PageRank 算法-Google 如何给网页排名
公号:码农充电站pro
主页:https://codeshellme.github.io
在互联网早期,随着网络上的网页逐渐增多,如何从海量网页中检索出我们想要的页面,变得非常的重要。
当时著名的雅虎和其它互联网公司都试图解决这个问题,但都没能有一个很好的解决方案。
直到1998 年前后,两位斯坦福大学的博士生,拉里·佩奇和谢尔盖·布林一起发明了著名的 PageRank 算法,才完美的解决了网页排名的问题。也正是因为这个算法,诞生了伟大的 Google 公司。

(上图中:左为布林,右为佩奇。)
1,PageRank 算法原理
PageRank 算法的核心原理是:在互联网中,如果一个网页被很多其它网页所链接,说明该网页非常的重要,那么它的排名就高。
拉里·佩奇将整个互联网看成一张大的图,每个网站就像一个节点,而每个网页的链接就像一个弧。那么,互联网就可以用一个图或者矩阵来描述。
拉里·佩奇也因该算法在30 岁时当选为美国工程院院士。
假设目前有4 个网页,分别是 A,B,C,D,它们的链接关系如下:
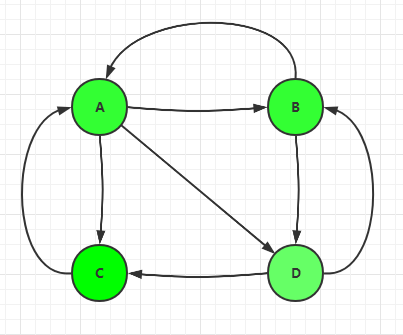
我们规定有两种链:
- 出链:从自身引出去的链。
- 入链:从外部引入自身的链。
比如图中的C 网页,有两个入链,一个出链。
PageRank 的思想就是,一个网页的影响力就等于它的所有入链的影响力之和。
用数学公式表示为:
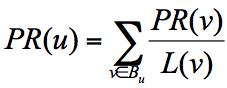
其中(分值代表页面影响力):
PR(u)是网页u的分值。Bu是网页u的入链集合。- 网页
v是网页u的任意一个入链。 PR(v)是网面v的分值。L(v)是网页v的出链数量。- 网页
v带给网页u的分值就是PR(v) / L(v)。 - 那么
PR(u)就等于所有的入链分值之和。
在上面的公式中,我们假设从一个页面v 到达它的所有的出链页面的概率是相等的。
比如上图来说,页面A 有三个出链分别链接到了 B、C、D 上。那么当用户访问 A 的时候,就有跳转到 B、C 或者 D 的可能性,跳转概率均为 1/3。
2,计算网页的分值
下面来看下如何计算网页的分值。
我们可以用一个表格,来表示上图中的网页的链接关系,及每个页面到其它页面的概率:
| A | B | C | D | |
|---|---|---|---|---|
| A | 0 A->A |
1/2 B->A |
1 C->A |
0 D->A |
| B | 1/3 A->B |
0 B->B |
0 C->B |
1/2 D->B |
| C | 1/3 A->C |
0 B->C |
0 C->C |
1/2 D->C |
| D | 1/3 A->D |
1/2 B->D |
0 C->D |
0 D->D |
根据这个表格中的数字,可以将其转换成一个矩阵M:

假设 A、B、C、D 四个页面的初始影响力都是相同的,都为 1/4,即:
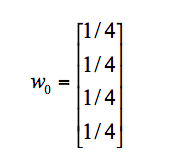
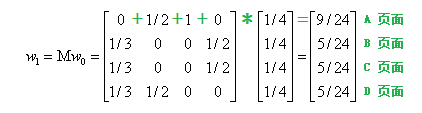
经过第一次分值转移之后,可以得到 W1,如下:
同理可以得到W2,W3 一直到 Wn:
- W2 = M * W1
- W3 = M * W2
- Wn = M * Wn-1
那么什么时候计算终止呢?
佩奇和布林已经证明,不管网页的初识值选择多少(我们这假设都是1/4),最终都能保证网页的分值能够收敛到一个真实确定值。
也就是直到 Wn 不再变化为止。
这就是网页分值的计算过程,还是比较好理解的。
3,PageRank 的两个问题
我们上文中介绍到的是PageRank 的基本原理,是简化版本。在实际应用中会出现等级泄露(RankLeak)和等级沉没(Rank Sink)的问题。
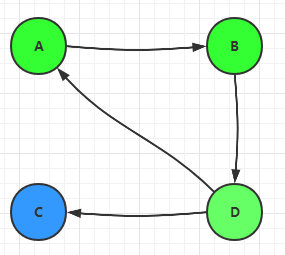
如果一个网页没有出链,就会吸收其它网页的分值不释放,最终会导致其它网页的分值为0,这种现象叫做等级泄露。如下图中的网页C:
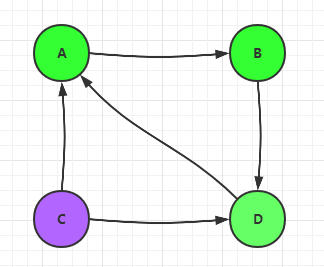
相反,如果一个网页没有入链,最终会导致该网页的分值为0,这种现象叫做等级沉没。如下图中的网页C:
4,PageRank 的随机浏览模型
为了解决上面的问题,拉里·佩奇提出了随机浏览模型,即用户并不都是依靠网页链接来访问网页,也有可能用其它方式访问网址,比如输入网址。
因此,提出了阻尼因子的概念,这个因子代表用户按照跳转链接来上网的概率,而 1-d 则代表用户通过其它方式访问网页的概率。
所以,将上文中的公式改进为:
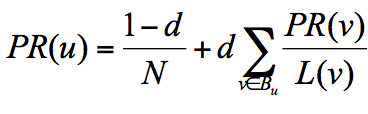
其中:
- d 为阻尼因子,通常可以取0.85。
- N 为网页总数。
5,用代码计算网页分值
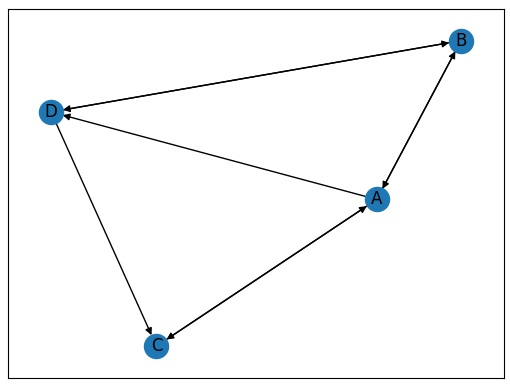
如何用代码来计算网页的PR 分值呢?(为了方便查看,我把上图放在这里)
我们可以看到,该图实际上就是数据结构中的有向图,因此我们可以通过构建有向图来构建 PageRank 算法。
NetworkX 是一个Python 工具包,其中集成了常用的图结构和网络分析算法。
我们可以用 NetworkX 来构建上图中的网络结构。
首先引入模块:
import networkx as nx
用 DiGraph 类创建有向图:
G = nx.DiGraph()
将4 个网页的链接关系,用数组表示:
edges = [
("A", "B"), ("A", "C"), ("A", "D"),
("B", "A"), ("B", "D"),
("C", "A"),
("D", "B"), ("D", "C")
]
数组中的元素作为有向图的边,并添加到图中:
for edge in edges:
G.add_edge(edge[0], edge[1])
使用pagerank 方法计算PR 分值:
# alpha 为阻尼因子
PRs = nx.pagerank(G, alpha=1)
print PRs
输出每个网页的PR 值:
{'A': 0.33333396911621094,
'B': 0.22222201029459634,
'C': 0.22222201029459634,
'D': 0.22222201029459634}
最终,我们计算出了每个网页的PR 值。
6,画出网络图
NetworkX 包中还提供了画出网络图的方法:
import matplotlib.pyplot as plt
# 画网络图
nx.draw_networkx(G)
plt.show()
如下:
我们还可以设置图的形状,节点的大小,边的长度等属性,具体可以点击这里查看。
更多关于 NetworkX 的内容可以参考其官方文档。
7,总结
PageRank 算法给了我们一个很重要的启发,权重在很多时候是一个非常重要的指标。
- 比如在人际交往中,个人的影响力不仅取决于你的朋友的数量,而且朋友的质量非常重要,说明了圈子的重要性。
- 比如在自媒体时代,粉丝数并不能真正的代表你的影响力,粉丝的质量也很重要。如果你的粉丝中有很多大V,那么将大大增加你影响力。
本篇文章主要介绍了:
- PageRank 算法的原理。
- 简化版的PageRank 算法遇到的问题,以及解决方案:
- 等级泄露和等级沉没。
- 引出随机浏览模型来解决这两个问题。
- 如何用代码模拟PageRank 算法:
- 使用了 NetworkX 模块。
(本节完。)
推荐阅读:
欢迎关注作者公众号,获取更多技术干货。

PageRank 算法-Google 如何给网页排名的更多相关文章
- PageRank算法简介及Map-Reduce实现
PageRank对网页排名的算法,曾是Google发家致富的法宝.以前虽然有实验过,但理解还是不透彻,这几天又看了一下,这里总结一下PageRank算法的基本原理. 一.什么是pagerank Pag ...
- [转]PageRank算法
原文引自: 原文引自: http://blog.csdn.net/hguisu/article/details/7996185 感谢 1. PageRank算法概述 PageRank,即网页排名,又称 ...
- pageRank算法 python实现
一.什么是pagerank PageRank的Page可是认为是网页,表示网页排名,也可以认为是Larry Page(google 产品经理),因为他是这个算法的发明者之一,还是google CEO( ...
- 谷歌pagerank算法简介
在这篇博客中我们讨论一下谷歌pagerank算法.这是参考的原博客连接:http://blog.jobbole.com/71431/ PageRank的Page可是认为是网页,表示网页排名,也可以认为 ...
- PageRank 算法简介
有两篇文章一篇讲解(下面copy)< PageRank算法简介及Map-Reduce实现>来源:http://www.cnblogs.com/fengfenggirl/p/pagerank ...
- Machine Learning:PageRank算法
1. PageRank算法概述 PageRank,即网页排名,又称网页级别.Google左側排名或佩奇排名. 在谷歌主导互联网搜索之前, 多数搜索引擎採用的排序方法, 是以被搜索词语在 ...
- PageRank算法原理与Python实现
一.什么是pagerank PageRank的Page可是认为是网页,表示网页排名,也可以认为是Larry Page(google 产品经理),因为他是这个算法的发明者之一,还是google CEO( ...
- 吴裕雄--天生自然HADOOP学习笔记:hadoop集群实现PageRank算法实验报告
实验课程名称:大数据处理技术 实验项目名称:hadoop集群实现PageRank算法 实验类型:综合性 实验日期:2018年 6 月4日-6月14日 学生姓名 吴裕雄 学号 15210120331 班 ...
- pagerank算法在数学模型中的运用(有向无环图中节点排序)
一.模型介绍 pagerank算法主要是根据网页中被链接数用来给网页进行重要性排名. 1.1模型解释 模型核心: a. 如果多个网页指向某个网页A,则网页A的排名较高. b. 如果排名高A的网页指向某 ...
随机推荐
- 在spark上构造随机森林模型过程的一点理解
这篇文章仅仅是为了帮助自己理解在分布式环境下是如何进行随机森林模型构建的,文章中记录的内容可能不太准确,仅仅是大致上的一个理解. 1.特征切分点统计 不管是连续取值型特征还是离散取值型特征,分裂树结点 ...
- 02 Filter过滤器
Filter 一.Filter过滤器 Filter过滤器它是JavaWeb的三大组件之一.三大组件分别是:Servlet程序.Listener监听器.Filter过滤器 Filter过滤器是JavaE ...
- 02、Spring-HelloWorld
0. 环境准备 1) jar包 jar包我会帮大家准备好的,所以不用担心找不到Jar包 链接:https://pan.baidu.com/s/1JJcYaspK07JL53vU-q-BUQ 提取码: ...
- 为什么Redis是单线程?
转载链接:https://cloud.tencent.com/developer/article/1120615 1)以前一直有个误区,以为:高性能服务器 一定是多线程来实现的 原因很简单因为误区二导 ...
- 分布式监控系统之Zabbix网络发现
前文我们了解了zabbix的宏,自定义item和模板的相关话题,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/14013331.html:今天我们来了解下zab ...
- ACCESS渗透测试
access-getshell 直接写shell # 创建临时表 create table test(a varchar(255)); # 插入一句话木马 insert into test(a) va ...
- ci爬坑
1.row_array() 问题描述:没有数据返回NULL,直接foreach,报错
- IDM下载器的队列功能有什么用?
使用IDM下载器中的队列功能,可以帮助大家快速分类下载任务,这样,就可以统一管理有同样下载需求的内容. 一.队列的添加及设置 打开IDM下载器,单击菜单中的"队列",可以看到在左侧 ...
- Vegas教程:教你制作热门人物消失特效
在许多电影中,我们经常会看到一些人物逐渐消失的情景,这种情景一般都是通过后期技术处理的结果,现实生活中根本不可能出现,那么这种特效是如何制作处理的呢?下面小编就来教大家如何用Vegas Pro ...
- ELK---- Elasticsearch 使用ik中文分词器增加拓展热词
进入到我们ik分词器安装目录下的config目录 cd /usr/local/myapp/elasticsearch-6.4.3/plugins/ik/configvi IKAnalyzer.cfg. ...