让你的浏览器变成Siri一样的语音助手
最近业余时间浏览技术文章的时候,看到了一篇关于语音朗读的文章:Use JavaScript to Make Your Browser Speak(用Javascript让你的浏览器说话),文章中提到可以通过speechSynthesis实现让现代浏览器语音朗读指定的内容,这激发了我的好奇心去探索了一番,于是便有了下文。
本文提及的代码片段执行需要音频输出设备(如音响、耳机)和音频输入设备(如麦克风)等硬件设备的支持。
语音朗读 speechSynthesis
严格意义来上,实现语音朗读的功能需要speechSynthesis和SpeechSynthesisUtterance两个方法共同协作完成。SpeechSynthesisUtterance告诉浏览器需要语音朗读的内容,而speechSynthesis将需要朗读的内容合成为音频内容,由音响等一类的音频输出设备进行播放。
支持朗读的语言
speechSynthesis的实现是通过浏览器底层调用了操作系统的相关接口实现的语音朗读。因此语言的支持度可能因为浏览器和操作系统的不同而不同,可以通过speechSynthesis.getVoices()获取当前设备支持的朗读语言。
不过,多数支持speechSynthesis方法的浏览器一般都支持中文内容的朗读。而且这样也带来了一个好处:可以离线使用,也可以通过SpeechSynthesisVoice.localService方法替换成自己的音源。
代码示例
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<title>语音朗读</title>
</head>
<body>
<button type="button" onclick="speak('你好,李焕英')">说话</button>
<script type="text/javascript">
// 语音朗读功能
function speak(sentence) {
// 生成需要语音朗读的内容
const utterance = new SpeechSynthesisUtterance(sentence)
// 由浏览器发起语音朗读的请求
window.speechSynthesis.speak(utterance)
}
</script>
</body>
</html>
兼容性

排除已不再维护的IE浏览器,PC几个主流的浏览器和IOS均已支持,安卓支持性有好有坏,需要做好兼容处理。
M71提案
不过值得注意的一点是,当Chrome上线相关功能之后,发现语音朗读的功能被一些网站滥用,于是Chrome在M71提案(提案链接)之后,将触发机制变更成:需要用户自行触发事件才能进行语音朗读。
我个人测试了Chrome、Edge两款浏览器,Chrome无法通过直接调用和通过创建DOM节点触发click事件间接调用,而Edge在写文时(2021-03-13)两种方法都可以调用;因此如果有相关业务需求时,建议做好相应的兼容准备。
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<title>语音朗读</title>
</head>
<body>
<script type="text/javascript">
function speak(sentence) {
const utterance = new SpeechSynthesisUtterance(sentence);
window.speechSynthesis.speak(utterance);
};
// 在M71提案后,Chrome禁止了自动调用语言朗读的机制
// Edge在2021-03-13时可以直接调用,其他浏览器跟进程度未知
speak('直接调用');
const button = document.createElement('button');
button.onclick = () => speak('创建节点调用');
document.body.appendChild(button);
button.click();
setTimeout(() => document.body.removeChild(button), 50);
</script>
</body>
</html>
测试完这些代码的时候,脑海中忽然闪过一个想法:既然都有语音朗读了,那有没有语音识别的方法呢?于是我查了MDN及一些相关的资料,发现还真有语音识别的方法:SpeechRecognition(文档链接)。
语音识别 SpeechRecognition
跟语音朗读speechSynthesis本地朗读不同,SpeechRecognition在MDN文档(点击此处)中明确提出了是基于服务器的语音识别,也就是说必须联网才能识别。
On some browsers, like Chrome, using Speech Recognition on a web page involves a server-based recognition engine. Your audio is sent to a web service for recognition processing, so it won't work offline.
在某些浏览器(例如Chrome)上,网页上使用的语音识别基于服务器的识别引擎。您的音频将发送到网络服务以进行识别处理,因此它将无法离线工作。
如果你使用的浏览器是Chrome,语音识别的服务端则是由谷歌提供的,如果不用梯子的话会直接提示结束。不过好在提供了SpeechRecognition.serviceURI用来自定义语音识别的提供商,算是一种权宜之计吧。
代码示例
<!DOCTYPE html>
<head lang="zh-CN">
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<title>语音朗读</title>
</head>
<body>
<button type="button" onclick="recognition.start()">点击识别语音</button>
<button type="button" onclick="recognition.stop()">结束语音识别</button>
<p id="status"></p>
<p id="output"></p>
<script type="text/javascript">
// 目前只有Chrome和Edge支持该特性,在使用时需要加私有化前缀
const SpeechRecognition = window.webkitSpeechRecognition
const recognition = new SpeechRecognition()
const output = document.getElementById("output")
const status = document.getElementById("status")
// 语音识别开始的钩子
recognition.onstart = function() {
output.innerText = ''
status.innerText = '语音识别开始'
}
// 如果没有声音则结束的钩子
recognition.onspeechend = function() {
status.innerText = "语音识别结束"
recognition.stop()
}
// 识别错误的钩子
recognition.onerror = function({ error }) {
const errorMessage = {
'not-speech': '未检测到声源',
'not-allowed': '未检测到麦克风设备或未允许浏览器使用麦克风'
}
status.innerText = errorMessage[ error ] || '语音识别错误'
}
// 识别结果的钩子,
// 可通过interimResults控制是否实时识别,maxAlternatives设置识别结果的返回数量
recognition.onresult = function({ results }) {
const { transcript, confidence } = results[0][0]
output.innerText = `识别的内容:${ transcript },识别率:${ (confidence * 100).toFixed(2) }%`
}
</script>
</body>
</html>
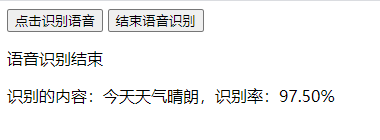
识别准确度
我个人拿Chrome浏览器尝试了一下午,当识别率低于90%的时候,基本就会出现丢字的情况,比如我用较快的语气说了一句“今天天气怎么样”,最后识别的结果是“怎么样”。当环境比较嘈杂的时候,基本识别率就没有高于70%的时候,说一句“你好”,得到的结果要么直接报错要么不搭边,对长难句的识别率也不怎么高。

如果希望达到一个比较高的识别率,则需要安静的环境,简单的语句,说话清晰响亮缓慢(类似于播音腔)。
兼容性
这算是一个相当新的api,新到什么程度呢?
新到MDN文档创建SpeechRecognition相关词条的时间在2020年9月15日,截止我写文的2021年03月13日刚好半年的时间。
虽然新意味着兼容性差,但这也从某种层次上说明,未来Web前端的发展方向也许真的可能替代原生应用。

从兼容性来看,PC只有Chrome和Edge(仅限Chromium核心)这两款浏览器支持,移动端几乎全军覆没,只有少数几个比较新的版本支持,但不确定对整体的兼容性如何。
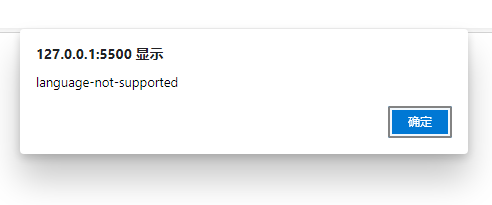
经过实际的测试,Chrome支持英文和中文的语音识别,而Edge会提示language-not-supported的错误,更改html上的语言仍然报错,怀疑需要更改电脑的系统语言才能解决(未确定)。
语音识别 + 语音朗读 = 语音助手
市面上比较常见的各类语音助手(比如Siri),在前端的逻辑都比较简单,一般情况下如果只处理本地化的配置,如设置闹钟、询问日期等功能,核心功能主要分为语音识别和语音朗读两部分,当浏览器提供了这两项能力的时候,便已满足了语音助手的条件。
于是我尝试写了一个很简单的DEMO,将两者合二为一实现了一个语音助手。
代码示例
<!DOCTYPE html>
<head lang="zh-CN">
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<title>语音助手</title>
</head>
<body>
<button type="button" onclick="recognition.start()">点击识别语音</button>
<p id="status"></p>
<p id="output"></p>
<script type="text/javascript">
function speak(sentence) {
const utterance = new SpeechSynthesisUtterance(sentence)
window.speechSynthesis.speak(utterance)
}
// 目前只有Chrome和Edge支持该特性,在使用时需要加私有化前缀
const SpeechRecognition = window.webkitSpeechRecognition
const recognition = new SpeechRecognition()
const output = document.getElementById("output")
const status = document.getElementById("status")
// 语音识别开始的钩子
recognition.onstart = function() {
output.innerText = ''
status.innerText = '语音识别开始'
}
// 如果没有声音则结束的钩子
recognition.onspeechend = function() {
recognition.stop()
}
// 识别错误的钩子
recognition.onerror = function({ error }) {
const errorMessage = {
'not-speech': '未检测到声源',
'not-allowed': '未检测到麦克风设备或未允许浏览器使用麦克风'
}
status.innerText = errorMessage[ error ] || '语音识别错误'
}
// 识别结果的钩子
recognition.onresult = function({ results }) {
// 设置一些比较简单的回复
const answers = {
'今天是星期几': '今天是星期六',
'今天天气怎么样': '今天天气晴朗'
}
const { transcript, confidence } = results[0][0]
// 设置一个阈值分别处理
if( confidence * 100 >= 90 ) {
speak(answers[transcript] || '这件事我还不知道,换个问题吧')
status.innerText = `语音回复的内容:${ answers[transcript] || '这件事我还不知道,换个问题吧' }`
} else {
speak('我好像没听明白')
status.innerText = `我好像没听明白`
}
}
</script>
</body>
</html>
总结
目前大部分的浏览器都还没兼容语音识别的特性,但在可预见的未来,不仅主流浏览器会支持语音识别的特性,也会有一些第三方服务商通过浏览器原生的方法提供类似的服务,同时会有更多类似的能力出现在Web平台上。
让你的浏览器变成Siri一样的语音助手的更多相关文章
- 三大操作系统对比使用之·MacOSX
时间:2018-11-13 整理:byzqy 本篇是一篇个人对Mac系统使用习惯和应用推荐的分享,在此记录,以便后续使用查询! 打开终端: command+空格,调出"聚焦搜索(Spotli ...
- 三星抛出万亿投资计划 布局四大科技创新领域(5G、人工智能、汽车半导体、生物技术四大新兴产业)
三星近日抛出震惊世人的投资计划,未来三年将在全球范围新增投资180万亿韩元(约1万亿元人民币).新增员工4万名.这是韩国单一企业集团大规模的投资计划. 笔者获悉,三星万亿投资计划主要分两大部分,一是在 ...
- 在iPhone上同时关闭语音控制和siri的方法
分享 步骤及要点:1.在设置里打开siri.语音控制就自动关闭了.2.在siri里的"仅语言拨号"语言项里选择"土耳其文"或者"阿拉伯文". ...
- 【福利将至】iPhone用户可用Siri发微信了
北京时间6月14日,苹果WWDC16开发者大会召开.继2015年3月份春季发布会和9月份的秋季新品发布会,苹果和腾讯联手Apple Watch版微信和微信3DTouch功能之后,双方在今年的WWDC上 ...
- Domoticz 接入苹果的 HomeKit 实现 Siri 控制
前言 接上次的折腾,这次尝试将 Domoticz 接入到苹果的 HomeKit,也就是在 iPhone 的 Siri 中可以语音控制.参考官方文档 步骤 安装 nodejs curl -sL http ...
- 说说windows10自带浏览器Edge的好与不好
用了10几个月了,正式版也升级了,今天来说说微软自带浏览器microsoft Edge的好与不好 先说好的吧 一,浏览器速度非常快,无论是打开还是关闭,或者是语音助手小娜需要调动浏 ...
- 苹果公司以注重客户隐私闻名世界,但为什么Siri泄露了我的秘密?
编辑 | 于斌 出品 | 于见(mpyujian) 苹果的Siri因为其作为智能语音助手,方便人们打电话.发信息等功能,被人们所喜爱,但是最近,Siri好像有一些问题,让我们怀疑这位"小伙伴 ...
- win7升win10,初体验
跟宿舍哥们聊着聊着,聊到最近发布正式版的win10,听网上各种评论,吐槽,撒花的,想想,倒不如自己升级一下看看,反正不喜欢还可以还原.于是就开始了win10的初体验了,像之前装黑苹果双系统一样的兴奋, ...
- iOS 1 到 iOS 10 ,我都快老了
iOS 1:iPhone诞生 虽然很难想像,但初代iPhone在问世时在功能方面其实远远落后于那时的竞争对手,比如Windows Mobile.Palm OS.塞班.甚至是黑莓.它不支持3G.多任务. ...
随机推荐
- Google reCAPTCHA 2 : Protect your site from spam and abuse & Google reCAPTCHA 2官方教程
1
- 微信小程序-云开发实战教程
微信小程序-云开发实战教程 云函数,云存储,云数据库,云调用 https://developers.weixin.qq.com/miniprogram/dev/wxcloud/basis/gettin ...
- JavaScript & Automatic Semicolon Insertion
JavaScript & Automatic Semicolon Insertion ECMA 262 真香警告️ https://www.ecma-international.org/ecm ...
- React LifeCycle API
React LifeCycle API old API & new API 不可以混用 demo https://codesandbox.io/s/react-parent-child-lif ...
- GitHub & GitHub Package Registry
GitHub & GitHub Package Registry npm https://github.blog/2019-05-10-introducing-github-package-r ...
- perl 在windows上获取当前桌面壁纸
更多 #!/usr/bin/perl # 在windows获取当前的桌面壁纸 # See also: https://www.winhelponline.com/blog/find-current-w ...
- NGK内存将为全球投资者创造新的财富增长机会
2020年,随着BTC的持续上涨带动了整个区块链市场的持续加温,同时金融市场也对金融体制做出了改变,关于金融和区块链的结合越来越被人们所认可,在此基础上,DeFi行业借此迎来了快速发展,据不完全统计, ...
- Python 装饰器原理剖析
以下内容仅用于帮助个人理解装饰器这个概念,案例可能并不准确. 什么是装饰器? 我们知道iPhone 应用商店中有成千上万的APP,我们也知道苹果系统每年都会大版本更新增加很多新功能.这些功能要想发挥出 ...
- Tawk.to一键给自己的网站增加在线客服功能
Tawk.to一键给自己的网站增加在线客服功能 很多外贸网站只有contact页面,留下邮箱.电话等联系方式,而在国际贸易当中能够及时在线交流沟通,能给客户留下更好的印象.接下来,就让我们一起来了解一 ...
- Iterative learning control for linear discrete delay systems via discrete matrix delayed exponential function approach
对于一类具有随机变迭代长度的问题,如功能性电刺激,用户可以提前结束实验过程,论文也是将离散矩阵延迟指数函数引入到状态方程中. 论文中关于迭代长度有三个定义值:\(Z^Ta\) 为最小的实验长度,\(Z ...