linux nf_conntrack 连接跟踪机制 3-hook
conntrack hook函数分析
enum nf_ip_hook_priorities {
NF_IP_PRI_FIRST = INT_MIN,
NF_IP_PRI_CONNTRACK_DEFRAG = -400//优先级最大, 涉及到ip 分片重组
NF_IP_PRI_RAW = -300,
NF_IP_PRI_SELINUX_FIRST = -225,
NF_IP_PRI_CONNTRACK = -200,
NF_IP_PRI_MANGLE = -150,
NF_IP_PRI_NAT_DST = -100,
NF_IP_PRI_FILTER = 0,
NF_IP_PRI_SECURITY = 50,
NF_IP_PRI_NAT_SRC = 100,
NF_IP_PRI_SELINUX_LAST = 225,
NF_IP_PRI_CONNTRACK_HELPER = 300,
NF_IP_PRI_CONNTRACK_CONFIRM = INT_MAX,
NF_IP_PRI_LAST = INT_MAX,
};
连接跟踪机制在Netfilter框架里所注册的hook函数一共就五个:ipv4_conntrack_defrag()、ipv4_conntrack_in()、ipv4_conntrack_local()、ipv4_conntrack_help()和ipv4_confirm();
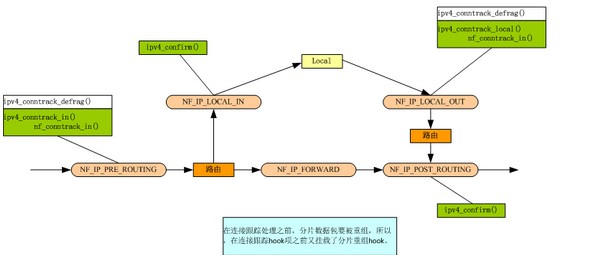
ipv4_conntrack_defrag 主要讲的是 分片重组 可以参考ip分片重组这篇文章。
- 这样数据包就会经过ipv4注册的钩子项,并调用nf_conntrack_in()函数建立连接表项,连接表项中的tuple由ipv4注册的3/4层协议处理函数构建。
- ipv4_conntrack_in() 挂载在NF_IP_PRE_ROUTING点上。该函数主要功能是创建链接,即创建struct nf_conn结构,同时填充struct nf_conn中的一些必要的信息,例如链接状态、引用计数、helper结构等。
- ipv4_confirm() 挂载在NF_IP_POST_ROUTING和NF_IP_LOCAL_IN点上。该函数主要功能是确认一个链接。对于一个新链接,在ipv4_conntrack_in()函数中只是创建了struct nf_conn结构,但并没有将该结构挂载到链接跟踪的Hash表中,因为此时还不能确定该链接是否会被NF_IP_FORWARD点上的钩子函数过滤掉,所以将挂载到Hash表的工作放到了ipv4_confirm()函数中。同时,子链接的helper功能也是在该函数中实现的。
- ipv4_conntrack_local() 挂载在NF_IP_LOCAL_OUT点上。该函数功能与ipv4_conntrack_in()函数基本相同,但其用来处理本机主动向外发起的链接。
- nf_conntrack_ipv4_compat_init() --> register_pernet_subsys() --> ip_conntrack_net_init() 创建/proc文件ip_conntrack和ip_conntrack_expect
nf_conntrack_in 分析:
/*
conntrack的工作主要是:
1. 由skb得到一个tuple,对数据包做合法性检查。
2. 查找net->ct.hash表是否已记录这个tuple。如果没有记录,则新建一个tuple及nf_conn并添加到unconfirmed链表中。
3. 对ct做一些协议相关的特定处理和检查。
4. 更新conntrack的状态ct->status和skb的状态skb->nfctinfo。
*/
unsigned int
nf_conntrack_in(struct net *net, u_int8_t pf, unsigned int hooknum,
struct sk_buff *skb)
{
struct nf_conn *ct, *tmpl = NULL;
enum ip_conntrack_info ctinfo;
struct nf_conntrack_l3proto *l3proto;
struct nf_conntrack_l4proto *l4proto;
unsigned int *timeouts;
unsigned int dataoff;
u_int8_t protonum;
int set_reply = 0;
int ret; if (skb->nfct) {nf_ct_get
/* Previously seen (loopback or untracked)? Ignore. 有点不明白 忽略 难道就是解决 lo场景
当skb->nfct为有效值时,即意味着该skb已经经过了conn track,再次落到conn track时。
如注释所说,比如发往回环的时候,会有这个情况。
*/
tmpl = (struct nf_conn *)skb->nfct;
if (!nf_ct_is_template(tmpl)) {
NF_CT_STAT_INC_ATOMIC(net, ignore);
return NF_ACCEPT;
}
skb->nfct = NULL;
} /* rcu_read_lock()ed by nf_hook_slow
根据proto family,来得到l3的conn track。
这里对于netfilter来说,它将conn track的具体工作下发到具体的L3层的target处理。
这样无论是ipv4还是ipv6,netfilter的处理可以保持一致。甚至其可以支持更多的L3协议。 对于ipv4来说,l3proto就是nf_conntrack_l3proto_ipv4。
*/
l3proto = __nf_ct_l3proto_find(pf);
/*
将L3的报文头的偏移即数据包skb传给l3->get_l4proto来得到L4的协议号即L4的起始位置。
这时L3的报文头完全由具体的L3层的proto负责解析
*/
ret = l3proto->get_l4proto(skb, skb_network_offset(skb),
&dataoff, &protonum);
if (ret <= 0) {
pr_debug("not prepared to track yet or error occurred\n");
NF_CT_STAT_INC_ATOMIC(net, error);
NF_CT_STAT_INC_ATOMIC(net, invalid);
ret = -ret;
goto out;
}
/*
/*
与L3类似,同样是通过L4的协议号得到具体的L4 proto的target。
实现与具体协议的解耦。
如nf_conntrack_l4proto_tcp4, nf_conntrack_l4proto_udp4等等
*/
*/
l4proto = __nf_ct_l4proto_find(pf, protonum); /* It may be an special packet, error, unclean...
* inverse of the return code tells to the netfilter
* core what to do with the packet. */
if (l4proto->error != NULL) {/* 对L4数据包进行正确性检查,由具体的L4协议负责 */
ret = l4proto->error(net, tmpl, skb, dataoff, &ctinfo,
pf, hooknum);
if (ret <= 0) {
NF_CT_STAT_INC_ATOMIC(net, error);
NF_CT_STAT_INC_ATOMIC(net, invalid);
ret = -ret;
goto out;
}
/* ICMP[v6] protocol trackers may assign one conntrack. */
if (skb->nfct)
goto out;
}
/* 根据skb L3和L4层的信息 得到一个nf_conn结构 */
ct = resolve_normal_ct(net, tmpl, skb, dataoff, pf, protonum,
l3proto, l4proto, &set_reply, &ctinfo);
if (!ct) {
/* Not valid part of a connection */
NF_CT_STAT_INC_ATOMIC(net, invalid);
ret = NF_ACCEPT;
goto out;
} if (IS_ERR(ct)) {
/* Too stressed to deal. */
NF_CT_STAT_INC_ATOMIC(net, drop);
ret = NF_DROP;
goto out;
} NF_CT_ASSERT(skb->nfct); /* Decide what timeout policy we want to apply to this flow. */
timeouts = nf_ct_timeout_lookup(net, ct, l4proto);
/*
将数据包传递给具体的L4 target进行特定的操作。
如nf_conntrack_l4proto_udp4,会update连接conn track的age,保证不ageout
更新超时时间时 可以详见 各个协议具体分析
对于nf_conntrack_l4proto_tcp4,会有更复杂的操作。
*/
ret = l4proto->packet(ct, skb, dataoff, ctinfo, pf, hooknum, timeouts);
if (ret <= 0) {
/* Invalid: inverse of the return code tells
* the netfilter core what to do */
pr_debug("nf_conntrack_in: Can't track with proto module\n");
nf_conntrack_put(skb->nfct);
skb->nfct = NULL;
NF_CT_STAT_INC_ATOMIC(net, invalid);
if (ret == -NF_DROP)
NF_CT_STAT_INC_ATOMIC(net, drop);
ret = -ret;
goto out;
}
/* 第一次收到应答,则设置IPS_SEEN_REPLY_BIT标记,原值为0,则需要记录应答事件 */
if (set_reply && !test_and_set_bit(IPS_SEEN_REPLY_BIT, &ct->status))
nf_conntrack_event_cache(IPCT_REPLY, ct);
out:
if (tmpl) {
/* Special case: we have to repeat this hook, assign the
* template again to this packet. We assume that this packet
* has no conntrack assigned. This is used by nf_ct_tcp. */
if (ret == NF_REPEAT)//set skb nfct 信息
skb->nfct = (struct nf_conntrack *)tmpl;
else
nf_ct_put(tmpl);
} return ret;
}
*
* 通过协议类型 pf 的值来得到该协议的L3层的协议处理函数,对于IPv4来说也就是IP网络层的处理函数
* 这些函数在 /net/ipv4/netfilter/nf_conntrack_l3proto_ipv4.c
* 文件中的 nf_conntrack_l3proto_ipv4 结构体中注册
*/
/*
* 通过L3层的 get_l4proto 函数获取L4层的协议类型,对于IPv4来说也就是TCP或者UDP运输层协议
* 对于TCP来说这些函数在 /net/netfilter/nf_conntrack_proto_tcp.c
* 文件中的 nf_conntrack_l4proto_tcp4 结构体中注册
*/ /*
* 调用L4层协议的 error 函数对数据包进行正确性检查,对于TCP协议来说调用的是
* nf_conntrack_l4proto_tcp4 结构体中的 tcp_error 函数
*/
/* 在函数resolve_normal_ct中对该数据包创建一个连接跟踪记录 */
/* L4proto->packet 对于TCP来说是设置TCP的各种状态信息,对于UDP来说就只设置了一个超时时间 */
resolve_normal_ct分析:
resolve_normal_ct函数首先会获取该数据包的五元组信息,然后通过这个信息计算出hash值,通过这个hash值在hash表中查找,如果没有找到则调用init_conntrack函数创建一个新的连接跟踪,要注意在创建连接跟踪的时候会同时创建两个方向的连接一个,一个是原始方向的称为IP_CT_DIR_ORIGINAL,另外一个是回复方向的称为IP_CT_DIR_REPLY,这样当此条连接的回复报文过来后就可以很快确认数据包属于哪条连接。回复方向的连接是在init_conntrack函数中调用nf_ct_invert_tuple函数创建的。最后调用nf_ct_set函数设置此数据包的连接跟踪标记。
ex:
原始方向:tuplehash[IP_CT_DIR_ORIGINAL] = {192.168.0.1:12345,200.200.200.200:80,TCP}
则回复方向为:tuplehash[IP_CT_DIR_REPLY] = {200.200.200.200:80,192.168.0.1:12345,TCP}
对于NAT 时 其五元组信息会改变。
static inline struct nf_conn *
resolve_normal_ct(struct net *net, struct nf_conn *tmpl,
struct sk_buff *skb,
unsigned int dataoff,
u_int16_t l3num,
u_int8_t protonum,
struct nf_conntrack_l3proto *l3proto,
struct nf_conntrack_l4proto *l4proto,
int *set_reply,
enum ip_conntrack_info *ctinfo)
{
const struct nf_conntrack_zone *zone;
struct nf_conntrack_tuple tuple;
struct nf_conntrack_tuple_hash *h;
struct nf_conntrack_zone tmp;
struct nf_conn *ct;
u32 hash;
/* 将数据包转换成tuple */
/* 由skb得出一个original方向的tuple,赋值给tuple,这是一个struct nf_conntrack_tuple结构,这里给其所有成员都赋值了,
以TCP包为例:
tuple->src.l3num = l3num;
tuple->src.u3.ip = srcip;
tuple->dst.u3.ip = dstip;
tuple->dst.protonum = protonum;
tuple->dst.dir = IP_CT_DIR_ORIGINAL;
tuple->src.u.tcp.port = srcport;
tuple->dst.u.tcp.port = destport;
调用L3proto->pkt_to_tuple() 以及 L4proto->pkt_to_tuple() 设置L3 L4信息
*/
if (!nf_ct_get_tuple(skb, skb_network_offset(skb),
dataoff, l3num, protonum, net, &tuple, l3proto,
l4proto)) {
pr_debug("Can't get tuple\n");
return NULL;
} /* look for tuple match */
zone = nf_ct_zone_tmpl(tmpl, skb, &tmp);
hash = hash_conntrack_raw(&tuple, net);//通过五元组信息计算一个 hash 值,是调用hash_conntrack函数,根据数据包对应的tuple实现的
/* 查找对应的tuple在连接跟踪表中是否存在 */
h = __nf_conntrack_find_get(net, zone, &tuple, hash);
if (!h) {/* 如果没有找到,则创建一对新的tuple(两个方向的tuple是同时创建的)及其
nf_conn结构,并添加到unconfirmed链表中。 */
h = init_conntrack(net, tmpl, &tuple, l3proto, l4proto,
skb, dataoff, hash);
if (!h)
return NULL;
if (IS_ERR(h))
return (void *)h;
}
ct = nf_ct_tuplehash_to_ctrack(h); /* It exists; we have (non-exclusive) reference. */
if (NF_CT_DIRECTION(h) == IP_CT_DIR_REPLY) { //是reply 放向
*ctinfo = IP_CT_ESTABLISHED_REPLY;
/* Please set reply bit if this packet OK */
*set_reply = 1;
} else { /* tuple为original方向,即初始的发送方向 */
/* Once we've had two way comms, always ESTABLISHED. */
if (test_bit(IPS_SEEN_REPLY_BIT, &ct->status)) {
pr_debug("normal packet for %p\n", ct); /* 之前收到过REPLY,那么ctinfo为established*/
*ctinfo = IP_CT_ESTABLISHED;
} else if (test_bit(IPS_EXPECTED_BIT, &ct->status)) {
pr_debug("related packet for %p\n", ct);/* 表明这是一个相关 期望的conn track。如ICMP error或者FTP的data session?????????*/
*ctinfo = IP_CT_RELATED;
} else {
pr_debug("new packet for %p\n", ct);/* 表明这是一个新的conn track*/
*ctinfo = IP_CT_NEW; //init ip_ct_new
}
*set_reply = 0;
}
/*
在struct nf_conn结构体中,ct_general是其第一个成员,所以它的地址和整个结构体的地址相同,
所以skb->nfct的值实际上就是skb对应的conntrack条目的地址,
因此通过(struct nf_conn *)skb->nfct就可以通过skb得到它的conntrack条目
*/
skb->nfct = &ct->ct_general;
skb->nfctinfo = *ctinfo;
return ct;
}
/* Allocate a new conntrack: we return -ENOMEM if classification
failed due to stress. Otherwise it really is unclassifiable. */
static struct nf_conntrack_tuple_hash *
init_conntrack(struct net *net, struct nf_conn *tmpl,
const struct nf_conntrack_tuple *tuple,
struct nf_conntrack_l3proto *l3proto,
struct nf_conntrack_l4proto *l4proto,
struct sk_buff *skb,
unsigned int dataoff, u32 hash)
{
struct nf_conn *ct;
struct nf_conn_help *help;
struct nf_conntrack_tuple repl_tuple;
struct nf_conntrack_ecache *ecache;
struct nf_conntrack_expect *exp = NULL;
const struct nf_conntrack_zone *zone;
struct nf_conn_timeout *timeout_ext;
struct nf_conntrack_zone tmp;
unsigned int *timeouts;
/* 根据tuple制作一个repl_tuple。主要是调用L3和L4的invert_tuple方法 */
if (!nf_ct_invert_tuple(&repl_tuple, tuple, l3proto, l4proto)) {
pr_debug("Can't invert tuple.\n");
return NULL;
}
/* 在cache中申请一个nf_conn结构,把tuple和repl_tuple赋值给ct的tuplehash[]数组,
并初始化ct.timeout定时器函数为death_by_timeout(),但不启动定时器。 *
*/
zone = nf_ct_zone_tmpl(tmpl, skb, &tmp);
ct = __nf_conntrack_alloc(net, zone, tuple, &repl_tuple, GFP_ATOMIC,
hash);
if (IS_ERR(ct))
return (struct nf_conntrack_tuple_hash *)ct; if (tmpl && nfct_synproxy(tmpl)) {
nfct_seqadj_ext_add(ct);
nfct_synproxy_ext_add(ct);
} timeout_ext = tmpl ? nf_ct_timeout_find(tmpl) : NULL;
if (timeout_ext) {
timeouts = nf_ct_timeout_data(timeout_ext);
if (unlikely(!timeouts))
timeouts = l4proto->get_timeouts(net);
} else {
timeouts = l4proto->get_timeouts(net);
}
/* 对tcp来说,下面函数就是将L4层字段如window, ack等字段
赋给ct->proto.tcp.seen[0],由于新建立的连接才调这里,所以
不用给reply方向的ct->proto.tcp.seen[1]赋值 */ if (!l4proto->new(ct, skb, dataoff, timeouts)) {
nf_conntrack_free(ct);
pr_debug("can't track with proto module\n");
return NULL;
} if (timeout_ext)
nf_ct_timeout_ext_add(ct, rcu_dereference(timeout_ext->timeout),
GFP_ATOMIC);
/* 为acct和ecache两个ext分配空间。不过之后一般不会被初始化,所以用不到 */
nf_ct_acct_ext_add(ct, GFP_ATOMIC);
nf_ct_tstamp_ext_add(ct, GFP_ATOMIC);
nf_ct_labels_ext_add(ct); ecache = tmpl ? nf_ct_ecache_find(tmpl) : NULL;
nf_ct_ecache_ext_add(ct, ecache ? ecache->ctmask : 0,
ecache ? ecache->expmask : 0,
GFP_ATOMIC); local_bh_disable();
/*
会在全局的期望连接链表expect_hash中查找是否有匹配新建tuple的期望连接。第一次过来的数据包肯定是没有的,
于是走else分支,__nf_ct_try_assign_helper()函数去nf_ct_helper_hash哈希表中匹配当前tuple,
由于我们在本节开头提到nf_conntrack_tftp_init()已经把tftp的helper extension添加进去了,
所以可以匹配成功,于是把找到的helper赋值给nfct_help(ct)->helper,而这个helper的help方法就是tftp_help()。
当tftp请求包走到ipv4_confirm的时候,会去执行这个help方法,即tftp_help(),也就是建立一个期望连接
当后续tftp传输数据时,在nf_conntrack_in里面,新建tuple后,在expect_hash表中查可以匹配到新建tuple的期望连接(因为只根据源端口来匹配),
因此上面代码的if成立,所以ct->master被赋值为exp->master,并且,还会执行exp->expectfn()函数,这个函数上面提到是指向nf_nat_follow_master()的,
该函数根据ct的master来给ct做NAT,ct在经过这个函数处理前后的tuple分别为:
*/
/* 在helper 函数中 回生成expect 并加入全局链表 同时 expect_count++*/
if (net->ct.expect_count) {
/* 如果在期望连接链表中 */
spin_lock(&nf_conntrack_expect_lock);
exp = nf_ct_find_expectation(net, zone, tuple);
/* 如果在期望连接链表中 */
if (exp) {
pr_debug("expectation arrives ct=%p exp=%p\n",
ct, exp);
/* Welcome, Mr. Bond. We've been expecting you... */
__set_bit(IPS_EXPECTED_BIT, &ct->status);
/* conntrack的master位指向搜索到的expected,而expected的sibling位指向conntrack……..解释一下,这时候有两个conntrack,
一个是一开始的初始连接(比如69端口的那个)也就是主连接conntrack1,
一个是现在正在处理的连接(1002)子连接conntrack2,两者和expect的关系是:
1. expect的sibling指向conntrack2,而expectant指向conntrack1,
2. 一个主连接conntrack1可以有若干个expect(int expecting表示当前数量),这些
expect也用一个链表组织,conntrack1中的struct list_head sibling_list就是该
链表的头。
3. 一个子连接只有一个主连接,conntrack2的struct ip_conntrack_expect *master
指向expect
通过一个中间结构expect将主连接和子连接关联起来 */
/* exp->master safe, refcnt bumped in nf_ct_find_expectation */
ct->master = exp->master;
if (exp->helper) {/* helper的ext以及help链表分配空间 */
help = nf_ct_helper_ext_add(ct, exp->helper,
GFP_ATOMIC);
if (help)
rcu_assign_pointer(help->helper, exp->helper);
} #ifdef CONFIG_NF_CONNTRACK_MARK
ct->mark = exp->master->mark;
#endif
#ifdef CONFIG_NF_CONNTRACK_SECMARK
ct->secmark = exp->master->secmark;
#endif
NF_CT_STAT_INC(net, expect_new);
}
spin_unlock(&nf_conntrack_expect_lock);
}
if (!exp) {// 如果不存在 从新赋值 ct->ext->...->help->helper = helper
__nf_ct_try_assign_helper(ct, tmpl, GFP_ATOMIC);
NF_CT_STAT_INC(net, new);
} /* Now it is inserted into the unconfirmed list, bump refcount */
nf_conntrack_get(&ct->ct_general);
/* 将这个tuple添加到unconfirmed链表中,因为数据包还没有出去,
所以不知道是否会被丢弃,所以暂时先不添加到conntrack hash中 */
nf_ct_add_to_unconfirmed_list(ct); local_bh_enable(); if (exp) {
if (exp->expectfn)
exp->expectfn(ct, exp);
nf_ct_expect_put(exp);
} return &ct->tuplehash[IP_CT_DIR_ORIGINAL];
}
ipv4_confirm分析:
ipv4_confirm相关函数完成对连接的确认,并且将连接按照方向加入到对应的hash表中;
static unsigned int ipv4_confirm(void *priv,
struct sk_buff *skb,
const struct nf_hook_state *state)
{
struct nf_conn *ct;
enum ip_conntrack_info ctinfo; ct = nf_ct_get(skb, &ctinfo);/* ct结构从下面获得: (struct nf_conn *)skb->nfct; */
/* 未关联,或者是 已建立连接的关联连接的响应 不明白*/
if (!ct || ctinfo == IP_CT_RELATED_REPLY)
goto out; /* adjust seqs for loopback traffic only in outgoing direction
/* 有调整序号标记,且不是环回包,调整序号 */
*/
if (test_bit(IPS_SEQ_ADJUST_BIT, &ct->status) &&
!nf_is_loopback_packet(skb)) {
if (!nf_ct_seq_adjust(skb, ct, ctinfo, ip_hdrlen(skb))) {
NF_CT_STAT_INC_ATOMIC(nf_ct_net(ct), drop);
return NF_DROP;
}
}
out:
/* We've seen it coming out the other side: confirm it */
return nf_conntrack_confirm(skb);
}
/* Confirm a connection: returns NF_DROP if packet must be dropped. */
static inline int nf_conntrack_confirm(struct sk_buff *skb)
{
struct nf_conn *ct = (struct nf_conn *)skb->nfct;
int ret = NF_ACCEPT; if (ct && !nf_ct_is_untracked(ct)) {/* 未确认,则进行确认 */
if (!nf_ct_is_confirmed(ct))
ret = __nf_conntrack_confirm(skb);
if (likely(ret == NF_ACCEPT)) /* accpet状态事件通知 */
nf_ct_deliver_cached_events(ct);//不是很明白
}
return ret;
} /* Confirm a connection given skb; places it in hash table
将该conntrack条目从unconfirmed链表中删除,并加入到已确认的链表中,
为该条目启动定时器,即该条目已经生效了
*/
int
__nf_conntrack_confirm(struct sk_buff *skb)
{
const struct nf_conntrack_zone *zone;
unsigned int hash, reply_hash;
struct nf_conntrack_tuple_hash *h;
struct nf_conn *ct;
struct nf_conn_help *help;
struct nf_conn_tstamp *tstamp;
struct hlist_nulls_node *n;
enum ip_conntrack_info ctinfo;
struct net *net;
unsigned int sequence;
int ret = NF_DROP; ct = nf_ct_get(skb, &ctinfo);
net = nf_ct_net(ct); /* ipt_REJECT uses nf_conntrack_attach to attach related
ICMP/TCP RST packets in other direction. Actual packet
which created connection will be IP_CT_NEW or for an
expected connection, IP_CT_RELATED. */
/* 如果不是original方向的包,直接返回 */
if (CTINFO2DIR(ctinfo) != IP_CT_DIR_ORIGINAL)
return NF_ACCEPT; zone = nf_ct_zone(ct);
local_bh_disable(); do {
sequence = read_seqcount_begin(&nf_conntrack_generation);
/* reuse the hash saved before */
hash = *(unsigned long *)&ct->tuplehash[IP_CT_DIR_REPLY].hnnode.pprev;
hash = scale_hash(hash);
reply_hash = hash_conntrack(net,
&ct->tuplehash[IP_CT_DIR_REPLY].tuple); } while (nf_conntrack_double_lock(net, hash, reply_hash, sequence)); /* We're not in hash table, and we refuse to set up related
* connections for unconfirmed conns. But packet copies and
* REJECT will give spurious warnings here.
*/
/* NF_CT_ASSERT(atomic_read(&ct->ct_general.use) == 1); */ /* No external references means no one else could have
* confirmed us.
*/
NF_CT_ASSERT(!nf_ct_is_confirmed(ct));
pr_debug("Confirming conntrack %p\n", ct);
/* We have to check the DYING flag after unlink to prevent
* a race against nf_ct_get_next_corpse() possibly called from
* user context, else we insert an already 'dead' hash, blocking
* further use of that particular connection -JM.
将 orig_tuple 从unconfirmd中删除
*/
nf_ct_del_from_dying_or_unconfirmed_list(ct); if (unlikely(nf_ct_is_dying(ct))) {
nf_ct_add_to_dying_list(ct);
goto dying;
} /* See if there's one in the list already, including reverse:
NAT could have grabbed it without realizing, since we're
not in the hash. If there is, we lost race. */
/* 待确认的连接如果已经在conntrack的hash表中(有一个方向存在就视为存在),就不再插入了,丢弃它 */
hlist_nulls_for_each_entry(h, n, &nf_conntrack_hash[hash], hnnode)
if (nf_ct_key_equal(h, &ct->tuplehash[IP_CT_DIR_ORIGINAL].tuple,
zone, net))
goto out; hlist_nulls_for_each_entry(h, n, &nf_conntrack_hash[reply_hash], hnnode)
if (nf_ct_key_equal(h, &ct->tuplehash[IP_CT_DIR_REPLY].tuple,
zone, net))
goto out; /* Timer relative to confirmation time, not original
setting time, otherwise we'd get timer wrap in
weird delay cases. */
ct->timeout.expires += jiffies;
add_timer(&ct->timeout);//一个nf_conn的超时处理函数death_by_timeout(),即超时后会执行这个函数:
atomic_inc(&ct->ct_general.use);//增加引用计数
ct->status |= IPS_CONFIRMED;//设置flag /* set conntrack timestamp, if enabled. */
tstamp = nf_conn_tstamp_find(ct);
if (tstamp) {
if (skb->tstamp.tv64 == 0)
__net_timestamp(skb); tstamp->start = ktime_to_ns(skb->tstamp);
}
/* Since the lookup is lockless, hash insertion must be done after
* starting the timer and setting the CONFIRMED bit. The RCU barriers
* guarantee that no other CPU can find the conntrack before the above
* stores are visible. 将 orig_tuple reply_tuple 添加到 nf_conntrack_hash
*/
__nf_conntrack_hash_insert(ct, hash, reply_hash);
nf_conntrack_double_unlock(hash, reply_hash);
NF_CT_STAT_INC(net, insert);
local_bh_enable(); help = nfct_help(ct);
if (help && help->helper)
nf_conntrack_event_cache(IPCT_HELPER, ct); nf_conntrack_event_cache(master_ct(ct) ?
IPCT_RELATED : IPCT_NEW, ct);
return NF_ACCEPT; out:
nf_ct_add_to_dying_list(ct);
ret = nf_ct_resolve_clash(net, skb, ctinfo, h);
dying:
nf_conntrack_double_unlock(hash, reply_hash);
NF_CT_STAT_INC(net, insert_failed);
local_bh_enable();
return ret;
}
EXPORT_SYMBOL_GPL(__nf_conntrack_confirm);
linux nf_conntrack 连接跟踪机制 3-hook的更多相关文章
- linux nf_conntrack 连接跟踪机制
PRE_ROUTING和LOCAL_OUT点可以看作是整个netfilter的入口,而POST_ROUTING和LOCAL_IN可以看作是其出口; 报文到本地:PRE_ROUTING----LOCAL ...
- linux nf_conntrack 连接跟踪机制 2
连接跟踪初始化 基础参数的初始化:nf_conntrack_standalone_init 会调用nf_conntrack_init_start 完成连接跟踪基础参数的初始化, hash slab 扩 ...
- Netfilter&iptables:如何理解连接跟踪机制?
如何理解Netfilter中的连接跟踪机制? 本篇我打算以一个问句开头,因为在知识探索的道路上只有多问然后充分调动起思考的机器才能让自己走得更远.连接跟踪定义很简单:用来记录和跟踪连接的状态. 问:为 ...
- Netfilter之连接跟踪实现机制初步分析
Netfilter之连接跟踪实现机制初步分析 原文: http://blog.chinaunix.net/uid-22227409-id-2656910.html 什么是连接跟踪 连接跟踪(CONNT ...
- [转]nf_conntrack: table full, dropping packet 连接跟踪表已满,开始丢包 的解决办法
nf_conntrack: table full, dropping packet 连接跟踪表已满,开始丢包 的解决办法 中午业务说机器不能登录,我通过USM管理界面登录单板的时候发现机器没有僵 ...
- linux内核netfilter连接跟踪的hash算法
linux内核netfilter连接跟踪的hash算法 linux内核中的netfilter是一款强大的基于状态的防火墙,具有连接跟踪(conntrack)的实现.conntrack是netfilte ...
- Netfilter 之 连接跟踪初始化
基础参数初始化 nf_conntrack_init_start函数完成连接跟踪基础参数的初始化,包括了hash,slab,扩展项,GC任务等: int nf_conntrack_init_start( ...
- linux下epoll实现机制
linux下epoll实现机制 原作者:陶辉 链接:http://blog.csdn.net/russell_tao/article/details/7160071 先简单回顾下如何使用C库封装的se ...
- Linux信号(signal) 机制分析
Linux信号(signal) 机制分析 [摘要]本文分析了Linux内核对于信号的实现机制和应用层的相关处理.首先介绍了软中断信号的本质及信号的两种不同分类方法尤其是不可靠信号的原理.接着分析了内核 ...
随机推荐
- 多测师讲解 _接口自动化框架设计分层思想(001)_高级讲师肖sir
第一层: 第二层:调用接口层 VOQGWBZYNBOAVZGE
- 2020年java全套教程,此套java涵盖了pdf,java源码,项目案例,完整视频约3000G的资源
疫情期间,百无聊赖,是不是需要充电一下,让自己更有竞争力呢?学习java一定要快呦! 废话不多说了,网盘已经爆炸了,把2006年-2020年的全部资料都发给爱学习的你吧, 希望可以改变你的命运,或者是 ...
- 用python you-get下载视频
安装python3后 安装you-get包: pip3 install you-get 下载视频: 打开windows终端:运行 you-get url 查看视频信息: you-get -i url ...
- C 和 C++ 打起来了!曾今最亲密的伙伴到现今的不爽?
70年代初,贝尔实验室创建了C语言,它是开发UNIX的副产品.很快C就成为了最受欢迎的编程语言之一.但是对于Bjarne Stroustrup来说,C的表达能力还不够.于是,他在1983年的博士论文中 ...
- linux(centos8):使用zip/unzip压缩和解压缩文件
一,查看zip命令所属的rpm包 1,zip [root@kubemaster ~]# whereis zip zip: /usr/bin/zip /usr/share/man/man1/zip.1. ...
- socket php
$socket = socket_create(AF_INET,SOCK_STREAM,SOL_TCP); socket_bind($socket,'0.0.0.0',6666); while(tru ...
- Docker学习笔记之-通过Xshell连接 CentOS服务
上一节演示如何在虚拟机中安装 CentOS服务,Docker学习笔记之-在虚拟机VM上安装CentOS 7.8 本节主要演示如何通过 Xshell软件链接CentOS服务,本例以虚拟机作为演示,直接在 ...
- tomcat在eclipse里部署
先下载安装包,解压缩,运行安装文件(端口:8080,下一步 指定jdk安装路径,记住tomcat的安装位置) 安装程序的位置 和 安装后的位置不一样 ...
- vivo 基于原生 RabbitMQ 的高可用架构实践
一.背景说明 vivo 在 2016 年引入 RabbitMQ,基于开源 RabbitMQ 进行扩展,向业务提供消息中间件服务. 2016~2018年,所有业务均使用一个集群,随着业务规模的增长,集群 ...
- 【5】TensorFlow光速入门-图片分类完整代码
本文地址:https://www.cnblogs.com/tujia/p/13862364.html 系列文章: [0]TensorFlow光速入门-序 [1]TensorFlow光速入门-tenso ...