分布式理论 PACELC 了解么?
PACELC 基于 CAP 理论演进而来。
CAP 理论是一个分布式系统中老生常谈的理论了:
- C(Consistency):一致性,所有节点在同一时间的数据完全一致。
- A(Availability):可用性,服务一直可用。
- P(Partition tolerance):分区容错性,遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务
系统设计中,这三点只能取其二,一般的分布式系统要求必须有分区容错性。剩下的只能从 C 或者 A 中取舍。
但是这个理论并不能很好地应用于实际,首先, A 中是有一定争议的,很长时间才返回,虽然可用,但是业务上可能不能接受。并且,系统大部分时间下,分区都是平稳运行的,并不会出错,在这种情况下,系统设计要均衡的其实是延迟与数据一致性的问题,为了保证数据一致性,写入与读取的延迟就会增高。这就引出了 PACELC 理论。
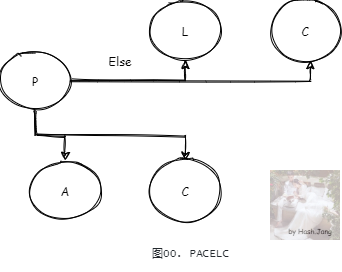
在出现分区错误的情况下,取前半部分 PAC,理论和 CAP 内容一致。没有出现分区错误的情况下(PACELC 中的 E 代表 Else),取 LC,也就是 Latency(延迟)与 Consistency(一致性)。
现在,其实很多存储,都已经实现了不同的 PACELC 的兼顾策略,并且交由用户配置去灵活根据不同业务场景使用不同的策略。
DynamoDB,Riak,Cassandra 的 NWR 模型
例如 DynamoDB 和 Riak 还有 Cassandra 都是 Dynamo 理论论文的基于一致性哈希写多份实现最终一致性的存储,在默认情况下,是 P+A 以及 E+L 的系统,但是可以根据配置修改,主要基于NWR模型与同步和异步备份。N 代表 N 个备份,W 代表要写入至少 W 份才认为成功,R 表示至少读取 R 个备份。配置的时候要求 W+R > N。 因为 W+R > N, 所以 R > N-W。这个是什么意思呢?就是读取的份数一定要比总备份数减去确保写成功的倍数的差值要大。
也就是说,每次读取,都至少读取到一个最新的版本。从而不会读到一份旧数据。当我们需要高可写的环境的时候(例如,amazon 的购物车的添加请求应该是永远不被拒绝的)我们可以配置W = 1 如果N=3 那么R = 3。 这个时候只要写任何节点成功就认为成功,但是读的时候必须从所有的节点都读出数据。如果我们要求读的高效率,我们可以配置 W=N R=1。这个时候任何一个节点读成功就认为成功,但是写的时候必须写所有三个节点成功才认为成功。
大家注意,一个操作的耗时是几个并行操作中最慢一个的耗时。比如R=3的时候,实际上是向三个节点同时发了读请求,要三个节点都返回结果才能认为成功。假设某个节点的响应很慢,它就会严重拖累一个读操作的响应速度。
MongoDB
MongoDB 和上面的 Dynamo 类似,MongoDB关于一致性、可用性的权衡,取决于三者:
write-concern: 表示当写请求在value个MongoDB实例处理之后才向客户端返回read-concern: 设定是否必须从 primary 读取最新的数据还是可以从 secondary 读取最终一致性的数据。read-preference: 对于replica set,是返回当前节点的最新数据,还是返回写入节点最多的数据,还是根据一些函数计算出的数据。
MySQL 同步
MySQL主从复制包括异步模式、半同步模式、全同步复制
默认情况下是异步模式,MySQL 一主多从部署读写分离的情况下,实现的为最终一致性,如果考虑一定延迟可以接受,一般可以通过 show slave status来查看主从延迟从而决定数据是否可以从 slave 读取。 MyCat 等中间件就是用了这种机制。可以通过对于这个时延的容忍性,控制 L 与 C 的取舍 以及 A 与 C 的取舍。
全同步复制:指当主库执行完一个事务,所有的从库都执行了该事务才返回给客户端。这样保证了强一致性,但是响应时间变长了。
半同步复制:主库在执行完客户端提交的事务后不是立刻返回给客户端,而是等待至少一个从库接收到并写到 relay log 中才返回给客户端。这样虽然还是有延迟,但是延迟小了很多并且数据相比于异步复制更加不容易丢失。
一致性协议
一致性协议一般包括:
- 2PC,两阶段提交
- 3PC,三阶段提交
- Paxos,Paxos 是很细致的一致性协议,但是一般实现过于复杂仅仅是理论
- Raft,Raft 是能够实现分布式系统强一致性的算法,TiDB 的一致性协议就是基于 Raft
- ZAB,Zookeeper 的一致性协议,基于 Paxos 简化
- NWR,上面提到的 dynamo 理论基础的协议,将 PACELC 均衡交给用户
每日一刷,轻松提升技术,斩获各种offer:

分布式理论 PACELC 了解么?的更多相关文章
- 【转】分布式理论-CAP理论
一 CAP理论简述 CAP (Consistency, Availability, Partition Tolerance,) 理论是NoSQL数据库管理系统构建的基础. 强一致性:等同于所 ...
- 分布式理论——从ACID到CAP再到BASE
在传统的数据中,有ACID四大原则,在分布式中也有对应的CAP理论和BASE理论,这些都是分布式理论的基础. 更多内容参考:大数据学习之路 ACID ACID分别是Atomicity 原子性.Cons ...
- 分布式理论(二)——Base 理论
前言 在前文 分布式理论(一) -- CAP 定理 中,我们说,CAP 不可能同时满足,而分区容错是对于分布式系统而言,是必须的.最后,我们说,如果系统能够同时实现 CAP 是再好不过的了,所以出现了 ...
- 分布式理论系列(三)ZAB 协议
分布式理论系列(三)ZAB 协议 在学习了 Paxos 后,接下来学习 Paxos 在开源软件 Zookeeper 中的应用. 一.Zookeeper Zookeeper 致力于提供一个高性能.高可用 ...
- 分布式理论系列(二)一致性算法:2PC 到 3PC 到 Paxos 到 Raft 到 Zab
分布式理论系列(二)一致性算法:2PC 到 3PC 到 Paxos 到 Raft 到 Zab 本文介绍一致性算法: 2PC 到 3PC 到 Paxos 到 Raft 到 Zab 两类一致性算法(操作原 ...
- 分布式理论系列(一)从 ACID 到 CAP 到 BASE
分布式理论系列(一)从 ACID 到 CAP 到 BASE 一.ACID 1.1 事务的四个特征: (1) Atomic(原子性) 事务必须是一个原子的操作序列单元,事务中包含的各项操作在一次执行过程 ...
- Apache ZooKeeper原理剖析及分布式理论名企高频面试v3.7.0
概述 **本人博客网站 **IT小神 www.itxiaoshen.com 定义 Apache ZooKeeper官网 https://zookeeper.apache.org/ 最新版本3.7.0 ...
- 分布式理论之一:Paxos算法的通俗理解
维基的简介:Paxos算法是莱斯利·兰伯特(Leslie Lamport,就是 LaTeX 中的"La",此人现在在微软研究院)于1990年提出的一种基于消息传递且具有高度容错特性 ...
- 分布式理论 之 CAP 定理
-----------------------------------------------------入巷间吃汤面 笑看窗边飞雪. 目录: 什么是 CAP 定理 为什么只能 3 选 2 能不能解决 ...
随机推荐
- SQL Server解惑——为什么ORDER BY改变了变量的字符串拼接结果
在SQL Server中可能有这样的拼接字符串需求,需要将查询出来的一列拼接成字符串,如下案例所示,我们需要将AddressID <=10的AddressLine1拼接起来,分隔符为|.如下 ...
- Logstash学习之路(一)Logstash的安装
一.Logstash简介 Logstash 是一个实时数据收集引擎,可收集各类型数据并对其进行分析,过滤和归纳.按照自己条件分析过滤出符合数据导入到可视化界面.它可以实现多样化的数据源数据全量或增量传 ...
- Mysql性能监控可视化
前言 操作系统以及Mysql数据库的实时性能状态数据尤为重要,特别是在有性能抖动的时候,这些实时的性能数据可以快速帮助你定位系统或Mysql数据库的性能瓶颈,镜像你在Linux系统上使用top.i ...
- 如何不使用 overflow: hidden 实现 overflow: hidden
一个很有意思的题目.如何不使用 overflow: hidden 实现 overflow: hidden? CSS 中 overflow 定义当一个元素的内容太大而无法适应块级格式化上下文时候该做什么 ...
- R语言学习笔记-Corrplot相关性分析
示例图像 首先安装需要的包 install.packages("Corrplot") #安装Corrplot install.packages("RColorBrewer ...
- Linux下的screen和作业任务管理
一.screen 首先介绍下screen,screen是Linux下的一个任务容器,开启了之后就可以让任务在后台执行而不会被网络中断或者是终端退出而影响到. 在Linux中有一些耗时比较久的操作(例如 ...
- python中re模块的使用(正则表达式)
一.什么是正则表达式? 正则表达式,又称规则表达式,通常被用来检索.替换那些符合某个模式(规则)的文本. 正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符.及这些特定字符的组合, ...
- 【Jboss】一台服务器上如何部署多个jboss
一台服务器上如何部署多个jboss呢?直接把整个部署环境copy一份到相应的目录下? 这样只是前提,但是启动复制后的jboss就会发现,有很多端口被占用 3873,8080,8009,8443,808 ...
- 大文件上传FTP
需求 将本地大文件通过浏览器上传到FTP服务器. 原有方法 将本地文件整个上传到浏览器,然后发送到node服务器,最后由node发送到FTP服务器. 存在问题 浏览器缓存有限且上传速率受网速影响,当文 ...
- 使用axis1.4生成webservice的客户端代码
webservice服务端: https://blog.csdn.net/ghsau/article/details/12714965 跟据WSDL文件地址生成客服端代码: 1.下载 axis1.4 ...