适用初学者的5种Python数据输入技术
摘要:数据是数据科学家的基础,因此了解许多加载数据进行分析的方法至关重要。在这里,我们将介绍五种Python数据输入技术,并提供代码示例供您参考。
数据是数据科学家的基础,因此了解许多加载数据进行分析的方法至关重要。在这里,我们将介绍五种Python数据输入技术,并提供代码示例供您参考。
作为初学者,您可能只知道一种使用p andas.read_csv函数读取数据的方式(通常以CSV格式)。它是最成熟,功能最强大的功能之一,但其他方法很有帮助,有时肯定会派上用场。
我要讨论的方法是:
- Manual 函数
- loadtxt 函数
- genfromtxtf 函数
- read_csv 函数
- Pickle
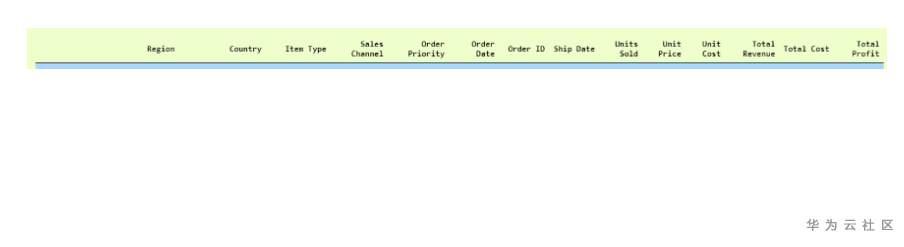
我们将用于加载数据的数据集可以在此处找到 。它被称为100-Sales-Records。
Imports
我们将使用Numpy,Pandas和Pickle软件包,因此将其导入。

1. Manual Function
这是最困难的,因为您必须设计一个自定义函数,该函数可以为您加载数据。您必须处理Python的常规归档概念,并使用它来读取 .csv 文件。
让我们在100个销售记录文件上执行此操作。

嗯,这是什么????似乎有点复杂的代码!!!让我们逐步打破它,以便您了解正在发生的事情,并且可以应用类似的逻辑来读取 自己的 .csv文件。
在这里,我创建了一个 load_csv 函数,该函数将要读取的文件的路径作为参数。
我有一个名为data 的列表, 它将具有我的CSV文件数据,而另一个列表 col 将具有我的列名。现在,在手动检查了csv之后,我知道列名在第一行中,因此在我的第一次迭代中,我必须将第一行的数据存储在 col中, 并将其余行存储在 data中。
为了检查第一次迭代,我使用了一个名为checkcol 的布尔变量, 它为False,并且在第一次迭代中为false时,它将第一行的数据存储在 col中 ,然后将checkcol 设置 为True,因此我们将处理 数据列表并将其余值存储在 数据列表中。
逻辑
这里的主要逻辑是,我使用readlines() Python中的函数在文件中进行了迭代 。此函数返回一个列表,其中包含文件中的所有行。
当阅读标题时,它会将新行检测为 \ n 字符,即行终止字符,因此为了删除它,我使用了 str.replace 函数。
由于这是一个 的.csv 文件,所以我必须要根据不同的东西 逗号 ,所以我会各执一个字符串, 用 string.split(“”) 。对于第一次迭代,我将存储第一行,其中包含列名的列表称为 col。然后,我会将所有数据附加到名为data的列表中 。
为了更漂亮地读取数据,我将其作为数据框格式返回,因为与numpy数组或python的列表相比,读取数据框更容易。
输出量
利弊
重要的好处是您具有文件结构的所有灵活性和控制权,并且可以以任何想要的格式和方式读取和存储它。
您也可以使用自己的逻辑读取不具有标准结构的文件。
它的重要缺点是,特别是对于标准类型的文件,编写起来很复杂,因为它们很容易读取。您必须对需要反复试验的逻辑进行硬编码。
仅当文件不是标准格式或想要灵活性并且以库无法提供的方式读取文件时,才应使用它。
2. Numpy.loadtxt函数
这是Python中著名的数字库Numpy中的内置函数。加载数据是一个非常简单的功能。这对于读取相同数据类型的数据非常有用。
当数据更复杂时,使用此功能很难读取,但是当文件简单时,此功能确实非常强大。
要获取单一类型的数据,可以下载 此处 虚拟数据集。让我们跳到代码。
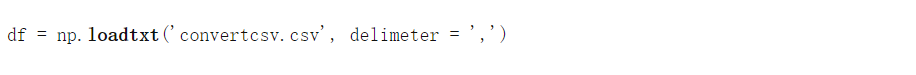
这里,我们简单地使用了在传入的定界符中 作为 ','的 loadtxt 函数 , 因为这是一个CSV文件。
现在,如果我们打印 df,我们将看到可以使用的相当不错的numpy数组中的数据。

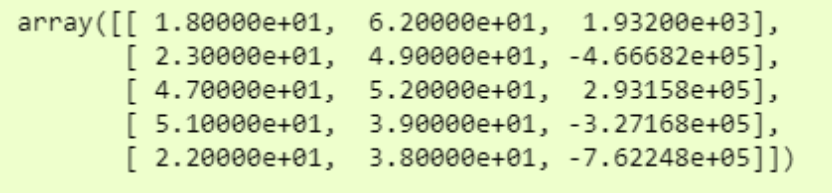
由于数据量很大,我们仅打印了前5行。
利弊
使用此功能的一个重要方面是您可以将文件中的数据快速加载到numpy数组中。
缺点是您不能有其他数据类型或数据中缺少行。
3. Numpy.genfromtxt()
我们将使用数据集,即第一个示例中使用的数据集“ 100 Sales Records.csv”,以证明其中可以包含多种数据类型。
让我们跳到代码。

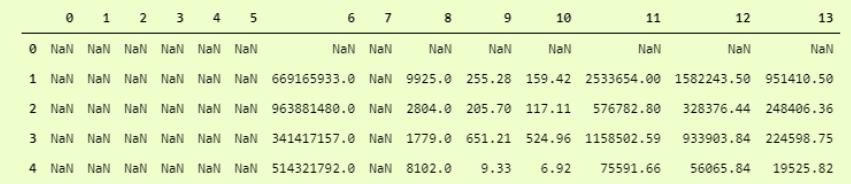
为了更清楚地看到它,我们可以以数据框格式看到它,即
这是什么?哦,它已跳过所有具有字符串数据类型的列。怎么处理呢?
只需添加另一个 dtype 参数并将dtype 设置 为None即可,这意味着它必须照顾每一列本身的数据类型。不将整个数据转换为单个dtype。

然后输出

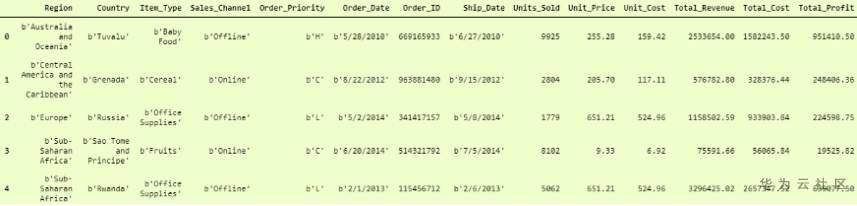
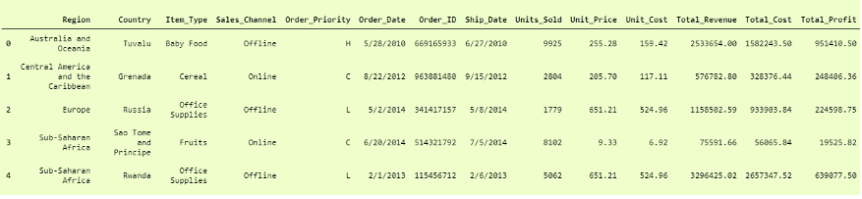
比第一个要好得多,但是这里的“列”标题是“行”,要使其成为列标题,我们必须添加另一个参数,即 名称 ,并将其设置为 True, 这样它将第一行作为“列标题”。
即

我们可以将其打印为

4. Pandas.read_csv()
Pandas是一个非常流行的数据操作库,它非常常用。read_csv()是非常重要且成熟的 功能 之一,它 可以非常轻松地读取任何 .csv 文件并帮助我们进行操作。让我们在100个销售记录的数据集上进行操作。
此功能易于使用,因此非常受欢迎。您可以将其与我们之前的代码进行比较,然后进行检查。

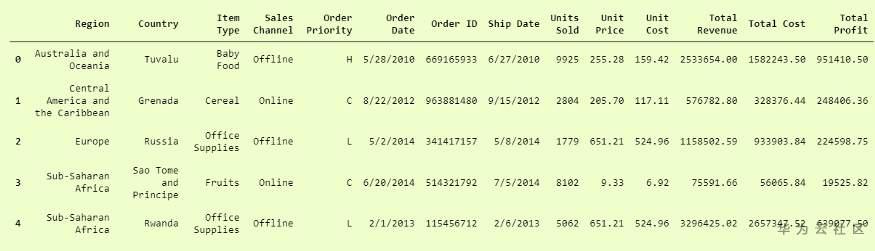
你猜怎么着?我们完了。这实际上是如此简单和易于使用。Pandas.read_csv肯定提供了许多其他参数来调整我们的数据集,例如在我们的 convertcsv.csv 文件中,我们没有列名,因此我们可以将其读取为
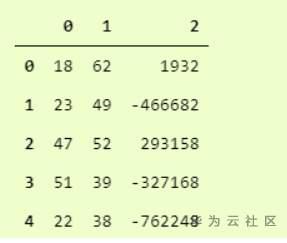
我们可以看到它已经读取了没有标题的 csv 文件。您可以在此处查看官方文档中的所有其他参数 。
5. Pickle
如果您的数据不是人类可以理解的良好格式,则可以使用pickle将其保存为二进制格式。然后,您可以使用pickle库轻松地重新加载它。
我们将获取100个销售记录的CSV文件,并首先将其保存为pickle格式,以便我们可以读取它。

这将创建一个新文件 test.pkl ,其中包含来自 Pandas 标题的 pdDf 。
现在使用pickle打开它,我们只需要使用 pickle.load 函数。

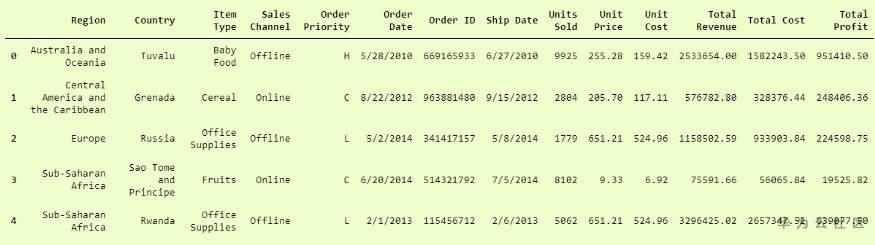
在这里,我们已成功从pandas.DataFrame 格式的pickle文件中加载了数据 。
本文分享自华为云社区《Python加载数据的5种不同方式》,原文作者:一只无脑程序员
适用初学者的5种Python数据输入技术的更多相关文章
- Python学习教程(learning Python)--1.3 Python数据输入
多数应用程序都有数据输入语句,用于读入数据,和用户进行交互,在Python语言里,可以通过raw_input函数实现数据的从键盘读入数据操作. 基本语法结构:raw_input(prompt) 通常p ...
- Python数据可视化的四种简易方法
摘要: 本文讲述了热图.二维密度图.蜘蛛图.树形图这四种Python数据可视化方法. 数据可视化是任何数据科学或机器学习项目的一个重要组成部分.人们常常会从探索数据分析(EDA)开始,来深入了解数据, ...
- 设计一种前端数据延迟加载的jQuery插件(2)
背景 最近看到很多网站都运用到了一种前端数据延迟加载技术,包括淘宝,新浪网等等,这样做的目的可以使得一些未显示的图片随 着滚动条的滚动进行延迟显示. 好处显而易见,可以减少前端对于图片的Http请求, ...
- Python中输入和输出(打印)数据
一个程序要进行交互,就需要进行输入,进行输入→处理→输出的过程.所以就需要用到输入和输出功能.同样的,在Python中,怎么实现输入和输出? Python3中的输入方式: Python提供了 inpu ...
- 15种Python片段去优化你的数据科学管道
来源:15 Python Snippets to Optimize your Data Science Pipeline 翻译:RankFan 15种Python片段去优化你的数据科学管道 为什么片段 ...
- 干货!小白入门Python数据科学全教程
前言 本文讲解了从零开始学习Python数据科学的全过程,涵盖各种工具和方法 你将会学习到如何使用python做基本的数据分析 你还可以了解机器学习算法的原理和使用 说明 先说一段题外话.我是一名数据 ...
- 【数据科学】Python数据可视化概述
注:很早之前就打算专门写一篇与Python数据可视化相关的博客,对一些基本概念和常用技巧做一个小结.今天终于有时间来完成这个计划了! 0. Python中常用的可视化工具 Python在数据科学中的地 ...
- python文件输入和输出
1.1文件对象 文件只是连续的字节序列.数据的传输经常会用到字节流,无论字节流是由单个字节还是大块数据组成.1.2文件内建函数open()和file() 内建函数open()的基本语法是: file_ ...
- 《Python数据科学手册》第五章机器学习的笔记
目录 <Python数据科学手册>第五章机器学习的笔记 0. 写在前面 1. 判定系数 2. 朴素贝叶斯 3. 自举重采样方法 4. 白化 5. 机器学习章节总结 <Python数据 ...
随机推荐
- Windows下的git服务器搭建
时间一晃又是两个月过去了,我好像在写博客这方面有点懒,= .= 主要也是没啥好写的,项目上的事情又不能写,能写的东西实在太少. 前两个月领导花巨资申请了一个服务器,让我搞git服务器来管理代码,花了几 ...
- 洛谷 P4819 [中山市选]杀人游戏(tarjan缩点)
P4819 [中山市选]杀人游戏 思路分析 题意最开始理解错了(我太菜了) 把题意简化一下,就是找到可以确定杀手身份的最小的危险查看数 (就是不知道该村名的身份,查看他的身份具有危险的查看数量),用 ...
- 浅谈MircoPython---ESP8266
一.连接WIFI 在Putty会话窗口输入 >>>help() 打印的消息会告诉你如何连接WIFI import network sta_if = network.WLAN(netw ...
- PHP-FPM包的安装与配置 转
实验环境:CentOS7 [root@~ localhost]#yum -y install php-fpm php-fpm包:用于将php运行于fpm模式 #在安装php-fpm时,一般同时安装如下 ...
- Codeforces Round #427 (Div. 2) E. The penguin's game (交互题,二进制分组)
E. The penguin's game time limit per test: 1 second memory limit per test: 256 megabytes input: stan ...
- mysql复制一个表到其他数据库
db1为原数据库,db2为要导出到的数据库,fromtable 是要导出的表名1.方法一:登录导出到的数据库,执行create table fromtable select * from db1.fr ...
- Windows2008R2+ IIS7.5+php+mysql 搭建教程
Windows2008R2+ IIS7.5+php+mysql 搭建教程 1. IIS7.5安装安装角色时候因为 Fastcgi 的需要, aspnet 和 asp 都要选装. 我为了方便,所有的除 ...
- 当浏览器窗口大小发生变化时,重新绘制JsPlumb中的线条、端点
1 window.addEventListener('resize', () => { 2 this.plumbInstance.repaintEverything() 3 }) 参考文章:ht ...
- java的“同一”与“相等”
变量:引用(指向地址) + 值(该变量指向值所储存的那一片内存) 两个变量同一 : 判断 是否 这两个变量指向同一片内存. 两个变量相等 : 判断 是否 这两个变量的类型相同,且值相等. 注:常用的& ...
- 4G DTU的应用场景介绍
4G DTU因为信号要比传统的gprs网络要好,目前已经被广泛应用于物联网产业链中的M2M行业,以远向4G DTU LTE-520为例,它的应用场景如智能电网.智能交通.智能家居.金融.移动 POS ...