【原创】xenomai与VxWorks实时性对比(资源抢占上下文切换对比)
版权声明:本文为本文为博主原创文章,转载请注明出处。如有问题,欢迎指正。博客地址:https://www.cnblogs.com/wsg1100/
(下面数据,仅供个人参考)
可能大部分人一直好奇VxWorks与xenomai对比,实时性孰优孰劣,正好笔者最近要做一个这方面的对比。声明:下面数据,仅供个人参考,有不对的地方还请指出。
本文继上一篇文章【原创】xenomai与VxWorks实时性对比(Jitter对比),主要对比VxWorks与xenomai两个硬实时操作系统在对各类资源操作时,任务抢占切换的耗时。
一、环境
简单介绍一下环境:
硬件平台:双核cortex-A15处理器,CPU频率1.5GHZ,内存2GB。
xenomai:Linux-4.19+xenomai 3.1,具体配置:略;
VxWorks:VxWorks 7,具体配置:略;
注:
- 由于VxWorks benchmark测试包含很多测试项,以下数据为其中包含的几项,每项测试2万次;xenomai与其一致。
- 既然对比,那么测试方法、数据处理就得和VxWorks一致,所以xenomai测试用例实现参考VxWorks benchmark测试用例。
- xenomai的数据为用户态测试,VxWorks数据为内核态测试,测试本身xenomai就处于劣势,哈哈,有兴趣的小伙伴可以将测试用例在xenomai内核态写一份看看。
- xenomai测试用例使用Alchemy API编写,Alchemy API是一层posix接口的封装,所以Alchemy API性能可能弱于POSIX接口。
二、 指标概念
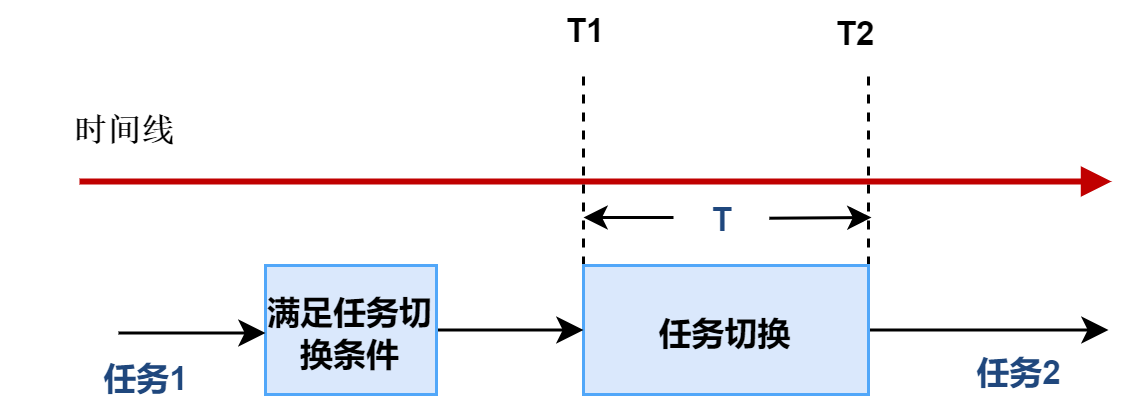
任务切换时间(task switching time),定义为系统在两个独立的、处于就绪态并且具有相同优先级的任务之间切换所需要的时间。
切换所需的时间主要取决于保存任务上下文所用的数据结构以及操作系统采用的调度算法的效率。产生任务切换的原因可以是资源可得,信号量的获取等。任务切换是任一多任务系统中基本效率的测量点,它是同步的,非抢占的。影响任务切换的因素有:主机CPU的结构,指令集以及CPU特性等
2.1 单核CPU
即测试相关的任务运行在同一CPU核上,这里表示单核上的上下文切换。
2.1.1 信号量响应上下文切换时间
信号量响应时间是指从一个任务释放信号量到另一个等待该信号量的任务被激活的时间延迟。 在RTOS中,通常有许多任务同时竞争某一共享资源,基于信号量的互斥访问保证了任一时刻只有一个任务能够访问公共资源。信号量响应时间反映了与互斥有关的时间开销,因此也是衡量RTOS实时性能的一个重要指标。
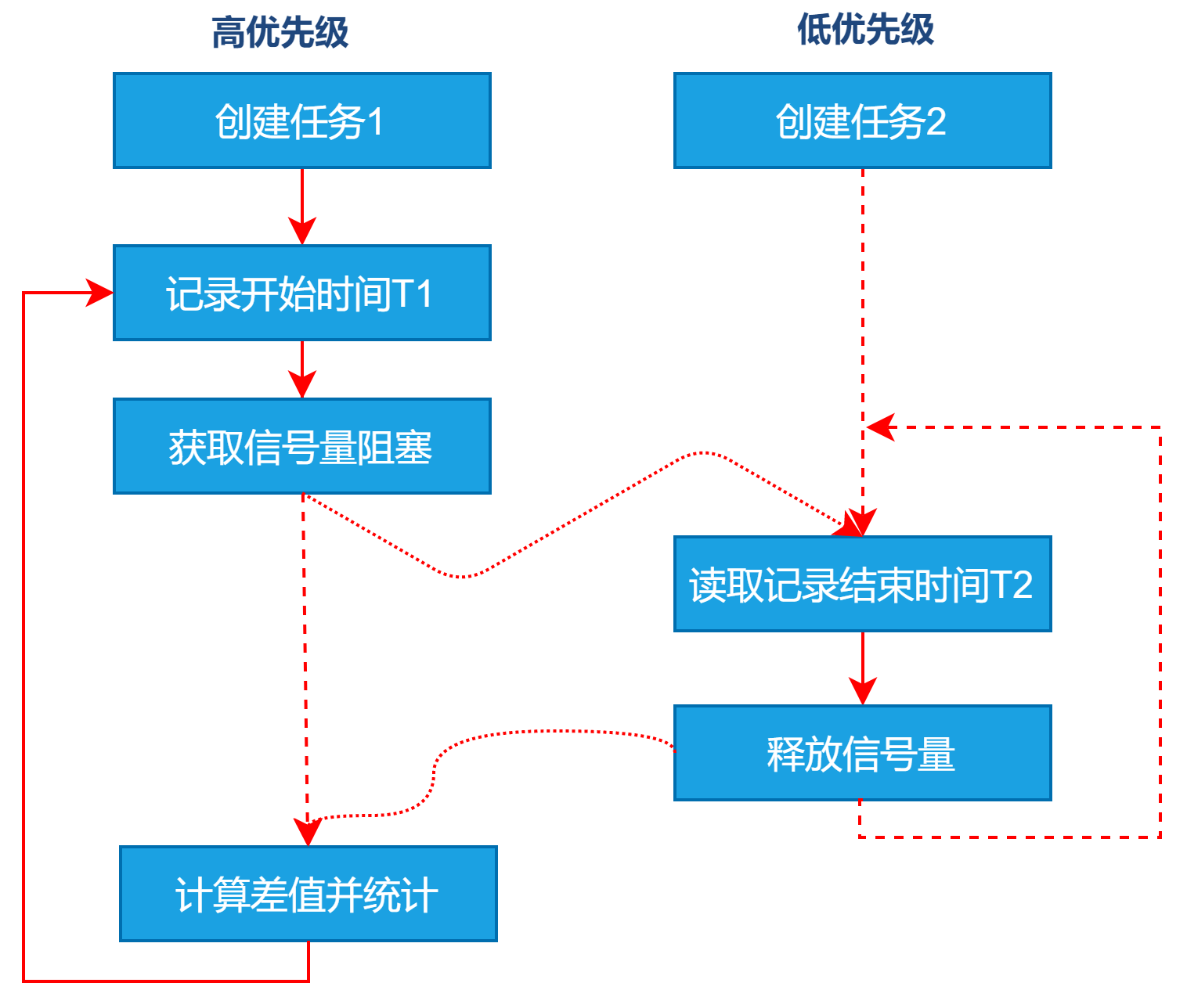
- bmCtxSempend
① 创建两个任务:高优先级任务$Task1$ 和 优先级任务$Task2$;
②$Task1$先非阻塞获取信号量,确保信号量为空。
③$Task1$记录当前时间T1,再次获取信号量导致挂起;
④ 上下文切换到低优先级任务$Task2$运行,$Task2$读取时间T2,再释放信号量;
⑤$Task1$得到信号量恢复运行。计算切换时间$T = T2 - T1$,反复进行②~⑤操作。
⑥最终统计最大值、最小值、平均值。
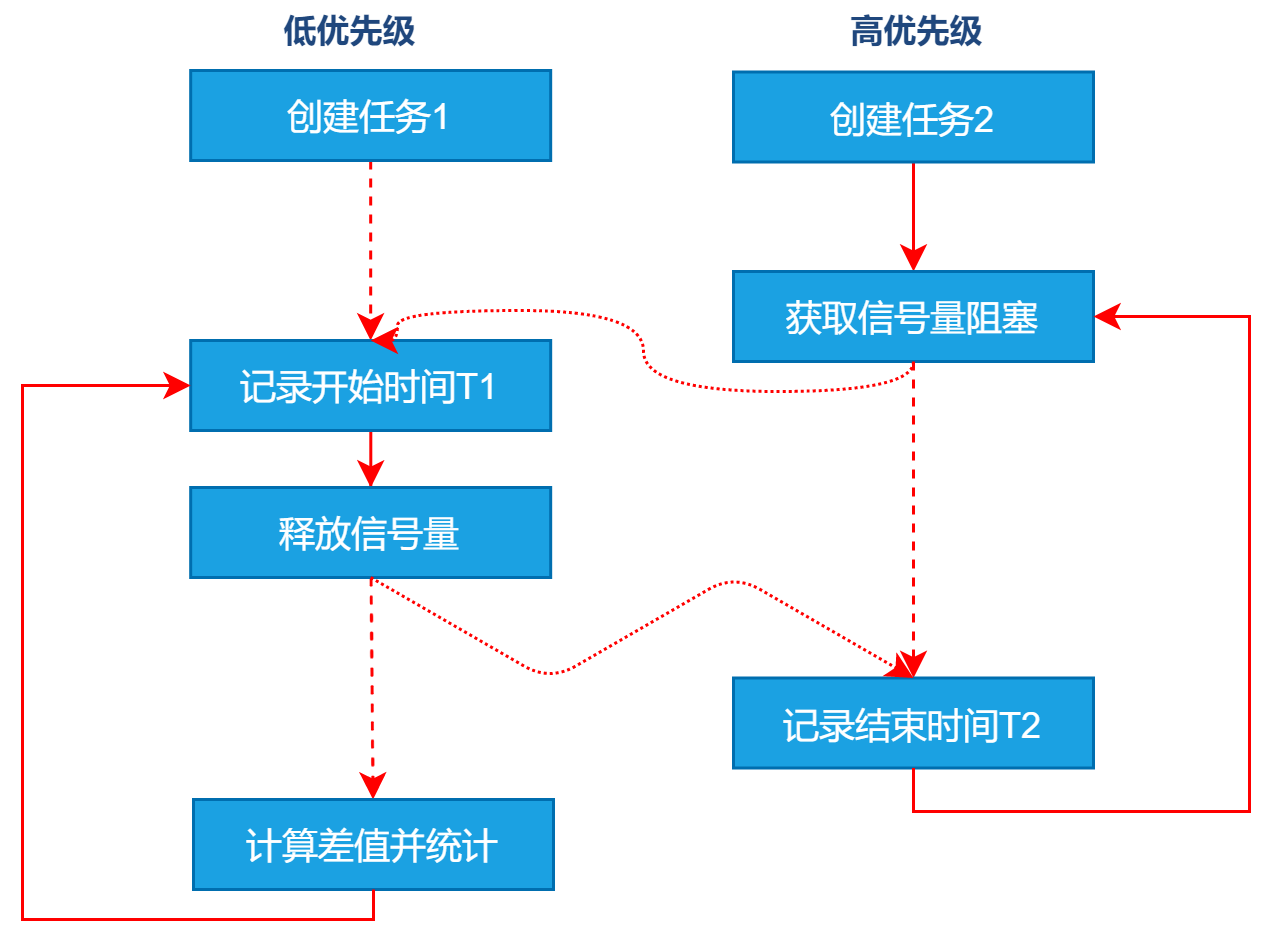
- bmCtxSemunpend
① 创建两个任务:高优先级任务$Task1$ 和 优先级任务$Task2$;
②$Task1$获取信号量导致挂起;
③上下文切换到低优先级任务$Task2$运行,$Task2$读取时间$T_1$,再释放信号量;
④ 高优先级$Task1$得到信号量恢复运行,读取时间$T_2$。进入下一次循环,反复进行②~⑤操作。
⑤ 最终统计最大值、最小值、平均值。
2.1.2 消息队列响应上下文切换时间
与信号量响应时间类似,是指从一个任务发送消息队列到另一个等待该消息队列的任务被激活的时间延迟。
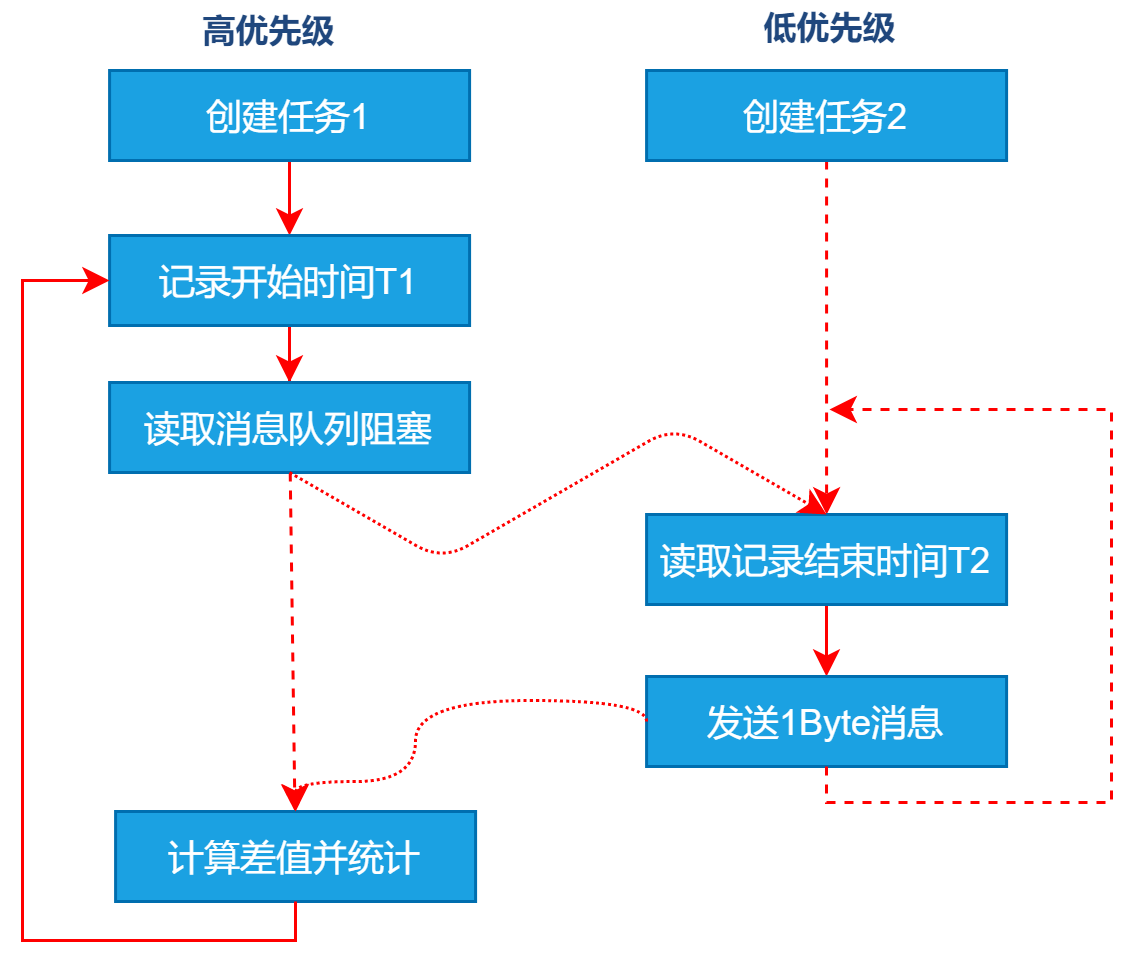
- bmCtxMsgQPend
① 创建两个任务:高优先级任务$Task1$ 和 优先级任务$Task2$;
② $Task1$记录当前时间T1,获取读取消息队列导致阻塞挂起;
③ 上下文切换到低优先级任务$Task2$运行,$Task2$读取时间T2,再向消息队列发送Byte数据,发送后阻塞;
④ $Task1$消息可用恢复运行。计算切换时间$T = T2 - T1$,反复进行②~⑤操作。
⑤ 最终统计最大值、最小值、平均值。
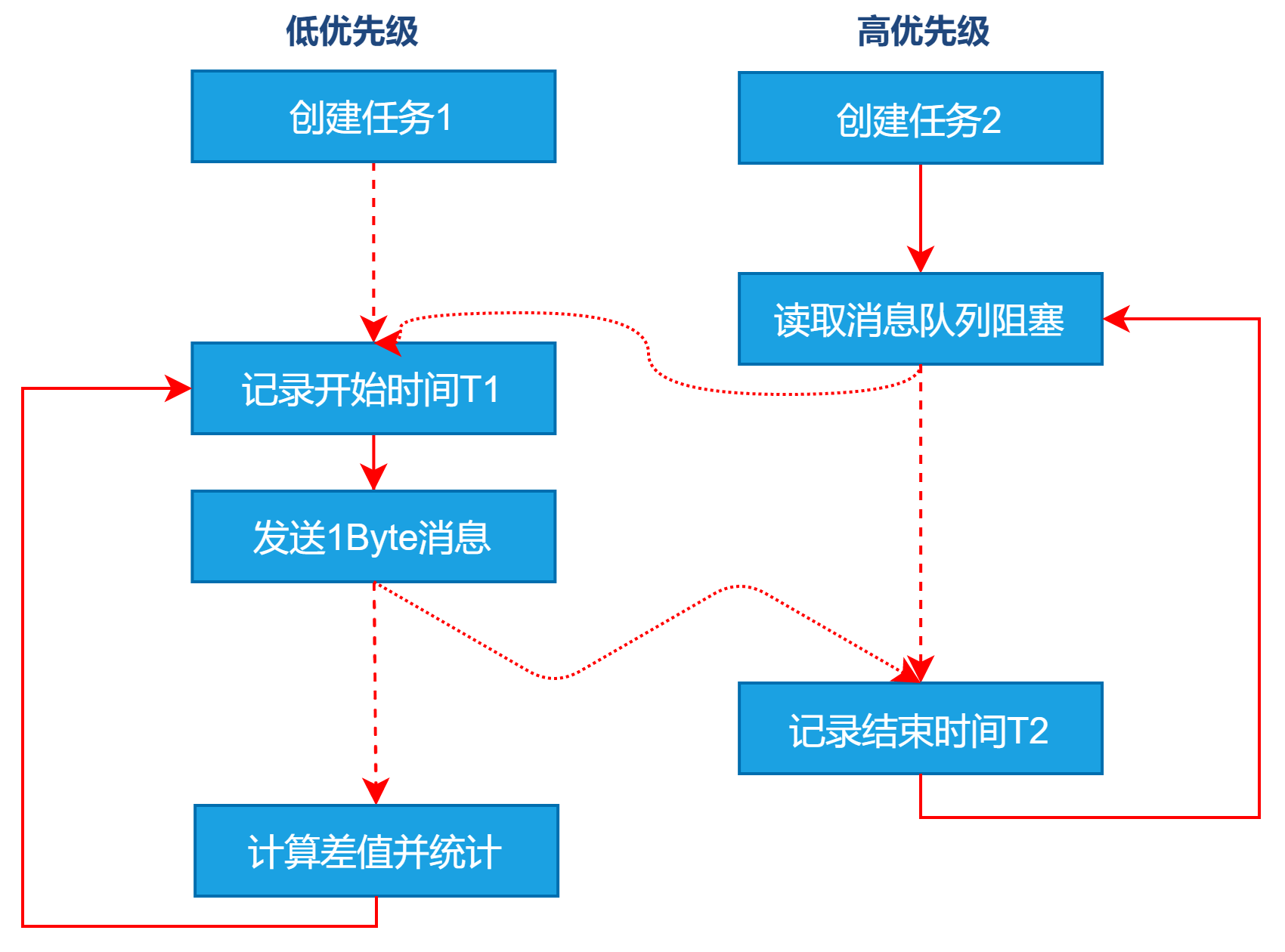
- bmCtxMsgQunPend
① 创建两个任务:高优先级任务$Task1$ 和 优先级任务$Task2$;
②$Task1$接收消息导致挂起;
③上下文切换到低优先级任务$Task2$运行,$Task2$读取时间T1,发送1Byte消息;
④ 高优先级$Task1$消息可用恢复运行,读取时间T2。进入下一次循环,反复进行②~⑤操作。
⑤ 最终统计最大值、最小值、平均值。
2.1.3 事件响应上下文切换时间
也就是对于event操作的上下文切换,与上面两种类似不再说明。
2.1.4 任务上下文切换时间
以上测试中,在资源上任务切换,下面是单纯的优先级调度下的任务切换。
需要注意的是:VxWorks中priority数值越高,优先级越低,xenomai相反。
① 优先级为50的任务$Task1$ 创建更高优先级40的任务$Task2$;
② $Task2$创建后立即抢占,$Task2$运行后立即降低自身优先级为60,比$Task1$优先级低
③$Task1$此时为最高优先级得到运行,读取时间T1,提升$Task2$优先级为40;
④ $Task2$此时为最高优先级抢占运行,发生一次上下文切换;
⑤ $Task2$运行后立即降低自身优先级为60;
⑥$Task1$此时为最高优先级得到运行,发生一次上下文切换;
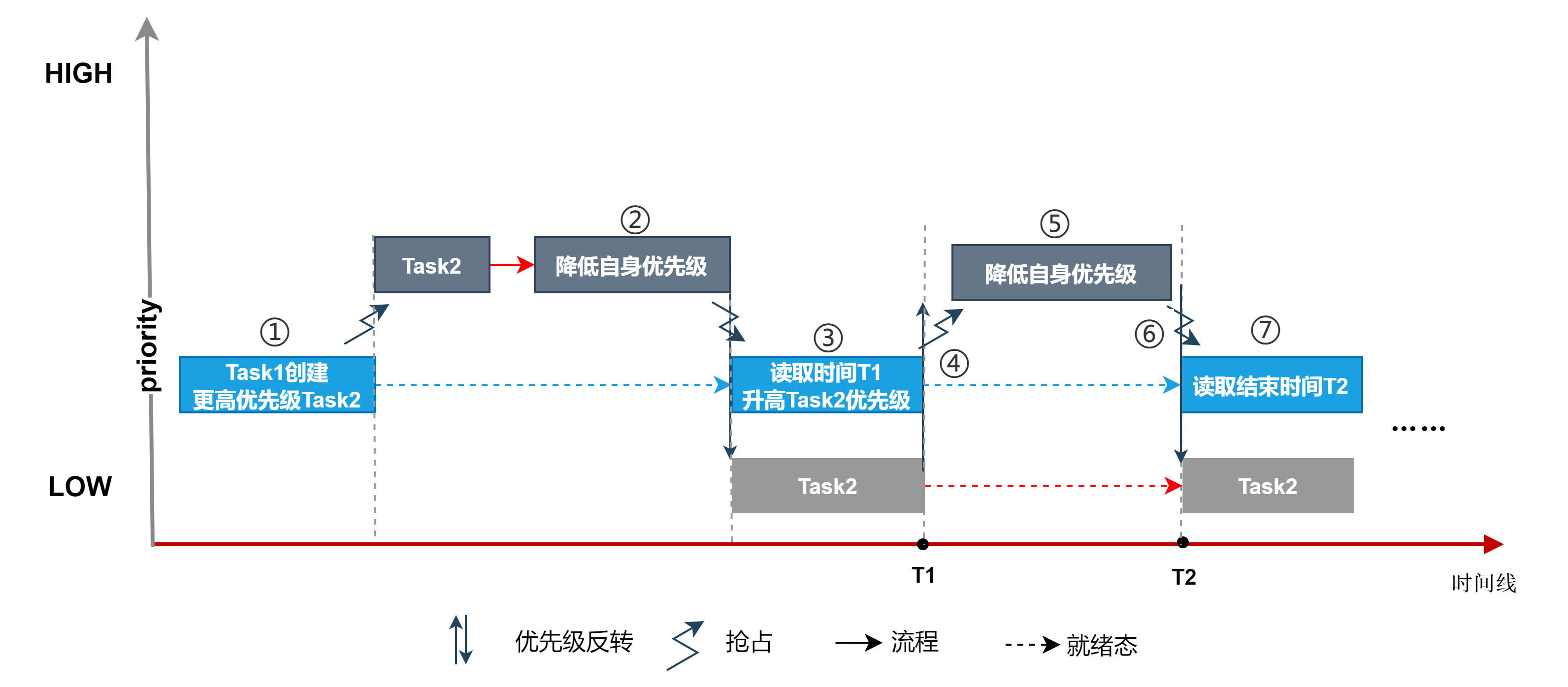
测试时间$T=T_2-T_1$,包含了1次提升优先级操作耗时$T_r$、1次降低优先级操作耗时$T_l$、2次任务切换$T_{sw}$、2次读取时间戳耗时$T_{rt}$。所以上下文切换时间$T_{sw}=\frac{T-T_r-T_l-2T_{rt}}{2}$。
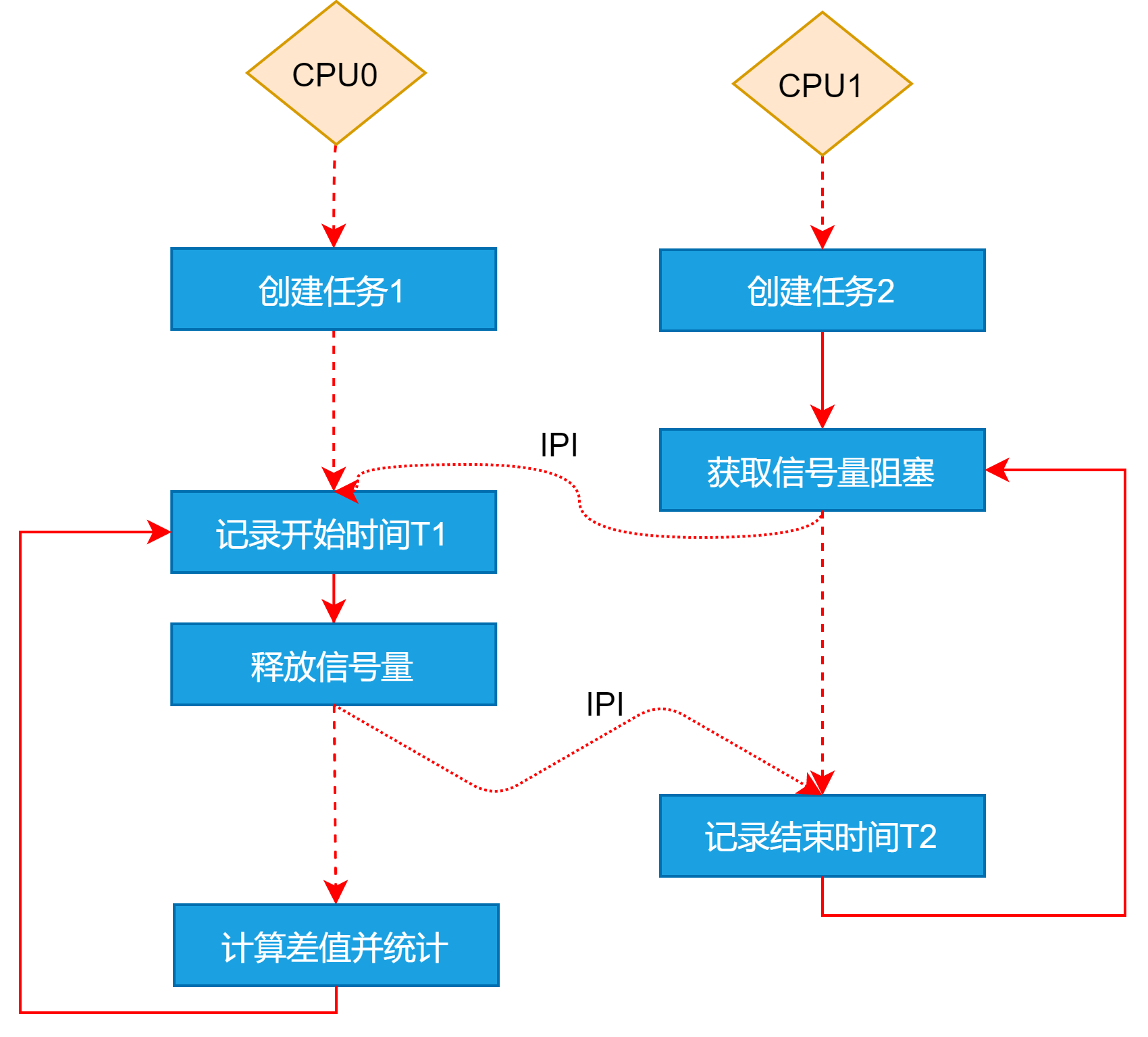
2.1 SMP
实时任务分别运行在不同CPU上,其任务切换在上述的基础上,还包含了多核间IPI 通信(Interrupt-Procecesorr Interrupt处理器间的中断)耗时。
以bmCtxSemunpend示例如下,其余的类似不再赘述。
三、 结果对比
3.1 单核
| Vxworks | avg | min | max |
|---|---|---|---|
| bmCtxSemPend | 1.387 | 0.162 | 5.205 |
| bmCtxSemUnpend | 1.389 | 0.162 | 5.205 |
| bmCtxMsgQPend | 1.719 | 0.325 | 6.181 |
| bmCtxMsgQUnpend | 2.183 | 0.487 | 7.807 |
| bmCtxEventPend | 1.349 | 0.000 | 5.042 |
| bmCtxEventUnpend | 1.466 | 0.162 | 5.367 |
| bmCtxTaskSwitch | 0.975 | 0.000 | 4.635 |
| Xenomai | avg | min | max |
|---|---|---|---|
| bmCtxSemPend | 3.597 | 3.252 | 6.345 |
| bmCtxSemUnpend | 3.735 | 3.415 | 7.482 |
| bmCtxMsgQPend | 4.228 | 3.903 | 6.833 |
| bmCtxMsgQUnpend | 5.368 | 5.042 | 8.622 |
| bmCtxEventPend | - | - | - |
| bmCtxEventUnpend | - | - | - |
| bmCtxTaskSwitch | 8.365 | 0.326 | 63.522 |
可以看到xenomaibmCtxTaskSwitch数据比较差,为什么什么会这样呢?VxWorks测试程序与内核都处于内核态(同一地址空间),而xenomai测试则是在用户态测试,可以回到2.1.4小节,其中$T=T_2-T_1$这段时间内的每一个操作都是必须发起实时系统调用来完成的,其中修改优先级还涉及Linux线程部分,除此之外由于系统调用路径复杂,每个系统调用时间不是确定的,比如前后两次修改优先级操作的时间是不等的,这就造成计算出的$T_{sw}$失真。通俗的说这个测试方法不适合xenomai用户态,将该测试放到xenomai内核态才与VxWorks具有可比性。
另外,本测试基于xenomai 3.1。xenomai任务对event资源不会发生阻塞唤醒(非抢占)了,xenomai3.0.8不存在这个问题,所以这两项没有测试数据。有兴趣的小伙伴可以研究一下,顺便还能向社区提个issue或patch,呵呵~~。
3.2 SMP
VxWorks没有启用SMP,所以这部分没有VxWorks的数据,只有xenomai的。
| Xenomai | avg | min | max |
|---|---|---|---|
| CtxSmpAffinitySemUnPend | 3.826 | 3.578 | 8.296 |
| CtxSmpAffinityMsgQUnPend | 5.262 | 4.879 | 8.133 |
| CtxSmpNoAffinitySemUnPend | 3.766 | 3.415 | 6.181 |
| CtxSmpNoAffinityMsgQUnPend | 5.322 | 5.042 | 9.597 |
【原创】xenomai与VxWorks实时性对比(资源抢占上下文切换对比)的更多相关文章
- 【原创】xenomai与VxWorks实时性对比(Jitter对比)
版权声明:本文为本文为博主原创文章,转载请注明出处.如有问题,欢迎指正.博客地址:https://www.cnblogs.com/wsg1100/ (下面数据,仅供个人参考) 可能大部分人一直好奇Vx ...
- 【原创】有利于提高xenomai 实时性的一些配置建议
版权声明:本文为本文为博主原创文章,转载请注明出处.如有错误,欢迎指正. @ 目录 一.影响因素 1.硬件 2.BISO(X86平台) 3.软件 4. 缓存使用策略与GPU 二.优化措施 1. BIO ...
- 【原创】ARM平台内存和cache对xenomai实时性的影响
目录 1. 问题概述 2. stress 内存压力原理 2. cache 因素 2.1 未加压 2.2 加压(cpu/io) 3. 内存管理因素 3.1 内存分配/释放 3.2 MMU拥塞 4 总结 ...
- 【原创】xenomai内核解析--实时内存管理--xnheap
目录 一. xenomai内存池管理 1.xnheap 2. xnpagemap 3. xnbucket 4. xnheap初始化 5. 内存块分配 5.1 小内存分配流程(<= 2*PAGE_ ...
- 【原创】xenomai内核解析--实时IPC概述
版权声明:本文为本文为博主原创文章,转载请注明出处.如有问题,欢迎指正.博客地址:https://www.cnblogs.com/wsg1100/ 目录 1.概述 2.Real-time IPC 2. ...
- 为树莓派添加一个强实时性前端[原创cnblogs.com/helesheng]
树莓派是最近流行嵌入式平台,其自由的开源特性以及低廉的价格,吸引了来 自全球的大量极客和计算机大咖的关注.来自各大树莓派社区的幕后英雄,无私地在这个开源硬件平台上做了大量的工作,将其打造成了世界上通用 ...
- Linux操作系统实时性分析
1. 概述 选择一个合适的嵌入式操作系统,可以考虑以下几个因素: 第一是应用.如果你想开发的嵌入式设备是一个和网络应用密切相关或者就是一个网络设备,那么你应该选择用嵌入式Linux或者uCLinux ...
- Linux 2.6 内核实时性分析 (完善中...)
经过一个月的学习,目前对linux 下驱动程序的编写有了入门的认识,现在需要着手实践,编写相关的驱动程序. 因为飞控系统对实时性有一定的要求,所以先打算学习linux 2.6 内核的实时性与任务调 ...
- vxworks 实时操作系统
VxWorks 是美国 Wind River System 公司( 以下简称风河公司 ,即 WRS 公司)推出的一个实时操作系统.Tornado 是WRS 公司推出的一套实时操作系统开发环境,类似Mi ...
随机推荐
- electron自定义最小化,最大化和关闭按钮
Electron ipcRenderer 模块 ipcRenderer 模块是一个 EventEmitter 类的实例. 它提供了有限的方法,你可以从渲染进程向主进程发送同步或异步消息. 也可以收到主 ...
- C#中String与byte[]的相互转换
从文件中读取字符串 string filePath = @"C:\Temp.xml"; string xmlString= File.ReadAllText(filePath); ...
- bzoj3289Mato的文件管理
bzoj3289Mato的文件管理 题意: 一共有n份资料,每天随机选一个区间[l,r],Mato按文件从小到大的顺序看编号在此区间内的这些资料.他先把要看的文件按编号顺序依次拷贝出来,再用排序程序给 ...
- mysql groupby 字段合并问题(group_concat)
在我们的日常mysql查询中,我们可能会遇到这样的情况: 对表中的所有记录进行分类,并且我需要得到每个分类中某个字段的全部成员. 上面的话,大家看起来可能不太好懂,下面举一个例子来给大家说明. 现在我 ...
- 【测试工具】这些APP实用测试工具,不知道你就out了!
本期,我将给大家介绍14款实用的测试工具,希望能够帮到大家!(建议收藏) UI自动化测试工具 1. uiautomator2 Github地址:https://github.com/openatx/u ...
- 3个月不发工资,拖延转正?2天跳槽软件测试成功,9.5k他不香吗!
今天聊到的小哥哥很悲催又很神奇,身处武汉的他,正好赶上了疫情,不仅长达3个月没有发工资,拖延转正,还要降薪,三重打击,实名悲催. 不破不立,试用期80%再打8折,怎么跳槽工资都得比这高,果然,仅仅两天 ...
- 记一次webpack打包的问题
记一次webpack打包的问题 在webpack打包中开启了webpack-bundle-analyzer,发现了一个chunk:tinymce  在整个项目中查找,只有一个未被使用的组件中有如下代 ...
- 修改虚拟机中的centos系统分辨率
使用vmware虚拟机安装centos系统,默认分辨都很低,可使用以下方法修改虚拟机中centos系统的分辨率 1,# vi /boot/grub/grub.conf 2,找到 kernel 的那一行 ...
- 题解 CF785E 【Anton and Permutation】
考虑用分块解决这个题,一次交换对当前逆序对个数的影响是,加上两倍的在区间\([l+1,r-1]\)中比\(a_r\)小的元素个数,减去两倍的在区间\([l+1,r-1]\)中比\(a_l\)小的元素个 ...
- linux nginx 部署多套服务(以react包为例)
前言 今天我特地写下笔记,希望可以完全掌握这个东西,也希望可以帮助到任何想对学习这个东西的同学. 本文用nginx部署服务为主要内容,基于CentOs 7.8系统. 文档版本:1.0.1 更新时间:2 ...