celery 基础教程(二):简单实例
前言
使用celery包含三个方面:1. 定义任务函数。2. 运行celery服务。3. 客户应用程序的调用。
实例一:
#1. 定义任务函数
创建一个文件 tasks.py输入下列代码:
- from celery import Celery #导入Celery
- broker = 'redis://127.0.0.1:6379/5' # 设置broker
- backend = 'redis://127.0.0.1:6379/6' # 设置backend
- app = Celery('tasks', broker=broker, backend=backend) # 实例化celery
- # 编写任务
- @app.task
- def add(x, y):
- return x + y
上述代码导入了celery,然后创建了celery 实例 app,实例化的过程中指定了任务名tasks(和文件名一致),传入了broker和backend。然后创建了一个任务函数add。
#2. 运行celery服务
下面启动celery服务。在当前命令行终端运行(分别在 env1 和 env2 下执行):
- celery -A tasks worker --loglevel=info
目录结构 (celery -A tasks worker --loglevel=info 这条命令当前工作目录必须和 tasks.py 所在的目录相同。即 进入tasks.py所在目录执行这条命令。)

使用 python 虚拟环境 模拟两个不同的 主机。
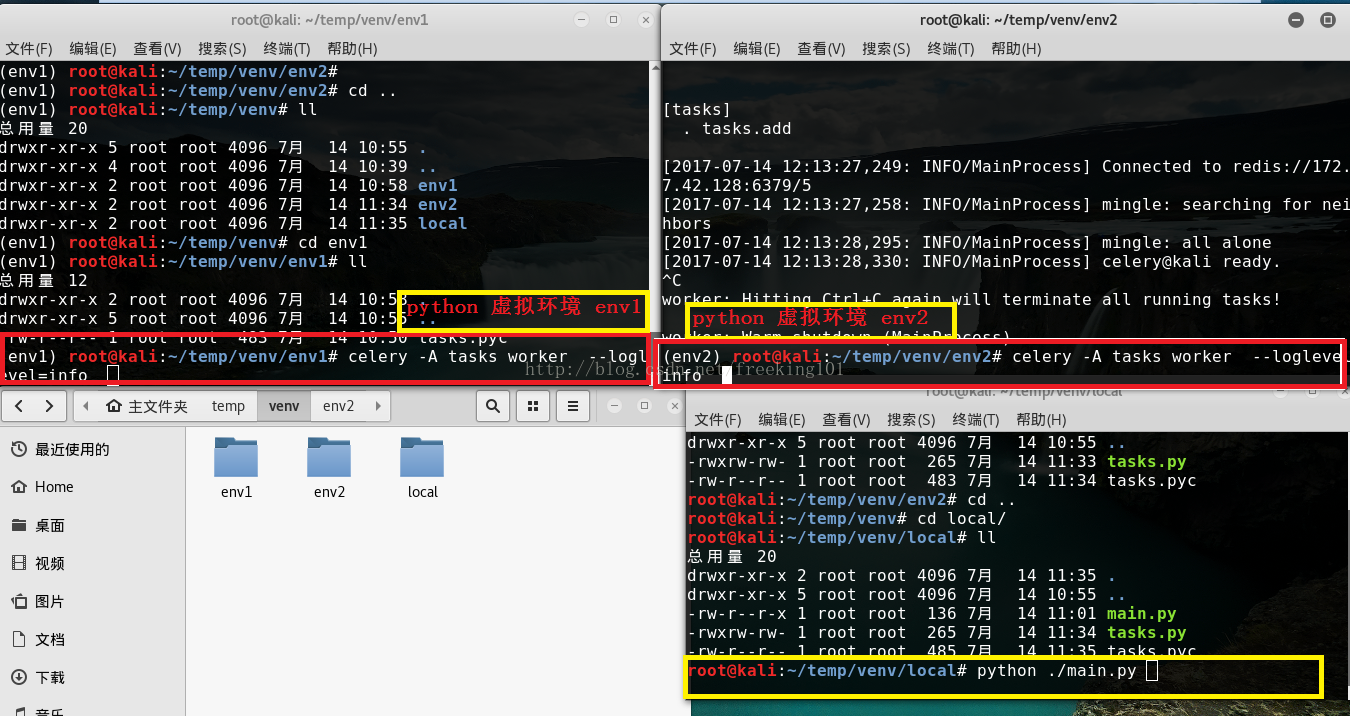
此时会看见一对输出。包括注册的任务啦。
#3. 客户应用程序的调用。
3.1 交互式客户端程序调用方法
打开一个命令行,进入Python环境。
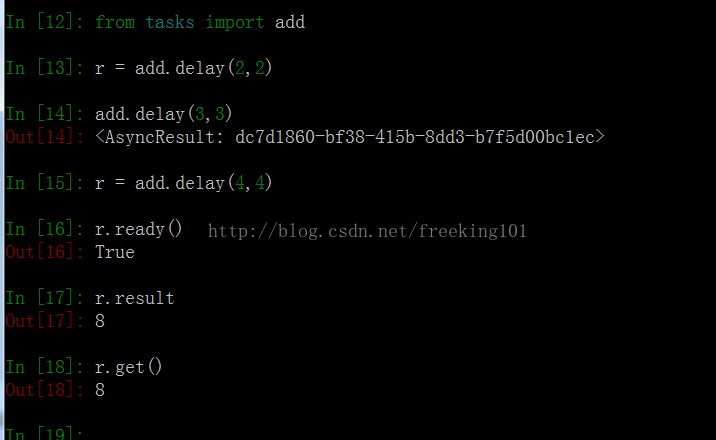
调用 delay 函数即可启动 add 这个任务。这个函数的效果是发送一条消息到broker中去,这个消息包括要执行的函数、函数的参数以及其他信息,具体的可以看 Celery官方文档。这个时候 worker 会等待 broker 中的消息,一旦收到消息就会立刻执行消息。
启动了一个任务之后,可以看到之前启动的worker已经开始执行任务了。

现在是在python环境中调用的add函数,实际上通常在应用程序中调用这个方法。
注意:如果把返回值赋值给一个变量,那么原来的应用程序也会被阻塞,需要等待异步任务返回的结果。因此,实际使用中,不需要把结果赋值。
3.2应用程序中调用方法
新建一个 main.py 文件 代码如下:
- from tasks import add
- r = add.delay(2, 2)
- r = add.delay(3, 3)
- print(r.ready())
- print(r.result)
- print(r.get())
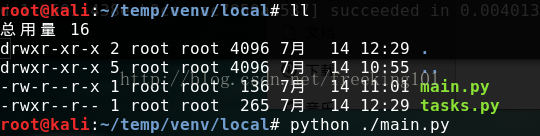
在celery命令行可以看见celery执行的日志。打开 backend的redis,也可以看见celery执行的信息。
实例二:
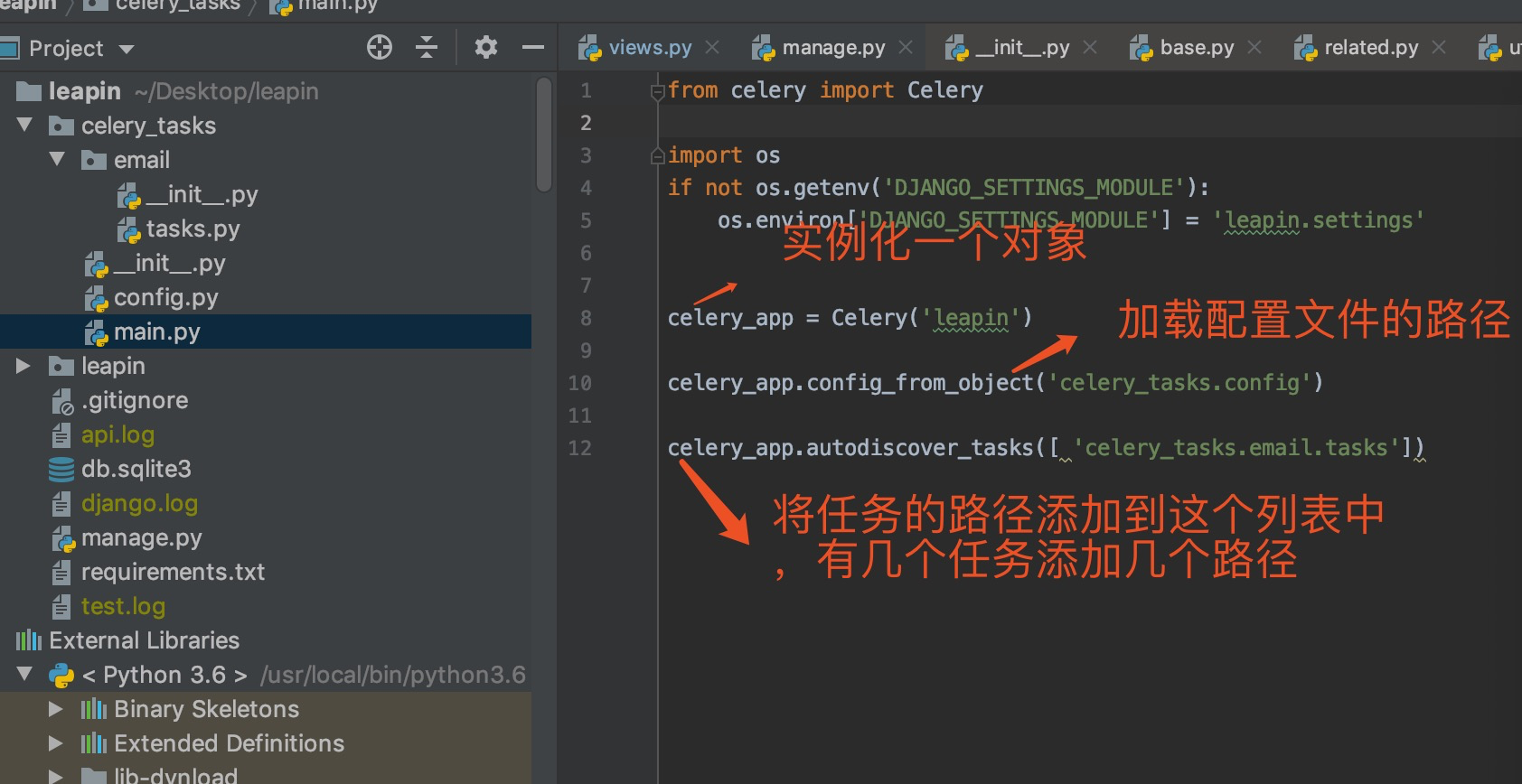
首先要有一个main文件
再者要有一个config文件
然后就是任务执行文件
如图 celery的目录

main.py 文件
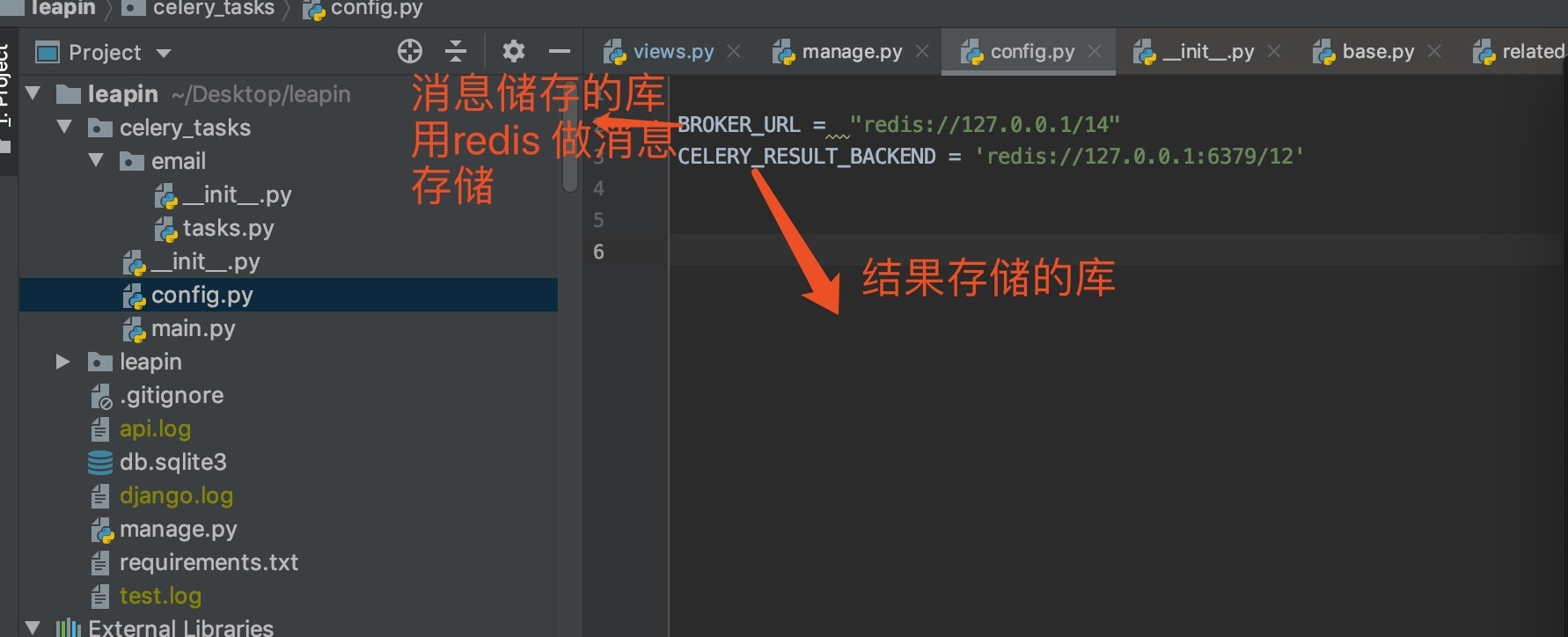
config.py文件
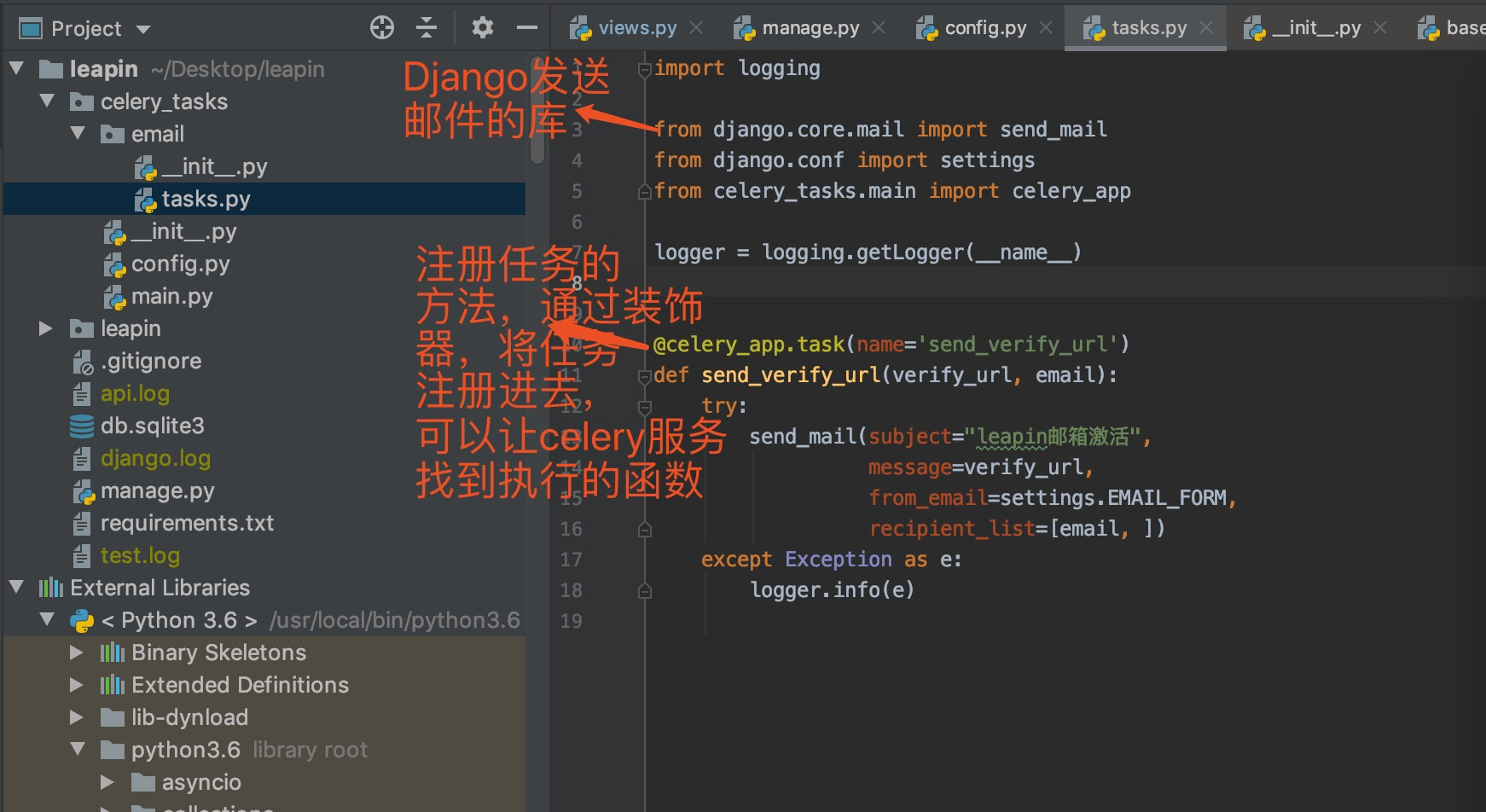
tasks.py文件
最后
celery服务的开启命令
celery -A celery_tasks.email.tasks worker -l info
注意:celery_tasks.email.tasks 是该函数执行的路径 填写正确才能启动celery服务
celery 基础教程(二):简单实例的更多相关文章
- celery 基础教程(三):配置
前言 如果你使用默认的加载器,你必须创建 celeryconfig.py 模块并且保证它在python路径中. 一.加载配置方法 1.基础方法 可以设置一些选项来改变 Celery 的工作方式.这 ...
- php分页原理教程及简单实例
<?php //连接数据库 $con = mysql_connect("localhost","root",""); mysql_se ...
- SpringCloud2.0 Eureka Server 服务中心 基础教程(二)
1.创建[服务中心],即 Eureka Server 1.1.新建 Spring Boot 工程,工程名称: springcloud-eureka-server 1.2.工程 pom.xml 文件添加 ...
- MySQL8.0数据库基础教程(二)-理解"关系"
1 SQL 的哲学 形如 Linux 哲学一切都是文件,在 SQL 领域也有这样一条至理名言 一切都是关系 2 关系数据库 所谓关系数据库(Relational database)是创建在关系模型基础 ...
- celery 基础教程(五):守护进程
一 守护进程方式启动 https://blog.csdn.net/p571912102/article/details/82735052 文件目录如下 . ├── config.py ├── main ...
- celery 基础教程(四):定时任务
简介 celery beat 是一个调度器:它以常规的时间间隔开启任务,任务将会在集群中的可用节点上运行. 默认情况下,入口项是从 beat_schedule 设置中获取,但是自定义的存储也可以使用, ...
- Java基础教程——二维数组
二维数组 Java里的二维数组其实是数组的数组,即每个数组元素都是一个数组. 每个数组的长度不要求一致,但最好一致. // 同样有两种风格的定义方法 int[][] _arr21_推荐 = { { 1 ...
- celery 基础教程(一):工作流程,架构以及概念
1.工作流程 celery通过消息进行通信,通常使用一个叫Broker(中间人)来协client(任务的发出者)和worker(任务的处理者). clients发出消息到队列中,broker将队列中的 ...
- numpy基础教程--二维数组的转置
使用numpy库可以快速将一个二维数组进行转置,方法有三种 1.使用numpy包里面的transpose()可以快速将一个二维数组转置 2.使用.T属性快速转置 3.使用swapaxes(1, 0)方 ...
随机推荐
- 如何在Centos7安装rabbitmq的PHP扩展
1.先安装rabbitmq-c, wget https://github.com/alanxz/rabbitmq-c/releases/download/v0.8.0/rabbitmq-c-0.8.0 ...
- 学习第一个python程序
打印9*9惩罚表 for i in range(1,10): for j in range(1,i+1): print(str(j)+"*"+str(i)+"=" ...
- cb52a_c++_STL_堆排序算法make_push_pop_sort_heap
cb52a_c++_STL_堆排序算法make_push_pop_sort_heapheapsort堆排序算法make_heap()-特殊的二叉树,每一个节点都比根小,根就是最大的数.大根堆,也可以做 ...
- 记一次 CocoaPod 的使用过程
目前有一个cocos2d creator项目, 接入了微信SDK, 现在需要接入阿里云移动推送. 用到了CocoaPod集成. 于是创建了一个Podfile, (此文件在项目目录中, 和 xxx ...
- WINCC 应用与提高(78讲15.98G)视频教程网盘下载
收集与网络,供参考. https://blog.csdn.net/txwtech/article/details/94225748
- Mybatis框架介绍
MyBatis 本是apache的一个开源项目iBatis, 2010年这个项目由apache software foundation 迁移到了google code,并且改名为MyBatis.201 ...
- VScode Doxygen与Todo Tree插件的使用与安装
VScode Doxygen与Todo Tree插件的使用与安装 引言 程序中代码注释的规范和统一性是作为工程人员必不可少的技能,本文在Visual Studio Code的环境下简单介绍Doxyge ...
- Java学习笔记5(API)
Java API API(Application Programming Interface)指的是应用程序编程接口. String类 String初始化有两种,一个是使用字符串常量初始化一个Stri ...
- android面试详解
前台就是和用户交互的进程 可见进程例如一个activity被一个透明的对话框覆盖,该activity就是可见进程 服务:service进程 后台一个activity按了home按键就是从前台退回到后台 ...
- 宝贝,来,满足你,二哥告诉你学 Java 应该买什么书?
(这次的标题是不是有点皮,对模仿好朋友 guide 哥的,我也要皮一皮) 高尔基说过,对吧?宝贝们,"书籍是人类进步的阶梯",不管学什么,买几本心仪的书读一读,帮助还是非常大的.尽 ...