Redis 集合统计(HyperLogLog)
统计功能是一类极为常见的需求,比如下面这个场景:
简单来说就是统计一天内,某个页面的访问用户量,如果相同的用户再次访问,也只算记为一次访问。
下面我们将从这个场景出发,讨论如何选择的合适的 Redis 数据结构实现统计功能。
Redis与统计
聚合统计
要完成这个统计任务,最直观的方式是使用一个SET保存页面在某天的访问用户 ID,然后通过对集合求差SDIFF和求交SINTER完成统计:
# 2020-01-01 当日的 UV
SADD page:uv:20200101 "Alice" "Bob" "Tom" "Jerry"
# 2020-01-02 当日的 UV
SADD page:uv:20200102 "Alice" "Bob" "Jerry" "Nancy"
# 2020-01-02 新增用户
SDIFFSTORE page:new:20200102 page:uv:20200102 page:uv:20200101
# 2020-01-02 新增用户数量
SCARD page:new:20200102
# 2020-01-02 留存用户
SINTERSTORE page:rem:20200102 page:uv:20200102 page:uv:20200101
# 2020-01-02 留存用户数量
SCARD page:rem:20200102
优点:
- 操作直观易理解,可以复用现有的数据集合
- 保留了用户的访问细节,可以做更细粒度的统计
缺点:
- 内存开销大,假设每个用户ID长度均小于 44 字节(使用 embstr 编码),记录 1 亿用户也至少需要 6G 的内存
SUNION、SINTER、SDIFF计算复杂度高,大数据量情况下会导致 Redis 实例阻塞,可选的优化方式有:- 从集群中选择一个从库专门负责聚合计算
- 把数据读取到客户端,在客户端来完成聚合统计
二值统计
当用户 ID 是连续的整数时,可以使用BITMAP实现二值统计:
# 2020-01-01 当日的 UV
SETBIT page:uv:20200101 0 1 # "Alice"
SETBIT page:uv:20200101 1 1 # "Bob"
SETBIT page:uv:20200101 2 1 # "Tom"
SETBIT page:uv:20200101 3 1 # "Jerry"
# 2020-01-02 当日的 UV
SETBIT page:uv:20200102 0 1 # "Alice"
SETBIT page:uv:20200102 1 1 # "Bob"
SETBIT page:uv:20200102 3 1 # "Jerry"
SETBIT page:uv:20200102 4 1 # "Nancy"
# 2020-01-02 新增用户
BITOP NOT page:not:20200101 page:uv:20200101
BITOP AND page:new:20200102 page:uv:20200102 page:not:20200101
# 2020-01-02 新增用户数量
BITCOUNT page:new:20200102
# 2020-01-02 留存用户
BITOP AND page:rem:20200102 page:uv:20200102 page:uv:20200101
# 2020-01-02 留存用户数量
BITCOUNT page:new:20200102
优点:
- 内存开销低,记录 1 亿个用户只需要 12MB 内存
- 统计速度快,计算机对比特位的异或运算十分高效
缺点:
- 对数据类型有要求,只能处理整数集合
基数统计
前面两种方式都能提供准确的统计结果,但是也存在以下问题:
- 当统计集合变大时,所需的存储内存也会线性增长
- 当集合变大时,判断其是否包含新加入元素的成本变大
考虑下面这一场景:
只统计一个集合中不重复的元素个数,而并不关心集合元素内容的统计方式,我们将其称为基数计数
cardinality counting
针对这一特定的统计场景,Redis 提供了HyperLogLog类型支持基数统计:
# 2020-01-01 当日的 UV
PFADD page:uv:20200101 "Alice" "Bob" "Tom" "Jerry"
PFCOUNT page:uv:20200101
# 2020-01-02 当日的 UV
PFADD page:uv:20200102 "Alice" "Bob" "Tom" "Jerry" "Nancy"
PFCOUNT page:uv:20200102
# 2020-01-01 与 2020-01-02 的 UV 总和
PFMERGE page:uv:union page:uv:20200101 page:uv:20200102
PFCOUNT page:uv:union
优点:
HyperLogLog计算基数所需的空间是固定的。只需要 12KB 内存就可以计算接近 \(2^{64}\) 个元素的基数。
缺点:
HyperLogLog的统计是基于概率完成的,其统计结果是有一定误差。不适用于精确统计的场景。
HyperLogLog 解析
概率估计
HyperLogLog是一种基于概率的统计方式,该如何理解?
我们来做一个实验:不停地抛一个均匀的双面硬币,直到结果是正面为止。
用 0 和 1 分别表示正面与反面,则实验结果可以表示为如下二进制串:
+-+
第 1 次抛到正面 |1|
+-+
+--+
第 2 次抛到正面 |01|
+--+
+---+
第 3 次抛到正面 |001|
+---+
+---------+
第 k 次抛到正面 |000...001| (总共 k-1 个 0)
+---------+
进行 n 实验后,将每次实验抛硬币的次数记为 \(k_1, k_3,\cdots,k_n\),其中的最大值记为 \(k_{max}\)。
理想情况下有 \(k_{max} = log_2(n)\),反过来也可以通过 \(k_{max}\) 来估计总的实验次数 \(n = 2^{k_{max}}\)。
处理极端情况
实际进行实验时,极端情况总会出现,比如在第 1 次实验时就连续抛出了 10 次反面。
如果按照前面的公式进行估计,会认为已经进行了 1000 次实验,这显然与事实不符。
为了提高估计的准确性,可以同时使用 m 枚硬币进行 分组实验。
然后计算这 m 组实验的平均值 \(\hat{k}_{max} = \frac{\sum_{i=0}^{m}{k_{max}}}{m}\),此时能更准确的估计实际的实验次数 \(\hat{n}=2^{\hat{k}_{max}}\)。
基数统计
通过前面的分析,我们可以总结出以下经验:
可以通过二进制串中首个 1 出现的位置 \(k_{max}\) 来估计实际实验发生的次数 \(n\)
HyperLogLog借鉴上述思想来统计集合中不重复元素的个数:
- 使用 hash 函数集合中的每个元素映射为定长二进制串
- 利用 分组统计 的方式提高准确性,将二进制串分到 \(m\) 个不同的桶
bucket中分别统计- 二进制串的前 \(log_2{m}\) 位用于计算该元素所属的桶
- 剩余二进制位中,首个 1 出现的比特位记为 \(k\),每个桶中的只保存最大值 \(k_{max}\)
- 当需要估计集合中包含的元素个数时,使用公式 \(\hat{n}=2^{\hat{k}_{max}}\) 计算即可
下面来看一个例子:
HyperLogLog实现,使用8bit 输出的 hash 函数并以 4 个桶进行分组统计使用该 HLL 统计 Alice,Bob,Tom,Jerry,Nancy 这 5 个用户访问页后的 UV
映射为二进制串 分组 计算k
| | |
V V V
+---------+
hash("Alice") => |01|101000| => bucket=1, k=1
+---------+ 分组统计 k_max
+---------+
hash("Bob") => |11|010010| => bucket=3, k=2 +----------+----------+----------+----------+
+---------+ | bucket_0 | bucket_1 | bucket_2 | bucket_3 |
+---------+ ==> +----------+----------+----------+----------+
hash("Tom") => |10|001000| => bucket=2, k=3 | k_max= 1 | k_max= 2 | k_max= 3 | k_max= 2 |
+---------+ +----------+----------+----------+----------+
+---------+
hash("Jerry") => |00|111010| => bucket=0, k=1
+---------+
+---------+
hash("Nancy") => |01|010001| => bucket=1, k=2
+---------+
分组计数完成后,用之前的公式估计集合基数为 \(2^{\hat{k}_{max}}= 2^{(\frac{1+2+3+2}{4})} = 4\)。
误差分析
在 Redis 的实现中,对于一个输入的字符串,首先得到 64 位的 hash 值:
- 前 14 位来定位桶的位置(共有16384个桶)
- 后 50 位用作元素对应的二进制串(用于更新首次出现 1 的比特位的最大值 \(k_{max}\))
由于使用了 64 位输出的 hash 函数,因此可以计数的集合的基数没有实际限制。
HyperLogLog的标准误差计算公式为 \(\frac{1.04}{\sqrt{m}}\)(\(m\) 为分组数量),据此计算 Redis 实现的标准误差为 \(0.81\%\)。
下面这幅图展示了统计误差与基数大小的关系:
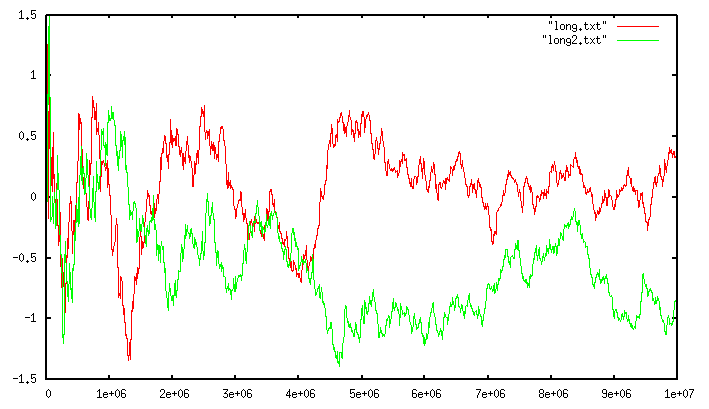
- 红线和绿线分别代表两个不同分布的数据集
- x 轴表示集合实际基数
- y 轴表示相对误差(百分比)
分析该图可以得出以下结论:
- 统计误差与数据本身的分布特征无关
- 集合基数越小,误差越小(小基数时精度高)
- 集合基数越大,误差越大(大基数时省资源)
参考资料
Redis 集合统计(HyperLogLog)的更多相关文章
- 初识Redis的数据类型HyperLogLog
前提 未来一段时间开发的项目或者需求会大量使用到Redis,趁着这段时间业务并不太繁忙,抽点时间预习和复习Redis的相关内容.刚好看到博客下面的UV和PV统计,想到了最近看书里面提到的HyperLo ...
- Redis集合的常用操作指令
Redis集合的常用操作指令 Sets常用操作指令 SADD 将指定的元素添加到集合.如果集合中存在该元素,则忽略. 如果集合不存在,会先创建一个集合然后在添加元素. 127.0.0.1:6379&g ...
- Redis 集合(Set)
Redis的Set是string类型的无序集合.集合成员是唯一的,这就意味着集合中不能出现重复的数据. Redis 中 集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1). 集合中最 ...
- 14. Redis配置统计字典
14. Redis配置统计字典14.1 info系统状态说明14.1.1 命令说明14.1.2 详细说明14.2 standalone配置说明和分析14.2.1 总体配置14.2.2 最大内存及策略1 ...
- redis(十二):Redis 集合(Set)
Redis 集合(Set) Redis 的 Set 是 String 类型的无序集合.集合成员是唯一的,这就意味着集合中不能出现重复的数据. Redis 中集合是通过哈希表实现的,所以添加,删除,查找 ...
- Redis配置统计字典
本章将对Redis的系统状态信息(info命令结果)和Redis的所有配置(包括Standalone.Sentinel.Cluster三种模式)做一个全面的梳理,希望本章能够成为Redis配置统计字典 ...
- Redis集合解决大数据筛选
Redis集合:集合是什么,就是一堆确定的数据放在一起,数学上集合有交集.并集的概念,这个就可以用来做大数据的筛选功能. 以商品为例,假如商品有颜色和分类.价格区间等属性. 给所有统一颜色的商品放一个 ...
- redis常用数据类型 HyperLoglog
1.HyperLoglog简介 HyperLoglog是redis新支持的两种类型中的另外一种(上一种是位图类型Bitmaps).主要适用场景是海量数据的计算.特点是速度快.占用空间小. 同样是用于计 ...
- 给你一个亿的keys,Redis如何统计?
前言 不知你大规模的用过Redis吗?还是仅仅作为缓存的工具了?在Redis中使用最多的就是集合了,举个例子,如下场景: 签到系统中,一天对应一系列的用户签到记录. 电商系统中,一个商品对应一系列的评 ...
随机推荐
- 1.5V转5V的最少电路的芯片电路图
PW5100满足1.5V转5V的很简洁芯片电路,同时达到了最少的元件即可组成DC-DC电路1.5V转5V的升压转换器系统. PW5100在1.5V转5V输出无负载时,输入效率电流极低,典型值10uA. ...
- CentOS系统内核升级(在线 离线)
为什么要升级内核? Docker 在CentOS系统中需要安装在 CentOS 7 64 位的平台,并且内核版本不低于 3.10:CentOS 7.× 满足要求的最低内核版本要求,但由于 CentOS ...
- (09)-Python3之--类的三大特性(封装、继承、多态)
1.封装 封装,就是只能在类的内部访问,外部访问属性或方法会报异常,python中的封装很简单,只要在属性前或者方法名前加上两个下划线就可以,如self.__name,def __eat(self)这 ...
- 树莓派zero 使用usb串口连接
使用minicom连接bash$ lsusbBus 002 Device 001: ID 1d6b:0003 Linux Foundation 3.0 root hubBus 001 Device 0 ...
- 415 Unsupported Media Type
415 Unsupported Media Type - HTTP | MDN https://developer.mozilla.org/en-US/docs/Web/HTTP/Status/415
- 腾讯libco协程原理
https://blog.csdn.net/GreyBtfly/article/details/83688420 堆栈 https://blog.csdn.net/lqt641/article/det ...
- python基础(格式化输出、基本运算符、编码)
1,格式化输出. 现有一练习需求,问用户的姓名.年龄.工作.爱好 ,然后打印成以下格式 ------------ info of Alex Li ----------- Name : Alex Li ...
- Treap——堆和二叉树的完美结合,性价比极值的搜索树
大家好,今天和大家聊一个新的数据结构,叫做Treap. Treap本质上也是一颗BST(平衡二叉搜索树),和我们之前介绍的SBT是一样的.但是Treap维持平衡的方法和SBT不太一样,有些许区别,相比 ...
- Spring听课笔记(专题二)
第3章 Spring Bean的装配(上) 3-1:配置项及作用域 1.Bean的配置项: -- Id -- Class (这个必须,其他的都可以不配置) -- Scope (作用域) -- Cons ...
- Linux CGroup入门
Linux cgroup Linux CGroup全称Linux Control Group, 是Linux内核的一个功能,用来限制,控制与分离一个进程组群的资源(如CPU.内存.磁盘输入输出等).L ...