requests 库和beautifulsoup库
python 爬虫和解析
库的安装:pip install requests; pip install beautifulsoup4
requests 的几个常用方法:
requests.request() #以下各方法的基础
requests.get(url,params=None,**kwargs) #获取html内容
requests.head() #获取网页头部内容
requests.post()
requests.put()
requests.patch()
requests.delete()
重点为:get()其有12个控制关键字参数 返回为response对象
r.status_code #200为正常
r.text #html内容
r.encoding 编码
r.apparent_encoding 备选编码
r.content 二进制形式返回,爬取 图片,视频,音频等的关键
常使用try,except框架
import requests
import os
url = 'http://image.ngchina.com.cn/2018/1010/20181010031434134.jpg'
root = 'd://pics//'
path = root + url.split('/')[-1]
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r=requests.get(url)
with open(path,'wb') as f:
f.write(r.content)
f.close()
print('文件保存成功')
else:
print('文件已存在')
except:
print('失败')
import requests
import os
url = 'http://mov.bn.netease.com/open-movie/nos/mp4/2016/05/16/SBM8NN8G6_shd.mp4'
root = 'd://vidio//'
path = root + url.split('/')[-1]
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r=requests.get(url)
with open(path,'wb') as f:
f.write(r.content)
f.close()
print('文件保存成功')
else:
print('文件已存在')
except:
print('失败')
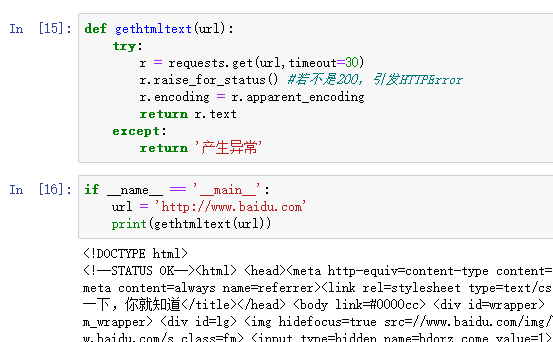
1 import requests
2 from bs4 import BeautifulSoup
3 import bs4
4 def gethtmltext(url):
5 try:
6 r = requests.get(url,timeout=30)
7 r.raise_for_status()
8 r.encoding=r.apparent_encoding
9 return r.text
10 except:
11 return ''
12
13
14 def fillunivlist(ulist,html):
15 soup = BeautifulSoup(html,'html.parser')
16 for tr in soup.find('tbody').children:
17 if isinstance(tr,bs4.element.Tag):
18 tds = tr('td')
19 ulist.append([tds[0].string,tds[1].string,tds[2].string])
20
21 def printunivlist(ulist,num):
22 print('{:^10}\t{:^6}\t{:^10}'.format('排名','学校名称','总分'))
23 for i in range(num):
24 u=ulist[i]
25 print('{:^10}\t{:^6}\t{:^10}'.format(u[0],u[1],u[2]))
26
27
28 def main():
29 uinfo = []
30 url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html'
31 html = gethtmltext(url)
32 fillunivlist(uinfo,html)
33 printunivlist(uinfo,20)
34
35 main()
查看爬虫协议在最后加上robots.txt 如:www.jd.com/robots.txt
Beautiful Soup库 #解析网页用
BeautifulSoup(text,'html.parser')
SOUP库的基本元素:
Tag 标签,最基本的信息单元,对应<>....</>
Name 标签名
attributes 标签属性:Tag.attrs
Navigablestring 标签内非属性字符串<>....</>中的字符串 格式:Tag.string
Comment 标签的注释部分
如:<p class='title'>.....</p> p标签
p.name p.attrs p.string
requests 库和beautifulsoup库的更多相关文章
- python爬虫学习(一):BeautifulSoup库基础及一般元素提取方法
最近在看爬虫相关的东西,一方面是兴趣,另一方面也是借学习爬虫练习python的使用,推荐一个很好的入门教程:中国大学MOOC的<python网络爬虫与信息提取>,是由北京理工的副教授嵩天老 ...
- Python:requests库、BeautifulSoup4库的基本使用(实现简单的网络爬虫)
Python:requests库.BeautifulSoup4库的基本使用(实现简单的网络爬虫) 一.requests库的基本使用 requests是python语言编写的简单易用的HTTP库,使用起 ...
- BeautifulSoup库整理
BeautifulSoup库 一.BeautifulSoup库的下载以及使用 1.下载 pip3 install beautifulsoup4 2.使用 improt bs4 二.BeautifulS ...
- 爬虫 Http请求,urllib2获取数据,第三方库requests获取数据,BeautifulSoup处理数据,使用Chrome浏览器开发者工具显示检查网页源代码,json模块的dumps,loads,dump,load方法介绍
爬虫 Http请求,urllib2获取数据,第三方库requests获取数据,BeautifulSoup处理数据,使用Chrome浏览器开发者工具显示检查网页源代码,json模块的dumps,load ...
- $python爬虫系列(2)—— requests和BeautifulSoup库的基本用法
本文主要介绍python爬虫的两大利器:requests和BeautifulSoup库的基本用法. 1. 安装requests和BeautifulSoup库 可以通过3种方式安装: easy_inst ...
- 利用python的requests和BeautifulSoup库爬取小说网站内容
1. 什么是Requests? Requests是用Python语言编写的,基于urllib3来改写的,采用Apache2 Licensed 来源协议的HTTP库. 它比urllib更加方便,可以节约 ...
- Python爬虫小白入门(三)BeautifulSoup库
# 一.前言 *** 上一篇演示了如何使用requests模块向网站发送http请求,获取到网页的HTML数据.这篇来演示如何使用BeautifulSoup模块来从HTML文本中提取我们想要的数据. ...
- 网络爬虫BeautifulSoup库的使用
使用BeautifulSoup库提取HTML页面信息 #!/usr/bin/python3 import requests from bs4 import BeautifulSoup url='htt ...
- 基于BeautifulSoup库的HTML内容的查找
一.BeautifulSoup库提供了一个检索的参数: <>.find_all(name,attrs,recursive,string,**kwargs),它返回一个列表类型,存储查找的结 ...
随机推荐
- is_mobile()判断手机移动设备
is_mobile()判断手机移动设备.md is_mobile()判断手机移动设备 制作响应式主题时会根据不同的设备推送不同的内容,是基于移动设备网络带宽压力,避免全局接收pc端内容. functi ...
- 理解vue与MVVM三要素
MVVM到底是什么,跟Jquery有什么区别? MVVM理解,跟MVC区别 Model View Controller,一般是用户操作view视图按钮,触发controller内方法,cotrolle ...
- React学习小记--setState的同步与异步
react中,state不能直接修改,而是需要使用setState()来对state进行修改,那什么时候是同步而什么时候是异步呢? 基础代码: setCounter = (v) => { thi ...
- CUMTCTF'2020 未完成 wp
Web babysqli burp抓包,发现有 的过滤,用/**/过滤空格. 报错注入 payload username=admin&password='/**/or/**/extractva ...
- matlab中imfilter、conv2、imfilter2用法及区别
来源 :https://blog.csdn.net/u013066730/article/details/56665308(比较详细) https://blog.csdn.net/yuanhuilin ...
- RHSA-2017:1842-重要: 内核 安全和BUG修复更新(需要重启、存在EXP、本地提权、代码执行)
[root@localhost ~]# cat /etc/redhat-release CentOS Linux release 7.2.1511 (Core) 修复命令: 使用root账号登陆She ...
- shell-的变量-局部变量
1. 定义本地变量 本地变量在用户当前的shell生产期的脚本中使用.例如,本地变量OLDBOY取值为ett098,这个值只在用户当前shell生存期中有意义.如果在shell中启动另一个进程或退出, ...
- [leetcode] 剑指 Offer 专题(一)
又开了一个笔记专题的坑,未来一两周希望能把<剑指Offer>的题目刷完
- iproute2工具
iproute2工具介绍 iproute2是linux下管理控制TCP/IP网络和流量控制的新一代工具包,出现目的是替代老工具链net-tools.net-tools是通过procfs(/proc)和 ...
- 【UR #2】猪猪侠再战括号序列
UOJ小清新题表 题目摘要 UOJ链接 有一个由 \(n\) 个左括号 "(" 和 \(n\) 个右括号 ")" 组成的序列.每次操作时可以选定两个数 \(l, ...