利用ELK构建一个小型的日志收集平台
利用ELK构建一个小型日志收集平台
伴随着应用以及集群的扩展,查看日志的方式总是不方便,我们希望可以有一个便于我们查询及提醒功能的平台;那么首先需要剖析有几步呢?
格式定义 --> 日志收集 --> 运输 --> 存入 --> 查询
根据上面这几步,我们简单来设计一个收集平台,如下图:
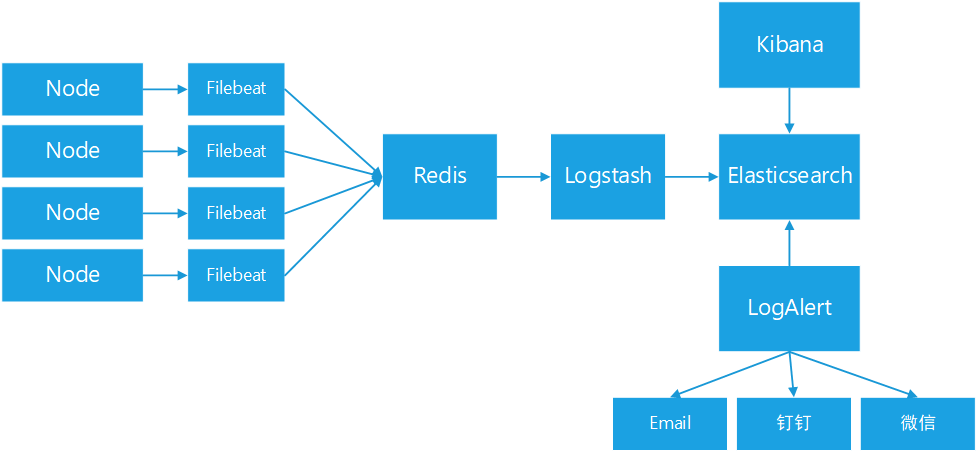
这里我们使用了Elastic Stack家族的Filebeat用作客户端收集,Kibana作为数据展示,Elasticsearch(后面简称ES)来存储日志,Logstash作为一个中转站帮助我们运输日志;同时我们还们还加入日志队列(这里使用Redis来担任)。
Filebeat以及Logstash自身带有队列功能,但是这里放置Redis可以做到解耦的功能,当然你也可以选择使用kafka这样的;至于Redis这边可以采用LB的模式来预防单点问题;
LogAlert是我们开发的专用于日志报警的工具,具体内容我们后面介绍。
整体软件环境说明:Filebeat、Kibana、Logstash、es均采用官方6.5.4的版本,请注意版本。
1、确定采集项目
我们简单梳理下采集项目如下:
- 系统日志 (Elastic Stack 有现成的模板)
- Message
- 审计日志
- 安全日志
- 开源组件 (绝大多数 Elastic Stack 有现成的模板)
- Nginx: 负载均衡,Web服务器;主要收集HTTP访问情况;
- Redis: 缓存组件;
- MySQL: 主要收集慢查询日志和常规日志;
- .... 等等
- Java应用 (比如自研发应用)
- 常规日志
- 业务日志
非常重要,一定要提前沟通规范日志格式,不然后期在进行改动推动非常的难,最后日志谁用就让谁定义格式;同时也要安利一波日志平台的好处,要不然怎么忽悠别人用呢,哈哈。
2、环境准备说明
这里呢,我将演示系统日志、Nginx日志、Redis日志、以及一个Java应用;采用系统为CentOS 7系统,如果未说明版本则不会影响我们的使用。
这里相关组件如Nginx、Redis我们采用最简单的Yum安装,别的需求可以自己定义。
3、采集节点日志(System,Nginx,Redis)
采集日志我们通过filebeat来搞,Filebeat比Logstash的一大优点是轻量级别,节省资源尤其是在云上我们很多情况下都是2核4G或者4核8G这样的机器,所以Filebeat作为客户端日志采集好处,balabala..... 我就不啰嗦了。(安装包请自行官网下载)
安装:
rpm -ivh filebeat-6.5.4-x86_64.rpm
打开Module的支持:
Module是Filebeat预配置的日志收集,其原理也非常的简单,通过Input进行收集,然后通过es pipeline进行解析日志。
filebeat modules enable auditd nginx redis system
调整配置配置文件:
shell> cat /etc/filebeat/filebeat.yml
filebeat.inputs:
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 3
setup.kibana:
host: "localhost:5601"
output.redis:
hosts: ["localhost:6379"]
password: "123456"
key: "logs"
db: 0
timeout: 5
processors:
- add_host_metadata: ~
这里的配置说明是,配置redis的地址,以及KibanaAPI的地址;redis的配置我们需要简单调整下,调整如下:
shell> cat /etc/filebeat/modules.d/redis.yml
- module: redis
# Main logs
log:
enabled: true
# Set custom paths for the log files. If left empty,
# Filebeat will choose the paths depending on your OS.
var.paths: ["/var/log/redis/redis.log*"]
# Slow logs, retrieved via the Redis API (SLOWLOG)
slowlog:
enabled: false
# The Redis hosts to connect to.
#var.hosts: ["localhost:6379"]
# Optional, the password to use when connecting to Redis.
#var.password:
可以看到,我们调整了Redis日志的路径,同时关闭了slowlog日志功能,当前版本还是测试,有兴趣的小伙伴可以研究一下,我这里就暂不使用。
启动服务:
shell> systemctl enable filebeat
shell> systemctl start filebeat
我们检查下Redis是否有日志存在
127.0.0.1:6379> LLEN logs
(integer) 5559
Ok, 至此我们通过Filebeat的Module快速收集了日志,接下来我们搞一个存储和Kibana了。
4、ES+Kibana部署
常规安装走一波:
首先我们需要看装JDK1.8的版本
shell> rpm -ivh jdk-8u191-linux-x64.rpm
安装部署ES
shell> rpm -ivh elasticsearch-6.5.4.rpm
shell> systemctl daemon-reload
shell> systemctl enable elasticsearch.service
shell> systemctl start elasticsearch.service
安装插件ingest-user-agent, ingest-geoip
shell> /usr/share/elasticsearch/bin/elasticsearch-plugin install file:///usr/local/src/ingest-user-agent-6.5.4.zip
shell> /usr/share/elasticsearch/bin/elasticsearch-plugin install file:///usr/local/src/ingest-geoip-6.5.4.zip
shell> systemctl restart elasticsearch
安装Kibana
shell> rpm -ivh kibana-6.5.4-x86_64.rpm
shell> systemctl enable kibana
shell> systemctl start kibana
然后可以Web查看一下,如果是其他机器请调整监听端口即可。

导入Filebeat模板与pipeline:
系统模板中,定义了非常多的字段属性,同时pipeline中定义的解析日志的规则;
导出默认的系统模板
shell> filebeat export template > filebeat.template.json
shell> sed -i 's@filebeat-6.5.4@sys-log@g' filebeat.template.json # 修改匹配索引
shell> curl -H 'Content-Type: application/json' -XPUT 'http://localhost:9200/_template/sys-log' -d@filebeat.template.json
导入modules到ES的pipline(导入前我们需要调整下,不然会有时区问题)
Nginx模块:
我们修改配置模板文件:/usr/share/filebeat/module/nginx/error/ingest/pipeline.json
原内容
"date": {
"field": "nginx.error.time",
"target_field": "@timestamp",
"formats": ["YYYY/MM/dd H:m:s"]
}
修改后
"date": {
"field": "nginx.error.time",
"target_field": "@timestamp",
"formats": ["YYYY/MM/dd H:m:s"],
"timezone" : "Asia/Shanghai"
}
Redis模块:
我们修改配置模板文件:/usr/share/filebeat/module/redis/log/ingest/pipeline.json
原内容
"date": {
"field": "redis.log.timestamp",
"target_field": "@timestamp",
"formats": ["dd MMM H:m:s.SSS", "dd MMM H:m:s", "UNIX"],
"ignore_failure": true
}
修改后
"date": {
"field": "redis.log.timestamp",
"target_field": "@timestamp",
"formats": ["dd MMM H:m:s.SSS", "dd MMM H:m:s", "UNIX"],
"ignore_failure": true,
"timezone" : "Asia/Shanghai"
}
系统模块:
我们编辑配置文件:/usr/share/filebeat/module/system/syslog/manifest.yml 打开时区的支持(Auth文件同样:/usr/share/filebeat/module/system/auth/manifest.yml)
原内容
- name: convert_timezone
default: false
修改后
- name: convert_timezone
default: true
审计模块:
我们修改配置模板文件:/usr/share/filebeat/module/auditd/log/ingest/pipeline.json
原内容
"date": {
"field": "auditd.log.epoch",
"target_field": "@timestamp",
"formats": [
"UNIX"
],
"ignore_failure": true
}
修改后
"date": {
"field": "auditd.log.epoch",
"target_field": "@timestamp",
"formats": [
"UNIX"
],
"ignore_failure": true,
"timezone" : "Asia/Shanghai"
}
导入到ES系统之中:
shell> filebeat setup --modules nginx,redis,system,auditd --pipelines -e -E 'output.elasticsearch.hosts=["localhost:9200"]'
这里可以通过ES API进行查询是否写入
es api> GET /_ingest/pipeline/
这里会提示多个Out冲突,怎么办呢? 吧原先的Output注释掉即可,不用重启服务。
5、通过Logstash打通日志
安装
shell> rpm -ivh logstash-6.5.4.rpm
配置一个pip
shell> cat /etc/logstash/conf.d/sys-log.conf
input {
redis {
host => "127.0.0.1"
password => '123456'
port => "6379"
db => "0"
data_type => "list"
key => "logs"
}
}
filter {
}
output {
if [fileset][module] in ["system", "nginx", "redis", "mysql", "auditd"] {
if [fileset][module] == "nginx" and [fileset][name] == "access" {
elasticsearch {
hosts => localhost
index => "sys-log-%{+YYYY.MM.dd}"
pipeline => "filebeat-6.5.4-%{[fileset][module]}-%{[fileset][name]}-default"
}
} else {
elasticsearch {
hosts => localhost
index => "sys-log-%{+YYYY.MM.dd}"
pipeline => "filebeat-6.5.4-%{[fileset][module]}-%{[fileset][name]}-pipeline"
}
}
}
}
启动测试
shell> systemctl enable logstash
shell> systemctl start logstash
可以通过Redis队列状态 或者 ES当前日志信息进行查询。
6、自定义收集项
Grok表达式:
\[%{DATA:svc}\] %{TIMESTAMP_ISO8601:time} %{LOGLEVEL:log.level} %{POSINT:process.pid} --- \[ *%{DATA:process.thread}\] %{DATA:process.class} *: %{GREEDYDATA:msg}
配置系统日志索引模板:主要内容字段根据Grok表达式写入模板文件,模板文件根据系统模板修改而成。
将模板导入ES系统之中:
shell> curl -H 'Content-Type: application/json' -XPUT 'http://localhost:9200/_template/svc-log' -d@svc.template.json
配置Filebeat抓取服务日志:(增加Input内容如下)
- type: log
paths:
- /application/apps/*/server.log
multiline.pattern: '^\['
multiline.negate: true
multiline.match: after
fields:
svc_type: java
具体配置信息,请了解官方信息。
配置Logstash解析格式
input {
...
}
filter {
if [fields][svc_type] == "java" {
grok {
match => { "message" => "\[%{DATA:svc}\] %{TIMESTAMP_ISO8601:time} +%{LOGLEVEL:log.level} %{POSINT:process.pid} --- \[ *%{DATA:process.thread}\] %{DATA:process.class} *: %{GREEDYDATA:msg}" }
remove_field => "message"
}
date {
match => [ "time", "ISO8601", "yyyy-MM-dd HH:mm:ss.SSS" ]
remove_field => "time"
}
mutate {
add_field => { "read_timestamp" => "%{@timestamp}" }
}
}
}
output {
if [fields][svc_type] == "java" {
elasticsearch {
hosts => localhost
index => "svc-log-%{+YYYY.MM.dd}"
}
}
}
至此,我们简单的日志架构就已经完成了。
利用ELK构建一个小型的日志收集平台的更多相关文章
- ELK+Kafka 企业日志收集平台(一)
背景: 最近线上上了ELK,但是只用了一台Redis在中间作为消息队列,以减轻前端es集群的压力,Redis的集群解决方案暂时没有接触过,并且Redis作为消息队列并不是它的强项:所以最近将Redis ...
- FILEBEAT+ELK日志收集平台搭建流程
filebeat+elk日志收集平台搭建流程 1. 整体简介: 模式:单机 平台:Linux - centos - 7 ELK:elasticsearch.logstash.kiban ...
- ELK 6安装配置 nginx日志收集 kabana汉化
#ELK 6安装配置 nginx日志收集 kabana汉化 #环境 centos 7.4 ,ELK 6 ,单节点 #服务端 Logstash 收集,过滤 Elasticsearch 存储,索引日志 K ...
- 利用 vue-cli 构建一个 Vue 项目
一.项目初始构建 现在如果要构建一个 Vue 的项目,最方便的方式,莫过于使用官方的 vue-cli . 首先,咱们先来全局安装 vue-cli ,打开命令行工具,输入以下命令: $ npm inst ...
- 利用Dockerfile构建一个基于CentOS 7镜像
利用Dockerfile构建一个基于CentOS 7,包括java 8, tomcat 7,php ,mysql+mycat的镜像. Dockerfile内容如下: FROM centosMAINTA ...
- 【转】flume+kafka+zookeeper 日志收集平台的搭建
from:https://my.oschina.net/jastme/blog/600573 flume+kafka+zookeeper 日志收集平台的搭建 收藏 jastme 发表于 10个月前 阅 ...
- CoSky-Mirror 就像一个镜子放在 Nacos、CoSky 中间,构建一个统一的服务发现平台
CoSky 基于 Redis 的服务治理平台(服务注册/发现 & 配置中心) Consul + Sky = CoSky CoSky 是一个轻量级.低成本的服务注册.服务发现. 配置服务 SDK ...
- ELK构建MySQL慢日志收集平台详解
上篇文章<中小团队快速构建SQL自动审核系统>我们完成了SQL的自动审核与执行,不仅提高了效率还受到了同事的肯定,心里美滋滋.但关于慢查询的收集及处理也耗费了我们太多的时间和精力,如何在这 ...
- ELK 构建 MySQL 慢日志收集平台详解
ELK 介绍 ELK 最早是 Elasticsearch(以下简称ES).Logstash.Kibana 三款开源软件的简称,三款软件后来被同一公司收购,并加入了Xpark.Beats等组件,改名为E ...
随机推荐
- Head First 设计模式 - 01. 策略 (Strategy) 模式
当涉及到"维护"时,为了"复用"目的而使用继承,结局并不完美 P4 对父类代码进行修改时,影响层面可能会很大 思考题 利用继承来提供 Duck 的行为,这会导致 ...
- 你真会看idea中的Log吗?
在项目中提交代码时,我们时常忘了自己是否已经update代码或者push代码了,或者以为自己push,但是别人说你的代码没push,其实可以通过idea的Log日志中查看,你会发现里面有三种颜色的标签 ...
- es6 Array.from + new Set 去重复
// es6 set数据结构 生成一个数据集 里面的元素是唯一的 const items = new Set([1, 2, 3, 4, 5, 5, 5, 5]); // items 是个对象 item ...
- 【Spring】Spring 入门
Spring 入门 文章源码 Spring 概述 Spring Spring 是分层的 Java SE/EE 应用全栈式轻量级开源框架,以 IOC(Inverse Of Control,反转控制)和 ...
- PC个人隐私保护小方法
前言 近期爆出了腾讯读取用户浏览器浏览记录的消息.话不过说直接上图,懂的自然懂. 网上也有详细的分析文章,不管它读取后用来做什么,在你不知情的情况下读取了你的浏览器浏览记录,你说气不气. 虽然在整体大 ...
- 【Oracle】Script to Collect DRM Information (drmdiag.sql) (文档 ID 1492990.1)
脚本对应如下: The following (drmdiag.sql) is a script to collect information related to DRM (Dyanamic Reso ...
- ctfshow—web—web5
打开靶机,代码审计 附上代码 <?php error_reporting(0); ?> <html lang="zh-CN"> <head> & ...
- npm i 报错 'match' of undefined 错误以及删除node_modules失败
简单粗暴的解决办法就是一个字'删', 1.先把node_modules给删了 手动删除的话,window系统经常会有部分删不了,说需要个权限什么的,直接用rimraf 就能解决 先安装npm inst ...
- 1.搭建Hadoop实验平台
节点功能规划 操作系统:CentOS7.2(1511) Java JDK版本:jdk-8u65-linux-x64.tar.gz Hadoop版本:hadoop-2.8.3.tar.gz 下载地址: ...
- 1.5V升3V芯片和电路图,DC-DC升压IC
1.5V升3V的升压芯片,3V给LED供电,或者单片机模块供电等. PW5200A工作频率为1.4MHZ.轻载时自动PWM/PFM模式切换,提高效率. PW5200A能够提供2.5V和5V之间的可调输 ...