Python post请求模拟登录淘宝并爬取商品列表
一、前言
大概是一个月前就开始做淘宝的爬虫了,从最开始的用selenium用户配置到selenium模拟登录,再到这次的post请求模拟登录。一共是三篇博客,记录了我爬取淘宝网的经历。期间也有朋友向我提出了不少问题,比如滑块失败,微博登录失败等,可以说用selenium模拟登录这方面,坑特别多,直接加载用户配置又很笨重,效率低下。所以这次尝试构造post请求表单,模拟登录。
很多人学习python,不知道从何学起。
很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手。
很多已经做案例的人,却不知道如何去学习更加高深的知识。
那么针对这三类人,我给大家提供一个好的学习平台,免费领取视频教程,电子书籍,以及课程的源代码!
QQ群:101677771
往期链接:
https://blog.csdn.net/pineapple_C/article/details/107461989
https://blog.csdn.net/pineapple_C/article/details/107641799
github源码链接:
https://github.com/Pineapple666/TaobaoSpider/tree/master/Taobao_face
本文篇幅较长,建议先看代码,有疑惑的再来看。
二、模拟登录
1)用浏览器走一遍登录过程
先把淘宝网的cookies全部清除,然后访问淘宝:https://www.taobao.com,这时候是不需要登录的。
在搜索框搜索iphone,立即跳出了登录页面,它的url是:https://login.taobao.com/member/login.jhtml?redirectURL=http%3A%2F%2Fs.taobao.com%2Fsearch%3Fq%3Diphone%26imgfile%3D%26commend%3Dall%26ssid%3Ds5-e%26search_type%3Ditem%26sourceId%3Dtb.index%26spm%3Da21bo.2017.201856-taobao-item.1%26ie%3Dutf8%26initiative_id%3Dtbindexz_20170306&uuid=f6dd176ff336683f5d47fc1cb16504af
很长很长,但标红的这部分url很重要,redirectURL是重定向url,登录后会跳转到这个url,当然这个是经过url编码的。

![]() 其余后面的参数很乱,不知道有用没用,先试一下,把后面的参数去掉,访问https://login.taobao.com/member/login.jhtml?redirectURL=http%3A%2F%2Fs.taobao.com%2Fsearch%3Fq%3Diphone看看能不能行:
其余后面的参数很乱,不知道有用没用,先试一下,把后面的参数去掉,访问https://login.taobao.com/member/login.jhtml?redirectURL=http%3A%2F%2Fs.taobao.com%2Fsearch%3Fq%3Diphone看看能不能行:

![]() 可以进入登录页面,那能不能登录呢?
可以进入登录页面,那能不能登录呢?
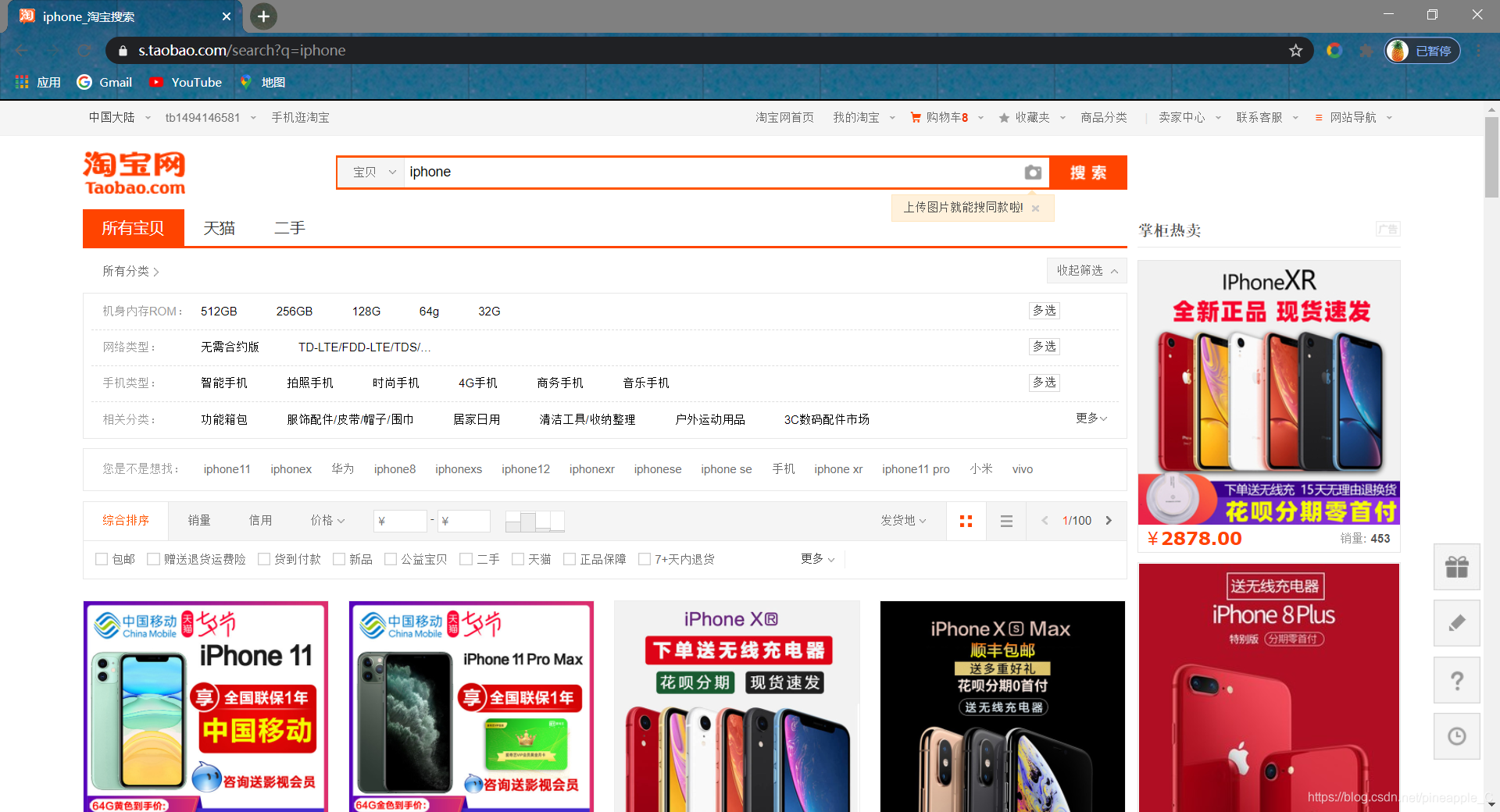
![]() 好,正如上面所说,跳转到了这个url。
好,正如上面所说,跳转到了这个url。
2)用抓包工具分析登录过程
既然可行,那么接着再来一次,这次看看这个过程都发起了哪些请求,提交了哪些数据。(别忘记清除cookies)
可以使用浏览器开发者模式也可以使用抓包工具Fidder,使用浏览器的话要打开Preserve log
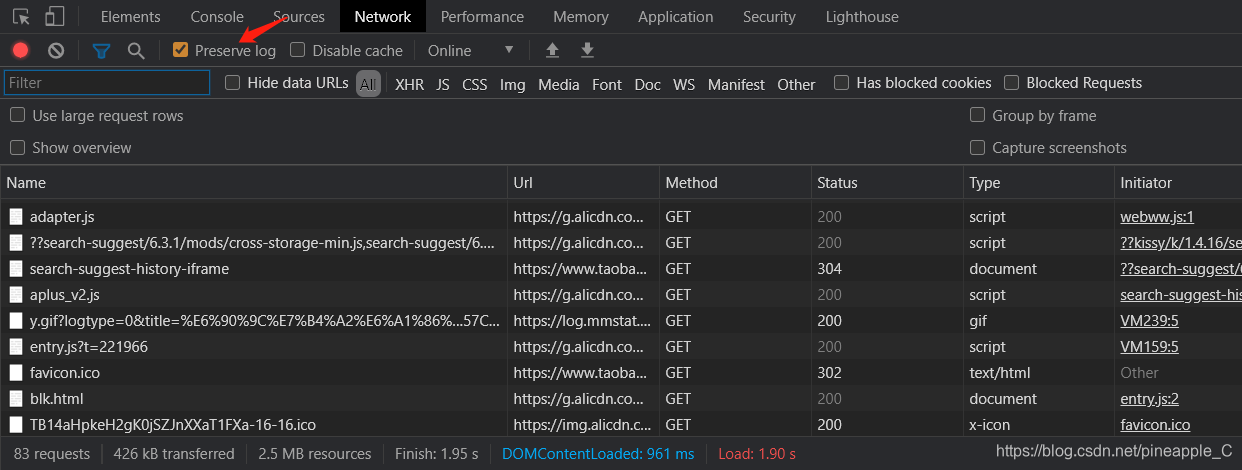
![]() 我用的是Fidder
我用的是Fidder
设置抓取的User-Agents为Chrome
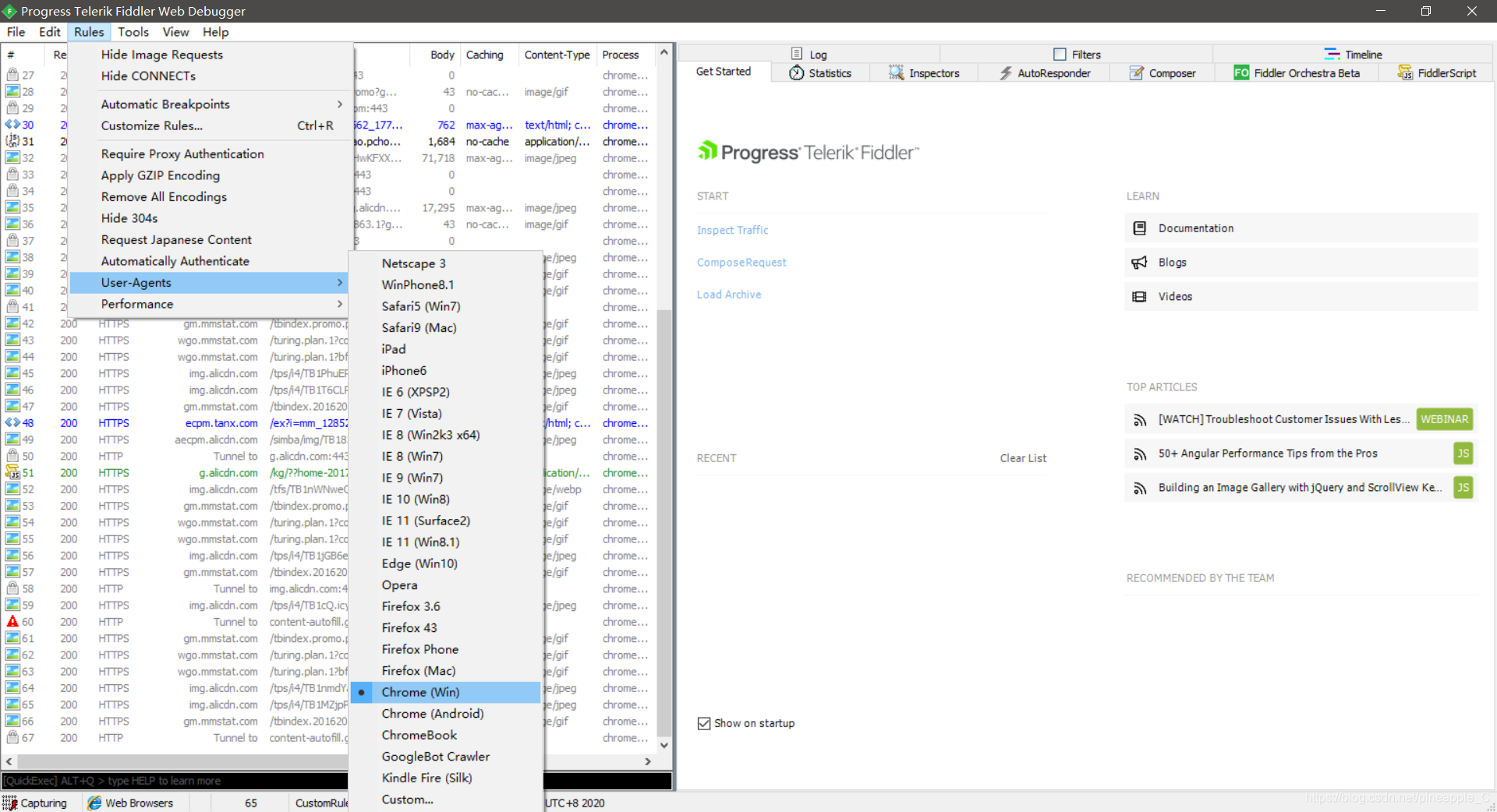
点击登录。查看请求记录。

![]() 这是两个非常重要的url
这是两个非常重要的url
第一个是最开始访问的登录页面,一个普通的get请求,第二个就不同了,它是一个post请求,其中表单包含了大量的数据信息
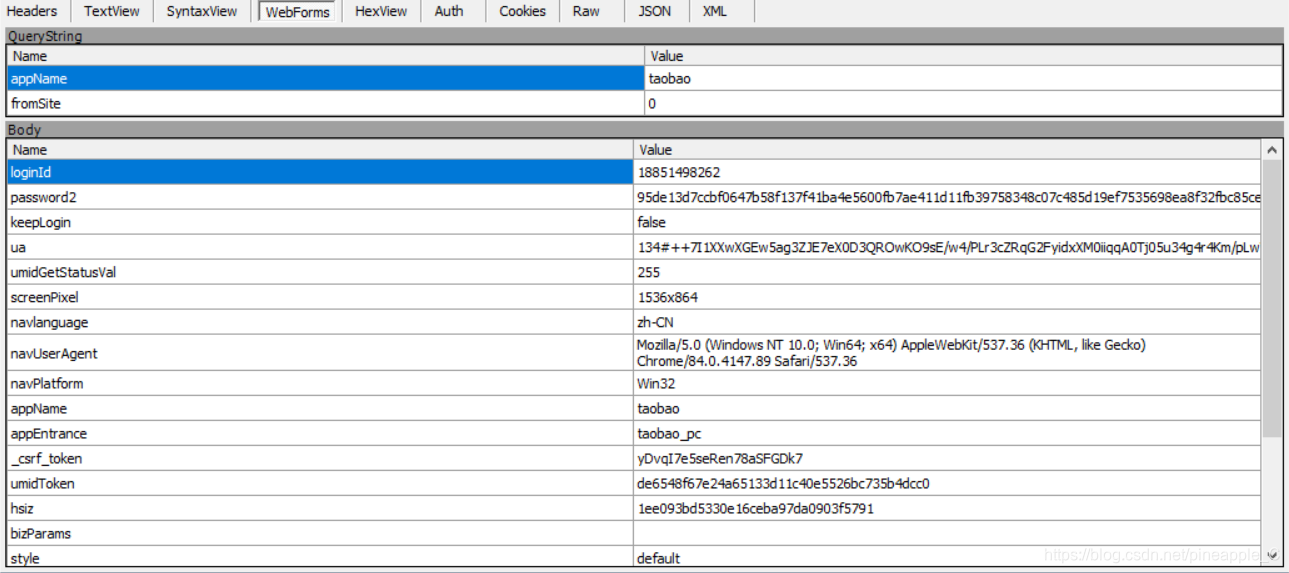
![]() 内容虽然很多,但经过我多次的测试和比对后,发现了如下几条规律:
内容虽然很多,但经过我多次的测试和比对后,发现了如下几条规律:
1、loginId一眼就可以看出是账号,ua猜测为一种加密后的用户标识,password2猜测为加密后的密码。这三条信息可以当作固定值反复使用
2、_csrf_token, umidToken, hsiz隐藏在登录页面里

![]() 3、其他的都是不变的
3、其他的都是不变的
3)代码实战
文件名为login.py,类名为Login
class Login:
"""
模拟登录并获取cookies
"""
def __init__(self, ua, loginId, password2):
"""
初始化用户参数信息和相关url
:param ua:
:param loginId:
:param password2:
"""
self.ua = ua
self.loginId = loginId
self.password2 = password2
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36'
}
# 模拟输入商品后跳转的登录页面
self.login_url = f'https://login.taobao.com/member/login.jhtml?redirectURL=http%3A%2F%2Fs.taobao.com%2Fsearch%3Fq%3D{quote(PRODUCT)}'
# 提交表单,获取重定向url
self.commit_url = 'https://login.taobao.com/newlogin/login.do?appName=taobao&fromSite=0'
# 默认重定向url
self.redirect_url = f'https://s.taobao.com/search?q={PRODUCT}'
urllib3.disable_warnings()
![]()
ua, loginId, password2这三个是用户信息,传递这三个参数以初始化Login类。PRODUCT是一个全局变量,代表着商品名,在setting.py里可以设置这个变量。如果商品名带有中文,则需要用urllib.parse.quote()进行url编码。
logged函数
def logged(self):
"""
模拟登录
:return: bool
"""
if self.load_cookies():
return False
post_data = {
'loginId': self.loginId,
'password2': self.password2,
'keepLogin': 'false',
'ua': self.ua,
# 'umidGetStatusVal': '255',
# 'screenPixel': '1536x864',
# 'navlanguage': 'zh-CN',
'navUserAgent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36',
'navPlatform': 'Win32',
'appName': 'taobao',
'appEntrance': 'taobao_pc',
'_csrf_token': self.get_value('_csrf_token'),
'umidToken': self.get_value('umidToken'),
'hsiz': self.get_value('hsiz'),
'bizParams': None,
# 'style': 'default',
'appkey': '00000000',
'from': 'tb',
'isMobile': 'false',
# 'lang': 'zh-CN',
'returnUrl': self.redirect_url,
'fromSite': '0'
}
headers = {
'Host': 'login.taobao.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36',
'Accept': 'application/json, text/plain, */*',
# 'Accept-Language': 'zh-CN,en-US;q=0.7,en;q=0.3',
# 'Accept-Encoding': 'gzip, deflate, br',
'Content-Type': 'application/x-www-form-urlencoded',
'Origin': 'https://login.taobao.com',
'Connection': 'keep-alive',
'Referer': self.login_url,
}
try:
response = SESSION.post(url=self.commit_url, headers=headers, data=post_data, verify=False)
response.raise_for_status()
except Exception as e:
logger.error(f'登录失败,原因:')
raise e
self.queue_cookies()
self.redirect_url = response.json()['content']['data']['redirectUrl']
return True
![]()
为了方便登录,每次登录成功后都会自动保存cookies,所以在登录之前都先要判断是否存在cookies,cookies是否正确等问题。如果上述条件都不成立的话,则重新登录,重新保存cookies。模拟登录最重要的就是执行post请求,而执行post请求就要构造好一个正确的post字典,对于_csrf_token, umidToken, hsiz这三条数据,可以去登录页面提取
这个提取过程主要依靠这两个函数:
@property
def _html(self):
"""
获取登录页面代码
:return: self._html
"""
response = SESSION.get(url=self.login_url, headers=self.headers, verify=False)
return response.text
def get_value(self, key):
"""
根据传入的键得到对应的值
:param key: 键名
:return: 键所对应的值
"""
match = re.search(rf'"{key}":"(.*?)"', self._html)
return match.group(1)
![]()
使用Python的@property装饰器,访问内部属性。它相当于又创造了一个和函数名相同的一个属性。调用此函数即调用此属性,有点像Java里的get方法。由于_csrf_token, umidToken, hsiz这三个字段都有一个共同点,都可以通过上面的正则表达式匹配到,所以可以归结为一个函数,不用写三个函数。
表单构造完后,发起post请求,SESSION是一个全局会话,登录和爬取都是一个会话,方便处理cookies。
请求没有问题后,调用queue_cookies(),立即保存cookies
def queue_cookies(self):
"""
序列化cookies
:return:
"""
cookies_dict = dict_from_cookiejar(SESSION.cookies)
with open(COOKIES_PATH, 'w', encoding='utf-8') as file:
json.dump(cookies_dict, file)
logger.success('保存cookies文件成功!')
![]()
之后有一个self.redirect_url,对重定向url的再次赋值,这个主要是检查是否会出现滑块验证。只有在连续多次相同ip登录的时候才会跳转到滑块验证,这时候如果还是访问原先的url,它也会跳转,所以加不加都行。
如果登录成功了,可以输出一下当前的网页标题来验证一下
def print_title(self):
"""
输出重定向页面后的标题,以验证登录
:return:
"""
try:
response = SESSION.get(url=self.redirect_url, headers=self.headers, verify=False)
response.raise_for_status()
content = response.text
# 有必要时保存第一页代码,便于调试
# with open('success.html', 'w', encoding='utf-8')as file:
# file.write(content)
match = re.search(r'<title>(.*?)</title>', content, re.S)
title = match.group(1)
if title != f'{PRODUCT}_淘宝搜索':
raise TitleError(f'标题错误,标题:{title}')
except TitleError as e:
raise e
else:
logger.info(f'网页标题为:{title}')
![]()
TitleErrors是个自定义异常,用来捕捉标题错误。出现滑块验证时候的标题为:security-X5这个时候要等待一会才能登录成功
这个抛出异常分为两种情况,如果是加载cookies失败,则重新登录,如果是登录失败,则退出程序,这是在load_cookies()函数内实现的
加载cookies首先要将保存的cookies取出来
def unqueue_cookies(self):
"""
反序列化cookies
:return:
"""
try:
with open(COOKIES_PATH, 'r', encoding='utf-8') as file:
cookies_dict = json.load(file)
except JSONDecodeError as e:
raise e
else:
return cookiejar_from_dict(cookies_dict)
![]()
根据load_cookies()的返回值判断是否不需要登录。
这就是整个登录的流程,本来很简单的被我这么一说反而变复杂了。再概括一下整个流程吧,首先一上来先加载cookies,如果没有cookies文件,或者加载cookies失败,则再登录一遍并保存cookies,输出当前页面标题,符合条件则登录成功,不符合则失败退出程序。
三、爬取商品列表
借助全局的SESSION来处理cookies,就可以实现连续翻页,访问详情页面的操作。当然详情页面的爬取还有带开发,先爬取商品列表。
1)分析url
https://s.taobao.com/search?q=iphone&bcoffset=6&p4ppushleft=1%2C48&ntoffset=6&s=0
https://s.taobao.com/search?q=iphone&bcoffset=3&p4ppushleft=1%2C48&ntoffset=3&s=44
https://s.taobao.com/search?q=iphone&bcoffset=0&p4ppushleft=1%2C48&ntoffset=6&s=88
https://s.taobao.com/search?q=iphone&bcoffset=-3&p4ppushleft=1%2C48&ntoffset=-3&s=132
https://s.taobao.com/search?q=iphone&bcoffset=-6&p4ppushleft=1%2C48&ntoffset=-6&s=176
这是前五页的url,虽然参数很多,但也能窥探到其中的规律。
bcoffset和ntoffset判断为偏移量,从6开始逐页递增-3。s判断为已观看的商品数,从0开始逐页递增44
等一下,第三页的两个偏移量不相等啊?先别急,访问归我纳出的url试一下:https://s.taobao.com/search?q=iphone&bcoffset=0&p4ppushleft=1%2C48&ntoffset=0&s=88
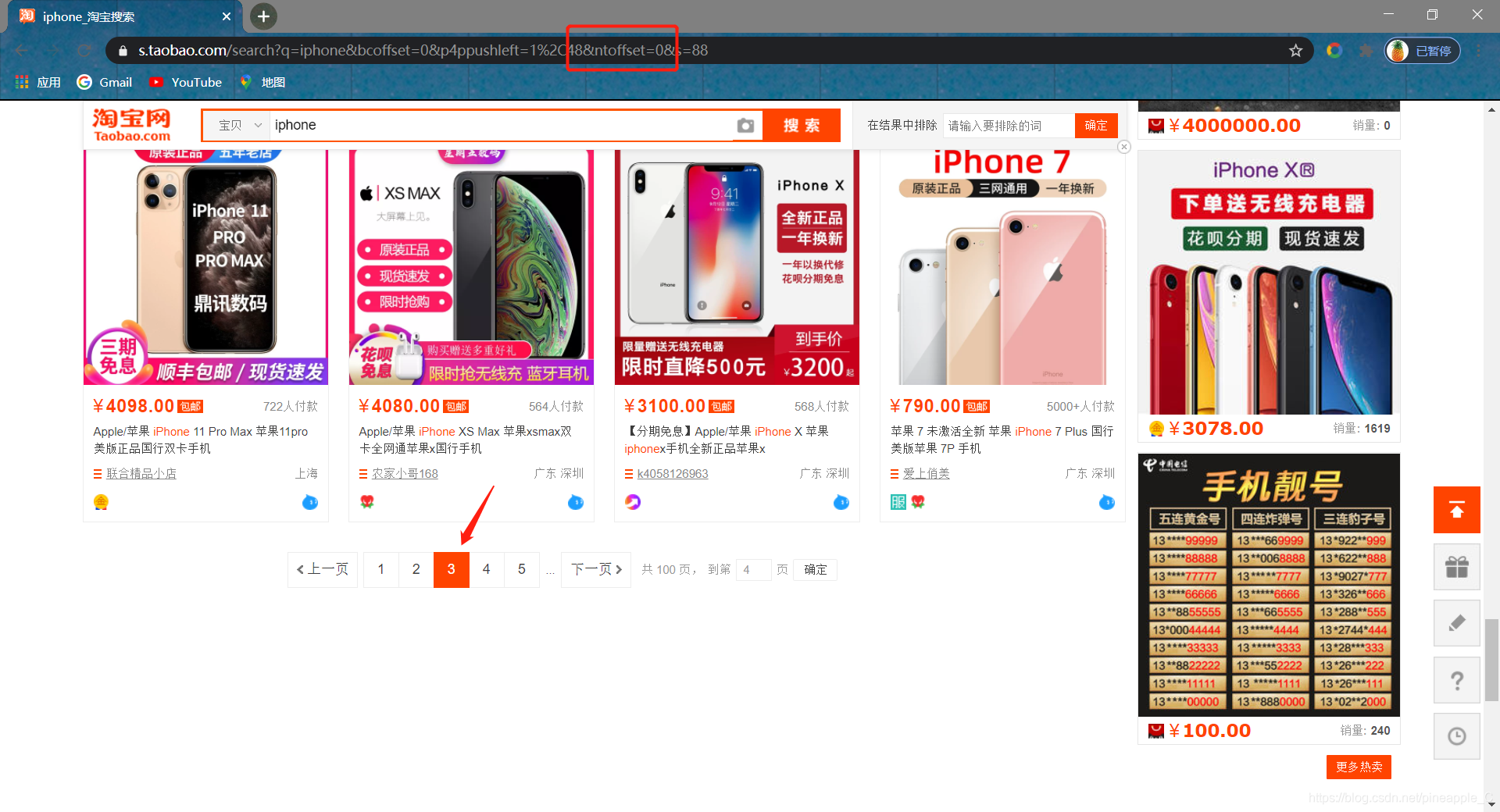
![]() 很好,根据上述归纳,把代码写下来:
很好,根据上述归纳,把代码写下来:
def get_url(self):
"""
构造url
:return: url
"""
for page in range(MAX_PAGE):
offset = 6 - page * 3
detali = 44 * page
yield f'http://s.taobao.com/search?q={PRODUCT}&bcoffset={offset}&ntoffset={offset}&p4ppushleft=1%2C48&s={detali}'
![]()
PRODUCT前面说过了,是商品名。
因为毕竟这不是一个小项目,淘宝的反爬也是非常厉害,所以按照可以添加代理的方式编写代码,为以后的代理,异步操作做准备。
这其中就有构造一个淘宝请求类,储存请求类,获取代理,设置超时时间,代理异常捕捉等问题。听我一一道来。
2)获取代理
def get_proxy(self):
"""
从代理池获取代理
:return: proxy
"""
try:
response = requests.get(PROXY_POOL_URL)
if response.status_code == 200:
logger.info('Get Proxy', response.text)
return response.text
return None
except requests.ConnectionError:
return None
![]()
PROXY_POOL_URL是获取代理的url,这个要配合代理池的使用。即使是付费代理,最好也是在代理池走一遍流程,以提高代理的正确率。
3)分析网页代码
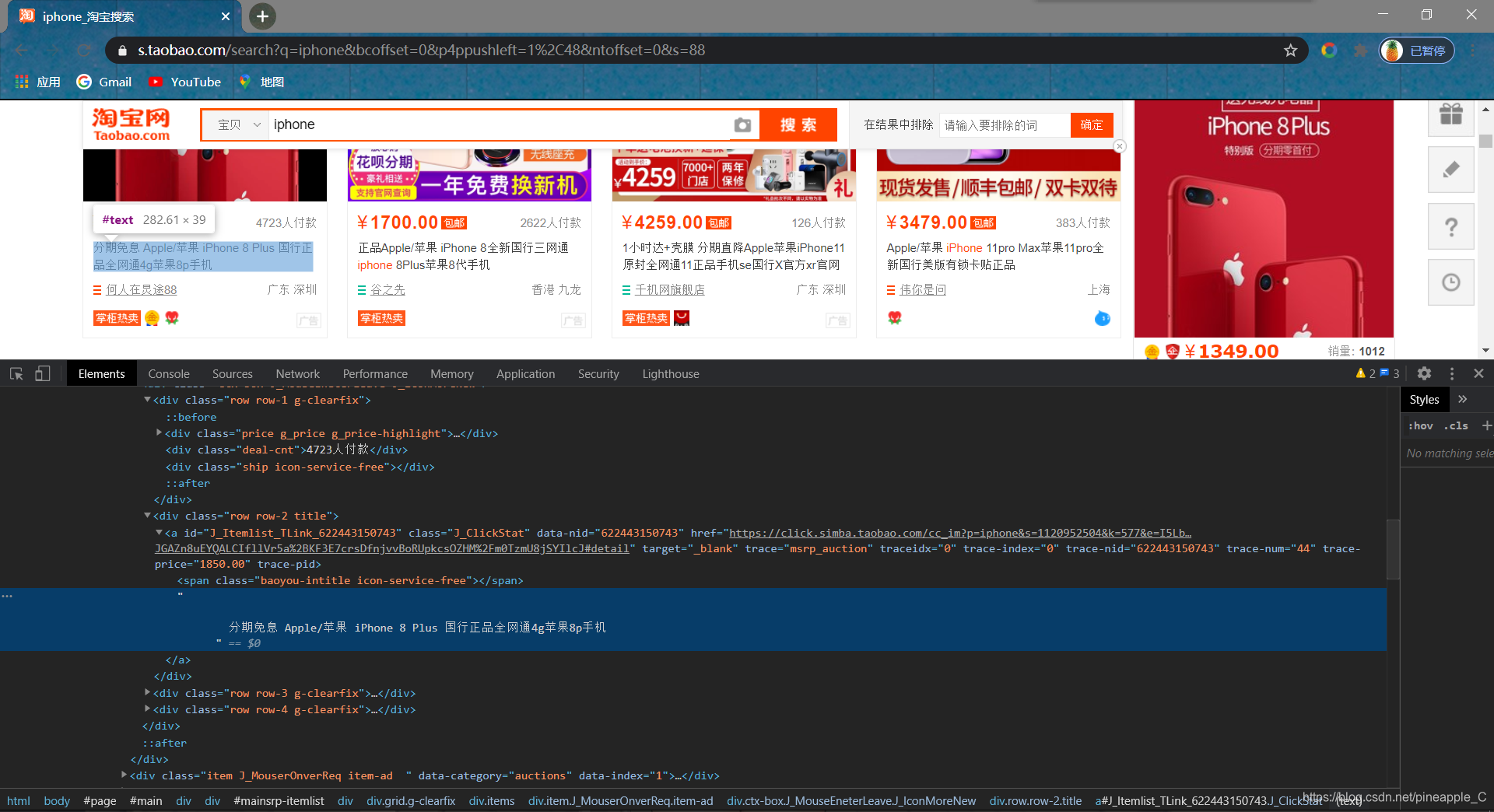
![]() 定位一下结点,看上去好像只要用代码定位到这里就可以提取数据了,其实不然,上图的页面和代码都是异步加载出来的,和真实的请求结果很不一样。我把代码请求获得的代码和浏览器看到的代码比对一下,你就知道。
定位一下结点,看上去好像只要用代码定位到这里就可以提取数据了,其实不然,上图的页面和代码都是异步加载出来的,和真实的请求结果很不一样。我把代码请求获得的代码和浏览器看到的代码比对一下,你就知道。
浏览器看到的代码

![]() 请求返回的代码
请求返回的代码
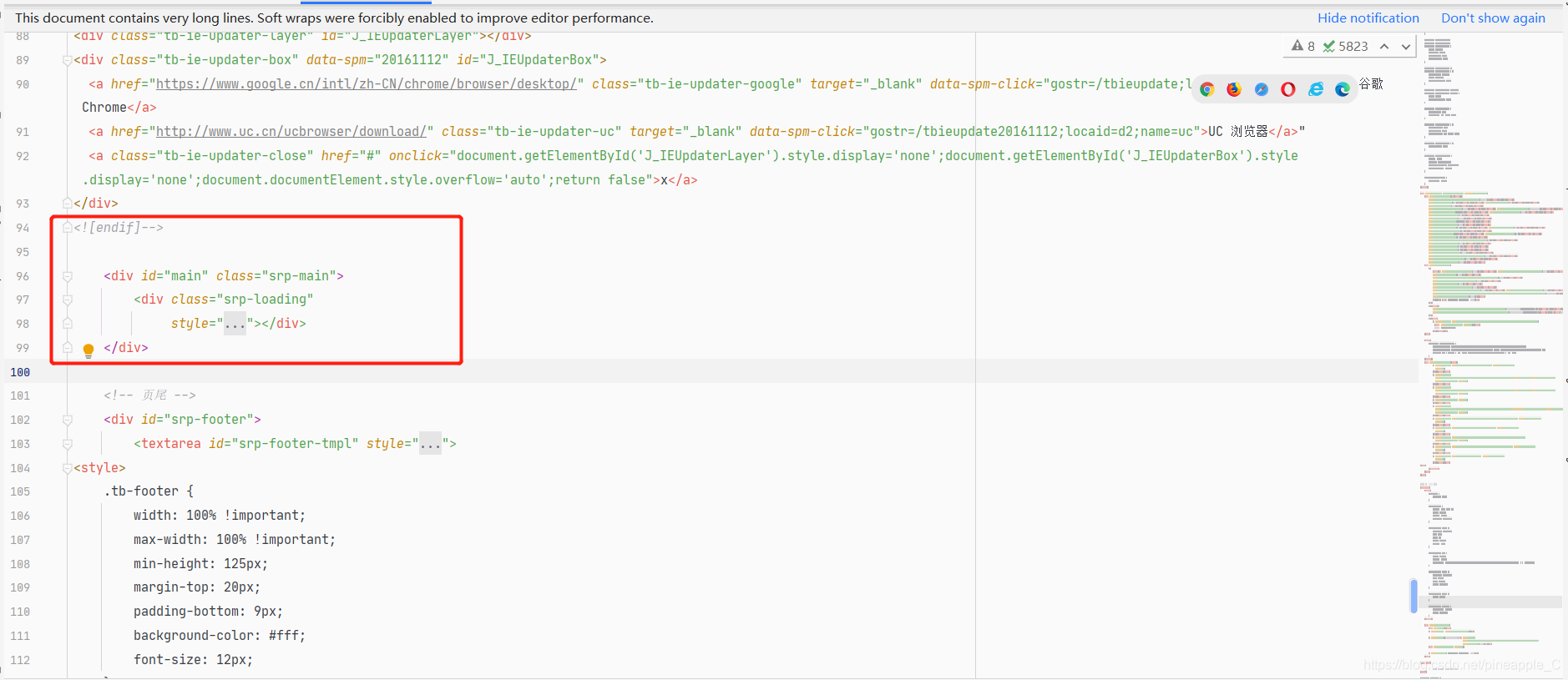
![]()
id为main的结点才刚开始,就到结尾了!!!
既然在html里找不到,那干脆就搜索吧,点击NetWork,刷新一下页面,搜索任意商品标题
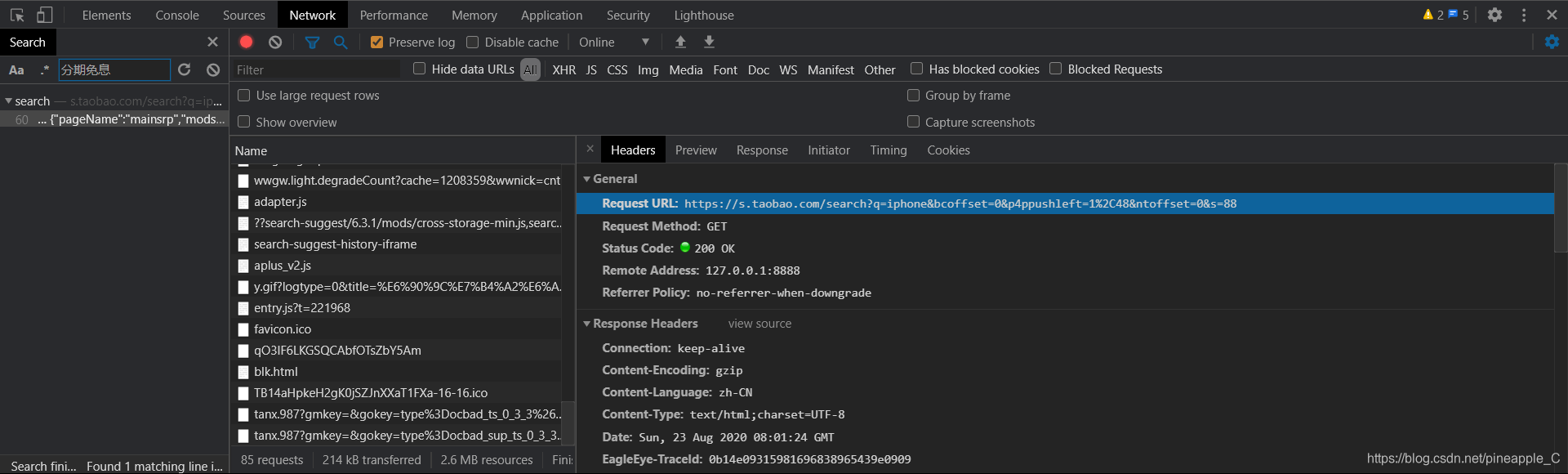
![]()
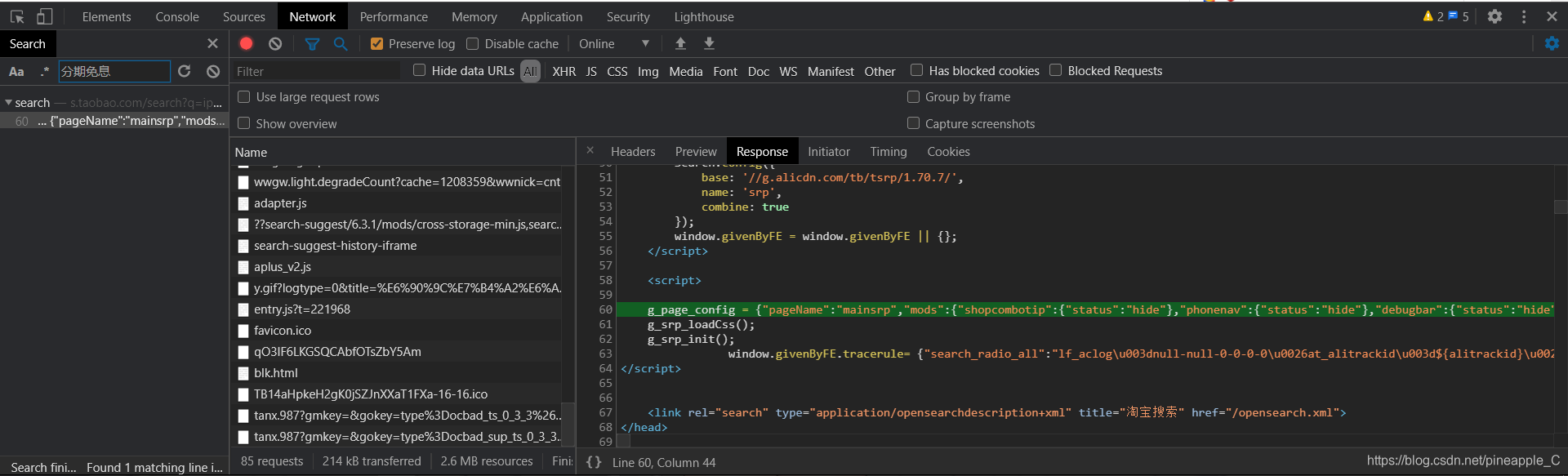
![]() 果然是有的,它保存在一个名为g_page_config的变量里,而且是json格式的。回过头来发现响应的结果也有这个东西:
果然是有的,它保存在一个名为g_page_config的变量里,而且是json格式的。回过头来发现响应的结果也有这个东西:

![]() 原来如此,数据藏在这个地方,直接用正则表达式就可以匹配出来:
原来如此,数据藏在这个地方,直接用正则表达式就可以匹配出来:
4)解析页面
def parse_detail(self, response):
"""
解析页面
:return: 商品信息列表
"""
# 匹配全部信息
# match = re.findall(
# r'"nid":"(.*?)","category":"(.*?)","pid":"(.*?)","title":"(.*?)","raw_title":"(.*?)","pic_url":"(.*?)",'
# r'"detail_url":"(.*?)","view_price":"(.*?)","view_fee":"(.*?)","item_loc":"(.*?)","view_sales":"(.*?)",'
# r'"comment_count":"(.*?)","user_id":"(.*?)","nick":"(.*?)"', response.text, re.S)
# keys = ('nid', 'category', 'pid', 'title', 'raw_title', 'pic_url', 'detail_url', 'view_price',
# 'view_fee', 'item_loc', 'view_sales', 'comment_count', 'user_id', 'nick')
# 匹配重要信息
match = re.findall(
r'"nid":"(.*?)",.*?,"raw_title":"(.*?)",.*?,"view_price":"(.*?)","view_fee":"(.*?)","item_loc":"(.*?)",'
r'"view_sales":"(.*?)人付款","comment_count":"(.*?)",.*?,"nick":"(.*?)"', response.text, re.S)
keys = ('id', 'name', 'price', 'fee', 'location', 'sales', 'comments', 'shop')
return [dict(zip(keys, value)) for value in match if len(value[4]) < 50]
![]()
因为要保存到mysql里面,所以匹配结果的每一组都应该是一个字典,都放在一个列表里。对于这个列表怎么构造,在这里说明一下:
re.findall()返回的结果是一个列表,列表内的每个元素都是一个元组,一个元组就是一个商品的信息(标题,价格,成交人数等等),keys也是一个元组,代表着mysql里的键名,运用dict(zip(keys,value))的方式创建字典,最后外面套上个列表推导式,这个列表就搞定了。
有时候,因为一个商品少了view_sales这个键,导致item_loc的值非常长,直接匹配到下一个商品的item_loc,这种情况是不允许的,所以加上长度限制,过长则直接跳过。
根据以往的套路,有了url,代理,解析函数,基本上就可以完成这次的爬虫了。但这次不同,要做到一个高效稳定的爬虫仅仅考这些是不够的。就好比代理,万一这次的请求失败了怎么办,会不会出现异常,这页的数据就不要了吗?当然是不行的,不到万不得已,绝不放过任何一条有价值的数据。所以要建立一个高稳定的高容错率的机制。
用redis去配合mysql的存储
5)淘宝请求类:
class TaobaoRequest(Request):
"""
淘宝请求
"""
def __init__(self, url, callback, method='GET', headers=None, need_proxy=NEED_PROXY, timeout=TIMEOUT, fail_time=0):
"""
:param url: url
:param callback: 回调函数
:param method: 请求方法
:param headers: 请求头
:param need_proxy: 是否需要代理
:param timeout: 超时时间
:param fail_time: 请求失败次数
"""
Request.__init__(self, method, url, headers)
self.callback = callback
self.need_proxy = need_proxy
self.timeout = timeout
self.fail_time = fail_time
![]()
上面构造了一个请求类,目的就是把本次请求的相关参数比如失败次数,超时时间,是否需要代理等整合到一起,统统放到redis数据库内。然后统一调度,若请求失败则再放入redis中,等待下一次的调度。这样就不会丢失数据。
6)存储
def start(self):
"""
储存全部url,等待调度
:return: None
"""
for url in self.get_url():
taobao_request = TaobaoRequest(url=url, callback=self.parse_detail, headers=self.headers)
self.queue.add(taobao_request)
logger.info(f'Add {taobao_request.url} to redis.')
![]()
存好url,等待后面的调度
7)调度
def schedule(self):
"""
调度请求
:return: None
"""
while not self.queue.empty():
taobao_request = self.queue.pop()
callback = taobao_request.callback
logger.info(f'Schedule {taobao_request.url}')
response = self.request(taobao_request)
if response and response.status_code in VALID_STATUSES:
results = callback(response)
if results:
for result in results:
if isinstance(result, dict):
self.mysql.insert(MYSQL_TABLE, result)
logger.success(f'successful parse {taobao_request.url}')
else:
self.error(taobao_request)
else:
self.error(taobao_request)
![]()
首先判断是否还有请求类等待调度,有则取出这个请求类,拿出来的这个类只是一空盒子,里面没有任何东西,只有表面的信息(捆绑在一起的参数)。所以要请求这个类里面的url,才能得到响应,盒子里才会有内容。
8)请求
def request(self, taobao_request):
"""
执行请求
:param taobao_request: 请求
:return: 响应
"""
try:
if taobao_request.need_proxy:
proxy = self.get_proxy()
if proxy:
proxies = {
'http': 'http://' + proxy,
'https': 'https://' + proxy
}
logger.info(f'Get proxy {proxies}')
return SESSION.get(url=taobao_request.url, headers=self.headers, timeout=taobao_request.timeout,
proxies=proxies)
return SESSION.get(url=taobao_request.url, headers=self.headers, timeout=taobao_request.timeout)
except (ConnectionError, ReadTimeout) as e:
print(e.args)
return False
![]()
在请求之前先判断是否需要代理,need_proxy这个属性是根据setting.py里的NEED_PROXY设置的。代理这个东西,有可能上一秒测试的时候还是好好的,下一秒就不行了,寿命非常有限。所以还是要有相应异常捕捉机制。
调度函数里的callback就是解析函数parse_detail(),如果这个请求返回的是个False,parse_detail()自然就不能解析出数据,解析不到数据怎么办?
这时候就用到容错函数了
9)错误处理
def error(self, taobao_request):
"""
错误处理
:param taobao_request: 请求
:return: None
"""
taobao_request.fail_time += 1
logger.debug(f'Url {taobao_request.url} faile_time + 1, current fail_time: {taobao_request.fail_time}')
if taobao_request.fail_time < MAX_FAIL_TIME:
self.queue.add(taobao_request)
else:
logger.debug(f'Url {taobao_request.url} delete!')
![]()
- 1
在解析的数据出现异常的时候,便会调用这个函数,将失败次数+1,到了最大失败次数MAX_FAIL_TIME时则从redis中彻底删除这个请求,MAX_FAIL_TIME在setting.py中设置。
如果解析数据成功,就直接插入mysql里。
有关redis和mysql的代码,都是些套路问题,记下来就好,需要的时候直接拿出来用,我就不在博客里详细介绍了。
更多详细内容,完整代码见github:https://github.com/Pineapple666/TaobaoSpider/tree/master/Taobao_face
三、结语
今天迈出了第一步,再接再厉!
Python post请求模拟登录淘宝并爬取商品列表的更多相关文章
- python使用sessions模拟登录淘宝
之前想爬取一些淘宝的数据,后来发现需要登录,找了很多的资料,有个使用request的sessions加上cookie来登录的,cookie的获取在登录后使用开发者工具可以找到.不过这个登录后获得的网页 ...
- Python爬虫实战五之模拟登录淘宝并获取所有订单
经过多次尝试,模拟登录淘宝终于成功了,实在是不容易,淘宝的登录加密和验证太复杂了,煞费苦心,在此写出来和大家一起分享,希望大家支持. 温馨提示 更新时间,2016-02-01,现在淘宝换成了滑块验证了 ...
- Python 爬虫实战5 模拟登录淘宝并获取所有订单
经过多次尝试,模拟登录淘宝终于成功了,实在是不容易,淘宝的登录加密和验证太复杂了,煞费苦心,在此写出来和大家一起分享,希望大家支持. 本篇内容 python模拟登录淘宝网页 获取登录用户的所有订单详情 ...
- Python模拟登录淘宝
最近想爬取淘宝的一些商品,但是发现如果要使用搜索等一些功能时基本都需要登录,所以就想出一篇模拟登录淘宝的文章!看了下网上有很多关于模拟登录淘宝,但是基本都是使用scrapy.pyppeteer.sel ...
- selenium跳过webdriver检测并模拟登录淘宝
目录 简介 编写思路 使用教程 演示图片 源代码 @(文章目录) 简介 模拟登录淘宝已经不是一件新鲜的事情了,过去我曾经使用get/post方式进行爬虫,同时也加入IP代理池进行跳过检验,但随着大型网 ...
- 淘宝地址爬取及UI展示
淘宝地址爬取及UI展示 淘宝国家省市区街道获取 参考 foxiswho 的 taobao-area-php 部分代码,改由c#重构. 引用如下: Autofac MediatR Swagger Han ...
- Python模拟登陆淘宝并统计淘宝消费情况的代码实例分享
Python模拟登陆淘宝并统计淘宝消费情况的代码实例分享 支付宝十年账单上的数字有点吓人,但它统计的项目太多,只是想看看到底单纯在淘宝上支出了多少,于是写了段脚本,统计任意时间段淘宝订单的消费情况,看 ...
- selenium+python自动化84-chrome手机wap模式(登录淘宝页面)
前言 chrome手机wap模式登录淘宝页面,点击验证码无效问题解决. 切换到wap模式,使用TouchActions模块用tap方法触摸 我的环境 chrome 62 chromedriver 2. ...
- C# 脚本代码自动登录淘宝获取用户信息
C# 脚本代码自动登录淘宝获取用户信息 最近遇到的一个需求是如何让程序自动登录淘宝, 获取用户名称等信息. 其实这个利用SS (SpiderStudio的简称) 实现起来非常简单. 十数行代码就可 ...
随机推荐
- java多线程的问题
1.多线程有什么用 (1) 发挥多核CPU的优势 单核CPU上所谓的"多线程"那是假的多线程,同一时间处理器只会处理一段逻辑,只不过线程之间切换得比较快,看着像多个线程" ...
- Improving RGB-D SLAM in dynamic environments: A motion removal approach
一.贡献 (1)提出一种针对RGB-D的新的运动分割算法 (2)运动分割采用矢量量化深度图像 (3)数据集测试,并建立RGB-D SLAM系统 二.Related work [1]R.K. Namde ...
- jquery 事件对象笔记
jQuery元素操作 设置或获取元素固有属性 获取 prop(属性名) 修改 prop(属性名,值) 获取自定义属性 ...
- Java 设置、删除、获取Word文档背景(基于Spire.Cloud.SDK for Java)
本文介绍使用Spire.Cloud.SDK for Java 提供的BackgroundApi接口来操作Word文档背景的方法,可设置背景,包括设置颜色背景setBackgroundColor().图 ...
- 【模式识别与机器学习】——3.5Fisher线性判别
---恢复内容开始--- 出发点 应用统计方法解决模式识别问题时,一再碰到的问题之一就是维数问题. 在低维空间里解析上或计算上行得通的方法,在高维空间里往往行不通. 因此,降低维数有时就会成为处理实际 ...
- Flutter 容器 (1) - Center
Center容器用来居中widget import 'package:flutter/material.dart'; class AuthList extends StatelessWidget { ...
- 关于word2vec我有话要说
写在前面的话: 总结一下使用word2vec一年来的一些经验,因为自己在做的时候,很难在网上搜到word2vec的经验介绍,所以归纳出来,希望对读者有用. 这里不介绍word2vec的原理,因为原理介 ...
- Android ScrollView嵌套ViewPager,嵌套的ViewPager无法显示
记录:ScrollView嵌套ViewPager,嵌套的ViewPager无法显示 项目中所需要布局:LinearLayout中包含(orientation="vertical") ...
- 实现0.5px边框线
实现0.5px边框方法 方案一:利用渐变(原理:高度1px,背景渐变,一半有颜色,一半透明) CSS部分 .container { width: 500px; margin: 0px auto; } ...
- jqgrid 获取选中用户的数据插入
因为查询出的表和被插入的表不是在同一个数据库,所以先从前台jqgrid表格中获取到数据后,再插入表中. 实现: 获取到jqgrid选中 的每行数据之后,发ajax请求把数据以json格式传入后台,后台 ...