Web Scraping using Python Scrapy_BS4 - Software
Install the following software before web scraping.
- Visual Studio Code
- Python and Pip
pip install virtualenv

virtualenv myenv

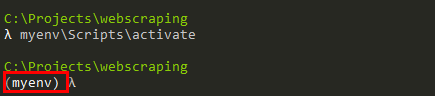
Activating a Virtual Environment
Myenv\scripts\activate -Windwos
Source myenv/scripts/avtivate -Mac
- BeautifulSoup
Documents: https://www.crummy.com/software/BeautifulSoup/bs4/doc/
pip install bs4
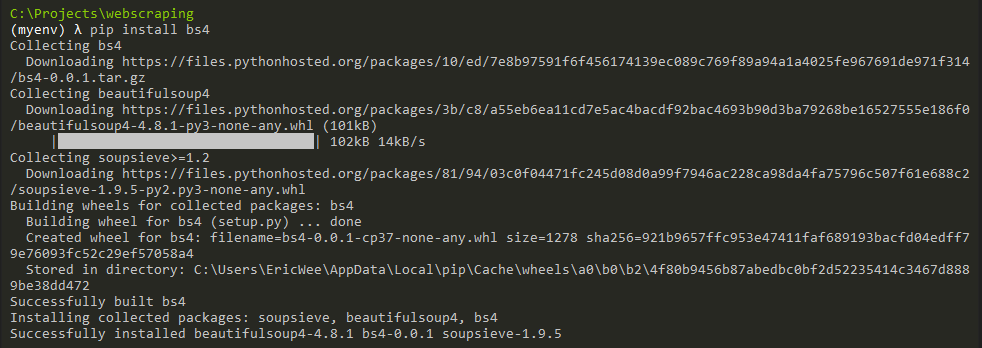
Check the installation status of beautiful soup.

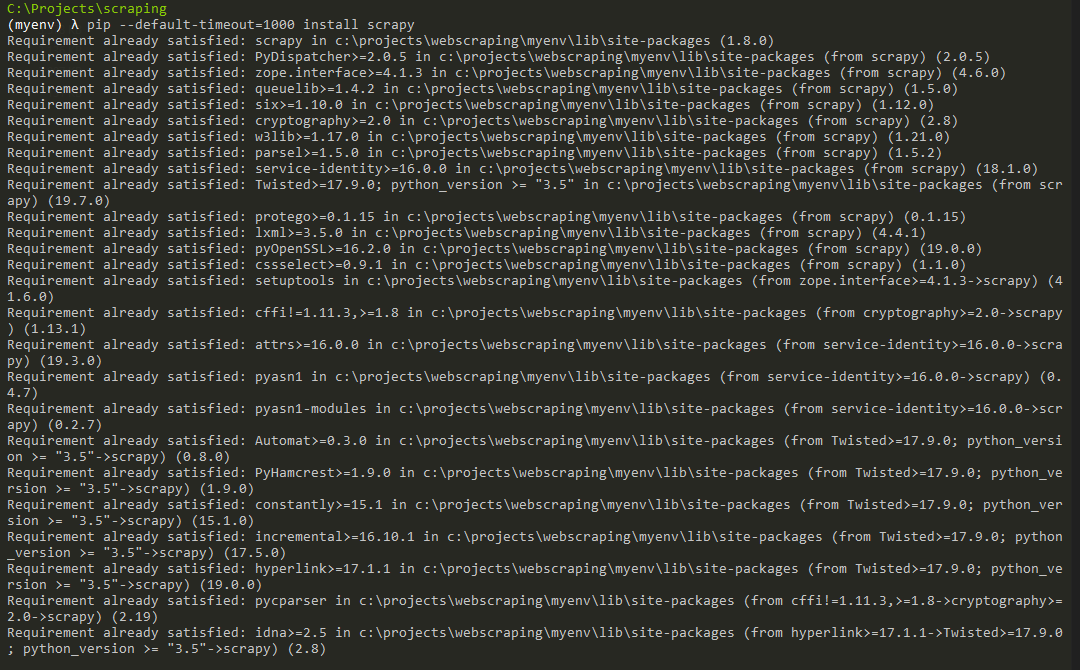
- Scapy
Documents:https://scapy.readthedocs.io/en/latest/
pip install scrapy
Web Scraping using Python Scrapy_BS4 - Software的更多相关文章
- Web Scraping using Python Scrapy_BS4 - using BeautifulSoup and Python
Use BeautifulSoup and Python to scrap a website Lib: urllib Parsing HTML Data Web scraping script fr ...
- Web Scraping using Python Scrapy_BS4 - Introduction
What is Web Scraping This is also referred to as web harvesting and web data extraction. This is the ...
- Web Scraping using Python Scrapy_BS4 - using Scrapy and Python(2)
Scrapy Architecture Creating a Spider. Spiders are classes that you define that Scrapy uses to scrap ...
- Web Scraping using Python Scrapy_BS4 - using Scrapy and Python(1)
Create a new Scrapy project first. scrapy startproject projectName . Open this project in Visual Stu ...
- Web Scraping with Python读书笔记及思考
Web Scraping with Python读书笔记 标签(空格分隔): web scraping ,python 做数据抓取一定一定要明确:抓取\解析数据不是目的,目的是对数据的利用 一般的数据 ...
- <Web Scraping with Python>:Chapter 1 & 2
<Web Scraping with Python> Chapter 1 & 2: Your First Web Scraper & Advanced HTML Parsi ...
- Web scraping with Python (part II) « Jean, aka Sig(gg)
Web scraping with Python (part II) « Jean, aka Sig(gg) Web scraping with Python (part II)
- 阅读OReilly.Web.Scraping.with.Python.2015.6笔记---Crawl
阅读OReilly.Web.Scraping.with.Python.2015.6笔记---Crawl 1.函数调用它自身,这样就形成了一个循环,一环套一环: from urllib.request ...
- 阅读OReilly.Web.Scraping.with.Python.2015.6笔记---找出网页中所有的href
阅读OReilly.Web.Scraping.with.Python.2015.6笔记---找出网页中所有的href 1.查找以<a>开头的所有文本,然后判断href是否在<a> ...
随机推荐
- 三星note8港版如何显示电量百分比呢?
设置-通知-状态栏,显示电量百分比打钩即可.
- 2020年最佳Java调试工具(翻译)
调试是应用程序开发周期不可或缺的一部分.用Java或任何其他语言编写程序时,每个开发人员应解决的首要问题之一是可靠的调试工具的可用性. 所使用的工具类型可能影响或破坏应用程序的调试过程,因此至关重要的 ...
- JVM源码分析之Object.wait/notify(All)完全解读
概述 本文其实一直都想写,因为各种原因一直拖着没写,直到开公众号的第一天,有朋友再次问到这个问题,这次让我静心下来准备写下这篇文章,本文有些东西是我自己的理解,比如为什么JDK一开始要这么设计,初衷是 ...
- 微信小程序入门-刘志敏-专题视频课程
微信小程序入门-269人已学习 课程介绍 微信小程序入门基础,给入门级程序员好的教程.教程中对小程序的介绍到小程序的基本使用都做了详细的介绍,教程以实用的实现作为案例,如列表下拉刷新.抽 ...
- v-if和v-show的使用和特点
v-if的特点是每次都会重新删除或创建操作 v-show的特点是每次不会进行DOM的删除和创建操作,只是切换了元素的display:none样式 <div id="app"& ...
- XmlHttpRequest使用及“跨域”问题解决
一. IE7以后对xmlHttpRequest 对象的创建在不同浏览器上是兼容的. 下面的方法是考虑兼容性的,实际项目中一般使用Jquery的ajax请求,可以不考虑兼容性问题. function g ...
- zookeeper 伪集群安装和 zkui管理UI配置
#=======================[VM机器,二进制安装] # 安装环境# OS System = Linux CNT7XZKPD02 4.4.190-1.el7.elrepo.x86_ ...
- \\u4e00-\\u9fa5\
select * from stu where name regexp '[\\u4e00-\\u9fa5\·]{2,10}$'; 结果: name这个字段从后到前 2 到10个字符之内 如果有汉字 ...
- Spring Cloud Alibaba基础教程:Nacos 生产级版本 0.8.0
昨晚Nacos社区发布了第一个生产级版本:0.8.0.由于该版本除了Bug修复之外,还提供了几个生产管理非常重要的特性,所以觉得还是有必要写一篇讲讲这次升级,在后续的文章中也都将以0.8.0版本为基础 ...
- Oracle 11g数据脱敏
Oracle 11g数据脱敏 前言 最近开发人员有个需求,导一份生产库的数据到测试库. 由于生产数据安全需要,需要并允许对导出的数据进行加密脱敏处理. 关于加密和脱敏 个人理解, 加密是通过一系列规则 ...