).get(indexOffsetKey);
}
if (null == cachePoint) {
cachePoint = Long.valueOf(0);
}
raf.seek(cachePoint);
while ((tmpLine = raf.readLine()) != null) {
final long point = raf.getFilePointer();
boolean matchFlag = pattern.matcher(tmpLine).find();
if (matchFlag) {
indexInfoLine = tmpLine;
break;
}
cachePoint = point;
}
} catch (IOException e) {
logger.error(e.getMessage(), e);
} finally {
try {
raf.close();
} catch (IOException e) {
logger.error(e.getMessage(), e);
}
}
return indexInfoLine;
}
/**
* 在后管页面上需要查询执行日志的时候,获取索引信息,
* 此处不能与上个通用,因为读取时没有map存取偏移量信息,相对隔离
* @param filePath
* @param logId
* @return
*/
private static String readIndex(String filePath, int logId) {
filePath = FilenameUtils.normalize(filePath);
String prefix = logId + "->";
Pattern pattern = Pattern.compile(prefix + ".*?");
String indexInfoLine = "";
BufferedReader bufferedReader = null;
try {
bufferedReader = new BufferedReader(new FileReader(filePath));
String tmpLine = null;
while ((tmpLine = bufferedReader.readLine()) != null) {
boolean matchFlag = pattern.matcher(tmpLine).find();
if (matchFlag) {
indexInfoLine = tmpLine;
break;
}
}
bufferedReader.close();
} catch (IOException e) {
logger.error(e.getMessage(), e);
} finally {
if (bufferedReader != null) {
try {
bufferedReader.close();
} catch (IOException e) {
logger.error(e.getMessage(), e);
}
}
}
return indexInfoLine;
}
/**
* 修改 logIndexFile 内容
* @param indexFileName
* @param oldContent
* @param newContent
* @return
*/
private static boolean modifyIndexFileContent(String indexFileName, String oldContent, String newContent) {
RandomAccessFile raf = null;
int logId = contextHolderLogId.get();
try {
raf = new RandomAccessFile(indexFileName, "rw");
String tmpLine = null;
// 偏移量
boolean indexOffsetExist = indexOffsetCacheMap.exists(logId);
Long cachePoint = null;
if (indexOffsetExist) {
cachePoint = indexOffsetCacheMap.get(logId).get(indexOffsetKey);
}
if (null == cachePoint) {
cachePoint = Long.valueOf(0);
}
raf.seek(cachePoint);
while ((tmpLine = raf.readLine()) != null) {
final long point = raf.getFilePointer();
if (tmpLine.contains(oldContent)) {
String str = tmpLine.replace(oldContent, newContent);
raf.seek(cachePoint);
raf.writeBytes(str);
}
cachePoint = point;
}
} catch (IOException e) {
logger.error(e.getMessage(), e);
} finally {
try {
raf.close();
} catch (IOException e) {
logger.error(e.getMessage(), e);
}
}
return true;
}
/**
* 统计文件内容行数
* @param logFileName
* @return
*/
private static long countFileLineNum(String logFileName) {
File file = new File(logFileName);
if (file.exists()) {
try {
FileReader fileReader = new FileReader(file);
LineNumberReader lineNumberReader = new LineNumberReader(fileReader);
lineNumberReader.skip(Long.MAX_VALUE);
// getLineNumber() 从0开始计数,所以加1
long totalLines = lineNumberReader.getLineNumber() + 1;
fileReader.close();
lineNumberReader.close();
return totalLines;
} catch (IOException e) {
logger.error(e.getMessage(), e);
}
}
return 0;
}
/**
* 重写读取日志:1. 读取logIndexFile;2.logFile
* @param logFileName
* @param logId
* @param fromLineNum
* @return
*/
public static LogResult readLogByIndex(String logFileName, int logId, int fromLineNum) {
int strLength = logFileName.length();
// 获取文件名前缀出去.log
String prefixFilePath = logFileName.substring(0, strLength-4);
String logIndexFilePath = prefixFilePath.concat(INDEX_SUFFIX).concat(FILE_SUFFIX);
// valid logIndex file
if (StringUtils.isEmpty(logIndexFilePath)) {
return new LogResult(fromLineNum, 0, "readLogByIndex fail, logIndexFile not found", true);
}
logIndexFilePath = FilenameUtils.normalize(logIndexFilePath);
File logIndexFile = new File(logIndexFilePath);
if (!logIndexFile.exists()) {
return new LogResult(fromLineNum, 0, "readLogByIndex fail, logIndexFile not exists", true);
}
// valid log file
if (StringUtils.isEmpty(logFileName)) {
return new LogResult(fromLineNum, 0, "readLogByIndex fail, logFile not found", true);
}
logFileName = FilenameUtils.normalize(logFileName);
File logFile = new File(logFileName);
if (!logFile.exists()) {
return new LogResult(fromLineNum, 0, "readLogByIndex fail, logFile not exists", true);
}
// read logIndexFile
String indexInfo = readIndex(logIndexFilePath, logId);
int startNum = 0;
int endNum = 0;
if (!StringUtils.isEmpty(indexInfo)) {
int startTmp = indexInfo.indexOf("(");
int endTmp = indexInfo.indexOf(")");
String[] fromAndTo = indexInfo.substring(startTmp + 1, endTmp).split(",");
try {
startNum = Integer.parseInt(fromAndTo[0]);
endNum = Integer.parseInt(fromAndTo[1]) + startNum;
} catch (Exception e) {
logger.error("readLogByIndex StringArrayException,{},{}", e.getMessage(), e);
throw new RuntimeException("StringArrayException");
}
}
// read File
StringBuffer logContentBuffer = new StringBuffer();
int toLineNum = 0;
LineNumberReader reader = null;
try {
reader = new LineNumberReader(new InputStreamReader(new FileInputStream(logFile), UTF_8));
String line = null;
while ((line = reader.readLine()) != null) {
// [from, to], start as fromNum(logIndexFile)
toLineNum = reader.getLineNumber();
if (toLineNum >= startNum && toLineNum < endNum) {
logContentBuffer.append(line).append("\n");
}
// break when read over
if (toLineNum >= endNum) {
break;
}
}
} catch (IOException e) {
logger.error(e.getMessage(), e);
} finally {
if (reader != null) {
try {
reader.close();
} catch (IOException e) {
logger.error(e.getMessage(), e);
}
}
}
LogResult logResult = new LogResult(fromLineNum, toLineNum, logContentBuffer.toString(), false);
return logResult;
}
}
XxlJobLogger.java
package com.xxl.job.core.log;
import com.xxl.job.core.util.DateUtil;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.slf4j.helpers.FormattingTuple;
import org.slf4j.helpers.MessageFormatter;
import java.io.PrintWriter;
import java.io.StringWriter;
import java.util.Date;
/**
* Created by xuxueli on 17/4/28.
*/
public class XxlJobLogger {
private static Logger logger = LoggerFactory.getLogger("xxl-job logger");
/**
* append log
*
* @param callInfo
* @param appendLog
*/
private static void logDetail(StackTraceElement callInfo, String appendLog) {
/*// "yyyy-MM-dd HH:mm:ss [ClassName]-[MethodName]-[LineNumber]-[ThreadName] log";
StackTraceElement[] stackTraceElements = new Throwable().getStackTrace();
StackTraceElement callInfo = stackTraceElements[1];*/
StringBuffer stringBuffer = new StringBuffer();
stringBuffer.append(DateUtil.formatDateTime(new Date())).append(" ")
.append("["+ callInfo.getClassName() + "#" + callInfo.getMethodName() +"]").append("-")
.append("["+ callInfo.getLineNumber() +"]").append("-")
.append("["+ Thread.currentThread().getName() +"]").append(" ")
.append(appendLog!=null?appendLog:"");
String formatAppendLog = stringBuffer.toString();
// appendlog
String logFileName = XxlJobFileAppender.contextHolder.get();
if (logFileName!=null && logFileName.trim().length()>0) {
// XxlJobFileAppender.appendLog(logFileName, formatAppendLog);
// 此处修改方法调用
// modify appendLogAndIndex for addIndexLogInfo
XxlJobFileAppender.appendLogAndIndex(logFileName, formatAppendLog);
} else {
logger.info(">>>>>>>>>>> {}", formatAppendLog);
}
}
}
JobThread.java
@Override
public void run() {
......
// execute
while(!toStop){
running = false;
idleTimes++;
TriggerParam triggerParam = null;
ReturnT<String> executeResult = null;
try {
// to check toStop signal, we need cycle, so wo cannot use queue.take(), instand of poll(timeout)
triggerParam = triggerQueue.poll(3L, TimeUnit.SECONDS);
if (triggerParam!=null) {
running = true;
idleTimes = 0;
triggerLogIdSet.remove(triggerParam.getLogId());
// log filename, like "logPath/yyyy-MM-dd/9999.log"
// String logFileName = XxlJobFileAppender.makeLogFileName(new Date(triggerParam.getLogDateTim()), triggerParam.getLogId());
// modify 将生成的日志文件重新命名,以jobId命名
String logFileName = XxlJobFileAppender.makeLogFileNameByJobId(new Date(triggerParam.getLogDateTim()), triggerParam.getJobId());
XxlJobFileAppender.contextHolderJobId.set(triggerParam.getJobId());
// 此处根据xxl-job版本号做修改
XxlJobFileAppender.contextHolderLogId.set(Integer.parseInt(String.valueOf(triggerParam.getLogId())));
XxlJobFileAppender.contextHolder.set(logFileName);
ShardingUtil.setShardingVo(new ShardingUtil.ShardingVO(triggerParam.getBroadcastIndex(), triggerParam.getBroadcastTotal()));
......
}
ExecutorBizImpl.java
package com.xxl.job.core.biz.impl;
import com.xxl.job.core.biz.ExecutorBiz;
import com.xxl.job.core.biz.model.LogResult;
import com.xxl.job.core.biz.model.ReturnT;
import com.xxl.job.core.biz.model.TriggerParam;
import com.xxl.job.core.enums.ExecutorBlockStrategyEnum;
import com.xxl.job.core.executor.XxlJobExecutor;
import com.xxl.job.core.glue.GlueFactory;
import com.xxl.job.core.glue.GlueTypeEnum;
import com.xxl.job.core.handler.IJobHandler;
import com.xxl.job.core.handler.impl.GlueJobHandler;
import com.xxl.job.core.handler.impl.ScriptJobHandler;
import com.xxl.job.core.log.XxlJobFileAppender;
import com.xxl.job.core.thread.JobThread;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Date;
/**
* Created by xuxueli on 17/3/1.
*/
public class ExecutorBizImpl implements ExecutorBiz {
private static Logger logger = LoggerFactory.getLogger(ExecutorBizImpl.class);
/**
* 重写读取日志方法
* @param logDateTim
* @param logId
* @param fromLineNum
* @return
*/
@Override
public ReturnT<LogResult> log(long logDateTim, long logId, int fromLineNum) {
// log filename: logPath/yyyy-MM-dd/9999.log
String logFileName = XxlJobFileAppender.makeFileNameForReadLog(new Date(logDateTim), (int)logId);
LogResult logResult = XxlJobFileAppender.readLogByIndex(logFileName, Integer.parseInt(String.valueOf(logId)), fromLineNum);
return new ReturnT<LogResult>(logResult);
}
}
LRUCacheUtil.java
通过LinkedHashMap实现一个缓存容器
package com.xxl.job.core.util;
import java.util.LinkedHashMap;
import java.util.Map;
/**
* @Author: liangxuanhao
* @Description: 使用LinkedHashMap实现一个固定大小的缓存器
* @Date:
*/
public class LRUCacheUtil<K, V> extends LinkedHashMap<K, V> {
// 最大缓存容量
private static final int CACHE_MAX_SIZE = 100;
private int limit;
public LRUCacheUtil() {
this(CACHE_MAX_SIZE);
}
public LRUCacheUtil(int cacheSize) {
// true表示更新到末尾
super(cacheSize, 0.75f, true);
this.limit = cacheSize;
}
/**
* 加锁同步,防止多线程时出现多线程安全问题
*/
public synchronized V save(K key, V val) {
return put(key, val);
}
public V getOne(K key) {
return get(key);
}
public boolean exists(K key) {
return containsKey(key);
}
/**
* 判断是否超限
* @param elsest
* @return 超限返回true,否则返回false
*/
@Override
protected boolean removeEldestEntry(Map.Entry elsest) {
// 在put或者putAll方法后调用,超出容量限制,按照LRU最近最少未使用进行删除
return size() > limit;
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
for (Map.Entry<K, V> entry : entrySet()) {
sb.append(String.format("%s:%s ", entry.getKey(), entry.getValue()));
}
return sb.toString();
}
}
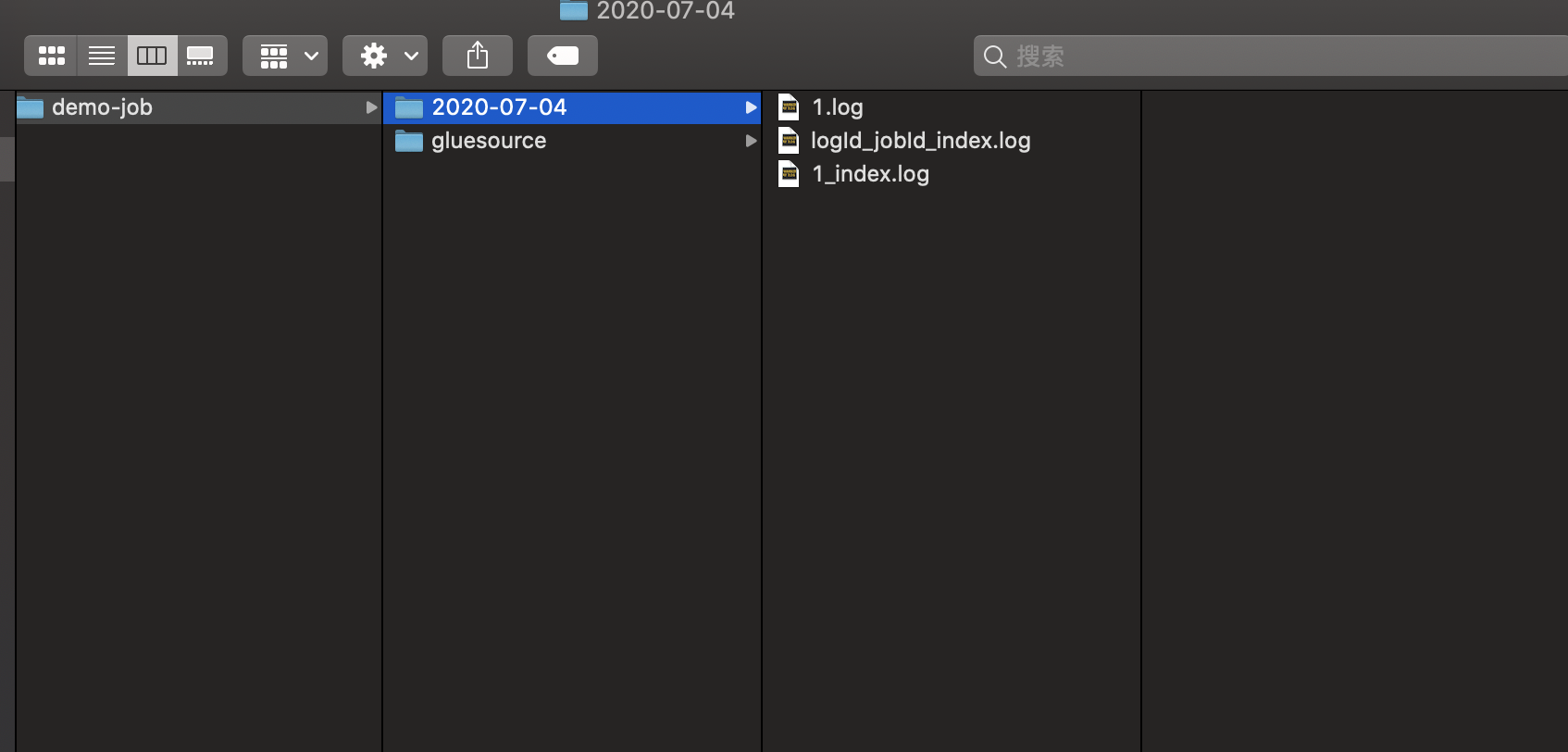
结果
执行效果如图所示:达到预期期望,且效果良好。
改造xxl-job的客户端日志文件生成体系的更多相关文章
- 使用已有的jmeter测试结果日志文件生成html报告
当并发数较大的时候,经常会出现测试结束后没有生成html报告的情况 解决办法: 测试结束后,使用生成的jmeter测试结果日志文件.jtl生成html报告 基本命令格式: jmeter -g < ...
- 屏蔽zencart logs文件夹下不断生成的日志文件
在根目錄下的logs文件夾中,經常生成一些錯誤文件類似myDEBUGxxxxx.log這樣的錯誤文件(而且這樣的錯誤文件由來并非網站出現什麽嚴重不可挽救的錯誤,大部分是一些未定義變量這樣的不起眼的小錯 ...
- Log4j使用笔记:每天生成一个日志文件、按日志大小生成文件
其中TestLog4j.java如下: package cn.zhoucy.test; import org.apache.log4j.Logger; public class TestLog4j { ...
- C# 开发 Windows 服务 使用Log4net 组件 不能生成日志文件
使用VS2012开发Windows服务,需要使用Log4net日志组件记录业务情况,但是始终生成不了日志文件. /// <summary> /// 入口方法 /// </summar ...
- SCCM2007日志文件
Microsoft System Center Configuration Manager 2007 中的所有客户端和站点服务器组件都将过程信息记录在单个日志文件中.您可以使用客户端和站点服务器日志文 ...
- ZENCART 打开/关闭日志文件
优秀的php开源程序很多都只带生成日志文件的功能,这类功能的开发可以帮助到站长在调试网站的时候及时的改正网站存在的错误,但是这类错误日志由来并非网站出现什么严重不可挽救的错误,大部分是一些未定义变量这 ...
- C#日志文件
写日志文件是一个很常用的功能,以前都是别人写好的,直接调用的,近期写了一个小工具,因为比较小,所以懒得引用dll文件了,直接上网找了一个,很方便,现在记录下 public class LogClass ...
- logback 指定每隔一段时间创建一个日志文件
我使用的logback版本是1.2.3 目前logback支持根据时间来配置产生日志文件,但是只支持每周,每天,每个小时,每分钟等创建一个文件,配置如下: <appender name=&quo ...
- PHP之编写日志文件留后门(免杀)
(我知道你们都喜欢干货,所以也没亏待你们,请到文末吧,成果附件已上传~) 本文原创作者:Laimooc(原名xoanHn) 鄙人宗旨: 本人秉着爱学习爱恶搞爱研究爱进步并且遵纪守法的心态写下这篇文章, ...
随机推荐
- js表单简单验证(手机号邮箱)
1 <%@ page language="java" contentType="text/html; charset=UTF-8" 2 pageEncod ...
- Linux 时间同步 05 chrony时间同步
Linux 时间同步 05 chrony时间同步 目录 Linux 时间同步 05 chrony时间同步 chrony 的优势: chrony包介绍 安装chrony 配置与外部时间服务器进行时间同步 ...
- Kubernetes官方java客户端之二:序列化和反序列化问题
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- laravel邮件发送
laravel邮件发送 使用邮件发送类Mail 文本 静态方法 raw() 富文本 静态方法 send() 注:使用邮件发送必须有邮件账号,需要开启smtp协议,现在主流服务器都支持,smtp默认端口 ...
- LeetCode841 钥匙和房间
有 N 个房间,开始时你位于 0 号房间.每个房间有不同的号码:0,1,2,...,N-1,并且房间里可能有一些钥匙能使你进入下一个房间. 在形式上,对于每个房间 i 都有一个钥匙列表 rooms[i ...
- 静默(命令行)安装oracle 11g
CentOS 6 静默安装oracle 11g 我参考的这个,他非常详细:https://blog.csdn.net/JIANG123456T/article/details/77745892 我只是 ...
- Vim 自动添加脚本头部信息
每次写脚本还在为忘记添加头部信息啥的烦恼? 按照下面这么做,帮你减轻点烦恼. # 打开配置文件: vim /root/.vimrc # 添加如下信息: autocmd BufNewFile *.sh ...
- Logrotate工具使用
Logrotate logrotate是一个被设计来简化系统管理日志文件的工具,在系统运行时,如果产生大量的日志文件,可以使用该工具进行管理,如/var/log/*文件夹是存储系统和应用日志的目录 ...
- 十二:SQL注入之简要注入
SQL注入漏洞将是重点漏洞,分为数据库类型,提交方法,数据类型等方式.此类漏洞是WEB漏洞中的核心漏洞,学习如何的利用,挖掘,和修复是重要的. SQL注入的危害 SQL注入的原理 可控变量,带入数据库 ...
- Jenkins+windows+.netcore+git+iis自动化部署入门
什么是自动化部署,就不介绍了,喜欢直接进入主题. 一. 所需环境: 1.系统为windows10 . 2.asp.net core3.1 runtime必须安装,因为我的代码是asp.net core ...