ElasticSearch 集群 & 数据备份 & 优化
ElasticSearch 集群相关概念
ES 集群颜色状态
①. — 红色:数据都不完整
②. — 黄色:数据完整,但是副本有问题
③. — 绿色:数据和副本全都没有问题
ES 集群节点类型
①. — 主节点:负责调度分配数据
②. — 数据节点:处理分配到自己的数据
ES 集群分片类型
①. — 主分片:存储数据,负责读写数据
②. — 副本分片:主分片的备份
ES 集群安全保障
①. — 数据会自动分配到多个节点
②. — 如果主分片所在节点挂掉,副本节点的分片会自动升为主分片
③. — 如果主节点挂了,数据节点会自动提升为主节点
ES 集群配置注意事项
①. — 集群节点的配置,不需要将所有节点的 IP 都写入配置文件,只需要写本机 IP 和集群中任意一台机器的 IP 即可:
# 修改 /etc/elasticsearch/elasticsearch.yml 配置文件
122 配置: discovery.zen.ping.unicast.hosts: ["10.0.0.121", "10.0.0.122"]
123 配置: discovery.zen.ping.unicast.hosts: ["10.0.0.121", "10.0.0.123"]
xxx 配置: discovery.zen.ping.unicast.hosts: ["10.0.0.121", "10.0.0.xxx"]
②. — 集群选举节点配置数量,一定是 N(集群节点总数)/2+1:
# 修改 /etc/elasticsearch/elasticsearch.yml 配置文件,当前集群节点总数 N = 3
discovery.zen.minimum_master_nodes: 2
③. — ES 默认 5 个分片 1 个副本,索引创建以后,分片数量不得修改,副本数可以修改
④. — 数据分配时,分片颜色:
1)紫色:数据正在迁移(扩展节点时会遇到)

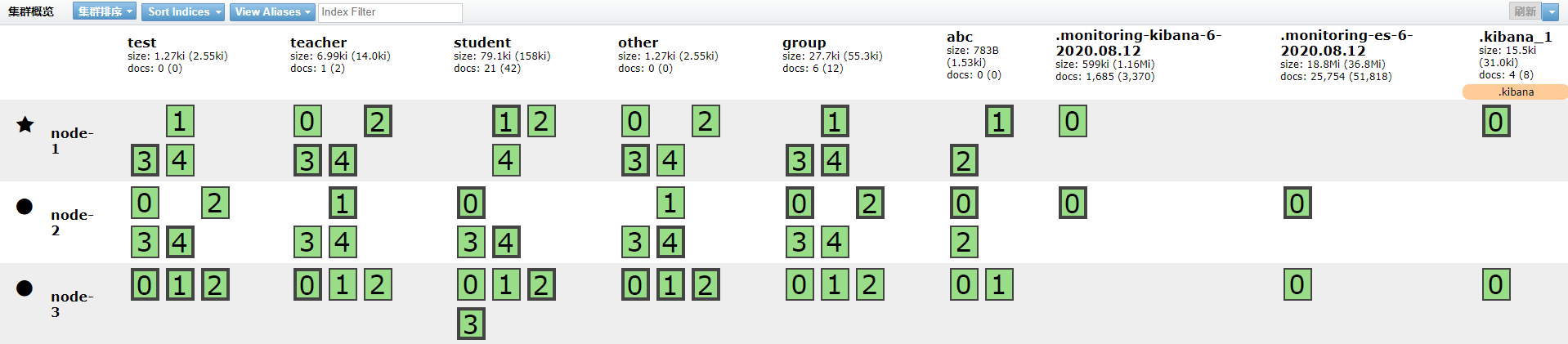
2)黄色:数据正在复制(节点宕机,其他节点需要补全分片副本)
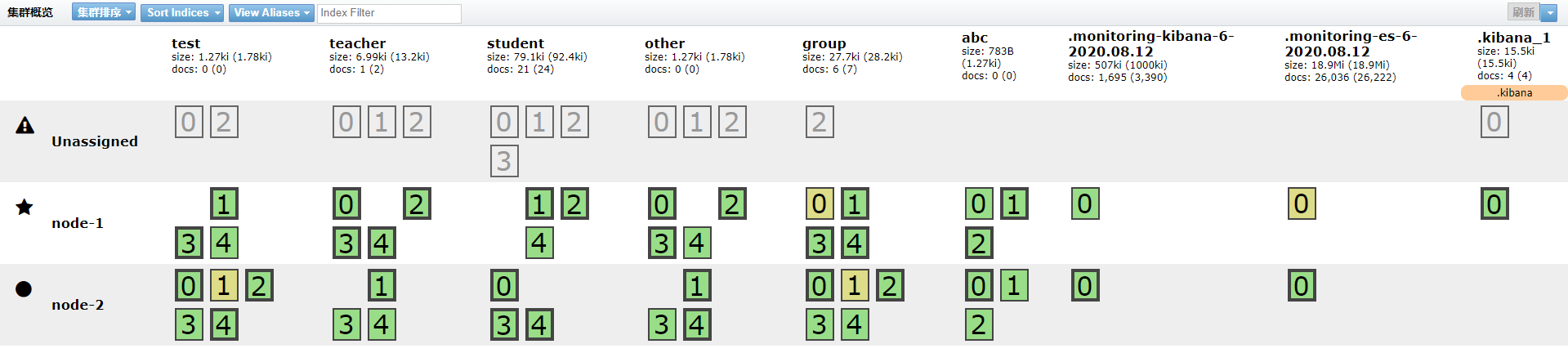
⑤. — 当集群共有三个节点时,根据配置的分片副本数,可发生的故障:
1)三个节点,没有副本时,一台机器都不能坏
2)三个节点,一个副本时,可以坏两台,但是只能一台一台坏(要时间复制生成新的副本)
3)三个节点,两个副本时,可以坏两台(一起坏)
ES 集群相关命令
# ======= ES 集群状态 ======= #
# 1.查看主节点
GET _cat/master
# 2.查看集群健康状态
GET _cat/health
# 3.查看索引
GET _cat/indices
# 4.查看所有节点
GET _cat/nodes
# 5.查看分片
GET _cat/shards
# 一般可以通过以下两个命令监控集群的健康状态,两者有一个发变化,说明集群发生故障
GET _cat/health
GET _cat/nodes
# 实际上 Kibana 会内置 X-Pack 软件,监控集群的健康状态
ElasticSearch 集群配置修改
配置分片数 & 副本数
ES 默认 5 个分片 1 个副本,索引创建以后,分片数量不得修改,副本数可以修改
# ======= 配置文件 ======= #
# 修改 /etc/elasticsearch/elasticsearch.yml 配置参数
# 设置索引的分片数 , 默认为 5
index.number_of_shards: 5
# 设置索引的副本数 , 默认为 1
index.number_of_replicas: 1
修改指定索引副本数
PUT /index/_settings
{
"number_of_replicas": 2
}
修改所有索引副本数
PUT _all/_settings
{
"number_of_replicas": 2
}
创建索引时指定分片数 & 副本数
PUT /testone
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2
}
}
注意,分片数不是越多越好:
①. — 分片数不是越多越好,会占用资源
②. — 每个分片都会占用文件句柄数
③. — 查询数据时会根据算法去指定节点获取数据,分片数越少,查询成本越低
分片数 & 副本数配置建议
①. — 跟开发沟通
②. — 看一共要几个节点
— 如果 2 个节点,默认就可以(1 副本 5 分片)
— 如果 3 个节点,重要的数据,2 副本 5 分片,不重要的数据,1 副本 5 分片
③. — 在开始阶段, 一个好的方案是根据你的节点数量按照 1.5 ~ 3 倍的原则来创建分片
— 例如:如果你有 3 个节点,则推荐你创建的分片数最多不超过 9(3 x 3)个
④. — 存储数据量多的可以设置分片多一些,存储数据量少的,可以少分些分片
ElasticSearch 配置优化
限制内存
1.启动内存最大是 32G
2.服务器一半的内存全都给 ES
3.设置可以先给小一点,慢慢提高
4.内存不足时
1)让开发删除数据
2)加节点
3)提高配置
5.关闭 swap 空间
文件句柄数
# 配置文件描述符
[root@db02 ~]# vim /etc/security/limits.conf
* soft memlock unlimited
* hard memlock unlimited
* soft nofile 131072
* hard nofile 131072
# 普通用户(CentOS7)
[root@db02 ~]# vim /etc/security/limits.d/20-nproc.conf
* soft nproc 65535
root soft nproc unlimited
# 普通用户(CentOS6)
[root@db02 ~]# vim /etc/security/limits.d/90-nproc.conf
* soft nproc 65535
root soft nproc unlimited
语句优化
1.条件查询时,使用term查询,减少range的查询
2.建索引的时候,尽量使用命中率高的词
ElasticSearch 数据备份与恢复
安装 npm 环境
# Linux-nodeJS 安装 V12
# 第一步:配置 yum 源
curl --silent --location https://rpm.nodesource.com/setup_12.x | sudo bash -
# 第二步:安装包
yum install -y nodejs
# 第三步:验证安装是否成功
node -v
# 第四步:设置淘宝镜像
npm config set registry http://registry.npm.taobao.org
安装备份工具
[root@db01 ~]# npm install elasticdump -g
备份命令
# 帮助文档
https://github.com/elasticsearch-dump/elasticsearch-dump
备份参数
--input: 数据来源
--output: 接收数据的目标
--type: 导出的数据类型(settings, analyzer, data, mapping, alias, template)
备份数据类型
①. — settings:指定 index 的配置信息,比如分片数、副本数,tranlog 同步条件、refresh 策略等信息;
②. — mappings:指定 index 的内部构建信息;
③. — templates:索引模板,就是把已经创建好的某个索引的参数设置(settings)和索引映射(mapping)保存下来作为模板,在创建新索引时,指定要使用的模板名,,就可以直接重用已经定义好的模板中的设置和映射;
④. — analyzer:分词器;
⑤. — data:数据;
⑥. — alias:索引别名
备份数据到集群
# 备份数据到另一个 ES 集群
elasticdump \
--input=http://10.0.0.121:9200/my_index \
--output=http://10.0.0.51:9200/my_index \
--type=analyzer
elasticdump \
--input=http://10.0.0.121:9200/my_index \
--output=http://10.0.0.51:9200/my_index \
--type=mapping
elasticdump --input=http://10.0.0.121:9200/my_index --output=http://10.0.0.51:9200/my_index --type=data
elasticdump \
--input=http://10.0.0.121:9200/my_index \
--output=http://10.0.0.51:9200/my_index \
--type=template
备份数据到本地
elasticdump \
--input=http://10.0.0.121:9200/student \
--output=/tmp/student_mapping.json \
--type=mapping
elasticdump \
--input=http://10.0.0.121:9200/student \
--output=/tmp/student_data.json \
--type=data
导出文件打包
elasticdump \
--input=http://production.es.com:9200/my_index \
--output=$ \
| gzip > /data/my_index.json.gz
备份指定条件的数据
elasticdump \
--input=http://production.es.com:9200/my_index \
--output=query.json \
--searchBody="{\"query\":{\"term\":{\"username\": \"admin\"}}}"
导入数据命令
elasticdump \
--input=./student_template.json \
--output=http://10.0.0.121:9200 \
--type=template
elasticdump \
--input=./student_mapping.json \
--output=http://10.0.0.121:9200 \
--type=mapping
elasticdump \
--input=./student_data.json \
--output=http://10.0.0.121:9200 \
--type=data
elasticdump \
--input=./student_analyzer.json \
--output=http://10.0.0.121:9200 \
--type=analyzer
# 恢复数据的时候,如果数据已存在,会覆盖原数据
备份脚本(指定索引)
[root@dbtest03 test]# cat bak.sh
#!/bin/bash
# 备份集群节点 IP
host_ip=10.0.0.121
index_name='
student
teacher
abc
'
for index in `echo $index_name`
do
echo "start input index ${index}"
elasticdump --input=http://${host_ip}:9200/${index} --output=/data/${index}_alias.json --type=alias &> /dev/null
elasticdump --input=http://${host_ip}:9200/${index} --output=/data/${index}_analyzer.json --type=analyzer &> /dev/null
elasticdump --input=http://${host_ip}:9200/${index} --output=/data/${index}_data.json --type=data &> /dev/null
elasticdump --input=http://${host_ip}:9200/${index} --output=/data/${index}_alias.json --type=alias &> /dev/null
elasticdump --input=http://${host_ip}:9200/${index} --output=/data/${index}_template.json --type=template &> /dev/null
done
导入脚本(指定索引)
[root@dbtest03 test]# cat imp.sh
#!/bin/bash
# 导入集群节点 IP
host_ip=10.0.0.121
index_name='
abc
student
'
for index in `echo $index_name`
do
echo "start input index ${index}"
elasticdump --input=/data/${index}_alias.json --output=http://${host_ip}:9200/${index} --type=alias &> /dev/null
elasticdump --input=/data/${index}_analyzer.json --output=http://${host_ip}:9200/${index} --type=analyzer &> /dev/null
elasticdump --input=/data/${index}_data.json --output=http://${host_ip}:9200/${index} --type=data &> /dev/null
elasticdump --input=/data/${index}_template.json --output=http://${host_ip}:9200/${index} --type=template &> /dev/null
done
备份脚本(全部索引)
[root@dbtest03 test]# cat back.sh
ES=http://10.0.0.121:9200
ED=/data
mkdir /data -p
for index in `curl -s -XGET $ES/_cat/indices?h=i`
do
# settings, analyzer, data, mapping, alias, template
echo "elasticdump --input=$ES/$index --output=$ED/$index"
elasticdump --input=$ES/$index --output=${ED}/${index}_setting.json --limit=10000 --type=settings --searchBody '{"query": { "match_all": {} }, "stored_fields": ["*"], "_source": true }'
elasticdump --input=$ES/$index --output=${ED}/${index}_analyzer.json --limit=10000 --type=analyzer --searchBody '{"query": { "match_all": {} }, "stored_fields": ["*"], "_source": true }'
elasticdump --input=$ES/$index --output=${ED}/${index}_alias.json --limit=10000 --type=alias --searchBody '{"query": { "match_all": {} }, "stored_fields": ["*"], "_source": true }'
elasticdump --input=$ES/$index --output=${ED}/${index}_template.json --limit=10000 --type=template --searchBody '{"query": { "match_all": {} }, "stored_fields": ["*"], "_source": true }'
elasticdump --input=$ES/$index --output=${ED}/${index}_mapping.json --limit=10000 --type=mapping --searchBody '{"query": { "match_all": {} }, "stored_fields": ["*"], "_source": true }'
elasticdump --input=$ES/$index --output=${ED}/${index}_data.json --limit=10000 --type=data --searchBody '{"query": { "match_all": {} }, "stored_fields": ["*"], "_source": true }'
echo ""
done
迁移数据(全部索引)
# 源 ES 集群地址
ES=http://search-es-0.search-es.app.svc.cluster.local:9200
# 目标 ES 集群地址
ED=http://es-0.es.infra.svc.cluster.local:9200
for index in `curl -s -XGET $ES/_cat/indices?h=i`
do
# settings, analyzer, data, mapping, alias, template
echo "elasticdump --input=$ES/$index --output=$ED/$index"
elasticdump --input=$ES/$index --output=$ED/$index --limit=10000 --type=settings --searchBody '{"query": { "match_all": {} }, "stored_fields": ["*"], "_source": true }'
elasticdump --input=$ES/$index --output=$ED/$index --limit=10000 --type=analyzer --searchBody '{"query": { "match_all": {} }, "stored_fields": ["*"], "_source": true }'
elasticdump --input=$ES/$index --output=$ED/$index --limit=10000 --type=alias --searchBody '{"query": { "match_all": {} }, "stored_fields": ["*"], "_source": true }'
elasticdump --input=$ES/$index --output=$ED/$index --limit=10000 --type=template --searchBody '{"query": { "match_all": {} }, "stored_fields": ["*"], "_source": true }'
elasticdump --input=$ES/$index --output=$ED/$index --limit=10000 --type=mapping --searchBody '{"query": { "match_all": {} }, "stored_fields": ["*"], "_source": true }'
elasticdump --input=$ES/$index --output=$ED/$index --limit=10000 --type=data --searchBody '{"query": { "match_all": {} }, "stored_fields": ["*"], "_source": true }'
echo ""
done
中文分词器
https://github.com/medcl/elasticsearch-analysis-ik/
插入测试数据
POST /index/text/1
{"content":"美国留给伊拉克的是个烂摊子吗"}
POST /index/text/2
{"content":"公安部:各地校车将享最高路权"}
POST /index/text/3
{"content":"中韩渔警冲突调查:韩警平均每天扣1艘中国渔船"}
POST /index/text/4
{"content":"中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"}
检测数据
POST /index/_search
{
"query" : { "match" : { "content" : "中国" }},
"highlight" : {
"pre_tags" : ["<tag1>", "<tag2>"],
"post_tags" : ["</tag1>", "</tag2>"],
"fields" : {
"content" : {}
}
}
}
配置中文分词器
安装插件
# 快速安装,所有节点全部安装
[root@db01 ~]# /usr/share/elasticsearch/bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.6.0/elasticsearch-analysis-ik-6.6.0.zip
# 手动安装方式
mkdir /usr/share/elasticsearch/plugins/ik
unzip -q elasticsearch-analysis-ik-6.6.0.zip -d /usr/share/elasticsearch/plugins/ik
vim /etc/elasticsearch/jvm.options
-Djava.security.policy=/usr/share/elasticsearch/plugins/ik/plugin-security.policy
systemctl restart elasticsearch.service
创建一个索引
PUT /news
添加 mapping
curl -XPOST http://localhost:9200/news/text/_mapping -H 'Content-Type:application/json' -d'
{
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}
添加我们指定中文词语
[root@redis01 ~]# vim /etc/elasticsearch/analysis-ik/IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">/etc/elasticsearch/analysis-ik/my.dic</entry>
[root@redis01 ~]# vim /etc/elasticsearch/analysis-ik/my.dic
中国
[root@redis01 ~]# chown -R elasticsearch.elasticsearch /etc/elasticsearch/analysis-ik/my.dic
重新插入数据
POST /news/text/1
{"content":"美国留给伊拉克的是个烂摊子吗"}
POST /news/text/2
{"content":"公安部:各地校车将享最高路权"}
POST /news/text/3
{"content":"中韩渔警冲突调查:韩警平均每天扣1艘中国渔船"}
POST /news/text/4
{"content":"中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"}
再次检测
POST /news/_search
{
"query" : { "match" : { "content" : "中国" }},
"highlight" : {
"pre_tags" : ["<tag1>", "<tag2>"],
"post_tags" : ["</tag1>", "</tag2>"],
"fields" : {
"content" : {}
}
}
}
ElasticSearch 集群 & 数据备份 & 优化的更多相关文章
- elasticsearch集群介绍及优化【转】
elasticsearch用于构建高可用和可扩展的系统.扩展的方式可以是购买更好的服务器(纵向扩展)或者购买更多的服务器(横向扩展),Elasticsearch能从更强大的硬件中获得更好的性能,但是纵 ...
- redis集群数据迁移
redis集群数据备份迁移方案 n 迁移环境描述及分析 当前我们面临的数据迁移环境是:集群->集群. 源集群: 源集群为6节点,3主3备 主 备 192.168.112.33:8001 192 ...
- 腾讯云Elasticsearch集群规划及性能优化实践
一.引言 随着腾讯云 Elasticsearch 云产品功能越来越丰富,ES 用户越来越多,云上的集群规模也越来越大.我们在日常运维工作中也经常会遇到一些由于前期集群规划不到位,导致后期业务增长集群 ...
- Elasticsearch 集群优化-尽可能全面详细
Elasticsearch 集群优化-转载参考1 基本配置 基本配置,5台配置为 24C 125G 17T 的主机,每台主机上搭建了一个elasticsearch节点. 采用的elasticsearc ...
- Elasticsearch(二)--集群原理及优化
一.ES原理 1.索引结构ES是面向文档的 各种文本内容以文档的形式存储到ES中,文档可以是一封邮件.一条日志,或者一个网页的内容.一般使用 JSON 作为文档的序列化格式,文档可以有很多字段,在创建 ...
- 我的ElasticSearch集群部署总结--大数据搜索引擎你不得不知
摘要:世上有三类书籍:1.介绍知识,2.阐述理论,3.工具书:世间也存在两类知识:1.技术,2.思想.以下是我在部署ElasticSearch集群时的经验总结,它们大体属于第一类知识“techknow ...
- Elasticsearch集群搭建及使用Java客户端对数据存储和查询
本次博文发两块,前部分是怎样搭建一个Elastic集群,后半部分是基于Java对数据进行写入和聚合统计. 一.Elastic集群搭建 1. 环境准备. 该集群环境基于VMware虚拟机.CentOS ...
- mongodump备份小量分片集群数据
1.使用mongodump备份小量分片集群数据 如果一个分片集群的数据集比较小,可以直接使用mongodump连接到mongos实例进行数据备份.默认情况下,mongodump到非primary的节点 ...
- Elasticsearch多集群数据同步
有时多个Elasticsearch集群避免不了要同步数据,网上查找了下数据同步工具还挺多,比较常用的有:elasticserach-dump.elasticsearch-exporter.logsta ...
随机推荐
- 最新详解android自动化无障碍服务accessibilityservice以及高版本问题_1_如何开启获得无障碍
前言 无障碍服务accessibilityservice是什么 简单来说 无障碍服务就是一个为残障人士 尤其是视觉障碍人士提供的一个帮助服务.具体就是可以识别控件 文字 可以配合语音助手 操作和 使用 ...
- pandas 写csv 操作
pandas 写csv 操作 def show_history(self): df = pd.DataFrame() df['Time'] = pd.Series(self.time_hist) df ...
- 关于请求接口报4XX错误,给广大前端同胞进行伸冤澄清,请相信它不一定都是前端的错
关于请求接口报4XX错误,给广大前端同胞进行伸冤澄清,请相信它不一定都是前端的错 首先确保接口没有写错,参数按照后台要的写,确保自己也没有写错,若页面还是报4xx错误,请站出来大胆的质疑后端,干什么吃 ...
- 入门OJ:八中生成树2
题目描述 八中里面有N个建设物,M条边.对于这种要建最小生成树的问题,你应该很熟练了.现在老大决定降低某条边的费用,然后这条边必须要被选中,因为这条路他每天都要走,自然......问选了这条边后是否可 ...
- 集成 12 种协议、可于 USBC 端口的快充协议芯片IP2188
1. 特性 支持 12 种 USB 端口快充协议 支持 USB TypeC PD2.0/PD3.0/PPS DFP 协议 支持多种充电协议(QC3.0/QC2.0,FCP,SCP, AFC,MT ...
- 生僻标签 fieldset 与 legend 的妙用
谈到 <fieldset> 与 <legend>,大部分人肯定会比较陌生,在 HTML 标签中,属于比较少用的那一批. 我最早知道这两个标签,是在早年学习 reset.css ...
- 容器化安装Mysql 8.0 并部署主从复制
系统: Centos 7.4 数据库版本:8.0.20 两台机器做相同操作 安装Docker export VERSION=18.06 && curl -fsSL http://rai ...
- VGA调试心得
以前自己调试过视频信号,无非就时钟加行场同步加数据线,如果视频信号出问题,第一看现象,第二测频率,反正出问题不是消隐信号出问题,就是时钟频率出问题.通过这种方式也调试成功过几个显示屏,然后就以为自己对 ...
- Ubuntu 能ping通DNS 地址 无法解析域名
ping通qq百度都行,唯独谷歌不行, 主机能够ping通google的dns服务器地址 8.8.8.8,却无法解析域名 $ ping www.google.co.uk ping: unknown ...
- Redis 底层数据结构设计
10万+QPS 真的只是因为单线程和基于内存?_Howinfun的博客-CSDN博客_qps面试题 https://blog.csdn.net/Howinfun/article/details/105 ...