通过BulkLoad快速将海量数据导入到Hbase(TDH,kerberos认证)
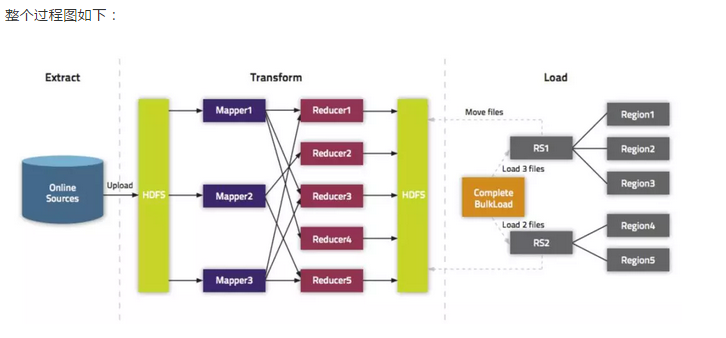
五、实践操作(kerberos认证)
1、创建表
create 'hfiletable','fm1','fm2'
2、数据准备

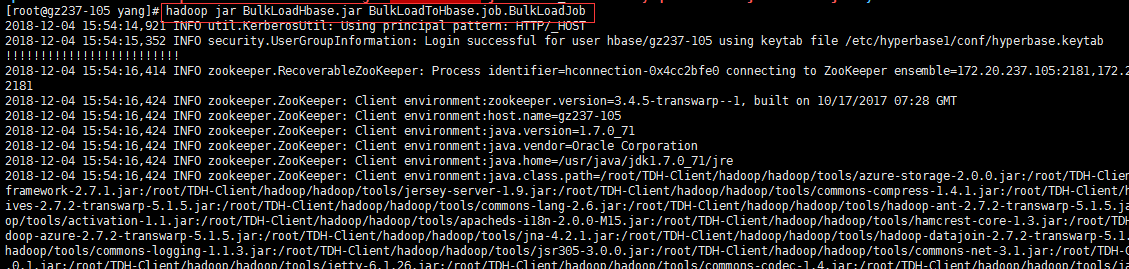
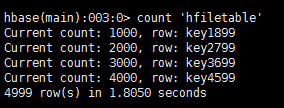
3、使用Mapreduce将数据通过Bulkload入到hbase表中
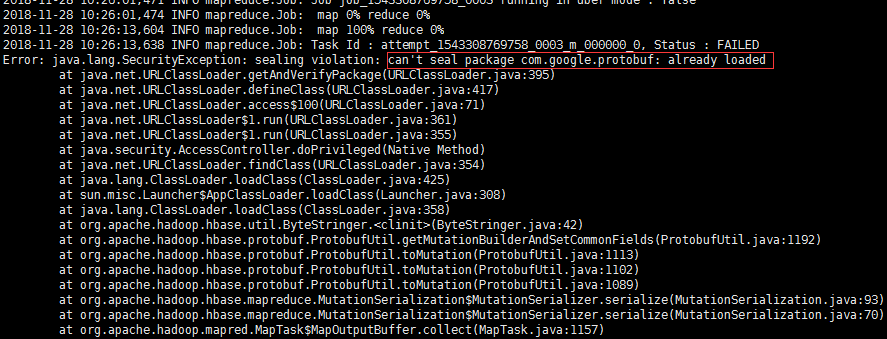
解决:protobuf-java-2.5.0.jar因为包冲突,由于我创建project时,结构为父模块和子模块,可能在导包的时候,被其他子模块的包给冲突了。因此,我新建了一个project重新打包到linux运行成功。

通过BulkLoad快速将海量数据导入到Hbase(TDH,kerberos认证)的更多相关文章
- 在Spark上通过BulkLoad快速将海量数据导入到Hbase
我们在<通过BulkLoad快速将海量数据导入到Hbase[Hadoop篇]>文中介绍了一种快速将海量数据导入Hbase的一种方法,而本文将介绍如何在Spark上使用Scala编写快速导入 ...
- 通过BulkLoad快速将海量数据导入到Hbase
在第一次建立Hbase表的时候,我们可能需要往里面一次性导入大量的初始化数据.我们很自然地想到将数据一条条插入到Hbase中,或者通过MR方式等. 但是这些方式不是慢就是在导入的过程的占用Region ...
- sqoop将关系型的数据库得数据导入到hbase中
1.sqoop将关系数据库导入到hbase的参数说明
- BulkLoad加载本地文件到HBase表
BulkLoad加载文件到HBase表 1.功能 将本地数据导入到HBase中 2.原理 BulkLoad会将tsv/csv格式的文件编程hfile文件,然后再进行数据的导入,这样可以避免大量数据导入 ...
- HBase(三): Azure HDInsigt HBase表数据导入本地HBase
目录: hdfs 命令操作本地 hbase Azure HDInsight HBase表数据导入本地 hbase hdfs命令操作本地hbase: 参见 HDP2.4安装(五):集群及组件安装 , ...
- HBase结合MapReduce批量导入(HDFS中的数据导入到HBase)
HBase结合MapReduce批量导入 package hbase; import java.text.SimpleDateFormat; import java.util.Date; import ...
- 干货 | 快速实现数据导入及简单DCS的实现
干货 | 快速实现数据导入及简单DCS的实现 原创: 赵琦 京东云开发者社区 4月18日 对于多数用户而言,在利用云计算的大数据服务时首先要面临的一个问题就是如何将已有存量数据快捷的导入到大数据仓库 ...
- 使用Spark的newAPIHadoopRDD接口访问有kerberos认证的hbase
使用newAPIHadoopRDD接口访问hbase数据,网上有很多可以参考的例子,但是由于环境使用了kerberos安全加固,spark使用有kerberos认证的hbase,网上的参考资料不多,访 ...
- zookeeper、hbase集成kerberos
1.KDC创建principal 1.1.创建认证用户 登陆到kdc服务器,使用root或者可以使用root权限的普通用户操作: # kadmin.local -q “addprinc -randke ...
随机推荐
- PyQt(Python+Qt)学习随笔:Action功能详解及Designer中的操作方法
老猿Python博文目录 老猿Python博客地址 一.引言 Qt Designer中的部件栏并没Action相关的部件,Action可以在右侧的Action Editor中编辑,如图: 如果没有出现 ...
- Python3安装且环境配置(三)
1.在Window 平台安装 Python3 以下为在 Window 平台上安装 Python3 的简单步骤: 打开WEB浏览器访问http://www.python.org/download/ 在下 ...
- pytorch SubsetRandomSampler 用法和说明
官网:https://pytorch.org/docs/stable/data.html?highlight=subsetrandomsampler#torch.utils.data.SubsetRa ...
- Scrum冲刺_Day04
一.团队展示: 1.项目:light_note备忘录 2.队名:删库跑路队 3.团队成员 队员(不分先后) 项目角色 黄敦鸿 后端工程师.测试 黄华 后端工程师.测试 黄骏鹏 后端工程师.测试 黄源钦 ...
- Spring引用数据库文件配置数据源
例子:引用 druid.properties 在Spring配置文件(applicationContext.xml)引入外部配置文件,需要指定特定的 key才能被正确识别并使用 在原本的 url.us ...
- web前端页面常见优化方法
(1)减少http请求,尽量减少向服务器的请求数量 (2)避免重定向 (3)利用缓存:使用外联式引用CSS.JS,在实际应用中使用外部文件可以提高页面速度,因为JavaScript和CSS文件都能在浏 ...
- Springboot mini - Solon详解(一)- 快速入门
一.Springboot min -Solon 最近号称 Springboot mini 的 Solon框架,得空搞了一把,发觉Solon确实好用,小巧而快速.那Solon到底是什么,又是怎么好用呢? ...
- STL-Vector容量问题:
1.clear,erase ,pop_back() 函数只删除对象,并没有释放vec中的内存,若对象是指针还需要delete:2.在erase,clear,pop_back()删除对象的后,size改 ...
- 协程gevent学习
import gevent def f1(): print(11) gevent.sleep(2) print(33) def f2(): print(22) gevent.sleep(1) prin ...
- 【MindSpore】Ubuntu16.04上成功安装GPU版MindSpore1.0.1
本文是在宿主机Ubuntu16.04上拉取cuda10.1-cudnn7-ubuntu18.04的镜像,在容器中通过Miniconda3创建python3.7.5的环境并成功安装mindspore_g ...