B树摘要
BTree
以下内容是根据《算法导论》摘要而来,由于国内书籍对B树的定义是以阶来定义,而《算法导论》中使用的是最小度来定义,并且节点中关键字个数也不相同,在翻看网上博客时,产生了诸多疑问,考虑到B树是从国外而来,我还是打算相信《算法导论》
定义
- 用最小度来t定义,t>=2,每个节点的关键字个数 t-1 < n < 2t-1,非叶子节点子女指针个数范围 t < c <2t (有j个孩子的节点,恰好有j-1个关键字)
- 非叶子节点上也有数据,适合随机检索,越靠近root,磁盘i/o时间越少,速度越快
- 所有叶子节点具有相同的深度,根节点至少有一个关键字
- 真实数据并未存放到B树的各个节点上,节点上只是存储了节点数据在硬盘上的存储地址
- 通常采用的分支因子为50-2000,主要取决于一个关键字相对于一个磁盘块|内存页的大小
- 由于根节点实现时,会一直在主存中,寻找某个关键字(仅寻找关键字,应该不含数据那一次),进行的磁盘IO次数,最多为树的高度(高度h为树的层数-1),树的深度与根节点为第几层有关,如根节点为0,则层数为3的树,深度为2,如果根节点为1,则深度为3
- 一颗分支因子为1001,高度为2的树,可以有10亿个关键字
- 每个页节点有相同的高度
- 树非空时,root至少含义一个关键字
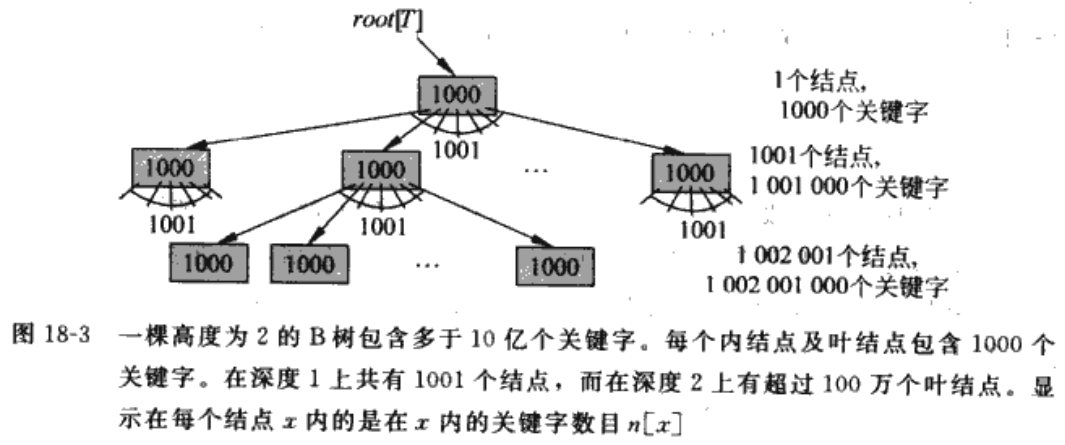
搜索
实现search操作时,会用到递归
顶层调用为search(root,k)
search(node,k)
i=1
while(k> keys[i])
i++;
if(keys[i] =k)
then return (node,i)
if(leaf[i] == null)
then return null
else disk-read(leaf[i])
then return search(leaf[i],k)
时间复杂度O(tlogt(n))
插入
以最小度为4举例,节点的关键字个数为 3~7
如果k需要插入node x,而x不是叶节点,则应将k插入到x的子树中去,直到找到叶节点
判断是否需要分裂,确保无满子节点->如果插入前节点中key的个数为7(即判断是否满子),则不能再插,因为它已经达到了最大key个数,此时需要将这个节点分裂,方法是将中间关键字上移到父节点,上移后,一个节点分裂为2个节点,左边的是小于中间key的关键字,右边是大于中间key的关键字,建立一个新的节点,使之继续满足要求,以此类推,如果中间key上移到父节点后,父节点的key大于7,则父节点按次方法继续分裂,最终可能导致根节点分裂,这样,树的高度就会 + 1,根节点分裂是B树高度增加的唯一途径
判断k需要插入到分裂后(如果需要分裂的话)的哪个叶子节点
递归插入操作,在任何时刻,需要留在主存中的页面数为O(1),注:根节点以外,根结点始终在主存中
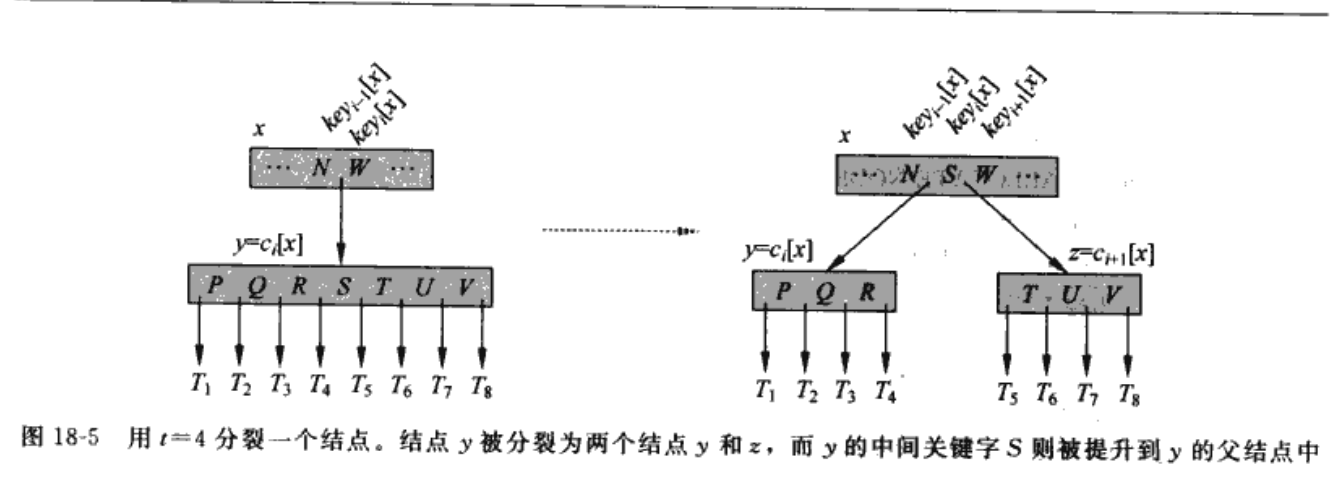
删除
删除操作和插入操作一样,为了满足B树的性质,需要尝试合并节点,而插入操作会分裂节点
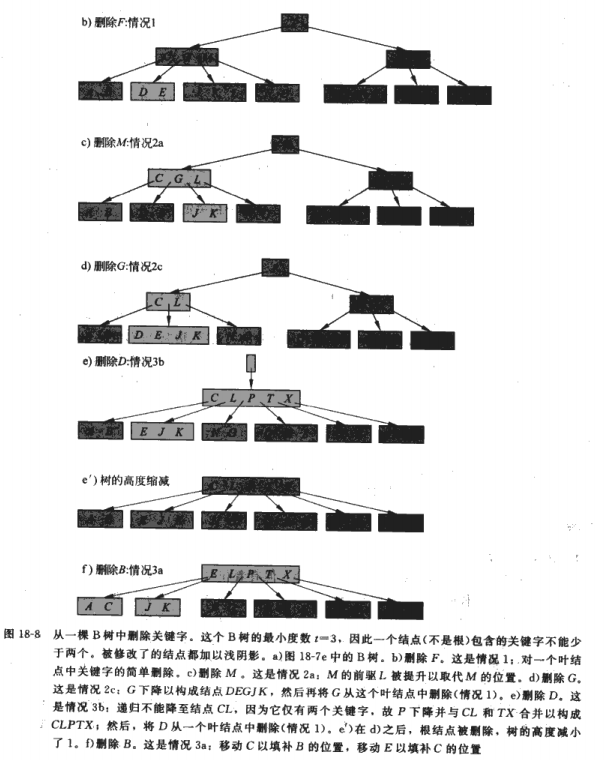
1.如果关键字k在叶子节点中,直接删除;
2.如果在内部节点中,则判断节点中,前于k的子节点p中关键字的个数至少有t个关键字,此时将其最大的键提到k的位置;
3.否则判断后于k的子节点中关键字个数大于t,如果大于,将其最小的键提到k的位置,这样树的结构变化就很小,仅需要修改几个指针
4.如果前于k的子节点和后于k的子节点都只有t-1个关键字,则将他们3个合并到前于k的节点上去
5.不在某个节点中,递归查询,查询中如果遇到相邻节点关键字较少时,将其合并,合并操作可能会导致根节点下沉,高度
6.k不在某个内节点中(k实际在树结构中),此时需要递归的寻找它,并且在递归寻找中,如果发现含关键字的子树的根,只有t-1个关键字,则通过移动它兄弟节点中的关键字,来保证它至少有t个关键字(至少t个关键字的原因由1.2.3点可以得知,是为了在将来的删除操作来临时,有较大概率命中1.2.3)。
如果根结点不含有任何关键字,但它有子节点,则需要删除根结点,从而使树的高度降低了1
这其中最重要的是第5点,它从根节点开始,会遍历所有子树中含k的节点,如果节点中不至少包含t个关键字,则会进行操作5,当删除操作以此方式操作完整个树后,树的高度可能-1;
B树摘要的更多相关文章
- DotNet基础
DotNet基础 URL特殊字符转义 摘要: URL中一些字符的特殊含义,基本编码规则如下: 1.空格换成加号(+) 2.正斜杠(/)分隔目录和子目录 3.问号(?)分隔URL和查询 4.百分号(%) ...
- 正则表达式与领域特定语言(DSL)
如何设计一门语言(十)——正则表达式与领域特定语言(DSL) 几个月前就一直有博友关心DSL的问题,于是我想一想,我在gac.codeplex.com里面也创建了一些DSL,于是今天就来说一说这个事情 ...
- DevExpress v18.2新版亮点——DevExtreme篇(五)
行业领先的.NET界面控件2018年第二次重大更新——DevExpress v18.2日前正式发布,本站将以连载的形式为大家介绍新版本新功能.本文将介绍了DevExtreme Complete Sub ...
- 菜鸟系列Fabric源码学习 — MVCC验证
Fabric 1.4 源码分析 MVCC验证 读本节文档之前建议先查看[Fabric 1.4 源码分析 committer记账节点]章节. 1. MVCC简介 Multi-Version Concur ...
- [转]双数组TRIE树原理
原文名称: An Efficient Digital Search Algorithm by Using a Double-Array Structure 作者: JUN-ICHI AOE 译文: 使 ...
- [.net 面向对象程序设计进阶] (7) Lamda表达式(三) 表达式树高级应用
[.net 面向对象程序设计进阶] (7) Lamda表达式(三) 表达式树高级应用 本节导读:讨论了表达式树的定义和解析之后,我们知道了表达式树就是并非可执行代码,而是将表达式对象化后的数据结构.是 ...
- 数据结构--树(遍历,红黑,B树)
平时接触树还比较少,写一篇博文来积累一下树的相关知识. 很早之前在数据结构里面学的树的遍历. 前序遍历:根节点->左子树->右子树 中序遍历:左子树->根节点->右子树 后序遍 ...
- 基于tiny4412的Linux内核移植 -- 设备树的展开
作者信息 作者: 彭东林 邮箱:pengdonglin137@163.com QQ:405728433 平台简介 开发板:tiny4412ADK + S700 + 4GB Flash 要移植的内核版本 ...
- C#中的表达式树的浅解
表达式树可以说是Linq的核心之一,为什么是Linq的核心之一呢?因为表达式树使得c#不再是仅仅能编译成IL,我们可以通过c#生成一个表达式树,将结果作为一个中间格式,在将其转换成目标平台上的本机语言 ...
随机推荐
- 通过adrci ips打包incident给oracle
1.adrci查看incident 2.show home 3.set home adrci> set home diag/rdbms/mesdb/mesdb1 4.show incident ...
- Oracle学习(十五)PLSQL安装
PS:由于原来一直用的旧版本的PLSQL客户端,查看执行计划有些数据无法展示,所以今天换一波新版本的使用,记录下安装和使用流程. PLSQL(oracle数据可视化工具) 一.下载 我用的13的版本, ...
- Oracle学习(三)SQL高级--表结构相关(建表、约束)
一.建表语句 CREATE DATABASE(创建数据库) --创建数据库 create database 数据库名字; CREATE TABLE(创建表) --创建表 CREATE TABLE 表名 ...
- Oracle 11gR2
OracleOraDb11g_home1TNSListener #其它客服端连接需要开启服务,如不开启,本机连接可以直接使用sqlplus OracleServiceORCL #实例SID服务 sq ...
- linux中重启网卡后网络不通(NetworkManager篇)
1.问题描述 RHEL7.6系统,使用nmcli绑定双网卡后,在使用以下命令重启network服务后主机网络异常,导致无法通过ssh远程登录系统. systemctl restart network ...
- Centos-内核核心组成
linux内核,相当于linux大脑,高可靠和高稳定都是针对内核来说 完整linux核心组成部分 1. 内存管理 合理有效的管理整个系统的物理内存,同时快速响应内核各子系统对内存分配的请求 2. 进程 ...
- 错误: 在类中找不到 main 方法, 请将 main 方法定义为:    public static void main(String[] args) 否则 JavaFX 应用程序类必须扩展javafx.application.Application 。
昨天在eclipse编写JAVA程序时,遇到一个问题: 错误: 在类中找不到 main 方法, 请将 main 方法定义为: public static void main(String[] a ...
- 软件定义网络实验记录③--Mininet 实验——测量路径的损耗率
一.实验目的 在实验 2 的基础上进一步熟悉 Mininet 自定义拓扑脚本,以及与损耗率相关的设定: 初步了解 Mininet 安装时自带的 POX 控制器脚本编写,测试路径损耗率. 二.实验任务 ...
- 025 01 Android 零基础入门 01 Java基础语法 03 Java运算符 05 if条件结构
025 01 Android 零基础入门 01 Java基础语法 03 Java运算符 05 if条件结构 本文知识点:Java中的if条件结构语句 关系运算符回顾 生活中根据条件进行判断采取不同操作 ...
- python在一个画布上画多个子图
转载:https://blog.csdn.net/qq_26449287/article/details/103022636 matplotlib 是可以组合许多的小图, 放在一张大图里面显示的. 使 ...