天啦噜!知道硬盘很慢,但没想到比 CPU L1 Cache 慢 10000000 倍
前言
大家如果想自己组装电脑的话,肯定需要购买一个 CPU,但是存储器方面的设备,分类比较多,那我们肯定不能只买一种存储器,比如你除了要买内存,还要买硬盘,而针对硬盘我们还可以选择是固态硬盘还是机械硬盘。
相信大家都知道内存和硬盘都属于计算机的存储设备,断电后内存的数据是会丢失的,而硬盘则不会,因为硬盘是持久化存储设备,同时也是一个 I/O 设备。
但其实 CPU 内部也有存储数据的组件,这个应该比较少人注意到,比如寄存器、CPU L1/L2/L3 Cache 也都是属于存储设备,只不过它们能存储的数据非常小,但是它们因为靠近 CPU 核心,所以访问速度都非常快,快过硬盘好几个数量级别。
问题来了,那机械硬盘、固态硬盘、内存这三个存储器,到底和 CPU L1 Cache 相比速度差多少倍呢?
在回答这个问题之前,我们先来看看「存储器的层次结构」,好让我们对存储器设备有一个整体的认识。
正文
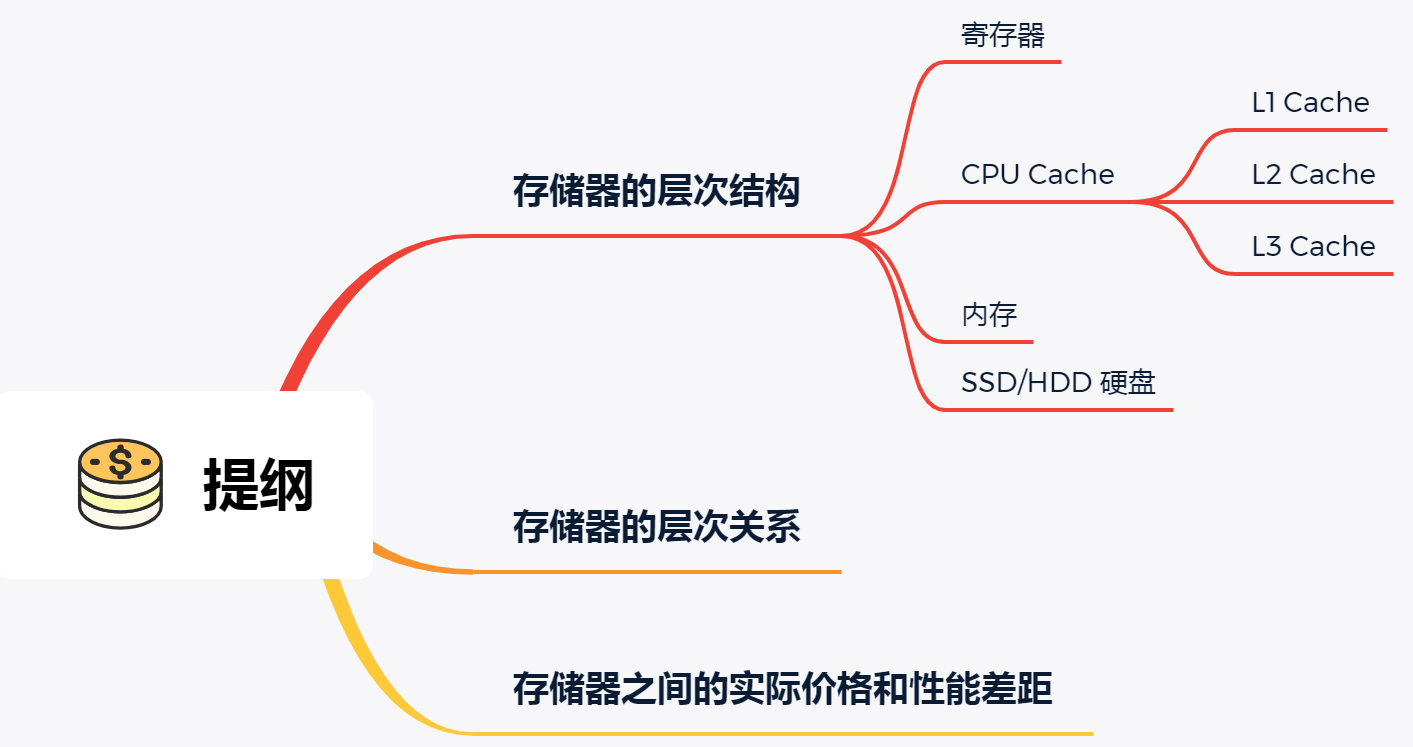
存储器的层次结构
我们想象中一个场景,大学期末准备考试了,你前去图书馆临时抱佛脚。那么,在看书的时候,我们的大脑会思考问题,也会记忆知识点,另外我们通常也会把常用的书放在自己的桌子上,当我们要找一本不常用的书,则会去图书馆的书架找。
就是这么一个小小的场景,已经把计算机的存储结构基本都涵盖了。
我们可以把 CPU 比喻成我们的大脑,大脑正在思考的东西,就好比 CPU 中的寄存器,处理速度是最快的,但是能存储的数据也是最少的,毕竟我们也不能一下同时思考太多的事情,除非你练过。
我们大脑中的记忆,就好比 CPU Cache,中文称为 CPU 高速缓存,处理速度相比寄存器慢了一点,但是能存储的数据也稍微多了一些。
CPU Cache 通常会分为 L1、L2、L3 三层,其中 L1 Cache 通常分成「数据缓存」和「指令缓存」,L1 是距离 CPU 最近的,因此它比 L2、L3 的读写速度都快、存储空间都小。我们大脑中短期记忆,就好比 L1 Cache,而长期记忆就好比 L2/L3 Cache。
寄存器和 CPU Cache 都是在 CPU 内部,跟 CPU 挨着很近,因此它们的读写速度都相当的快,但是能存储的数据很少,毕竟 CPU 就这么丁点大。
知道 CPU 内部的存储器的层次分布,我们放眼看看 CPU 外部的存储器。
当我们大脑记忆中没有资料的时候,可以从书桌或书架上拿书来阅读,那我们桌子上的书,就好比内存,我们虽然可以一伸手就可以拿到,但读写速度肯定远慢于寄存器,那图书馆书架上的书,就好比硬盘,能存储的数据非常大,但是读写速度相比内存差好几个数量级,更别说跟寄存器的差距了。
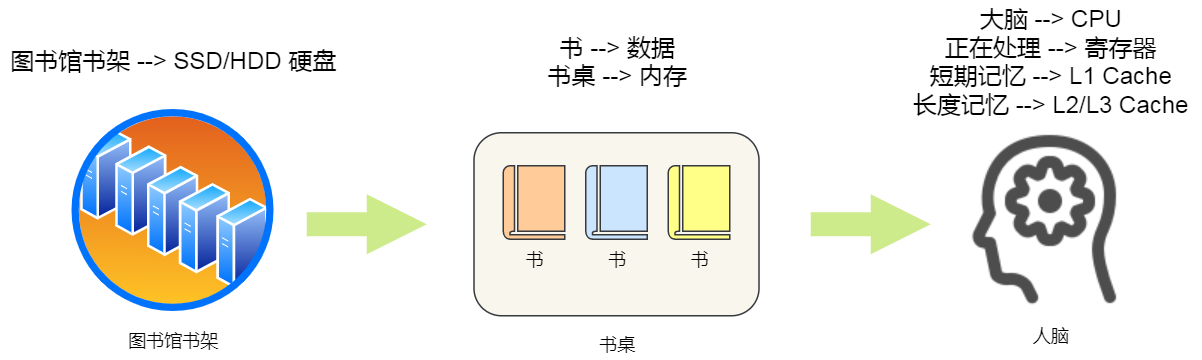
我们从图书馆书架取书,把书放到桌子上,再阅读书,我们大脑就会记忆知识点,然后再经过大脑思考,这一系列过程相当于,数据从硬盘加载到内存,再从内存加载到 CPU 的寄存器和 Cache 中,然后再通过 CPU 进行处理和计算。
对于存储器,它的速度越快、能耗会越高、而且材料的成本也是越贵的,以至于速度快的存储器的容量都比较小。
CPU 里的寄存器和 Cache,是整个计算机存储器中价格最贵的,虽然存储空间很小,但是读写速度是极快的,而相对比较便宜的内存和硬盘,速度肯定比不上 CPU 内部的存储器,但是能弥补存储空间的不足。
存储器通常可以分为这么几个级别:
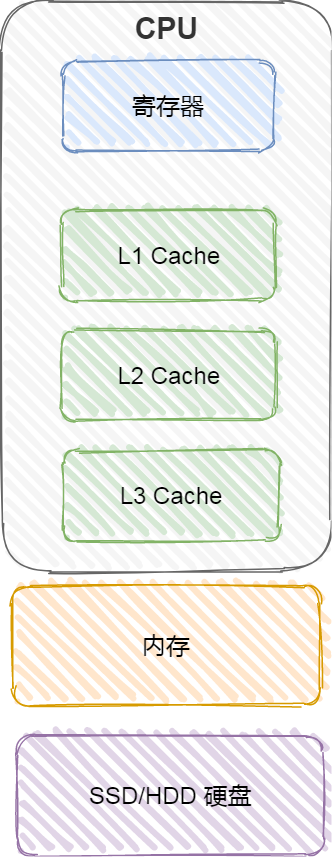
- 寄存器;
- CPU Cache;
- L1-Cache;
- L2-Cache;
- L3-Cahce;
- 内存;
- SSD/HDD 硬盘
寄存器
最靠近 CPU 的控制单元和逻辑计算单元的存储器,就是寄存器了,它使用的材料速度也是最快的,因此价格也是最贵的,那么数量不能很多。
存储器的数量通常在几十到几百之间,每个寄存器可以用来存储一定的字节(byte)的数据。比如:
- 32 位 CPU 中大多数寄存器可以存储
4个字节; - 64 位 CPU 中大多数寄存器可以存储
8个字节。
寄存器的访问速度非常快,一般要求在半个 CPU 时钟周期内完成读写,CPU 时钟周期跟 CPU 主频息息相关,比如 2 GHz 主频的 CPU,那么它的时钟周期就是 1/2G,也就是 0.5ns(纳秒)。
CPU 处理一条指令的时候,除了读写寄存器,还需要解码指令、控制指令执行和计算。如果寄存器的速度太慢,则会拉长指令的处理周期,从而给用户的感觉,就是电脑「很慢」。
CPU Cache
CPU Cache 用的是一种叫 SRAM(Static Random-Access Memory,静态随机存储器) 的芯片。
SRAM 之所以叫「静态」存储器,是因为只要有电,数据就可以保持存在,而一旦断电,数据就会丢失了。
在 SRAM 里面,一个 bit 的数据,通常需要 6 个晶体管,所以 SRAM 的存储密度不高,同样的物理空间下,能存储的数据是有限的,不过也因为 SRAM 的电路简单,所以访问速度非常快。
CPU 的高速缓存,通常可以分为 L1、L2、L3 这样的三层高速缓存,也称为一级缓存、二次缓存、三次缓存。

L1 高速缓存
L1 高速缓存的访问速度几乎和寄存器一样快,通常只需要 2~4 个时钟周期,而大小在几十 KB 到几百 KB 不等。
每个 CPU 核心都有一块属于自己的 L1 高速缓存,指令和数据在 L1 是分开存放的,所以 L1 高速缓存通常分成指令缓存和数据缓存。
在 Linux 系统,我们可以通过这条命令,查看 CPU 里的 L1 Cache 「数据」缓存的容量大小:
$ cat /sys/devices/system/cpu/cpu0/cache/index0/size
32K
而查看 L1 Cache 「指令」缓存的容量大小,则是:
$ cat /sys/devices/system/cpu/cpu0/cache/index1/size
32K
L2 高速缓存
L2 高速缓存同样每个 CPU 核心都有,但是 L2 高速缓存位置比 L1 高速缓存距离 CPU 核心 更远,它大小比 L1 高速缓存更大,CPU 型号不同大小也就不同,通常大小在几百 KB 到几 MB 不等,访问速度则更慢,速度在 10~20 个时钟周期。
在 Linux 系统,我们可以通过这条命令,查看 CPU 里的 L2 Cache 的容量大小:
$ cat /sys/devices/system/cpu/cpu0/cache/index2/size
256K
L3 高速缓存
L3 高速缓存通常是多个 CPU 核心共用的,位置比 L2 高速缓存距离 CPU 核心 更远,大小也会更大些,通常大小在几 MB 到几十 MB 不等,具体值根据 CPU 型号而定。
访问速度相对也比较慢一些,访问速度在 20~60个时钟周期。
在 Linux 系统,我们可以通过这条命令,查看 CPU 里的 L3 Cache 的容量大小:
$ cat /sys/devices/system/cpu/cpu0/cache/index3/size
3072K
内存
内存用的芯片和 CPU Cache 有所不同,它使用的是一种叫作 DRAM (Dynamic Random Access Memory,动态随机存取存储器) 的芯片。
相比 SRAM,DRAM 的密度更高,功耗更低,有更大的容量,而且造价比 SRAM 芯片便宜很多。
DRAM 存储一个 bit 数据,只需要一个晶体管和一个电容就能存储,但是因为数据会被存储在电容里,电容会不断漏电,所以需要「定时刷新」电容,才能保证数据不会被丢失,这就是 DRAM 之所以被称为「动态」存储器的原因,只有不断刷新,数据才能被存储起来。
DRAM 的数据访问电路和刷新电路都比 SRAM 更复杂,所以访问的速度会更慢,内存速度大概在 200~300 个 时钟周期之间。
SSD/HDD 硬盘
SSD(Solid-state disk) 就是我们常说的固体硬盘,结构和内存类似,但是它相比内存的优点是断电后数据还是存在的,而内存、寄存器、高速缓存断电后数据都会丢失。内存的读写速度比 SSD 大概快 10~1000 倍。
当然,还有一款传统的硬盘,也就是机械硬盘(Hard Disk Drive, HDD),它是通过物理读写的方式来访问数据的,因此它访问速度是非常慢的,它的速度比内存慢 10W 倍左右。
由于 SSD 的价格快接近机械硬盘了,因此机械硬盘已经逐渐被 SSD 替代了。
存储器的层次关系
现代的一台计算机,都用上了 CPU Cahce、内存、到 SSD 或 HDD 硬盘这些存储器设备了。
其中,存储空间越大的存储器设备,其访问速度越慢,所需成本也相对越少。
CPU 并不会直接和每一种存储器设备直接打交道,而是每一种存储器设备只和它相邻的存储器设备打交道。
比如,CPU Cache 的数据是从内存加载过来的,写回数据的时候也只写回到内存,CPU Cache 不会直接把数据写到硬盘,也不会直接从硬盘加载数据,而是先加载到内存,再从内存加载到 CPU Cache 中。

所以,每个存储器只和相邻的一层存储器设备打交道,并且存储设备为了追求更快的速度,所需的材料成本必然也是更高,也正因为成本太高,所以 CPU 内部的寄存器、L1\L2\L3 Cache 只好用较小的容量,相反内存、硬盘则可用更大的容量,这就我们今天所说的存储器层次结构。
另外,当 CPU 需要访问内存中某个数据的时候,如果寄存器有这个数据,CPU 就直接从寄存器取数据即可,如果寄存器没有这个数据,CPU 就会查询 L1 高速缓存,如果 L1 没有,则查询 L2 高速缓存,L2 还是没有的话就查询 L3 高速缓存,L3 依然没有的话,才去内存中取数据。
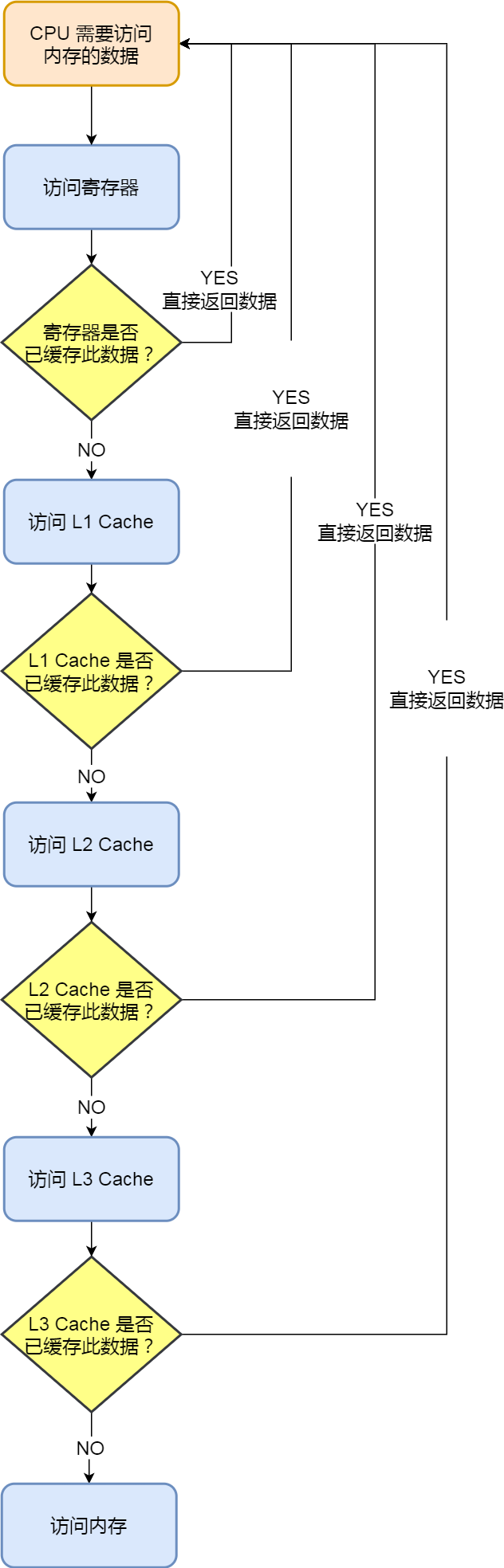
所以,存储层次结构也形成了缓存的体系。
存储器之间的实际价格和性能差距
前面我们知道了,速度越快的存储器,造价成本往往也越高,那我们就以实际的数据来看看,不同层级的存储器之间的性能和价格差异。
下面这张表格是不同层级的存储器之间的成本对比图:
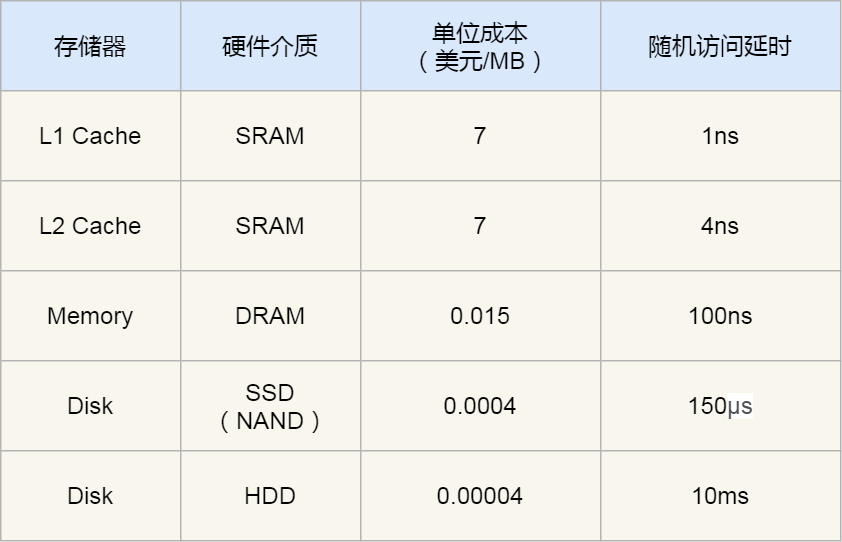
你可以看到 L1 Cache 的访问延时是 1 纳秒,而内存已经是 100 纳秒了,相比 L1 Cache 速度慢了 100 倍。另外,机械硬盘的访问延时更是高达 10 毫秒,相比 L1 Cache 速度慢了 10000000 倍,差了好几个数量级别。
在价格上,每生成 MB 大小的 L1 Cache 相比内存贵了 466 倍,相比机械硬盘那更是贵了 175000 倍。
我在某东逛了下各个存储器设备的零售价,8G 内存 + 1T 机械硬盘 + 256G 固态硬盘的总价格,都不及一块 Intle i5-10400 的 CPU 的价格,这款 CPU 的高速缓存的总大小也就十多 MB。
总结
各种存储器之间的关系,可以用我们在图书馆学习这个场景来理解。
CPU 可以比喻成我们的大脑,我们当前正在思考和处理的知识的过程,就好比 CPU 中的寄存器处理数据的过程,速度极快,但是容量很小。而 CPU 中的 L1-L3 Cache 好比我们大脑中的短期记忆和长期记忆,需要小小花费点时间来调取数据并处理。
我们面前的桌子就相当于内存,能放下更多的书(数据),但是找起来和看起来就要花费一些时间,相比 CPU Cache 慢不少。而图书馆的书架相当于硬盘,能放下比内存更多的数据,但找起来就更费时间了,可以说是最慢的存储器设备了。
从 寄存器、CPU Cache,到内存、硬盘,这样一层层下来的存储器,访问速度越来越慢,存储容量越来越大,价格也越来越便宜,而且每个存储器只和相邻的一层存储器设备打交道,于是这样就形成了存储器的层次结构。
再来回答,开头的问题:那机械硬盘、固态硬盘、内存这三个存储器,到底和 CPU L1 Cache 相比速度差多少倍呢?
CPU L1 Cache 随机访问延时是 1 纳秒,内存则是 100 纳秒,所以 CPU L1 Cache 比内存快 100 倍左右。
SSD 随机访问延时是 150 微妙,所以 CPU L1 Cache 比 SSD 快 150000 倍左右。
最慢的机械硬盘随机访问延时已经高达 10 毫秒,我们来看看机械硬盘到底有多「龟速」:
- SSD 比机械硬盘快 70 倍左右;
- 内存比机械硬盘快 100000 倍左右;
- CPU L1 Cache 比机械硬盘快 10000000 倍左右;
我们把上述的时间比例差异放大后,就能非常直观感受到它们的性能差异了。如果 CPU 访问 L1 Cache 的缓存时间是 1 秒,那访问内存则需要大约 2 分钟,随机访问 SSD 里的数据则需要 1.7 天,访问机械硬盘那更久,长达近 4 个月。
可以发现,不同的存储器之间性能差距很大,构造存储器分级很有意义,分级的目的是要构造缓存体系。
絮叨
大家好,我是小林,一个专为大家图解的工具人,欢迎微信搜索「小林coding」,关注公众号,这里有好多图解等着你呢!
另外,如果觉得文章对你有帮助,欢迎分享给你的朋友,也给小林点个「点和收藏」,这对小林非常重要,谢谢你们,给各位小姐姐小哥哥们抱拳了,我们下次见!*

推荐阅读
天啦噜!知道硬盘很慢,但没想到比 CPU L1 Cache 慢 10000000 倍的更多相关文章
- 【原创】这道Java基础题真的有坑!我也没想到还有续集。
前情回顾 自从我上次发了<这道Java基础题真的有坑!我求求你,认真思考后再回答.>这篇文章后.我通过这样的一个行文结构: 解析了小马哥出的这道题,让大家明白了这题的坑在哪里,这题背后隐藏 ...
- 杀死众筹的N种方法:没想到山寨大军也参与了
众筹作为当下创业者筹集资金,将创意变为现实的最重要手段之一,正面临着越来越多的困难,甚至衍生出杀死众筹的N种方法.甚至这些方法还分为了两类,就众筹本身看,杀死它们的主要方法是:创业者卷钱跑路. ...
- 没想到 Google 排名第一的编程语言,为什么会这么火?
没想到吧,Python 又拿第一了! 在 Google 公布的编程语言流行指数中,Python 依旧是全球范围内最受欢迎的技术语言! 01 为什么 Python 会这么火? 核心还是因为企业需要用 ...
- 万万没想到!ModelArts与AppCube组CP了
摘要:嘘,华为云内部都不知道的秘密玩法,我悄悄告诉您! 双"魔"合璧庆双节 ↑开局一张图,故事全靠编 华为云的一站式开发平台ModelArts和应用魔方AppCube居然能玩到一起 ...
- 没想到吧!这个可可爱爱的游戏居然是用 ECharts 实现的!
摘要:echarts 是一个很强大的图表库,除了我们常见的图表功能,还可以自定义图形,这个功能让我们可以很简单地在画布上绘制一些非常规的图形,基于此,我们来玩一些花哨的:做一个 Flappy Bird ...
- 在做关于NIO TCP编程小案例时遇到无法监听write的问题,没想到只是我的if语句的位置放错了位置,哎,看了半天没看出来
在做关于NIO TCP编程小案例时遇到无法监听write的问题,没想到只是我的if语句的位置放错了位置,哎,看了半天没看出来 贴下课堂笔记: 在Java中使用NIO进行网络TCP套接字编程主要以下几个 ...
- centos clamav杀毒软件安装配置及查杀,没想到linux下病毒比windows还多!
centos clamav杀毒软件安装配置及查杀,没想到linux下病毒比windows还多! 一.手动安装 1.下载(官网) cd /soft wget http://www.clam ...
- 头条编程题 万万没想到之抓捕孔连顺 JavaScript
[编程题] 万万没想到之抓捕孔连顺 时间限制:1秒 空间限制:131072K 我叫王大锤,是一名特工.我刚刚接到任务:在字节跳动大街进行埋伏,抓捕恐怖分子孔连顺.和我一起行动的还有另外两名特工,我提议 ...
- 字节跳动:[编程题]万万没想到之聪明的编辑 Java
时间限制:1秒 空间限制:32768K 我叫王大锤,是一家出版社的编辑.我负责校对投稿来的英文稿件,这份工作非常烦人,因为每天都要去修正无数的拼写错误.但是,优秀的人总能在平凡的工作中发现真理.我发现 ...
随机推荐
- 14_Python语法示例(面向对象)
1.自己写一个Student类,此类的对象有属性name, age, score, 用来保存学生的姓名,年龄,成绩 # 1)写一个函数input_student读入n个学生的信息,用对象来存储这些信息 ...
- Solon详解(三)- Solon的web开发
Solon详解系列文章: Solon详解(一)- 快速入门 Solon详解(二)- Solon的核心 Solon详解(三)- Solon的web开发 Solon详解(四)- Solon的事务传播机制 ...
- [Oracle/SQL]找出id为0的科目考试成绩及格的学生名单的四种等效SQL语句
本文是受网文 <一次非常有意思的SQL优化经历:从30248.271s到0.001s>启发而产生的. 网文没讲创建表的数据过程,我帮他给出. 创建科目表及数据: CREATE TABLE ...
- Zookeeper启动流程分析
前言 之前的Zookeeper协议篇-Paxos算法与ZAB协议通过了解Paoxs算法开始,到Zab协议的两大特性:崩溃恢复和消息广播,学习了Zookeeper是如何通过Zab协议实现高可用,本篇主要 ...
- AD16
第三集 制作光敏小夜灯的原理图 1.点击G切换栅格的精度 2.元器件放置好之后要先布局在布线 3.布线完成后要检查电路的合理性.对应查一下电阻的个数,位置是不是符合.在原理上大概的估计是否可以. ...
- .net MVC4.0项目发布到阿里云虚拟主机中遇到的问题。
正所谓学以致用,今天本来想做个bootstrap的demo发到服务器上看一下效果,结果服务器搞了半天,最终太晚了没能学到什么东西. 首先写好页面之后我做了一个MVC4.0的网站项目,然后把Bootst ...
- js中的选择排序和冒泡排序
var arr = [12,25,8,16,14]; console.log("排序前数组,",arr) //选择排序:第一轮,找出数组中最小的数,将第一项和最小的数互换位置.第二 ...
- day53:django:URL别名/反向解析&URL分发&命名空间&ORM多表操作修改/查询
目录 1.URL别名&反向解析 2.URL分发&命名空间 3.ORM多表操作-修改 4.ORM多表操作-查询 4.1 基于对象的跨表查询 4.2 基于双下划线的跨表查询 4.3 聚合查 ...
- Flutter学习四之实现一个支持刷新加载的列表
上一篇文章用Scaffold widget搭建了一个带底部导航栏的的项目架构,这篇文章就来介绍一下在flutter中怎么实现一个带下拉刷新和上拉加载更多的一个列表,这里用到了pull_to_refre ...
- kafka学习(二)kafka工作流程分析
一.发送数据 follower的同步流程 PS:Producer在写入数据的时候永远的找leader,不会直接将数据写入follower PS:消息写入leader后,follower是主动的去lea ...