被集群节点负载不均所困扰?TKE 重磅推出全链路调度解决方案
引言
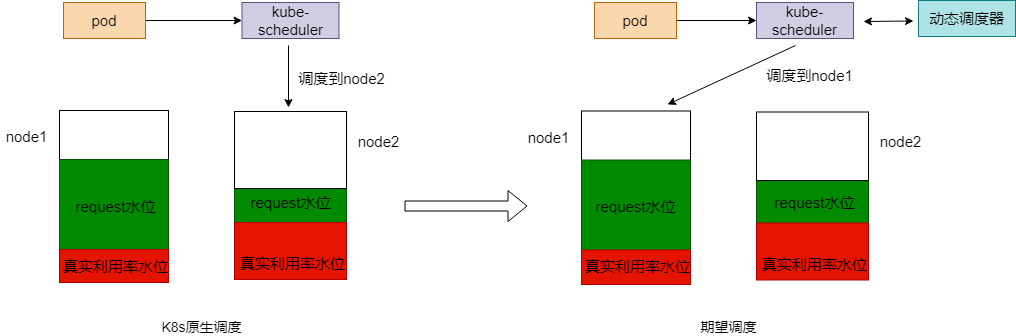
在 K8s 集群运营过程中,常常会被节点 CPU 和内存的高使用率所困扰,既影响了节点上 Pod 的稳定运行,也会增加节点故障的几率。为了应对集群节点高负载的问题,平衡各个节点之间的资源使用率,应该基于节点的实际资源利用率监控信息,从以下两个策略入手:
- 在 Pod 调度阶段,应当优先将 Pod 调度到资源利用率低的节点上运行,不调度到资源利用率已经很高的节点上
- 在监控到节点资源率较高时,可以自动干预,迁移节点上的一些 Pod 到利用率低的节点上
为此,我们提供 动态调度器 + Descheduler 的方案来实现,目前在公有云 TKE 集群内【组件管理】- 【调度】分类下已经提供这两个插件的安装入口,文末还针对具体的客户案例提供了最佳实践的例子。
动态调度器
原生的 Kubernetes 调度器有一些很好的调度策略用来应对节点资源分配不均的问题,比如 BalancedResourceAllocation,但是存在一个问题是这样的资源分配是静态的,不能代表资源真实使用情况,节点的 CPU/内存利用率 经常处于不均衡的状态。所以,需要有一种策略可以基于节点的实际资源利用率进行调度。动态调度器所做的就是这样的工作。
技术原理
原生 K8s 调度器提供了 scheduler extender 机制来提供调度扩展的能力。相比修改原生 scheduler 代码添加策略,或者实现一个自定义的调度器,使用 scheduler extender 的方式侵入性更少,实现更加灵活。所以我们选择基于 scheduler extender 的方式来添加基于节点的实际资源利用率进行调度的策略。
scheduler extender 可以在原生调度器的预选和优选阶段加入自定义的逻辑,提供和原生调度器内部策略同样的效果。
架构

- node-annotator:负责拉取 Prometheus 中的监控数据,定期同步到 Node 的 annotation 里面,同时负责其他逻辑,如动态调度器调度有效性衡量指标,防止调度热点等逻辑。
- dynamic-scheduler:负责 scheduler extender 的优选和预选接口逻辑实现,在预选阶段过滤掉资源利用率高于阈值的节点,在优选阶段优先选择资源利用率低的节点进行调度。
实现细节
- 动态调度器的策略在优选阶段的权重如何配置?
原生调度器的调度策略在优选阶段有一个权重配置,每个策略的评分乘以权重得到该策略的总得分。对权重越高的策略,符合条件的节点越容易调度上。默认所有策略配置权重为 1,为了提升动态调度器策略的效果,我们把动态调度器优选策略的权重设置为 2。
- 动态调度器如何防止调度热点?
在集群中,如果出现一个新增的节点,为了防止新增的节点调度上过多的节点,我们会通过监听调度器调度成功事件,获取调度结果,标记每个节点过去一段时间的调度 Pod 数,比如 1min、5min、30min 内的调度 Pod 数量,衡量节点的热点值然后补偿到节点的优选评分中。
产品能力
组件依赖
组件依赖较少,仅依赖基础的节点监控组件 node-exporter 和 Prometheus。Prometheus 支持托管和自建两种方式,使用托管方式可以一键安装动态调度器,而使用自建 Prometheus 也提供了监控指标配置方法。
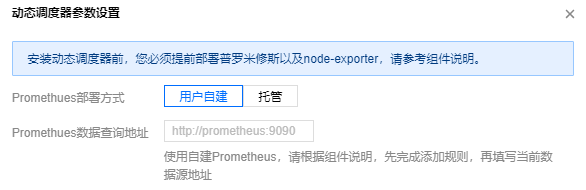
组件配置
调度策略目前可以基于 CPU 和内存两种资源利用率。
预选阶段

配置节点 5分钟内 CPU 利用率、1小时内最大 CPU 利用率,5分钟内平均内存利用率,1小时内最大内存利用率的阈值,超过了就会在预选阶段过滤节点。
优选阶段

动态调度器优选阶段的评分根据截图中 6个指标综合评分得出,6个指标各自的权重表示优选时更侧重于哪个指标的值,使用 1h 和 1d 内最大利用率的意义是要记录节点 1h 和 1d 内的利用率峰值,因为有的业务 Pod 的峰值周期可能是按照小时或者天,避免调度新的 Pod 时导致在峰值时间节点的负载进一步升高。
产品效果
为了衡量动态调度器对增强 Pod 调度到低负载节点的提升效果,结合调度器的实际调度结果,获取所有调度到的节点在调度时刻的的 CPU/内存利用率以后统计以下几个指标:
- cpu_utilization_total_avg :所有调度到的节点 CPU 利用率平均值。
- memory_utilization_total_avg :所有调度到的节点内存利用率平均值。
- effective_dynamic_schedule_count :有效调度次数,当调度到节点的 CPU 利用率小于当前所有节点 CPU 利用率的中位数,我们认为这是一次有效调度,effective_dynamic_schedule_count 加 0.5分,对内存也是同理。
- total_schedule_count :所有调度次数,每次新的调度累加1。
- effective_schedule_ratio :有效调度比率,即 effective_dynamic_schedule_count/total_schedule_count
下面是在同一集群中不开启动态调度和开启动态调度各自运行一周的指标变化,可以看到对于集群调度的增强效果。
| 指标 | 未开启动态调度 | 开启动态调度 |
|---|---|---|
| cpu_utilization_total_avg | 0.30 | 0.17 |
| memory_utilization_total_avg | 0.28 | 0.23 |
| effective_dynamic_schedule_count | 2160 | 3620 |
| total_schedule_count | 7860 | 7470 |
| effective_schedule_ratio | 0.273 | 0.486 |
Descheduler
现有的集群调度场景都是一次性调度,即一锤子买卖。后续出现节点 CPU 和内存利用率过高,也无法自动调整 Pod 的分布,除非触发节点的 eviction manager 后驱逐,或者人工干预。这样在节点 CPU/内存利用率高时,影响了节点上所有 Pod 的稳定性,而且负载低的节点资源还被浪费。
针对此场景,借鉴 K8s 社区 Descheduler 重调度的设计思想,给出基于各节点 CPU/内存实际利用率进行驱逐的策略。
架构
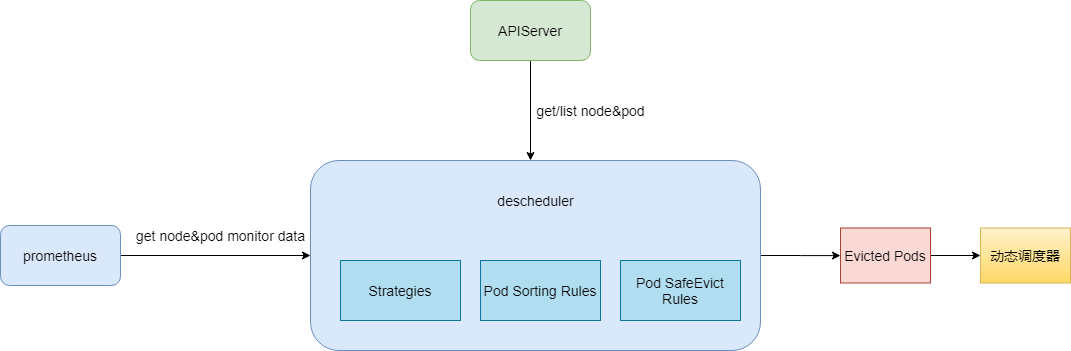
Descheduler 从 apiserver 中获取 Node 和 Pod 信息,从 Prometheus 中获取 Node 和 Pod 监控信息,然后经过Descheduler 的驱逐策略,驱逐 CPU/内存使用率高的节点上的 Pod ,同时我们加强了 Descheduler 驱逐 Pod 时的排序规则和检查规则,确保驱逐 Pod 时服务不会出现故障。驱逐后的 Pod 经过动态调度器的调度会被调度到低水位的节点上,实现降低高水位节点故障率,提升整体资源利用率的目的。
产品能力
产品依赖
依赖基础的节点监控组件 node-exporter 和Prometheus。Prometheus 支持托管和自建两种方式,使用托管方式可以一键安装 Descheduler,使用自建 Prometheus 也提供了监控指标配置方法。
组件配置
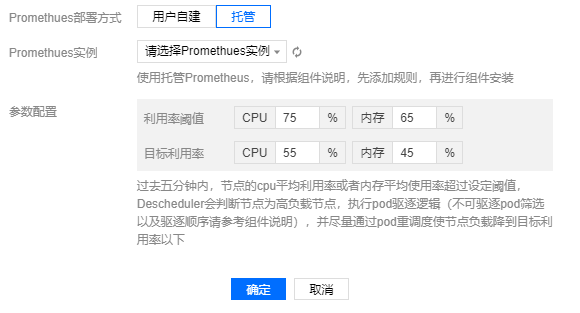
Descheduler 根据用户配置的利用率阈值,超过阈值水位后开始驱逐 Pod ,使节点负载尽量降低到目标利用率水位以下。
产品效果
通过 K8s 事件
通过 K8s 事件可以看到 Pod 被重调度的信息,所以可以开启集群事件持久化功能来查看 Pod 驱逐历史。

节点负载变化
在类似如下节点 CPU 使用率监控视图内,可以看到在开始驱逐之后,节点的 CPU 利用率下降。

最佳实践
集群状态
拿一个客户的集群为例,由于客户的业务大多是内存消耗型的,所以更容易出现内存利用率很高的节点,各个节点的内存利用率也很不平均,未使用动态调度器之前的各个节点监控是这样的:
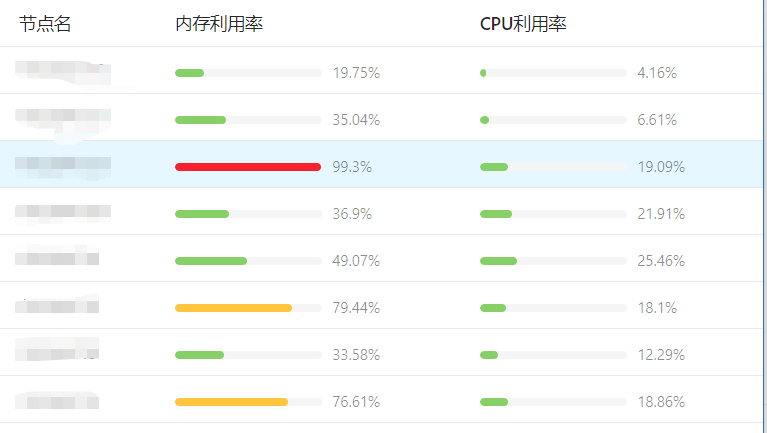
动态调度器配置
配置预选和优选阶段的参数如下:

在预选阶段过滤掉 5分钟内平均内存利用率超过 60%或者 1h内最大内存利用率超过 70%的节点,即 Pod 不会调度到这些这些节点上。
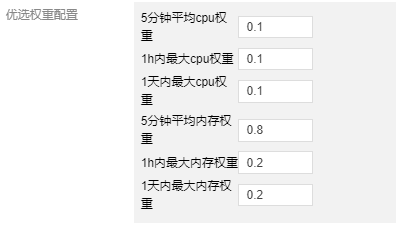
在优选阶段将 5分钟平均内存利用率权重配置为 0.8,1h 和1d 内最大内存利用率权重配置为 0.2、0.2,而将 CPU 的指标权重都配置为 0.1。这样优选时更优先选择调度到内存利用率低的节点上。
Descheduler配置
配置 Descheduler 的参数如下,当节点内存利用率超过 80%这个阈值的时候,Descheduler 开始对节点上的 Pod 进行驱逐,尽量使节点内存利用率降低到目标值 60% 为止。
集群优化后状态
通过以上的配置,运行一段时间后,集群内各节点的内存利用率数据如下,可以看到集群节点的内存利用率分布已经趋向于均衡:

【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!!

被集群节点负载不均所困扰?TKE 重磅推出全链路调度解决方案的更多相关文章
- DB层面上的设计 分库分表 读写分离 集群化 负载均衡
第1章 引言 随着互联网应用的广泛普及,海量数据的存储和访问成为了系统设计的瓶颈问题.对于一个大型的 互联网应用,每天几十亿的PV无疑对数据库造成了相当高的负载.对于系统的稳定性和扩展性造成了极大的 ...
- 结合Apache和Tomcat实现集群和负载均衡 JK 方式 2 (转)
本文Apache+Tomcat集群配置 基于最新的Apache和Tomcat,具体是2011年4月20日最新的Tomcat和Apache集群和负载均衡配置. 准备环境 Apache Apa ...
- ActiveMQ(八)_多集群的负载均衡
图一 图一说明: 1.集群一包含3个队列:A ...
- 结合Apache和Tomcat实现集群和负载均衡 JK 方式
本文基本参考自 轻松实现Apache,Tomcat集群和负载均衡,经由实操经历记录而成,碰到些出入,以及个别地方依据个人的习惯,所以在一定程度上未能保持原文的完整性,还望原著者海涵. 因原文中有较多的 ...
- 结合Apache和Tomcat实现集群和负载均衡
http://fableking.iteye.com/blog/360870 TomcatApacheJSP应用服务器Web 本文基本参考自 轻松实现Apache,Tomcat集群和负载均衡,经由实 ...
- Akka(11): 分布式运算:集群-均衡负载
在上篇讨论里我们主要介绍了Akka-Cluster的基本原理.同时我们也确认了几个使用Akka-Cluster的重点:首先,Akka-Cluster集群构建与Actor编程没有直接的关联.集群构建是A ...
- Web服务器Tomcat集群与负载均衡技术
我们曾经介绍过三种Tomcat集群方式的优缺点分析.本文将介绍Tomcat集群与负载均衡技术具体实施过程. 在进入集群系统架构探讨之前,先定义一些专门术语: 1. 集群(Cluster):是一组独立的 ...
- WEB 集群与负载均衡(一)基本概念-上
Web集群是由多个同时运行同一个web应用的服务器组成,在外界看来就像一个服务器一样,这多台服务器共同来为客户提供更高性能的服务.集群更标准的定义是:一组相互独立的服务器在网络中表现为单一的系统,并以 ...
- Kubernetes从懵圈到熟练:读懂这一篇,集群节点不下线
排查完全陌生的问题,完全不熟悉的系统组件,是售后工程师的一大工作乐趣,当然也是挑战.今天借这篇文章,跟大家分析一例这样的问题.排查过程中,需要理解一些自己完全陌生的组件,比如systemd和dbus. ...
随机推荐
- Java中构造代码块的使用
例子1 public class Client { { System.out.println("执行构造代码块1"); } { System.out.println("执 ...
- css 04-CSS选择器:伪类
04-CSS选择器:伪类 #伪类(伪类选择器) 伪类:同一个标签,根据其不同的种状态,有不同的样式.这就叫做"伪类".伪类用冒号来表示. 比如div是属于box类,这一点很明确,就 ...
- js上 十八、字符串
十八.字符串 #18.1.认识字符串 #什么是字符串 字符串可以是引号中的任意文本.字符串可以由双引号(")或单引号(')表示 ,如 'hello' , "中国" #为什 ...
- 5行Python代码就能实现刷爆全网的动态条形图!
说起动态图表,最火的莫过于动态条形图了. 在B站上搜索「数据可视化」这个关键词,可以看到很多与动态条形图相关的视频. 好多视频都达到了上百万的播放量,属实厉害. 目前网上实现动态条形图现成的工具也很多 ...
- 卡尔曼滤波学习笔记1-Matlab模拟温度例子--代码比较乱,还需优化
温度模拟参数选取 xk 系统状态 实际温度 A 系统矩阵 温度不变,为1 B.uk 状态的控制量 无控制量,为0 Zk 观测值 温度计读数 H 观测矩阵 直接读出,为1 wk 过程噪声 温度变化偏差, ...
- .NET Core 下的 API 网关
网关介绍 网关其实就是将我们写好的API全部放在一个统一的地址暴露在公网,提供访问的一个入口.在 .NET Core下可以使用Ocelot来帮助我们很方便的接入API 网关.与之类似的库还有Proxy ...
- ARP局域网断网攻击
Kali--ARP局域网攻击 什么是ARP? ARP ( Address Resolution Protocol)地址转换协议,工作在OSI模型的数据链路层,在以太网中,网络设备之间互相通信是用MAC ...
- IntelliJ IDEA如何用maven命令打jar包
IntelliJ IDEA如何用maven命令打jar包?下面给大家详细介绍一下具体步骤及说明. 工具/原料 IntelliJ IDEA maven 方法/步骤 第一步在CMD命令窗口输入 ...
- JS function 是函数也是对象, 浅谈原型链
JS function 是函数也是对象, 浅谈原型链 JS 唯一支持的继承方式是通过原型链继承, 理解好原型链非常重要, 我记录下我的理解 1. 前言 new 出来的实例有 _proto_ 属性, 并 ...
- reactor模式:多线程的reactor模式
上文说到单线程的reactor模式 reactor模式:单线程的reactor模式 单线程的reactor模式并没有解决IO和CPU处理速度不匹配问题,所以多线程的reactor模式引入线程池的概念, ...