数据源管理 | 分布式NoSQL系统,Cassandra集群管理
本文源码:GitHub·点这里 || GitEE·点这里
一、Cassandra简介
1、基础描述
Cassandra是一套开源分布式NoSQL数据库系统。它最初由Facebook开发,用于储存收件箱等简单格式数据,此后,由于Cassandra良好的可扩展性,逐渐发展成为了一种流行的分布式结构化数据存储方案。
2、特点分析
弹性可扩展性
Cassandra是高度可扩展的;它允许添加更多的硬件以适应更多的客户和更多的数据根据要求,可以根据业务的数据流量轻松扩展集群规模。
架构特点
Cassandra可以基于分布式运行,并采用了许多容错机制。由于去中心化无主的策略,所以没有单点故障。可以做到不停服滚动升级。这是因为Cassandra可以支持多个节点的临时失效(取决于群集大小),对群集的整体性能影响可以忽略不计。并且Cassandra提供多地域容灾。Cassandra允许将数据复制到其他数据中心,并在多个地域保留多副本,十分适用于不能承担故障的关键业务,必须持续提供服务的应用程序。
数据存储机制
Cassandra适应所有可能的数据格式,包括:结构化,半结构化和非结构化。可以根据业务的需要动态地适应变化的数据结构,并且通过在多个数据中心之间复制数据,可以灵活地在需要时分发数据。有许多案例证明Cassandra可以在金融,医疗,物联网等领域使用。
资源整合能力
Cassandra可以很容易的跟其他开源组件做集成,其中包括Hadoop,Spark,Kafka,Solr等系列组件,成为大数据业务处理里面重要的一个角色。
二、集群环境搭建
1、环境概览
- jdk1.8
- apache-cassandra-3.11.7-bin.tar.gz
- centos7
- 三台服务:hop01、hop02、hop03节点
2、安装包处理
tar -zxvf apache-cassandra-3.11.7-bin.tar.gz
mv apache-cassandra-3.11.7 cassandra3.11
3、环境变量
[root@hop01 opt]# vim /etc/profile
export CASSANDRA_HOME=/opt/cassandra3.11
export PATH=$PATH:$CASSANDRA_HOME/bin
[root@hop01 opt]# source /etc/profile
4、创建目录
# 数据目录
mkdir -p /data/cassandra/data
# 日志目录
mkdir -p /data/cassandra/log
5、集群配置
vim /opt/cassandra3.11/conf/cassandra.yaml
# 配置集群名称
cluster_name: 'CasCluster'
# 配置数据目录
data_file_directories:
- /data/cassandra/data
# 配置日志目录
commitlog_directory: /data/cassandra/log
# 设置监听地址,当前服务IP
listen_address: 192.168.72.132
# 配置RPC服务
start_rpc: true
rpc_address: 192.168.72.132
# 配置集群节点
seed_provider:
- class_name: org.apache.cassandra.locator.SimpleSeedProvider
parameters:
- seeds: "192.168.72.132,192.168.72.138,192.168.72.139"
将该配置分发到集群的每个节点,注意listen_address和rpc_address是节点自己的IP地址即可。
6、启动集群
# 集群下节点依次执行启动命令
cassandra -R
# 查看节点状态
nodetool status
7、基础操作
进入命令行
cqlsh hop01
创建keyspace,并选择
CREATE KEYSPACE IF NOT EXISTS castest WITH REPLICATION = {'class': 'SimpleStrategy','replication_factor':3};
use castest ;
创建表,写入数据
CREATE TABLE user_info (id int, user_name varchar, PRIMARY KEY (id) );
INSERT INTO user_info (id,user_name) VALUES (1,'user01');
查询数据
select * from user_info ;
基于其他服务查看数据,可以看到数据已经在集群间做了同步过程:
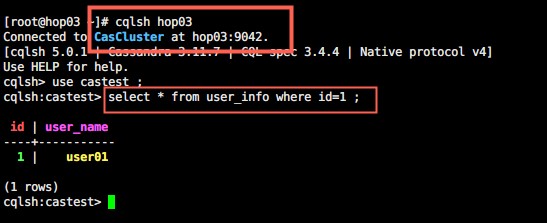
三、集成SpringBoot框架
1、核心依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>${spring.boot.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-cassandra</artifactId>
<version>${spring.boot.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
<version>${spring.boot.version}</version>
</dependency>
这里核心需要cassandra依赖和操作的API依赖。
2、核心配置
spring:
data:
cassandra:
keyspace-name: castest
contact-points: 192.168.72.138,192.168.72.132,192.168.72.139
port: 9042
cluster-name: CasCluster
keyspace-name:类似关系型数据库的名称;
contact-points:集群下节点的IP地址;
port:默认端口;
cluster-name:上述配置的集群名称;
3、基于Template命令
CassandraTemplate模板类,实现了一系列操作Cassandra数据库的基本方法,直接注入即可使用。
@Repository
public class UserInfoTemplate {
@Resource
private CassandraTemplate cassandraTemplate ;
// 查询全部数据
public List<UserInfo> getList (){
return cassandraTemplate.select("SELECT * FROM user_info",UserInfo.class) ;
}
// 添加数据
public UserInfo insert (UserInfo userInfo){
return cassandraTemplate.insert(userInfo) ;
}
// 根据主键查询
public UserInfo selectOneById (Integer id){
return cassandraTemplate.selectOneById(id,UserInfo.class) ;
}
// 修改数据
public UserInfo update (UserInfo userInfo){
return cassandraTemplate.update(userInfo) ;
}
// 删除数据
public Boolean deleteById (Integer id){
return cassandraTemplate.deleteById(id,UserInfo.class) ;
}
}
4、基于Repository接口
SpringBoot框架中定义的数据库访问核心接口。
接口实现
import com.cassand.cluster.entity.UserInfo;
import org.springframework.data.repository.CrudRepository;
public interface UserInfoRepository extends CrudRepository<UserInfo,Integer> {
}
接口用法
@Service
public class RepositoryService {
@Resource
private UserInfoRepository userInfoRepository ;
// 保存
public UserInfo save (UserInfo userInfo){
return userInfoRepository.save(userInfo) ;
}
// 查询
public UserInfo getById (Integer id){
return userInfoRepository.findById(id).get() ;
}
// 修改
public UserInfo update (UserInfo userInfo){
// 主键ID存在的情况即为修改
return userInfoRepository.save(userInfo);
}
// 删除
public void deleteById (Integer id){
userInfoRepository.deleteById(id);
}
}
5、实体表结构
注意这里的注解是基于cassandra特定的一套。
import org.springframework.data.cassandra.core.mapping.Column;
import org.springframework.data.cassandra.core.mapping.PrimaryKey;
import org.springframework.data.cassandra.core.mapping.Table;
@Table("user_info")
public class UserInfo {
public UserInfo(Integer id, String userName) {
this.id = id;
this.userName = userName;
}
@PrimaryKey
private Integer id ;
@Column(value = "user_name")
private String userName ;
}
四、源代码地址
GitHub·地址
https://github.com/cicadasmile/data-manage-parent
GitEE·地址
https://gitee.com/cicadasmile/data-manage-parent

推荐阅读:数据源管理系列
数据源管理 | 分布式NoSQL系统,Cassandra集群管理的更多相关文章
- 一步到位分布式开发Zookeeper实现集群管理
说到分布式开发Zookeeper是必须了解和掌握的,分布式消息服务kafka .hbase 到hadoop等分布式大数据处理都会用到Zookeeper,所以在此将Zookeeper作为基础来讲解. Z ...
- 【拆分版】Docker-compose构建Zookeeper集群管理Kafka集群
写在前边 在搭建Logstash多节点之前,想到就算先搭好Logstash启动会因为日志无法连接到Kafka Brokers而无限重试,所以这里先构建下Zookeeper集群管理的Kafka集群. 众 ...
- 运维利器-ClusterShell集群管理操作记录
在运维实战中,如果有若干台数据库服务器,想对这些服务器进行同等动作,比如查看它们当前的即时负载情况,查看它们的主机名,分发文件等等,这个时候该怎么办?一个个登陆服务器去操作,太傻帽了!写个shell去 ...
- Clustershell集群管理
在运维实战中,如果有若干台数据库服务器,想对这些服务器进行同等动作,比如查看它们当前的即时负载情况,查看它们的主机名,分发文件等等,这个时候该怎么办?一个个登陆服务器去操作,太傻帽了!写个shell去 ...
- 运维利器-ClusterShell集群管理
在运维实战中,如果有若干台数据库服务器,想对这些服务器进行同等动作,比如查看它们当前的即时负载情况,查看它们的主机名,分发文件等等,这个时候该怎么办?一个个登陆服务器去操作,太傻帽了!写个shell去 ...
- Spark的集群管理器
上篇文章谈到Driver节点和Executor节点,但是如果想要运行Driver节点和Executor节点,就不能不说spark的集群管理器.spark的集群管理器大致有三种,一种是自带的standa ...
- [转载] 一共81个,开源大数据处理工具汇总(下),包括日志收集系统/集群管理/RPC等
原文: http://www.36dsj.com/archives/25042 接上一部分:一共81个,开源大数据处理工具汇总(上),第二部分主要收集整理的内容主要有日志收集系统.消息系统.分布式服务 ...
- 一共81个,开源大数据处理工具汇总(下),包括日志收集系统/集群管理/RPC等
作者:大数据女神-诺蓝(微信公号:dashujunvshen).本文是36大数据专稿,转载必须标明来源36大数据. 接上一部分:一共81个,开源大数据处理工具汇总(上),第二部分主要收集整理的内容主要 ...
- 架构设计 | 分布式系统调度,Zookeeper集群化管理
本文源码:GitHub·点这里 || GitEE·点这里 一.框架简介 1.基础简介 Zookeeper基于观察者模式设计的组件,主要应用于分布式系统架构中的,统一命名服务.统一配置管理.统一集群管理 ...
随机推荐
- 区间dp复习 之 乘积最大
题目描述 今年是国际数学联盟确定的"2000--世界数学年",又恰逢我国著名数学家华罗庚先生诞辰90周年.在华罗庚先生的家乡江苏金坛,组织了一场别开生面的数学智力竞赛的活动,你的一 ...
- NIO实践-HTTP交互实现暨简版Tomcat交互内核
今天就NIO实现简单的HTTP交互做一下笔记,进而来加深Tomcat源码印象. 一.关于HTTP 1.HTTP的两个显著特点,HTTP是一种可靠的超文本传输协议 第一.实际中,浏览器作为客户端,每次访 ...
- git安装并与远程仓库关联相关配置
git是当前最流行的版本控制系统,下面简单记录一下git的安装及其与远程仓库的关联. git安装 打开git官网,下载对应的安装包. 双击运行安装包,安装过程中可以直接选择默认配置,一路next下去. ...
- 题解 洛谷 P6378 【[PA2010]Riddle】
首先不难看出对于本题的点与点之间的限制关系,我们可以考虑用\(2-SAT\)来解决,通过从状态\(x\)向状态\(y\)连一条有向边表示若状态\(x\)存在,那么状态\(y\)必须存在. 接下来的处理 ...
- EF Code 如何输出sql语句
首先写拷贝下面类 public class EFLoggerProvider : ILoggerProvider { public ILogger CreateLogger(string catego ...
- liunx安装和部署nacos配置中心
1.下载https://github.com/alibaba/nacos/releases nacos-server-1.3.1.tar.gz 源码包2.上传到liunx服务器 /usr/lo ...
- C语言中对文件的读写的一些浅显理解
前述:基于上学期完成的数据结构的课程设计,对于老师的提出要求实现的基础上,自己在使用过程中发现每次打开程序都需要重新输入数据,于是便决定,将文件读写功能加入此次课程设计中,以下是我的一些心得和浅显理解 ...
- Elasticsearch及相关插件的安装
Elasticsearch及相关插件的安装 1.安装Elasticsearch并启动服务 2.安装第三方插件 2.1.Head插件 是Elasticsearch的一个集群管理工具,可以通过它来查看和搜 ...
- php提取xml配置参数
demo1.php <?php class AddressManager{ private $addresses = array("ip地址1","ip地址2&qu ...
- Python os.tcsetpgrp() 方法
概述 os.tcsetpgrp() 方法用于设置与终端fd(一个由os.open()返回的打开的文件描述符)关联的进程组为pg.高佣联盟 www.cgewang.com 语法 tcsetpgrp()方 ...