Python爬虫学习第一记 (翻译小助手)
1 # Python爬虫学习第一记 8.24 (代码有点小,请放大看吧)
2
3 #实现有道翻译,模块一: $fanyi.py
4
5 import urllib.request
6 import urllib.parse
7 import json
8
9 # word 是将要传入的翻译的内容
10
11 def fanyi(word):
12 while 1:
13 # 去掉url中的 _o 可以解决反爬虫机制
14 url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
15 data={} # 定义一个data字典
16
17 data['i']= word #don't del
18 data['doctype']='json' #don't del
19
20 #data['from']='AUTO'
21 #data['version']='2.1'
22 #data['keyfrom']='fanyi.web'
23 #data['ue']='utf-8'
24 #data['typoResult']='true'
25
26 # 对数据进行编码处理
27 data=urllib.parse.urlencode(data).encode('utf-8')
28
29 # 创建一个res对象,把url和data传进去,并且同时打开这个请求,并且需要注意的使用的是POST请求
30 res = urllib.request.urlopen(url,data)
31 # 进行读取数据并且进行解码操作
32 html=res.read().decode('utf-8')
33 tar=json.loads(html)
34
35 # 返回值为t,也就是翻译之后的内容
36 t=tar['translateResult'][0][0]['tgt']
37 return t
38
39 #初步完成,使用示例:t = fanyi('hello')
------BTLord 小白工作室

以上是第一个模块,接下来将引用以上的这个模块,利用easygui来创建简单图形用户界面
1 # 翻译的小助手 $ 8.27 爬虫(GUI简单界面)
2 import easygui as g
3 import sys
4
import fanyi # 添加翻译模块 while 1:
# 弹出一个对话编辑框
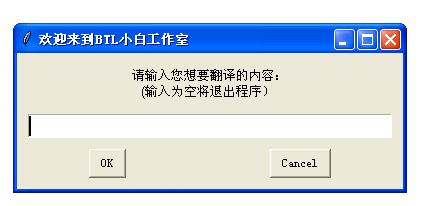
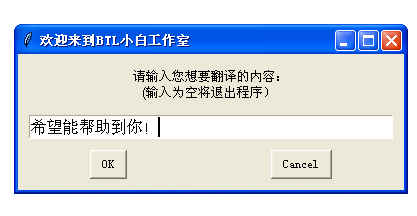
ret=g.enterbox('请输入您想要翻译的内容:\n (输入为空将退出程序)','欢迎来到BTL小白工作室')
# 判断用户点击情况,并且执行相应内容 if ret==None:
sys.exit(0) # 判断点 × 和取消 键的情况,如果是,退出程序 t=fanyi.fanyi(ret)
# 弹出一个选择框,返回值为1或0
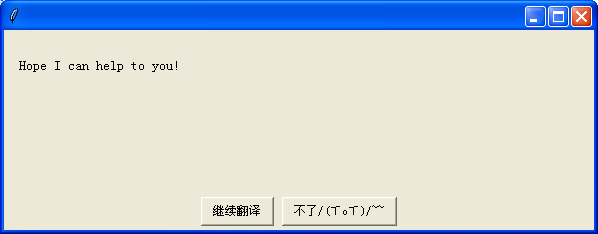
if g.ccbox(t,choices=("继续翻译","不了/(ㄒoㄒ)/~~")):
t=fanyi.fanyi(ret)
else:
sys.exit(0) # 翻译的小程序到此,告一段落,(为什么是 小 程序呢,因为它只能翻译少许内容,具体多少呢,嘿嘿嘿!)
 这两个文件必须在同一个目录,才可以执行。
这两个文件必须在同一个目录,才可以执行。
附上程序图 :
2020-08-27 -BTL 小白工作室
Python爬虫学习第一记 (翻译小助手)的更多相关文章
- Python爬虫学习==>第一章:Python3+Pip环境配置
前置操作 软件名:anaconda 版本:Anaconda3-5.0.1-Windows-x86_64清华镜像 下载链接:https://mirrors.tuna.tsinghua.edu.cn/ ...
- Pyqt5开发一款小工具(翻译小助手)
翻译小助手 开发需求 首先五月份的时候,正在学习爬虫的中级阶段,这时候肯定要接触到js逆向工程,于是上网找了一个项目来练练手,这时碰巧有如何进行对百度翻译的API破解思路,仿造网上的思路,我摸索着完成 ...
- python爬虫学习(1) —— 从urllib说起
0. 前言 如果你从来没有接触过爬虫,刚开始的时候可能会有些许吃力 因为我不会从头到尾把所有知识点都说一遍,很多文章主要是记录我自己写的一些爬虫 所以建议先学习一下cuiqingcai大神的 Pyth ...
- python爬虫学习 —— 总目录
开篇 作为一个C党,接触python之后学习了爬虫. 和AC算法题的快感类似,从网络上爬取各种数据也很有意思. 准备写一系列文章,整理一下学习历程,也给后来者提供一点便利. 我是目录 听说你叫爬虫 - ...
- Python爬虫学习:三、爬虫的基本操作流程
本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:三.爬虫的基本操作与流程 一般我们使用Python爬虫都是希望实现一套完整的功能,如下: 1.爬虫目标数据.信息: 2.将 ...
- Python爬虫学习:二、爬虫的初步尝试
我使用的编辑器是IDLE,版本为Python2.7.11,Windows平台. 本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:二.爬虫的初步尝试 1.尝试抓取指定网页 ...
- 《Python爬虫学习系列教程》学习笔记
http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多.学习过程中我把一些学习的笔记总结下来,还记录了一些自己 ...
- [转]《Python爬虫学习系列教程》
<Python爬虫学习系列教程>学习笔记 http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多. ...
- Python爬虫学习:四、headers和data的获取
之前在学习爬虫时,偶尔会遇到一些问题是有些网站需要登录后才能爬取内容,有的网站会识别是否是由浏览器发出的请求. 一.headers的获取 就以博客园的首页为例:http://www.cnblogs.c ...
随机推荐
- [luogu4140] 奇数国
题目 在一片美丽的大陆上有100000个国家,记为1到100000.这里经济发达,有数不尽的账房,并且每个国家有一个银行.某大公司的领袖在这100000个银行开户时都存了3大洋,他惜财如命,因此会不时 ...
- storcli 命令(更新Ing)
help [root@centos7]# storcli -h Storage Command Line Tool Ver 007.0606.0000.0000 Mar , (c)Copyright ...
- Git使用之submodule
入职第一周,就因为clone项目而产生了很大的障碍,花了差不多三四个小时才定位问题并解决,记录一下. 一.问题 当我们在使用Git克隆项目的时候,无法克隆下来一个文件夹.记该文件夹为A,A在远程仓库是 ...
- 用C++基础语句写一个五子棋游戏
(这是一个颜色会变化的呦) #include <iostream> using namespace std; int b[][]; int n; int m; void qipan() { ...
- node.js03 第一个node.js程序和读取文件
Hello World 1.创建运行 创建txt文件起名为hellonode,在记事本中编写JavaScript脚本文件 例如: var bbl = 'hellonode' console.log(b ...
- 自动化项目Jenkins持续集成
一.Jenkins的优点 1.传统网站部署流程 一般网站部署的流程 这边是完整流程而不是简化的流程 需求分析—原型设计—开发代码—内网部署-提交测试—确认上线—备份数据—外网更新-最终测试 ,如果 ...
- mysql事务级别和spring中应用
一.事务的基本要素(ACID) 1.原子性(Atomicity):事务开始后所有操作,要么全部做完,要么全部不做,不可能停滞在中间环节.事务执行过程中出错,会回滚到事务开始前的状态,所有的操作就像没有 ...
- 【Flutter 实战】自定义动画-涟漪和雷达扫描
老孟导读:此篇文章是 Flutter 动画系列文章第五篇,本文介绍2个自定义动画:涟漪和雷达扫描效果. 涟漪 实现涟漪动画效果如下: 此动画通过 CustomPainter 绘制配合 Animatio ...
- Qt 改变鼠标形状
Qt 改变鼠标形状(转载) 改变鼠标形状,在绘制坐标系的时候有用到,特此记下: 1 this->setMouseTracking(true); //设置为不按下鼠标键触发moveEvent 2 ...
- Ubuntu 20.04.1 安装软件和系统配置脚本
#!/bin/bash # https://launchpad.net/ubuntu # https://www.easyicon.net # https://download-chromium.ap ...