Spark入门(第1讲)
一、Spark是什么
引用官方文档的一句话
Apache Spark is a unified analytics engine for large-scale data processing.
Apache Spark是用于大规模数据处理的统一分析引擎。
可以从这句话拆分出几个关键点
- 统一
- 大数据
- 分析引擎/计算引擎
何为统一
Spark的主要目标是为编写大数据应用程序提供统一的平台,其中包括统一计算引擎和统一API。
Spark提供一致的,可组合的API来构建应用程序,使得任务的编写更加高效。
例如:使用SQL加载数据,然后使用Spark的ML库评估其上的机器学习模型,引擎能够将这些步骤合并成一次数据扫描。
通用API设计+高性能执行
同时Spark为了实现统一,不仅支持使用自带的标准库,为通用数据分析人物提供统一的API,也支持由开源社区以第三方包形式发布的大量外部库。
何为计算引擎
不同于其他大数据软件平台(例如Hadoop),Spark仅负责加载数据并计算,并不负责数据永久存储(持久化)。因此,Spark可以与多种持久化存储系统结合使用。常用的有以下几种
- 云存储系统(Azure存储、Amazon S3)
- 分布式文件系统(Apache Hadoop)
- 键值存储系统(Apache Cassandra)
- 消息队列系统(Apache Kafka)
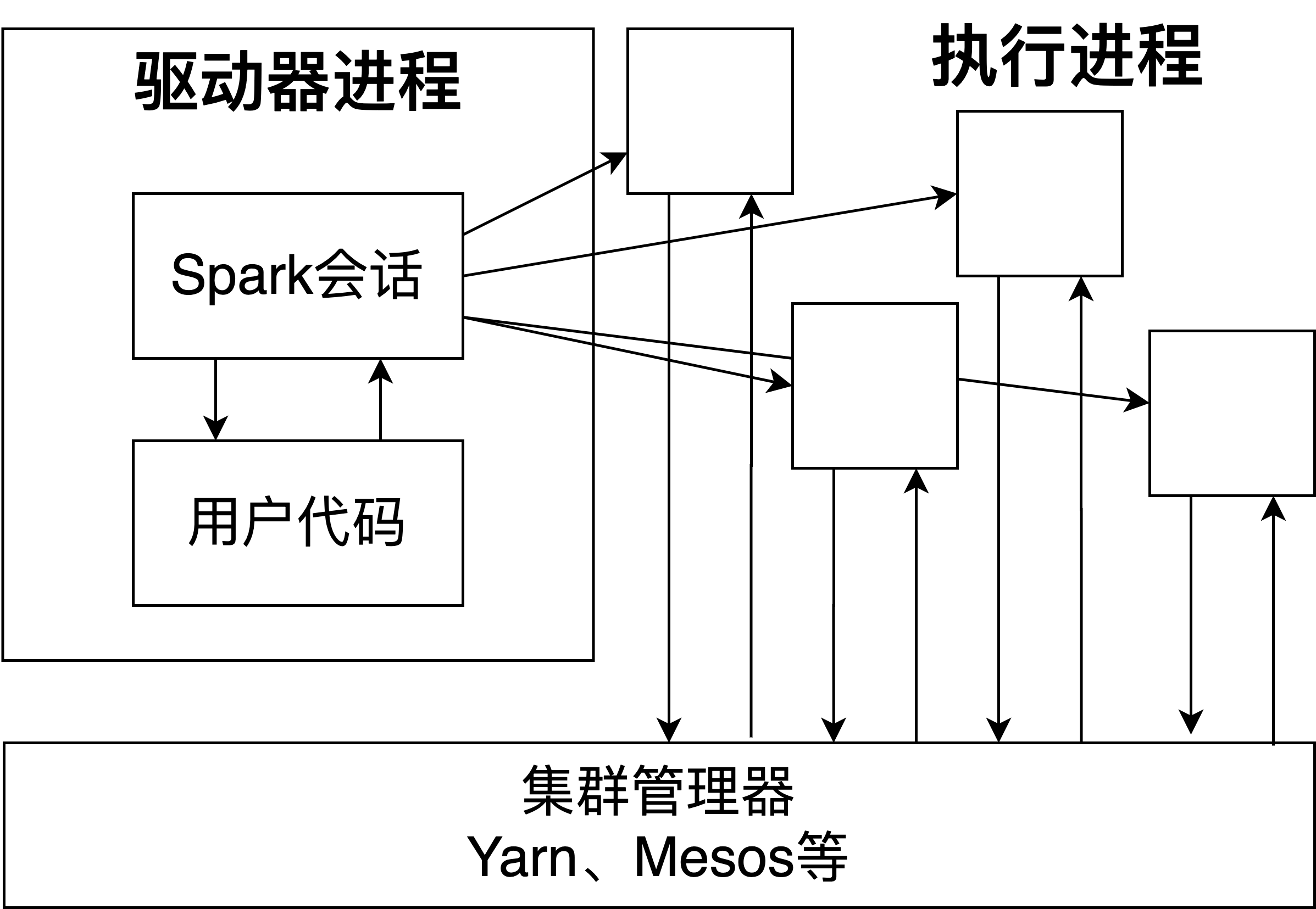
二、Spark基本架构
Spark应用程序由一个驱动器进程和一组执行器进程组成。
驱动进程负责:
- 维护Spark应用程序的相关信息
- 回应用户的程序或输入
- 分析任务并分发给若干执行器处理
驱动器负责:
- 执行驱动器分配给他的代码
- 汇报执行器计算状态给驱动器
这种分发可以交给Spark的集群管理器来处理,在一个任务提交给集群管理器后,集群管理器会将计算资源分配给应用程序。集群管理器可以是三个核心集群管理器之一:Spark独立集群管理器,Yarn、Mesos
三、Spark基本概念
SparkSession
Spark API支持多种语言来启动Spark任务,各种进程通过创建SparkSession的方式将用户命令和数据发送给Spark。
DataFrame
包含行和列的数据表,区别于普通的电子表格,DataFrame支持分布式存储。用于说明这些列和列类型的一些规则称为schema
数据分区
为了让多个执行器并行地工作,Spark将数据分解为多个数据块,每个数据块叫做一个分区
转换操作
将一个抽象的操作指定给一个操作对象,但不会立即执行。有两类转换操作:
指定窄依赖关系(narrow dependency)的转换操作
每个输出分区只影响一个输出分区。
在内存中执行多个转换操作
指定宽依赖关系(wide dependency)的转换操作 ==》shuffle
每个输出分区决定多个输出分区。
将结果写入磁盘
惰性评估(lazy evaluation)
等到绝对需要时才执行计算。
用户表达对数据的一些操作,不会立刻修改数据,而是建立一个作用到原始数据的转换计划。Spark将计划编译为可以在及群众高效运行的流水线式的物理执行计划。等到最后时刻才执行代码。
动作操作
- 在控制台查看数据的动作
- 在某个语言中将数据汇集为原生对象的动作
- 写入输出数据源的动作
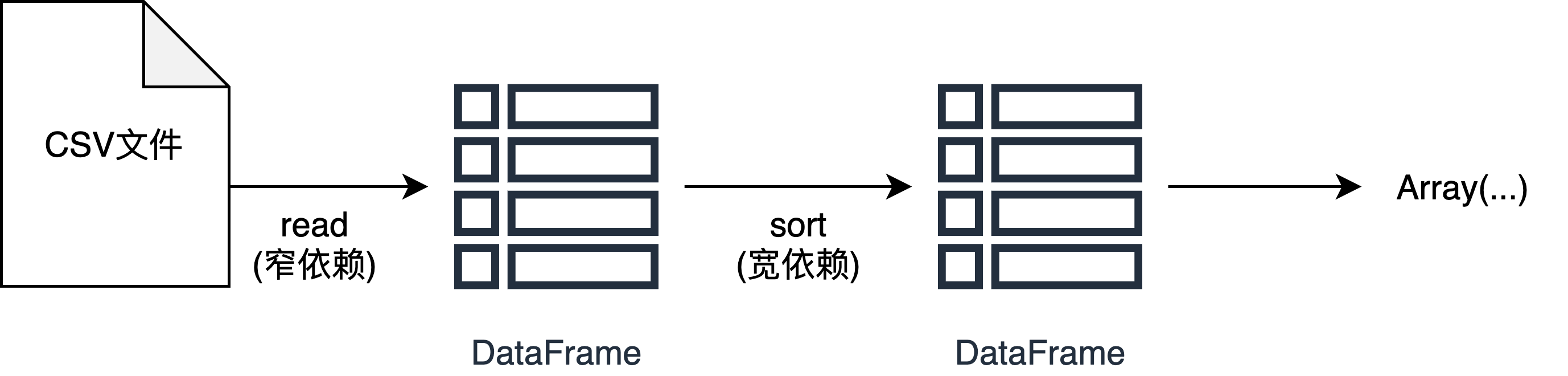
上述概念看着可能比较抽象,用实际例子标识
//创建一个DataFramescala> var flightData2015 = spark.read.option("inferSchema","true").option("header","true").csv("/Users/jacobzheng/IdeaProjects/Spark-The-Definitive-Guide/data/flight-data/csv/2015-summary.csv")//返回flightData2015: org.apache.spark.sql.DataFrame = [DEST_COUNTRY_NAME: string, ORIGIN_COUNTRY_NAME: string ... 1 more field]//取数据scala> flightData2015.take(3)res3: Array[org.apache.spark.sql.Row] = Array([United States,Romania,15], [United States,Croatia,1], [United States,Ireland,344])//排序后取数据scala> flightData2015.sort("count").take(3)res4: Array[org.apache.spark.sql.Row] = Array([Moldova,United States,1], [United States,Croatia,1], [United States,Singapore,1])//取数据scala> flightData2015.take(3)res5: Array[org.apache.spark.sql.Row] = Array([United States,Romania,15], [United States,Croatia,1], [United States,Ireland,344])
从上述例子可以看出
Sort操作不会修改原有的DataFrame,而是生成一个新的DataFrame。
DataFrame和SQL
我理解(仅限于我理解,可能是错的)
DataFrame和SQL都是一种逻辑框架,Spark通过解析这种逻辑编译出一个用于底层执行的执行计划。
DataFrame可以使用简单的函数注册一个表或者视图
flightData2015.createOrReplaceTempView("flightData2015")
通过SparkSql查询,结果将会返回一个DataFrame
spark.sql("select max(count) from flightData2015")
使用DataFrame和SparkSql执行一样的操作,执行计划是一样的。
四、Spark工具集
spark-submit
将测试级别的交互式程序转化为生产级别的应用程序。
spark-submit --class org.apache.spark.examples/SparkPi --master local ../examples/jars/spark-examples_2.11-2.4.6.jar
通过修改master参数,可以将应用程序提交到集群上,集群需要运行Spark standalone集群、Mesos或Yarn。
Dataset
Dataset是一种类型安全的Spark结构化API,与DataFrame不同的是,Dataset api能够让用户用Java/scala定义DataFrame中的每条记录。
//定义一个Datasetscala> case class Flight(DEST_COUNTRY_NAME: String,ORIGIN_COUNTRY_NAME: String,count: BigInt)defined class Flight//读取parquet文件到DataFramescala> var flightDF = spark.read.parquet("/Users/jacobzheng/IdeaProjects/Spark-The-Definitive-Guide/data/flight-data/parquet/2010-summary.parquet")flightDF: org.apache.spark.sql.DataFrame = [DEST_COUNTRY_NAME: string, ORIGIN_COUNTRY_NAME: string ... 1 more field]//将DataFrame转换为Datasetscala> val flights = flightDF.as[Flight]flights: org.apache.spark.sql.Dataset[Flight] = [DEST_COUNTRY_NAME: string, ORIGIN_COUNTRY_NAME: string ... 1 more field]
结构化流处理
可以减少延迟并允许增量更新,可以快速地从流式系统中提取数据而几乎不需要修改代码。可以按照传统批式处理作业的模式进行设计,然后将其转换为流式作业。
机器学习和高级数据分析
低级API
SparkR
附录
Spark安装实录
0.环境准备
| 系统版本 | MacOS 10.15.4 |
|---|---|
| MacOS 10.15.4 | 1.8.0_111 |
1.在官网上下载Spark安装包
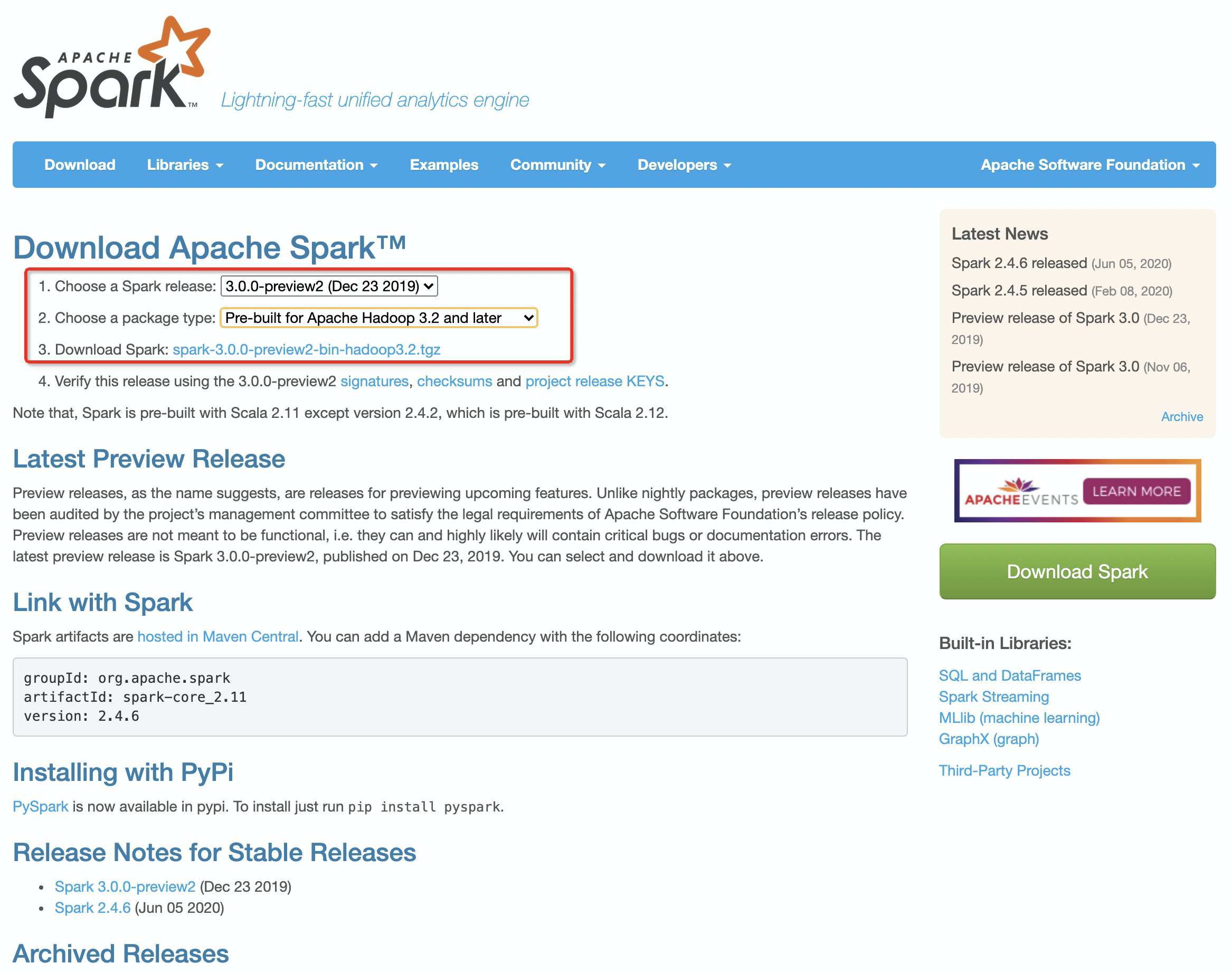
在这里我大胆选择了最新版的Spark+最新版的Hadoop3.2
下载完成后解压即可
ps.我把解压后的目录软链到了~/spark目录下了
2.检查是否可用
#进入Spark目录下~/spark $ bin/spark-shell20/06/11 13:58:53 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableUsing Spark's default log4j profile: org/apache/spark/log4j-defaults.propertiesSetting default log level to "WARN".To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).Spark context Web UI available at http://192.168.199.36:4040Spark context available as 'sc' (master = local[*], app id = local-1591855138249).Spark session available as 'spark'.Welcome to____ __/ __/__ ___ _____/ /___\ \/ _ \/ _ `/ __/ '_//___/ .__/\_,_/_/ /_/\_\ version 3.0.0-preview2/_/Using Scala version 2.12.10 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_111)Type in expressions to have them evaluated.Type :help for more information.scala>
3.配置环境变量**
#sparkexport SAPRK_HOME=/Users/jacobzheng/sparkexport PATH=$PATH:$SPARK_HOME/bin
配置完成后source一下使得环境变量生效
然后直接spark-shell会有和步骤2一样的效果
4.启动master
~/spark $ ./sbin/start-master.shstarting org.apache.spark.deploy.master.Master, logging to /Users/jacobzheng/spark/logs/spark-jacobzheng-org.apache.spark.deploy.master.Master-1-MacBook-Pro.local.out
根据输出提示的目录地址,查看spark服务日志
~/spark $ tail -500f /Users/jacobzheng/spark/logs/spark-jacobzheng-org.apache.spark.deploy.master.Master-1-MacBook-Pro.local.outSpark Command: /Library/Java/JavaVirtualMachines/jdk1.8.0_111.jdk/Contents/Home//bin/java -cp /Users/jacobzheng/spark/conf/:/Users/jacobzheng/spark/jars/* -Xmx1g org.apache.spark.deploy.master.Master --host MacBook-Pro.local --port 7077 --webui-port 8080========================================Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties20/06/11 14:10:53 INFO Master: Started daemon with process name: 74179@MacBook-Pro.local20/06/11 14:10:53 INFO SignalUtils: Registered signal handler for TERM20/06/11 14:10:53 INFO SignalUtils: Registered signal handler for HUP20/06/11 14:10:53 INFO SignalUtils: Registered signal handler for INT20/06/11 14:10:53 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable20/06/11 14:10:53 INFO SecurityManager: Changing view acls to: jacobzheng20/06/11 14:10:53 INFO SecurityManager: Changing modify acls to: jacobzheng20/06/11 14:10:53 INFO SecurityManager: Changing view acls groups to:20/06/11 14:10:53 INFO SecurityManager: Changing modify acls groups to:20/06/11 14:10:53 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(jacobzheng); groups with view permissions: Set(); users with modify permissions: Set(jacobzheng); groups with modify permissions: Set()20/06/11 14:10:53 INFO Utils: Successfully started service 'sparkMaster' on port 7077.20/06/11 14:10:53 INFO Master: Starting Spark master at spark://MacBook-Pro.local:707720/06/11 14:10:54 INFO Master: Running Spark version 3.0.0-preview220/06/11 14:10:54 INFO Utils: Successfully started service 'MasterUI' on port 8080.20/06/11 14:10:54 INFO MasterWebUI: Bound MasterWebUI to 0.0.0.0, and started at http://192.168.199.36:808020/06/11 14:10:54 INFO Master: I have been elected leader! New state: ALIVE
可以看到sparkMaster服务监听了7077端口,MasterUI监听了8080端口
访问 http://localhost:8080/ 来查看到当前master的总体状态。
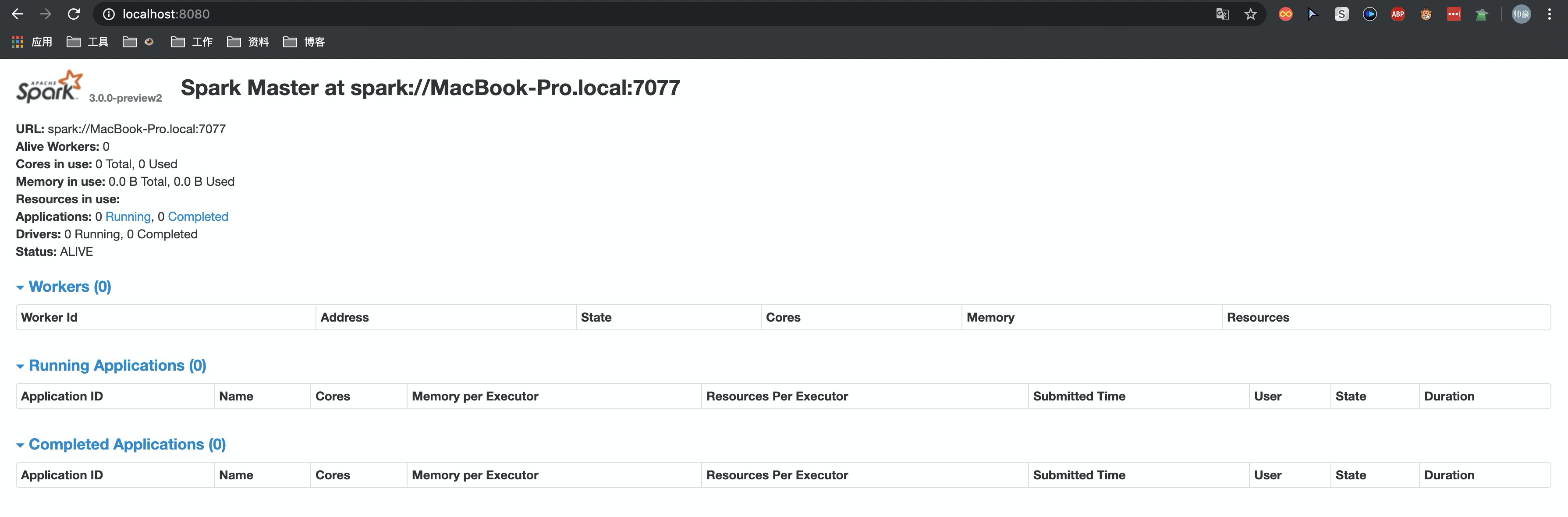
5.启动Worker
~/spark $ spark-class org.apache.spark.deploy.worker.Worker spark://MacBook-Pro.local:7077Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties20/06/11 14:17:13 INFO Worker: Started daemon with process name: 74367@MacBook-Pro.local20/06/11 14:17:13 INFO SignalUtils: Registered signal handler for TERM20/06/11 14:17:13 INFO SignalUtils: Registered signal handler for HUP20/06/11 14:17:13 INFO SignalUtils: Registered signal handler for INT20/06/11 14:17:13 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable20/06/11 14:17:13 INFO SecurityManager: Changing view acls to: jacobzheng20/06/11 14:17:13 INFO SecurityManager: Changing modify acls to: jacobzheng20/06/11 14:17:13 INFO SecurityManager: Changing view acls groups to:20/06/11 14:17:13 INFO SecurityManager: Changing modify acls groups to:20/06/11 14:17:13 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(jacobzheng); groups with view permissions: Set(); users with modify permissions: Set(jacobzheng); groups with modify permissions: Set()20/06/11 14:17:13 INFO Utils: Successfully started service 'sparkWorker' on port 55878.20/06/11 14:17:13 INFO Worker: Starting Spark worker 192.168.199.36:55878 with 16 cores, 15.0 GiB RAM20/06/11 14:17:14 INFO Worker: Running Spark version 3.0.0-preview220/06/11 14:17:14 INFO Worker: Spark home: /Users/jacobzheng/spark20/06/11 14:17:14 INFO ResourceUtils: ==============================================================20/06/11 14:17:14 INFO ResourceUtils: Resources for spark.worker:20/06/11 14:17:14 INFO ResourceUtils: ==============================================================20/06/11 14:17:14 INFO Utils: Successfully started service 'WorkerUI' on port 8081.20/06/11 14:17:14 INFO WorkerWebUI: Bound WorkerWebUI to 0.0.0.0, and started at http://192.168.199.36:808120/06/11 14:17:14 INFO Worker: Connecting to master MacBook-Pro.local:7077...20/06/11 14:17:14 INFO TransportClientFactory: Successfully created connection to MacBook-Pro.local/192.168.199.36:7077 after 41 ms (0 ms spent in bootstraps)20/06/11 14:17:14 INFO Worker: Successfully registered with master spark://MacBook-Pro.local:7077
可以看到启动了一个sparkWorker监听55878,启动了WorkerUI监听8081端口
此时刷新masterUI可以看到多了一个worker的信息
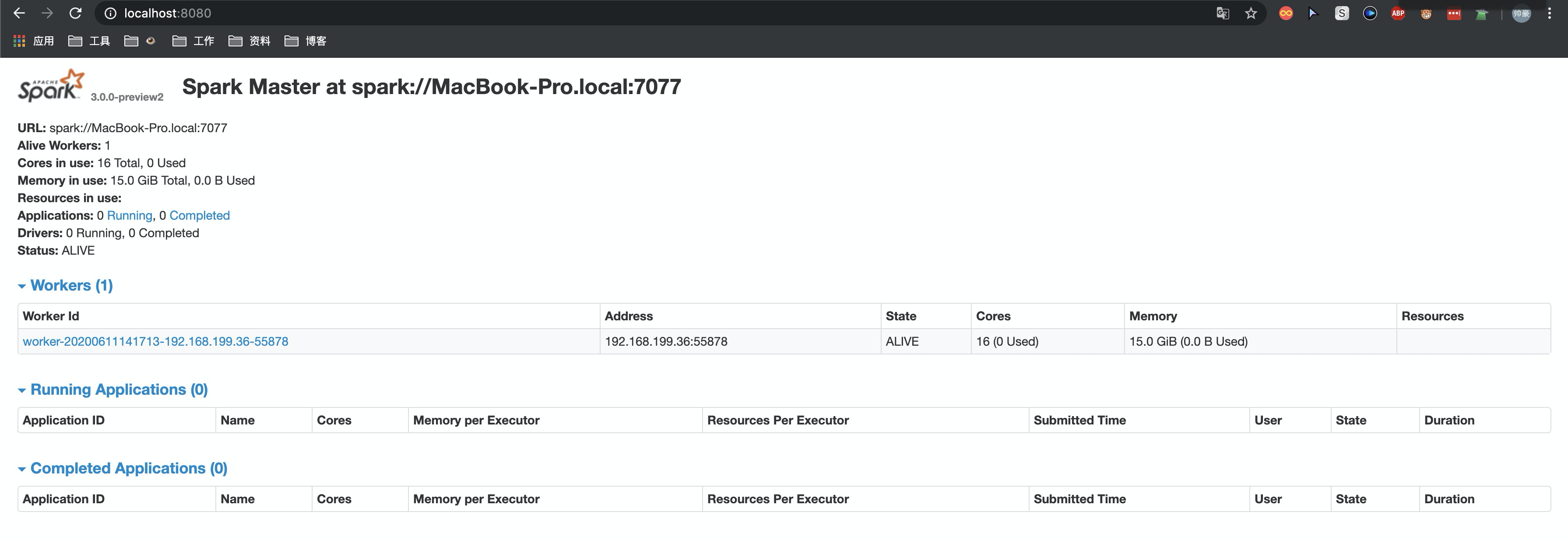
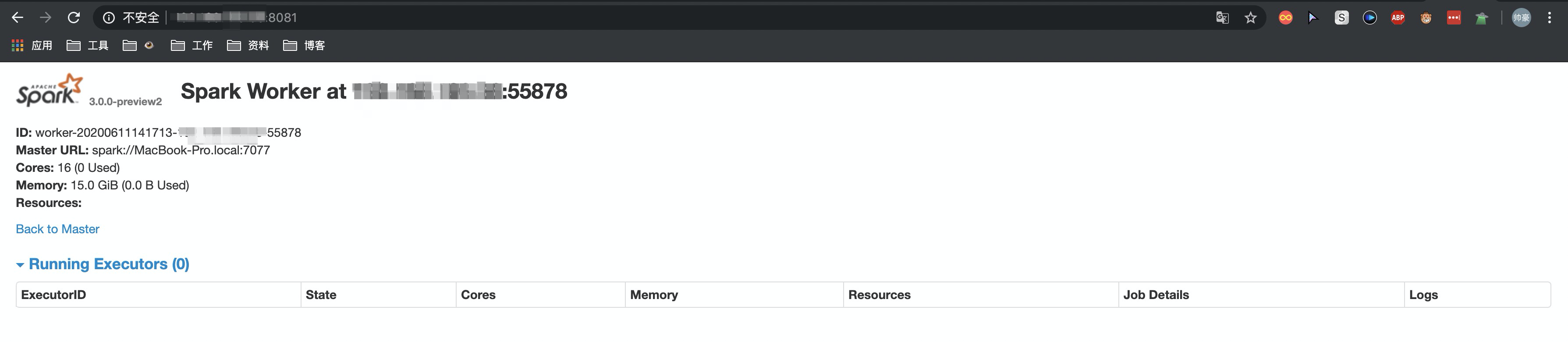
点击进去可以看到worker的信息
Spark入门(第1讲)的更多相关文章
- Spark 入门
Spark 入门 目录 一. 1. 2. 3. 二. 三. 1. 2. 3. (1) (2) (3) 4. 5. 四. 1. 2. 3. 4. 5. 五. Spark Shell使用 ...
- Spark入门实战系列--4.Spark运行架构
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 1. Spark运行架构 1.1 术语定义 lApplication:Spark Appli ...
- Spark入门实战系列--7.Spark Streaming(上)--实时流计算Spark Streaming原理介绍
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark Streaming简介 1.1 概述 Spark Streaming 是Spa ...
- Spark入门实战系列--8.Spark MLlib(上)--机器学习及SparkMLlib简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .机器学习概念 1.1 机器学习的定义 在维基百科上对机器学习提出以下几种定义: l“机器学 ...
- Spark入门——什么是Hadoop,为什么是Spark?
#Spark入门#这个系列课程,是综合于我从2017年3月分到今年7月份为止学习并使用Spark的使用心得感悟,暂定于每周更新,以后可能会上传讲课视频和PPT,目前先在博客园把稿子打好.注意:这只是一 ...
- Spark入门(Python)
Hadoop是对大数据集进行分布式计算的标准工具,这也是为什么当你穿过机场时能看到”大数据(Big Data)”广告的原因.它已经成为大数据的操作系统,提供了包括工具和技巧在内的丰富生态系统,允许使用 ...
- Spark入门(Python版)
Hadoop是对大数据集进行分布式计算的标准工具,这也是为什么当你穿过机场时能看到”大数据(Big Data)”广告的原因.它已经成为大数据的操作系统,提供了包括工具和技巧在内的丰富生态系统,允许使用 ...
- Spark入门实战系列--10.分布式内存文件系统Tachyon介绍及安装部署
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Tachyon介绍 1.1 Tachyon简介 随着实时计算的需求日益增多,分布式内存计算 ...
- 使用scala开发spark入门总结
使用scala开发spark入门总结 一.spark简单介绍 关于spark的介绍网上有很多,可以自行百度和google,这里只做简单介绍.推荐简单介绍连接:http://blog.jobbole.c ...
- Spark入门实战系列--1.Spark及其生态圈简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .简介 1.1 Spark简介 年6月进入Apache成为孵化项目,8个月后成为Apache ...
随机推荐
- 恕我直言你可能真的不会java第5篇:Stream的状态与并行操作
一.回顾Stream管道流操作 通过前面章节的学习,我们应该明白了Stream管道流的基本操作.我们来回顾一下: 源操作:可以将数组.集合类.行文本文件转换成管道流Stream进行数据处理 中间操作: ...
- 使用itext asian 解决中文不显示的问题
本人使用的itextpdf版本是5.4.3<dependency> <groupId>com.itextpdf</groupId> <artifactId&g ...
- xutils工具上传日志文件--后台服务器的搭建
在上一篇文章中使用xutils将手机上保存的日志上传到后台服务器中,现在我们来讲后台服务器是如何搭建的 后台服务器采用jsp+sevlet+mysql的框架 首先讲mysql数据库的表的建立 在fil ...
- SMB扫描-Server Message Block 协议、nmap
版本 操作系统 SMB1 Windows 200.xp.2003 SMB2 Windows Vista SP1.2008 SMB2.1 Windows 7/2008 R2 SMB3 Windows 8 ...
- C++核心内容和机制
备注:不局限与C++版本 一. 基础知识 数据类型和POD/Trivial 数据类型: 类型转换: NULL和nullptr: 操作符重载: 全局静态变量和成员静态变量的申明和初始化: 左值和右值 ...
- 手把手教你使用Python抓取QQ音乐数据(第二弹)
[一.项目目标] 通过Python爬取QQ音乐数据(一)我们实现了获取 QQ 音乐指定歌手单曲排行指定页数的歌曲的歌名.专辑名.播放链接. 此次我们在之前的基础上获取QQ音乐指定歌曲的歌词及前15个精 ...
- HTTP 协议详解(二)
前面一篇已经说过了 HTTP 的基本特性,HTTP 的发展史,前情回顾.这一篇就更详细的 HTTP 协议使用过程一些参数配置,缓存,Cookie设置相关的细节做一些梳理. 数据类型与编码 在 TCP/ ...
- 《The Google File System》论文研读
GFS 论文总结 说明:本文为论文 <The Google File System> 的个人总结,难免有理解不到位之处,欢迎交流与指正 . 论文地址:GFS Paper 阅读此论文的过程中 ...
- 记一次使用elasticsearch遇到bug的探索过程
背景: 练习一个小项目,爬取京东的数据,存到ES库中,然后读取ES库中数据,展示到页面上.效果图如下: 涉及两个接口,一个爬取写入ES接口,一个查询展示接口,当我写完代码信心满满准备看看效果的时候,调 ...
- 控制流程之while循环, for循环
条件循环:while,语法如下 while 条件: # 循环体 # 如果条件为真,那么循环体则执行,执行完毕后再次循环,重新判断条件... # 如果条件为假,那么循环体不执行,循环终止死循环 基本使用 ...