Selective Acknowledgment 选项 浅析 2
来自:http://abcdxyzk.github.io/blog/2013/09/06/kernel-net-sack/
static int
tcp_sacktag_write_queue(struct sock *sk, const struct sk_buff *ack_skb,
u32 prior_snd_una, struct tcp_sacktag_state *state)
{
struct tcp_sock *tp = tcp_sk(sk);
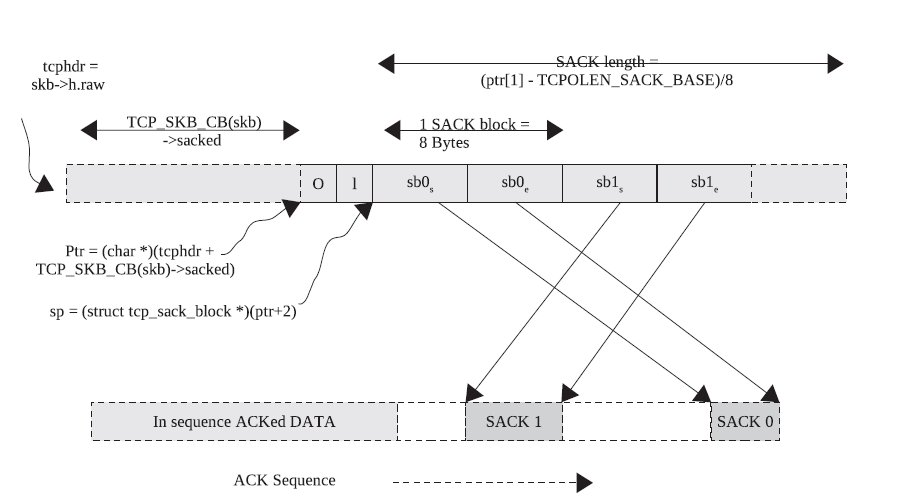
//ptr指向的就是SACK选项的起始位置
const unsigned char *ptr = (skb_transport_header(ack_skb) +
TCP_SKB_CB(ack_skb)->sacked);
//sp_wire在ptr的基础上前移两个字节,跳过选项的kind和len,指向SACK信息块的开始
struct tcp_sack_block_wire *sp_wire = (struct tcp_sack_block_wire *)(ptr+2);
//用于保存最后解析出来的SACK信息块,因为一个skb中最多可以携带4个,所以数组长度为4
struct tcp_sack_block sp[TCP_NUM_SACKS];
struct tcp_sack_block *cache;
struct sk_buff *skb;
//每个SACK信息块为8字节,所以num_sacks记录的是该skb中携带的SACK信息块的个数
int num_sacks = min(TCP_NUM_SACKS, (ptr[1] - TCPOLEN_SACK_BASE) >> 3);
int used_sacks;
bool found_dup_sack = false;
int i, j;
int first_sack_index; state->flag = 0;
state->reord = tp->packets_out;
//如果之前还没有SACK确认过的段,那么复位highest_sack域为发送队列的头部,即当前发送队列中
//最大的序号(该数据可能还尚未发送),
if (!tp->sacked_out) {
if (WARN_ON(tp->fackets_out))
tp->fackets_out = 0;
tcp_highest_sack_reset(sk);//因为当sacked_out为0,则说明没有通过sack确认的段,此时highest_sack自然就指向写队列的头。
//--->tcp_sk(sk)->highest_sack = tcp_write_queue_head(sk);
} } /*
D-SACK的判断是通过RFC2883中所描述的进行的。如果是下面两种情况,则说明收到了一个D-SACK。
1 如果SACK的第一个段所ack的区域被当前skb的ack所确认的段覆盖了一部分,则说明我们收到了一个d-sack,
而代码中也就是sack第一个段的起始序列号小于snd_una
2、如果sack的第二个段完全包含了第二个段,则说明我们收到了重复的sack
*/
found_dup_sack = tcp_check_dsack(sk, ack_skb, sp_wire,
num_sacks, prior_snd_una);
if (found_dup_sack)//检查是否有DSACK信息块,如果有,设置FLAG_DSACKING_ACK标记,表示输入段中有DSACK
state->flag |= FLAG_DSACKING_ACK; /* Eliminate too old ACKs, but take into
* account more or less fresh ones, they can
* contain valid SACK info.为接收方通告过的最大接收窗口。
* 如果SACK信息是很早以前的,直接丢弃
*/
if (before(TCP_SKB_CB(ack_skb)->ack_seq, prior_snd_una - tp->max_window))
return 0;
//当前根本就没有需要确认的段,所以也没有必要继续处理 if (!tp->packets_out)
goto out;
//后面会对sp[]数组按照SACK信息块中seq的大小做升序排列,first_sack_index
//记录了排序后原本输入段携带的第一个SACK信息块在sp[]中的位置,如果第一个
//SACK块无效,那么最终first_sack_index为-1
used_sacks = 0;
first_sack_index = 0;
for (i = 0; i < num_sacks; i++) {
//如果有DSACK,那么它一定在第一个位置。综合前面的判断设置dup_sack
bool dup_sack = !i && found_dup_sack; sp[used_sacks].start_seq = get_unaligned_be32(&sp_wire[i].start_seq);
sp[used_sacks].end_seq = get_unaligned_be32(&sp_wire[i].end_seq);
//如果SACK信息块无效,分别进行相关统计
if (!tcp_is_sackblock_valid(tp, dup_sack,
sp[used_sacks].start_seq,
sp[used_sacks].end_seq)) {
int mib_idx; if (dup_sack) {
if (!tp->undo_marker)
mib_idx = LINUX_MIB_TCPDSACKIGNOREDNOUNDO;
else
mib_idx = LINUX_MIB_TCPDSACKIGNOREDOLD;
} else {
/* Don't count olds caused by ACK reordering */
if ((TCP_SKB_CB(ack_skb)->ack_seq != tp->snd_una) &&
!after(sp[used_sacks].end_seq, tp->snd_una))
continue;
mib_idx = LINUX_MIB_TCPSACKDISCARD;
} NET_INC_STATS(sock_net(sk), mib_idx);
if (i == 0)//第一个SACK是无效的SACK,所以设置first_sack_index为-1
first_sack_index = -1;
continue;
} /* Ignore very old stuff early */
if (!after(sp[used_sacks].end_seq, prior_snd_una))
continue; used_sacks++;
} /* order SACK blocks to allow in order walk of the retrans queue
对实际使用的SACK块,按起始序列号,从小到大进行冒泡排序。*/
for (i = used_sacks - 1; i > 0; i--) {
for (j = 0; j < i; j++) {
if (after(sp[j].start_seq, sp[j + 1].start_seq)) {
swap(sp[j], sp[j + 1]); /* Track where the first SACK lock goes to */
if (j == first_sack_index)///注意first_sack_index会跟踪原始的第一个SACK信息块所在位置
first_sack_index = j + 1;
}
}
} skb = tcp_write_queue_head(sk);
state->fack_count = 0;
i = 0;
/*一旦收到对端的SACK信息,那么说明发生了丢包或者乱序,
而且这种状况可能往往无法 立即恢复,这意味着发送方会连续多次收到SACK信息,
而且这些SACK信息很可能是重复的。为了减少对发送队列的遍历次数,
这里发送方在用SACK信息块更新发送队列时采 用了cache机制。本质上也很简单,
就是将上一次的SACK信息块保存下来,在本次处理过程中,如果发现上一次已
经处理过了该范围的SACK,那么就可以跳过不处理。
cache //信息块就保存在tp->recv_sack_cache[]中
*/处理重传队列中的skb
重传队列中的skb有三种类型,分别是SACKED(S), RETRANS 和LOST(L),而每种类型所处理的数据包的个数分别保存在sacked_out, retrans_out 和lost_out中。
而处于重传队列的skb也就是会处于下面6中状态:
Valid combinations are: b
* Tag InFlight Description
* 0 1 - orig segment is in flight.inFlight也就是表示还在网络中的段的个数;没有ack的包
* S 0 - nothing flies, orig reached receiver.
* L 0 - nothing flies, orig lost by net.
* R 2 - both orig and retransmit are in flight.
* L|R 1 - orig is lost, retransmit is in flight.
* S|R 1 - orig reached receiver, retrans is still in flight.
* (L|S|R is logically valid, it could occur when L|R is sacked,
* but it is equivalent to plain S and code short-curcuits it to S.
* L|S is logically invalid, it would mean -1 packet in flight 8))
*
重传队列中的skb的状态变迁是通过下面这几种事件来触发的:
These 6 states form finite state machine, controlled by the following events:
* 1. New ACK (+SACK) arrives. (tcp_sacktag_write_queue())
* 2. Retransmission. (tcp_retransmit_skb(), tcp_xmit_retransmit_queue())
* 3. Loss detection event of two flavors:
* A. Scoreboard estimator decided the packet is lost.
* A'. Reno "three dupacks" marks head of queue lost.
* A''. Its FACK modification, head until snd.fack is lost.
* B. SACK arrives sacking SND.NXT at the moment, when the
* segment was retransmitted.
* 4. D-SACK added new rule: D-SACK changes any tag to S.
*
tcp socket的high_seq域,这个域是我们进入拥塞控制的时候最大的发送序列号,也就是snd_nxt.
if (!tp->sacked_out) {/* 如果之前没有SACK块 */
/* It's already past, so skip checking against it */
cache = tp->recv_sack_cache + ARRAY_SIZE(tp->recv_sack_cache);
} else {
cache = tp->recv_sack_cache;
/* Skip empty blocks in at head of the cache 上次的SACK 信息块保存在了数组的末尾n 个位置,
所以这里跳过开头的无效SACK信息*/
while (tcp_sack_cache_ok(tp, cache) && !cache->start_seq &&
!cache->end_seq)
cache++;
}
//下面的逻辑首先是检查cache和SACK信息块是否有交集,如果有,跳过当前SACK块,提高效率
while (i < used_sacks) {
u32 start_seq = sp[i].start_seq;
u32 end_seq = sp[i].end_seq;
bool dup_sack = (found_dup_sack && (i == first_sack_index));
struct tcp_sack_block *next_dup = NULL; if (found_dup_sack && ((i + 1) == first_sack_index))
next_dup = &sp[i + 1]; /* Skip too early cached blocks blocks如果cache的区间为[100, 200), 而当前SACK信息块的区间为[300, 400),
直接跳过这些cache块 */
while (tcp_sack_cache_ok(tp, cache) &&
!before(start_seq, cache->end_seq))
cache++; /* Can skip some work by looking recv_sack_cache?
cache和SACK块一定是有交集的*/
if (tcp_sack_cache_ok(tp, cache) && !dup_sack &&
after(end_seq, cache->start_seq)) {
//1. cache[100, 300), SACK[40, 440)
/* Head todo? */
if (before(start_seq, cache->start_seq)) {
skb = tcp_sacktag_skip(skb, sk, state,
start_seq);//前移发送队列,使得遍历指针知道seq为100的的地方
skb = tcp_sacktag_walk(skb, sk, next_dup,
state,//用[40, 100)即[start_seq, cache->start_seq)标记发送队列
start_seq,
cache->start_seq,
dup_sack);
} /* Rest of the block already fully processed? cache[100, 300), SACK[50, 200)SACK信息块的后半段已经全部被cache包含,
这部分已经标记过了,没必要重新标记,所以继续处理下一个SACK信息块 */
if (!after(end_seq, cache->end_seq))
goto advance_sp;
/*next_dup不为NULL的唯一一种情况就是输入段的DSACK信息块表示的确认范围被
后面的SACK信息块完全包裹,比如DSACK为[100, 200), 后面SACK为[50, 300),
只有这种情况,排序后,DSACK块才能排在SACK之后,这样next_dup才不为NULL
有可能DSACK和cache也有一部分重合
*///果start_seq < next_dup->start_seq < cache->start_seq,那么next_dup落在
//* (start_seq, cache->start_seq) 内的部分已经被上面的处理过了:)现在处理的next_dup的剩余部分
skb = tcp_maybe_skipping_dsack(skb, sk, next_dup,
state,
cache->end_seq); /* ...tail remains todo... */
if (tcp_highest_sack_seq(tp) == cache->end_seq) {
/* ...but better entrypoint exists! */
skb = tcp_highest_sack(sk);
if (!skb)/* 如果已经到了snd_nxt了,那么直接退出SACK块的遍历 */
break;
state->fack_count = tp->fackets_out;
cache++;
goto walk;
}
///跳过发送队列中那些序号小于cache->end_seq的skb,它们已经被标记过了
skb = tcp_sacktag_skip(skb, sk, state, cache->end_seq);
/* Check overlap against next cached too (past this one already) */
cache++;
continue;
}
//这个SACK信息块和cache块没有重叠,并且其start_seq一定大于所有的cache块的end_seq
if (!before(start_seq, tcp_highest_sack_seq(tp))) {
skb = tcp_highest_sack(sk);
if (!skb)
break;
state->fack_count = tp->fackets_out;
}
//跳过发送队列中那些序号小于start_seq的段
skb = tcp_sacktag_skip(skb, sk, state, start_seq); walk://更新序号位于[start_seq,end_seq)之间的skb的记分牌
skb = tcp_sacktag_walk(skb, sk, next_dup, state,
start_seq, end_seq, dup_sack); advance_sp:
i++;
}
、、
用上次缓存的tp->recv_sack_cache块来避免重复工作,提高处理效率。
主要思想就是,处理sack块时,和cache块作比较,如果它们有交集,说明交集部分已经处理过了,
不用再重复处理。
//更新cache,cache的大小同样是4个,并且每次收到SACK,上一次的cache内容都会清除,
//然后将本次接收的SACK块排序后的结果保存在cache中
/* Clear the head of the cache sack blocks so we can skip it next time */
for (i = 0; i < ARRAY_SIZE(tp->recv_sack_cache) - used_sacks; i++) {
tp->recv_sack_cache[i].start_seq = 0;
tp->recv_sack_cache[i].end_seq = 0;
}
for (j = 0; j < used_sacks; j++)
tp->recv_sack_cache[i++] = sp[j];
//更新乱序信息
if ((state->reord < tp->fackets_out) &&
((inet_csk(sk)->icsk_ca_state != TCP_CA_Loss) || tp->undo_marker))
tcp_update_reordering(sk, tp->fackets_out - state->reord, 0);
//更新计数器
tcp_verify_left_out(tp);
out: #if FASTRETRANS_DEBUG > 0
WARN_ON((int)tp->sacked_out < 0);
WARN_ON((int)tp->lost_out < 0);
WARN_ON((int)tp->retrans_out < 0);
WARN_ON((int)tcp_packets_in_flight(tp) < 0);
#endif
return state->flag;
}
tcp_sacktag_walk是遍历重传队列,找到对应需要设置的段,然后设置tcp_cb的sacked域为TCPCB_SACKED_ACKED,这里要注意,还有一种情况就是sack确认了多个skb,这个时候我们就需要合并这些skb,然后再处理
/*从参数skb指向的位置开始向后遍历发送队列,
更新序号位于[start_seq,end_seq)之间的skb的记分牌*/
static struct sk_buff *tcp_sacktag_walk(struct sk_buff *skb, struct sock *sk,
struct tcp_sack_block *next_dup,
struct tcp_sacktag_state *state,
u32 start_seq, u32 end_seq,
bool dup_sack_in)
{
struct tcp_sock *tp = tcp_sk(sk);
struct sk_buff *tmp; tcp_for_write_queue_from(skb, sk) {
int in_sack = 0;
bool dup_sack = dup_sack_in;
//已经遍历到了tp->sk_send_head,后面的skb还没有发送,结束处理
if (skb == tcp_send_head(sk))
break;
//因为发送队列中skb的序号是递增的,而当前skb的seq大于等于
//SACK块的末尾序号,说明该skb和SACK信息块已经没有交集了,
//而且发送队列后续skb也不会和该SACK信息块有交集了,结束处理
/* queue is in-order => we can short-circuit the walk early */
if (!before(TCP_SKB_CB(skb)->seq, end_seq))
break;
/*//假设用序号dseq和dend表示DSACK信息块的序号,
DSACK有两种情形:
1)dend<=snd_una,即DSACK是由已经ACK的数据段触发的;
2)dend>sud_una并且DSACK信息块的序号被后面的SACK信息块包含;
//情形1根本就无需更新记分牌,所以如果next_dup不为NULL,那么一定
//是情形2。此时,由于DSACK被SACK包围,所以一定是先处理SACK
//然后再处理DSACK,此时为了避免重复遍历发送队列,所以需要同时处理这 两个SACK信息块。
*/
/*下一个是DSACK块,需要先处理DSACK块。如果dend>=skb->seq,
//说明DSACK块和当前skb可能有交集*/
if (next_dup &&
before(TCP_SKB_CB(skb)->seq, next_dup->end_seq)) {
//传入的序号范围是DSACK的序号范围
in_sack = tcp_match_skb_to_sack(sk, skb,
next_dup->start_seq,
next_dup->end_seq);
//1)in_sack==0:压根就没有DSACK;
//2)DSACK无法确认skb;
//3)in_sack<0:DSACK导致了skb分片,但是分片失败了
if (in_sack > 0)
dup_sack = true;
} /* skb reference here is a bit tricky to get right, since
* shifting can eat and free both this skb and the next,
* so not even _safe variant of the loop is enough.
*/
if (in_sack <= 0) {
//对于情形1,没得说,这里用SACK检测。情形2和3也一样是因为SACK是DSACK的超集
tmp = tcp_shift_skb_data(sk, skb, state,
start_seq, end_seq, dup_sack);
if (tmp) {
if (tmp != skb) {
skb = tmp;
continue;
} in_sack = 0;
} else {
in_sack = tcp_match_skb_to_sack(sk, skb,
start_seq,
end_seq);
}
}
//结果小于0,说明skb分割失败,处理结束
if (unlikely(in_sack < 0))
break;
//如果最终检测到skb数据可以被确认,则标记该skb
if (in_sack) {
TCP_SKB_CB(skb)->sacked =
/* Mark the given newly-SACKed range as such, adjusting counters and hints.
用来设置对应的tag,这里所要设置的也就是tcp_cb的sacked域
值 为:
#define TCPCB_SACKED_ACKED 0x01 /* SKB ACK'd by a SACK block
#define TCPCB_SACKED_RETRANS 0x02 /* SKB retransmitted
#define TCPCB_LOST 0x04 /* SKB is lost
#define TCPCB_TAGBITS 0x07 /* All tag bits
#define TCPCB_EVER_RETRANS 0x80 /* Ever retransmitted frame
#define TCPCB_RETRANS (TCPCB_SACKED_RETRANS|TCPCB_EVER_RETRANS)
*/
tcp_sacktag_one(sk,
state,
TCP_SKB_CB(skb)->sacked,
TCP_SKB_CB(skb)->seq,
TCP_SKB_CB(skb)->end_seq,
dup_sack,
tcp_skb_pcount(skb),
&skb->skb_mstamp); if (!before(TCP_SKB_CB(skb)->seq,
tcp_highest_sack_seq(tp)))
tcp_advance_highest_sack(sk, skb);
} state->fack_count += tcp_skb_pcount(skb);
}
return skb;
} /* Avoid all extra work that is being done by sacktag while walking in
* a normal way 参数skb指向发送队列中的某个skb,该函数从skb开始向后遍历发送队列,
直到遍历到sk->sk_send_head(即下一个要发送的skb,
可能为NULL)或者skb的末尾序号
(假设序号范围为[seq1, end1))end1大于等于参数skip_to_seq为止,
返回终止时的skb指针。
该函数的作用就是跳过那些序号小于SACK信息块确认范围的skb。
*/
static struct sk_buff *tcp_sacktag_skip(struct sk_buff *skb, struct sock *sk,
struct tcp_sacktag_state *state,
u32 skip_to_seq)
{
tcp_for_write_queue_from(skb, sk) {
if (skb == tcp_send_head(sk))
break; if (after(TCP_SKB_CB(skb)->end_seq, skip_to_seq))
break; state->fack_count += tcp_skb_pcount(skb);
}
return skb;
}
note:SACK 选项的接收方在收到一个包后可能会被要求做大量处理。这种 N:1 的比例使 SACK 发送方可以打击非常强大的平台上的接收方。
然后攻击者发送一个充满 SACK 选项的包,目的是使另一方主机扫描整个队列以处理每个选项。一个指向队列末尾包的选项可能会迫使接收方的 TCP 协议栈遍历整个队列以判断此选项指向哪一个包。显然,攻击客户机可以根据自己的喜好发送任何 SACK 选项,但不太容易看出的一个问题是,它可以轻易控制被攻击方的重传队列的长度。SACK 选项的创建者可以控制接收者对接收到的每个选项执行的工作量,因为它也可以控制队列的大小。
Selective Acknowledgment 选项 浅析 2的更多相关文章
- Selective Acknowledgment 选项 浅析 1
抓包的时候,发现 tcp 三次握手中一般会有几个options 一个是mss 一个是ws 一个sack perm 这次主要是来说一说 sack 这个选项: 1. 只重传超时的数据包,比较实用与后 ...
- 从TCP三次握手说起–浅析TCP协议中的疑难杂症(2)
版权声明:本文由黄日成原创文章,转载请注明出处: 文章原文链接:https://www.qcloud.com/community/article/108 来源:腾云阁 https://www.qclo ...
- 浅析TCP协议---转载
https://cloud.tencent.com/developer/article/1150971 前言 说到TCP协议,相信大家都比较熟悉了,对于TCP协议总能说个一二三来,但是TCP协议又是一 ...
- 在深谈TCP/IP三步握手&四步挥手原理及衍生问题—长文解剖IP
如果对网络工程基础不牢,建议通读<细说OSI七层协议模型及OSI参考模型中的数据封装过程?> 下面就是TCP/IP(Transmission Control Protoco/Interne ...
- [转帖]技术扫盲:新一代基于UDP的低延时网络传输层协议——QUIC详解
技术扫盲:新一代基于UDP的低延时网络传输层协议——QUIC详解 http://www.52im.net/thread-1309-1-1.html 本文来自腾讯资深研发工程师罗成的技术分享, ...
- PROC 文件系统调节参数介绍(netstat -us)
转自:http://www.cnblogs.com/super-king/p/3296333.html /proc/net/* snmp文件 Ip: ip项 Forwarding : 是 ...
- linux下TCP/IP及内核参数优化调优(转)
Linux下TCP/IP及内核参数优化有多种方式,参数配置得当可以大大提高系统的性能,也可以根据特定场景进行专门的优化,如TIME_WAIT过高,DDOS攻击等等. 如下配置是写在sysctl.con ...
- (转)Linux服务器调优
Linux内核参数 http://space.itpub.net/17283404/viewspace-694350 net.ipv4.tcp_syncookies = 1 表示开启SYN Cooki ...
- Linux内核参数配置
Linux在系统运行时修改内核参数(/proc/sys与/etc/sysctl.conf),而不需要重新引导系统,这个功能是通过/proc虚拟文件系统实现的. 在/proc/sys目录下存放着大多数的 ...
随机推荐
- redis协议规范
好多年前看过redis的代码,那个时候还是2.6的版本,集群和哨兵还没加入正式代码,这几年redis发展的好快.简略翻译一篇文章redis的https://redis.io/topics/protoc ...
- 多测师讲解a'pi自动化框架设计思想_高级讲师肖sir
API自动化框架API自动化框架分为conf.data.utils.api.testcase.runner.report.log8个模块.conf是用来储存系统环境.数据库.邮件等的配置参数.项目的绝 ...
- MeteoInfoLab脚本示例:加载地图图层
应用最广泛的的地图数据应该是shape格式,网络上有很多免费下载资源.MeteoInfoLab中读取shape文件的函数是shaperead,参数即文件名,返回数据包含图形和属性信息的图层对象.矢量图 ...
- Python自动化准备工作(pycharm安装)
一.安装Python 1.下载python-3.7.0-amd64.exe后双击 2.勾选Add Python3.7 to PATH可不用配置环境变量 3.点击下一步,可以按默认路径,也可以自己选择路 ...
- C# 面试前的准备_基础知识点的回顾_01
本系列本章来至于http://www.cnblogs.com/LionelMessi/p/4311931.html 1.try{} 里面有个Return语句,那么紧跟try后面的Finally{}会不 ...
- git学习(十一) idea git pull 解决冲突
测试如下: 先将远程的代码修改,之后更新: 之后将工作区修改的代码(这里修改的代码跟远程修改的位置一样)提交到本地,之后拉取远程的代码,会发现有冲突: Accept Yours 就是直接选取本地的代码 ...
- 基于ssm的客户管理系统
查看更多系统:系统大全,课程设计.毕业设计,请点击这里查看 01 概述 一个简单的客户关系管理系统 管理用户的基本数据 客户的分配 客户的流失 已经客户的状态 02 技术 ssm + jdk1.8 + ...
- 自定义Jackson2HttpMessageConverter,适应.html后缀url
Jackson2HttpMessageConverter 用处 SpringMVC中,controller中的方法返回java Bean对象,mvc将此对象转换成字符串 默认支持的mediaType: ...
- 使用udev高效、动态的管理Linux设备文件
导读: 在Linux环境中,所有的设备都以文件的形式存在,在早期的Linux版本中,/dev目录包含了了所有可能出现的设备文件,很难想象Linux用户如何从大量的设备文件中找到想要的设备文件.举个例子 ...
- Yii2使用数据库操作汇总(增删查改、事务)
查询 //1.简单查询 $admin=Admin::model()->findAll($condition,$params); $admin=Admin::model()->findAll ...