你说一下Redis为什么快吧,怎么实现高可用,还有持久化怎么做的?
前言
作为Java程序员,在面试过程中,缓存相关的问题是躲不掉的,肯定会问,例如缓存一致性问题,缓存雪崩、击穿、穿透等。说到缓存,那肯定少不了Redis,我在面试的时候也是被问了很多关于Redis相关的知识,但是Redis的功能太强大了,并不是一时半会儿能掌握好的,因为有些高级特性或是知识平时并不会用到。
所以回答的不好,人家就会觉得你对自己平时使用的工具都没有了解,自然就凉凉了。其实很早就有这个打算,打算好好总结一下Redis的知识,但也是由于自己都没有好好的了解Redis呢,所以一直没有开始。这次准备慢慢的来总结。
Redis为什么这么快
Redis是一个由C语言编写的开源的,基于内存,支持多种数据结构可持久化的NoSQL数据库。
它速度快主要是有以下几个原因:
- 基于内存运行,性能高效;
- 数据结构设计高效,例如String是由动态字符数组构成,zset内部的跳表;
- 采用单线程,避免了线程的上下文切换,也避免了线程竞争产生的死锁等问题;
- 使用I/O多路复用模型,非阻塞IO;
官网上给出单台Redis的可以达到10w+的QPS的, 一台服务器上在使用Redis的时候单核的就够了,但是目前服务器都是多核CPU,要想不浪费资源,又能提交效率,可以在一台服务器上部署多个Redis实例。
高可用方案
虽然单台Redis的的性能很好,但是Redis的单节点并不能保证它不会挂了啊,毕竟单节点的Redis是有上限的,而且人家单节点又要读又要写,小身板扛不住咋办,所以为了保证高可用,一般都是做成集群。
主从(Master-Slave)
Redis官方是支持主从同步的,而且还支持从从同步,从从同步也可以理解为主从同步,只不过从从同步的主节点是另一个主从的从节点。
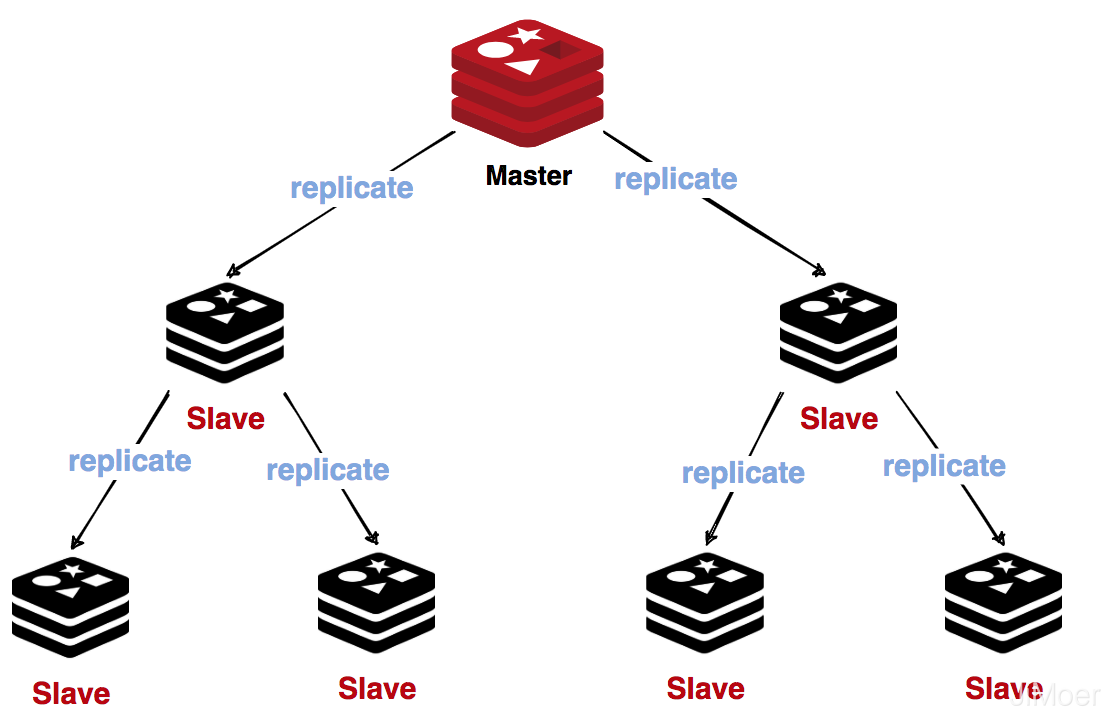
有了主从同步的集群,那么主节点就负责提供写操作,而从节点就负责支持读操作。
那么他们之间是如何进行数据同步的呢?
如果Slave(从节点)是第一次跟Master进行连接,
- 那么会首先会向Master发送同步请求
psync; - 主节点接收到同步请求,开始fork主子进程开始进行全量同步,然后生成RDB文件;
- 这个时候主节点同时会将新的写请求,保存到缓存区(buffer)中;
- 从节点接收到RDB文件后,先清空老数据,然后将RDB中数据加载到内存中;
- 等到从节点将RDB文件同步完成后再同步缓存区中的写请求。
这里有一点需要注意的就是,主节点的缓存区是有限的,内部结构是一个环形数组,当数组被占满之后就会覆盖掉最早之前的数据。
所以如果由于网络或是其他原因,造成缓存区中的数据被覆盖了,那么当从节点处理完主节点的RDB文件后,就不得不又要进行一全量的RDB文件的复制,才能保证主从节点的数据一致。
如果不设置好合理的buffer区空间,是会造成一个RDB复制的死循环。
当主从间的数据同步完成之后,后面主节点的每次写操作就都会同步到从节点,这样进行增量同步了。
由于负载的不断上升就导致了主从之间的延时变大,所以就有了上面我说的从从同步了,主节点先同步到一部分从节点,然后由从节点去同步其他的从节点。
在Redis从2.8.18开始支持无盘复制,主节点通过套接字,一边遍历内存中的数据,一边让数据发送给从节点,从节点和之前一样,先将数据存储在磁盘文件中,然后再一次性加载。
另外由于主从同步是异步的,所以从Redis3.0之后出现了同步复制,就是通过wait命令来进行控制,wait命令有两个参数,第一个是从库数量,第二个是等待从库的复制时间,如果第二个参数设置为0,那么就是代表要等待所有从库都复制完才去执行后面的命令。
但是这样就会存在一个隐患,当网络异常后,wait命令会一直阻塞下去,导致Redis不可用。
哨兵(Sentinel)
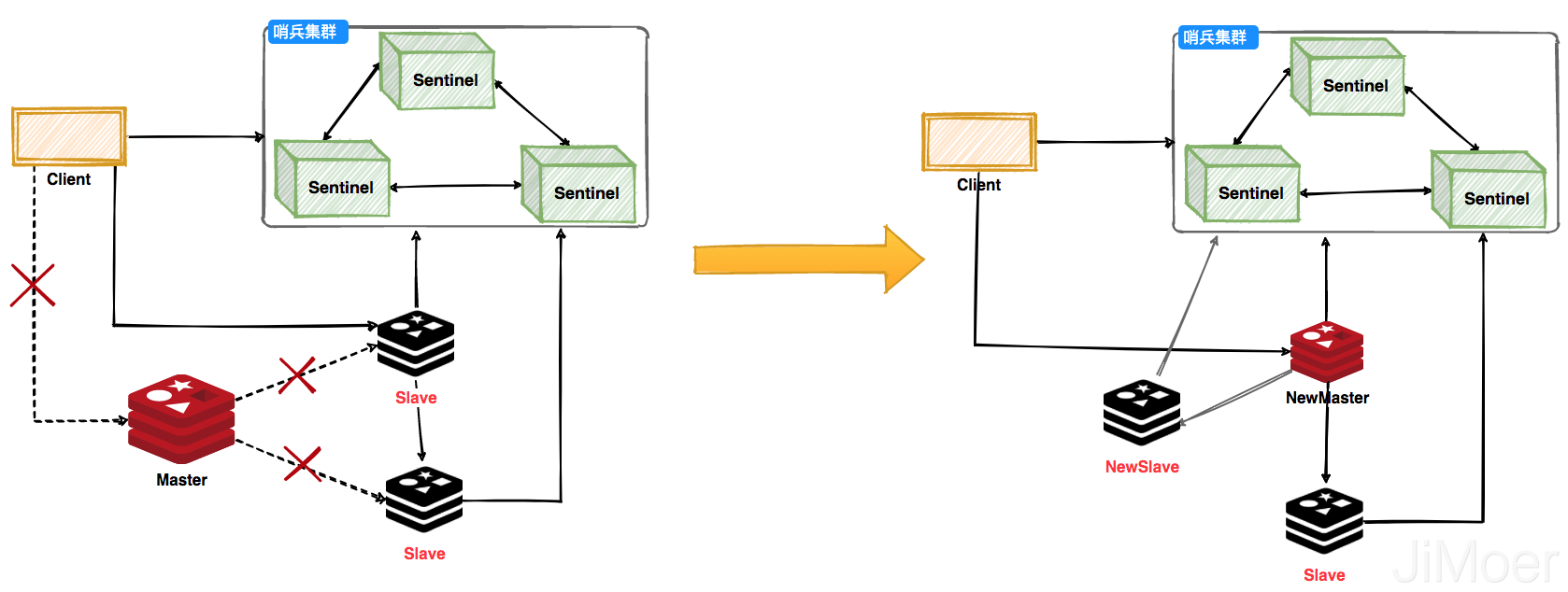
哨兵可以监控Redis集群的健康状态,当主节点挂掉之后,选举出新的主节点。客户端在使用Redis的时候会先通过Sentinel来获取主节点地址,然后再通过主节点来进行数据交互。当主节点挂掉之后,客户端会再次向Sentinel获取主节点,这样客户端就可以无感知的继续使用了。
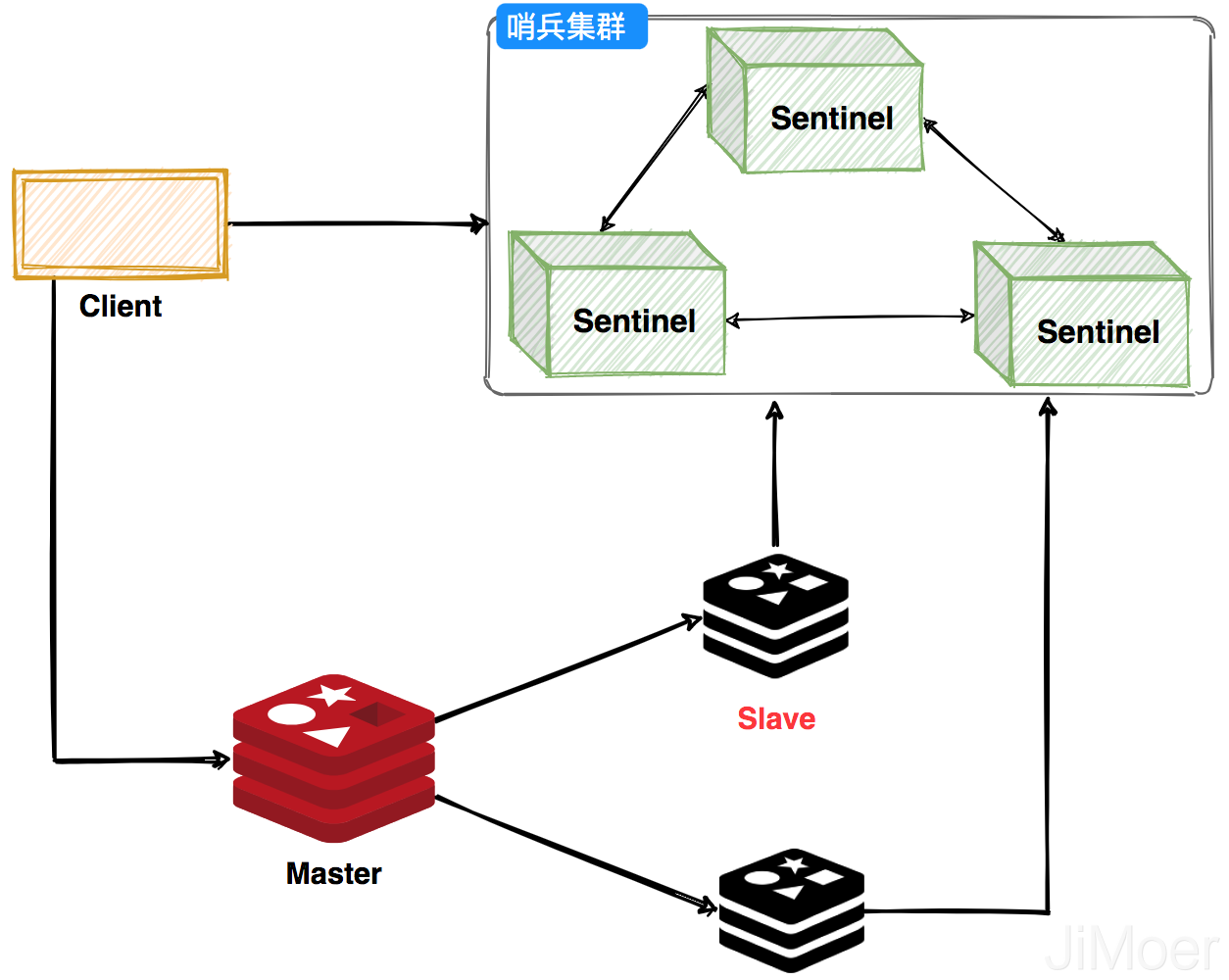
哨兵集群工作过程,主节点挂掉之后会选举出新的主节点,然后监控挂掉的节点,当挂掉的节点恢复后,原先的主节点就会变成从节点,从新的主节点那里建立主从关系。
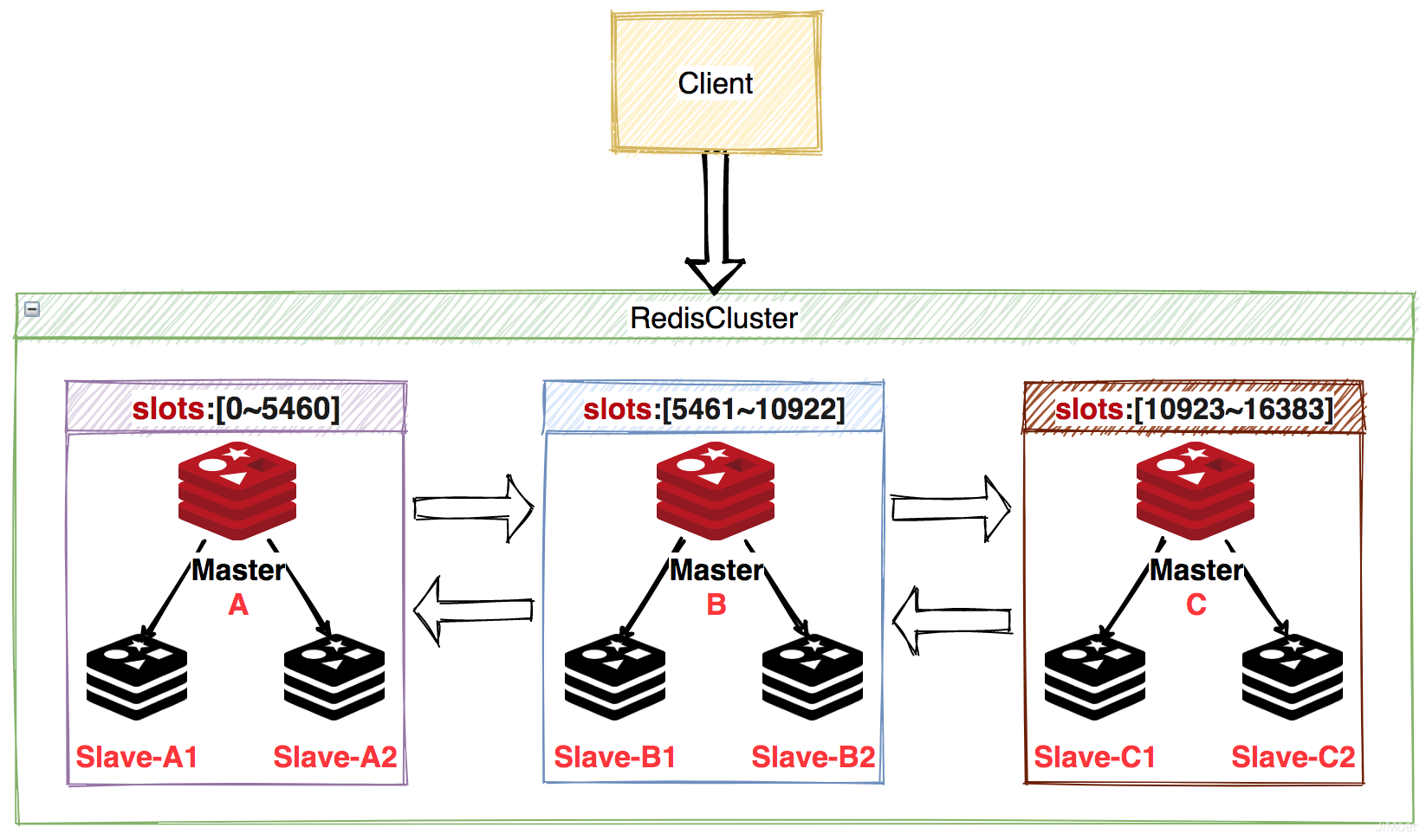
集群分片(Redis Cluster)
Redis Cluster是Redis官方推荐的集群模式,Redis Cluster将所有数据划分到16384个槽(slots)中,每个节点负责一部分槽位的读写操作。
存储
Redis Cluster默认是通过CRC16算法获取到key的hash值,然后再对16384进行取余(CRC16(key)%16384),获取到的槽位在哪个节点负责的范围内(这里一般是会有一个槽位和节点的映射表来进行快速定位节点的,通常使用bitmap来实现),就存储在哪个节点上。
重定向
当Redis Cluster的客户端在和集群建立连接的时候,也会获得一份槽位和节点的配置关系(槽位和节点的映射表),这样当客户端要查找某个key时,可以直接定位到目标节点。
但是当客户端发送请求时,如果接收请求的节点发现该数据的槽位并不在当前节点上,那么会返回MOVED指令将正确的槽位和节点信息返回给客户端,客户接着请求正确的节点获取数据。
一般客户端在接收到MOVED指令后,也会更新自己本地的槽位和节点的映射表,这样下次获取数据时就可以直接命中了。这整个重定向的过程对客户端是透明的。
数据迁移
当集群中新增节点或删除节点后,节点间的数据迁移是按槽位为单位的,一个槽位一个槽位的迁移,当迁移时原节点状态处于:magrating,目标节点处于:importing。
在迁移过程中,客户端首先访问旧节点,如果数据还在旧节点,那么旧节点正常处理,如果不在旧节点,就会返回一个-ASK + 目标节点地址的指令,客户端收到这个-ASK指令后,向目标节点执行一个asking指令(告诉新节点,必须处理客户端这个数据),然后再向目标节点执行客户端的访问数据的指令。
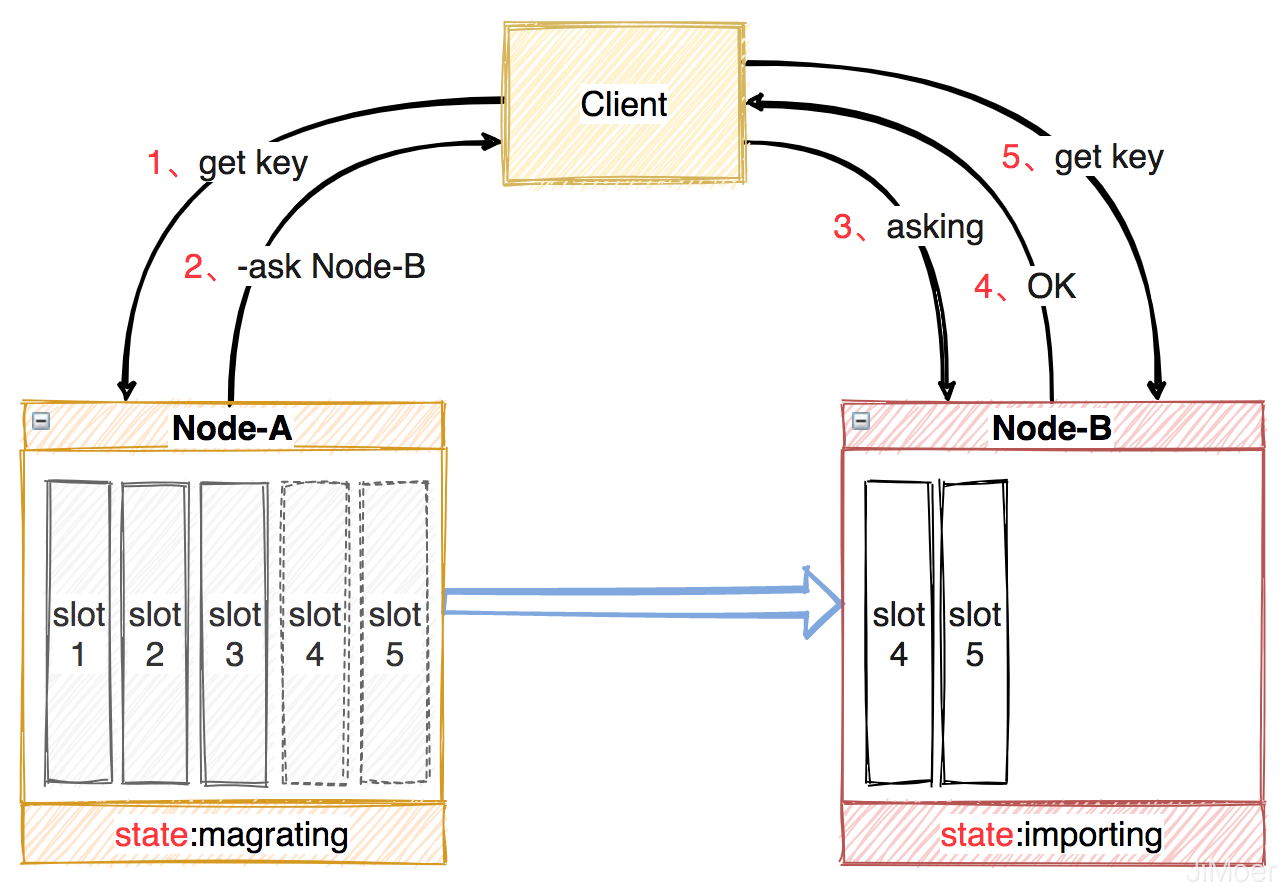
容错
Redis Cluster可以为每个主节点设置多个从节点,当单个主节点挂掉后,集群会自动将其中某个从节点提升为主节点,若没有从节点,那么集群将处于不可用状态。
Redis提供了一个参数:cluster-require-full-coverage,用来配置可以允许部分节点出问题后,还有其他节点在运行时可以正常提供服务。
另外一点比较特殊的是,Cluster中当一个节点发现某个其他节点出现失联了,这个时候问题节点只是PFail(Possibly-可能下线),然后它会把这个失联信息广播给其他节点,当一个节点接收到某个节点的失联信息达到集群的大多数时,就可以将失联节点标记为下线,然后将下线信息广播给其他节点。若失联节点为主节点,那么将立即对该节点进行主从切换。
Redis高可用就先说到这里吧,后面其实还有Codis,但是目前Cluster逐渐流行起来了,Codis的竞争力逐渐被蚕食,而且对新版本的支持,更新的也比较慢,所以这里就不说它了,感兴趣的可以自己去了解一下,国人开源的Redis集群模式Codis。
持久化
Redis持久化的意义在于,当出现宕机问题后,能将数据恢复到缓存中,它提供了两种持久化机制:一种是快照(RDB),一种是AOF日志。
快照是一次全量备份,而AOF是增量备份。快照是内存数据的二进制序列化形式,存储上非常紧凑,而AOF日志记录的是内存数据修改的指令记录文本。
快照备份(RDB)
因为Redis是单线程的,所以在做快照持久化的时候,通常有两个选择,save命令,会阻塞线程,直到备份完成;bgsave会异步的执行备份,其实是fork出了一个子进程,用子进程去执行快照持久化操作,将数据保存在一个.rdb文件中。
子进程刚刚产生的时候,是和父进程共享内存中的数据的,但是子进程做持久化时,是不会修改数据的,而父进程是要持续提供服务的,所以父进程就会持续的修改内存中的数据,这个时候父进程就会将内存中的数据,Copy出一份来进行修改。
父进程copy的数据是以数据页为单位的(4k一页),对那一页数据进行修改就copy哪一页的数据。
子进程由于数据没有变化就会一直的去遍历数据,进程持久化操作了,这就是只保留了创建子进程的时候的快照。
那么RDB是在什么时候触发的呢?
# save <seconds> <changes>
save 60 10000
save 300 10
上这段配置就是在redis.conf文件中配置的,第一个参数是时间单位是秒,第二个参数执行数据变化的次数。
意思就是说:300秒之内至少发生10次写操作、
60秒之内发生至少10000次写操作,只要满足任一条件,均会触发bgsave
增量日志备份(AOF)
Redis在接收到客户端请求指令后,会先进行校验,校验成功后,立即将指令存储到AOF日志文件中,就是说,Redis是先记录日志,再执行命令。这样即使命令还没执行突然宕机了,通过AOF日志文件也是可以恢复的。
AOF重写
AOF日志文件,随着时间的推移,会越来越大,所以就需要进行重写瘦身。AOF重写的原理就是,fork一个子进程,对内存进行遍历,然后生成一系列的Redis指令,然后序列化到一个新的aof文件中。然后再将遍历内存阶段的增量日志,追加到新的aof文件中,追加完成后立即替换旧的aof文件,这样就完成了AOF的瘦身重写。
fsync
因为AOF是一个写文件的IO操作,是比较耗时。所以AOF日志并不是直接写入到日志文件的,而是先写到一个内核的缓存中,然后通过异步刷脏,来将数据保存到磁盘的。
由于这个情况,就导致了会有还没来得急刷脏然后就宕机了,导致数据丢失的风险。
所以Redis提供了一个配置,可以手动的来选择刷脏的频率。
- always:每一条AOF记录都立即同步到文件,性能很低,但较为安全。
- everysec:每秒同步一次,性能和安全都比较中庸的方式,也是redis推荐的方式。如果遇到物理服务器故障,可能导致最多1秒的AOF记录丢失。
- no:Redis永不直接调用文件同步,而是让操作系统来决定何时同步磁盘。性能较好,但很不安全。
AOF默认是关闭的,需要在配置文件中手动开启。
# 只有在“yes”下,aof重写/文件同步等特性才会生效
appendonly yes
## 指定aof文件名称
appendfilename appendonly.aof
## 指定aof操作中文件同步策略,有三个合法值:always everysec no,默认为everysec
appendfsync everysec
## 在aof-rewrite期间,appendfsync是否暂缓文件同步,"no"表示“不暂缓”,“yes”表示“暂缓”,默认为“no”
no-appendfsync-on-rewrite no
## aof文件rewrite触发的最小文件尺寸(mb,gb),只有大于此aof文件大于此尺寸是才会触发rewrite,默认“64mb”,建议“512mb”
auto-aof-rewrite-min-size 64mb
Redis4.0混合持久化
Redis4.0提供了一种新的持久化机制,就是RDB和AOF结合使用,将rdb文件内容和aof文件存在一起,AOF中保存的不再是全部数据了,而是从RDB开始的到结束的增量日志。
这样在Redis恢复数据的时候,可以先假装RDB文件中的内容,然后在顺序执行AOF日志中指令,这样就将Redis重启时恢复数据的效率得到了大幅度提升。
结尾
恩,这次就先总结到这里吧,后面会继续总结Redis相关知识,LRU、LFU、内存淘汰策略,管道等等。
你说一下Redis为什么快吧,怎么实现高可用,还有持久化怎么做的?的更多相关文章
- Redis高可用(持久化、主从复制、哨兵、集群)
Redis高可用(持久化.主从复制.哨兵.集群) 目录 Redis高可用(持久化.主从复制.哨兵.集群) 一.Redis高可用 1. Redis高可用概述 2. Redis高可用策略 二.Redis持 ...
- 使用redis实现程序或者服务的高可用
使用redis实现程序或者服务的高可用,就是将某一程序或服务部署在不同服务器上,或者是跨机房部署,当运行服务的服务器挂了之后,其他服务器上的该服务能立马顶上,这里我简单的使用redis实现这一目的. ...
- Redis 高可用之"持久化"
Redis高可用概述 在Redis中,实现高可用的技术主要包括:持久化.复制(读写分离).哨兵.集群. 持久化: 持久化是最简单的高可用方法(有时甚至不被归为高可用手段),主要作用是数据备份,即将数据 ...
- Redis主从复制、多实例、高可用(三)--技术流ken
Redis主从复制 在开始实现redis的高可用之前,首先来学习一下如何实现redis的主从复制,毕竟高可用也会依赖主从复制的技术. Redis的主从复制,可以实现一个主节点master可以有多个从节 ...
- redis详解(四)-- 高可用分布式集群
一,高可用 高可用(High Availability),是当一台服务器停止服务后,对于业务及用户毫无影响. 停止服务的原因可能由于网卡.路由器.机房.CPU负载过高.内存溢出.自然灾害等不可预期的原 ...
- Redis Sentinel(哨兵)主从高可用方案
环境搭建 三台服务器: 192.168.126.100(master) 192.168.126.110(slaver) 192.168.126.120(slaver) 拷贝192.168.126.10 ...
- Redis主从复制、多实例、高可用
Redis主从复制 在开始实现redis的高可用之前,首先来学习一下如何实现redis的主从复制,毕竟高可用也会依赖主从复制的技术. Redis的主从复制,可以实现一个主节点master可以有多个从节 ...
- Redis 学习笔记(五)高可用之主从模式
上一节提到了 Redis 的持久性,也就是在服务器实例宕机或故障时,拥有再恢复的能力.但是在这个服务器实例宕机恢复期间,是无法接受新的数据请求.对于整体服务而言这是无法容忍的,因此我们可以使用多个服务 ...
- CYQ.Data 对于分布式缓存Redis、MemCache高可用的改进及性能测试
背景: 随着.NET Core 在 Linux 下的热动,相信动不动就要分布式或集群的应用的需求,会慢慢火起来. 所以这段时间一直在研究和思考分布式集群的问题,同时也在思考把几个框架的思维相对提升到这 ...
- Redis(1.7)Redis高可用架构(理论篇)
[0]常用架构种类 (0.1)单机Redis (0.2)单纯的Redis主从复制 (0.3)哨兵Sentinel+Redis主从复制集群(实现高可用自动故障转移) (0.4)Redis Cluster ...
随机推荐
- 一枚程序猿的MacBook M1详细体验报告
前言 2020年11月11日双十一上午,苹果发布了M1芯片的新款Mac,其最大的变化就是将处理器从Intel换成了苹果自研的ARM芯片M1. 上一次苹果更换Mac芯片要追溯到2006年,14年前,苹果 ...
- AndroidStudio中获得的VersionCode一直为1和VersionName一直为1.0
因为AndroidStudio把versionCode和versionName的维护放到了build.gradle中.
- shiro利用过期时间,解决用户冻结踢出问题
背景 shiro中需要冻结某个用户,但是此时此刻这个用户在线,如果冻结只是改变状态的话,只会导致用户不满,所以要改变这个办法. 在查找过程中发现都是告诉shiro写自定义过滤器,那么我如果自定义过滤器 ...
- Django----短信验证接口
1.注册荣联云账号 1.1注册账号 1.2 登录即可看到开发者账号信息 1.3 添加测试账号 2.使用容联云发送代码测试 '''1. 安装容联云sdk''' pip install ronglian_ ...
- 大数据-redis-redis启动出错
redis启动出错Creating Server TCP listening socket 127.0.0.1:6379: bind: No error 解决方法(1) 首先如果你是从官方redis官 ...
- 老猿学5G:融合计费基于QoS流计费QBC的触发器Triggers
☞ ░ 前往老猿Python博文目录 ░ 一.引言 SMF中的功能体CTF在用户上网时达到一定条件就会向CHF上报流量,而CTF什么时候触发流量上报是由CTF中的触发器来控制的.在<老猿学5G: ...
- Python的富比较方法__lt__、__gt__之间的关联关系分析
Python的富比较方法包括__lt__.__gt__分别表示:小于.大于,对应的操作运算符为:"<".">".那么是否象普通数字运算一样,这两个方 ...
- PyQt(Python+Qt)学习随笔:QListWidget对项进行排序的sortItems方法
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 QListWidget的sortItems方法用于对列表部件中所有项按参数进行排序,相关调用语法如下 ...
- SpringCloud-服务间通信方式
接下来在整个微服务架构中,我们比较关心的就是服务间的服务改如何调用,有哪些调用方式? 总结:在springcloud中服务间调用方式主要是使用 http restful方式进行服务间调用 1. 基于R ...
- 半夜删你代码队 Day5冲刺
一.每日站立式会议 1.站立式会议 成员 昨日完成工作 今日计划工作 遇到的困难 陈惠霖 跟进作业 完成注册界面 相关界面设计内容知识不充足 侯晓龙 开始双人合作 开始与数据库结合 无 周楚池 初步完 ...