Spark源码分析 – Shuffle
参考详细探究Spark的shuffle实现, 写的很清楚, 当前设计的来龙去脉
Hadoop
Hadoop的思路是, 在mapper端每次当memory buffer中的数据快满的时候, 先将memory中的数据, 按partition进行划分, 然后各自存成小文件, 这样当buffer不断的spill的时候, 就会产生大量的小文件
所以Hadoop后面直到reduce之前做的所有的事情其实就是不断的merge, 基于文件的多路并归排序, 在map端的将相同partition的merge到一起, 在reduce端, 把从mapper端copy来的数据文件进行merge, 以用于最终的reduce
多路并归排序, 达到两个目的
merge, 把相同key的value都放到一个arraylist里面
sort, 最终的结果是按key排序的
这个方案扩展性很好, 面对大数据也没有问题, 当然问题在效率, 毕竟需要多次进行基于文件的多路并归排序, 多轮的和磁盘进行数据读写……
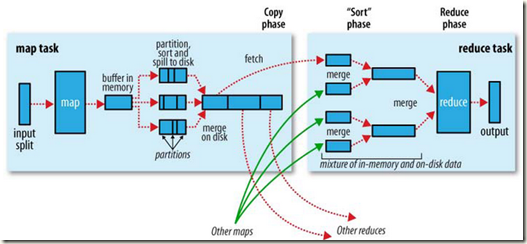
Spark
Spark的优势在于效率, 所以没有做merge sort, 这样省去多次磁盘读写
当然这样会有扩展性问题, 很难两全,
因为不能后面再merge, 所以在写的时候, 需要同时打开corenum * bucketnum个文件, 写完才能关闭
并且在reduce的时候, 由于之前没有做merge, 所以必须在内存里面维护所有key的hashmap, 实时的merge和reduce, 详细参考下面
写
如何将shuffle数据写入block, 关键看ShuffleMapTask中的逻辑
可用看到使用shuffleBlockManager, Spark从0.8开始将shuffleBlockManager从普通的BlockManager中分离出来, 便于优化
ShuffleMapTask
// Obtain all the block writers for shuffle blocks.
val ser = SparkEnv.get.serializerManager.get(dep.serializerClass)
shuffle = blockManager.shuffleBlockManager.forShuffle(dep.shuffleId, numOutputSplits, ser) // 创建ShuffleBlocks, 参数是shuffleId和目标partitions数目
buckets = shuffle.acquireWriters(partition) // 生成ShuffleWriterGroup, shuffle目标buckets(对应于partition) // Write the map output to its associated buckets.
for (elem <- rdd.iterator(split, taskContext)) { // 从RDD中取出每个elem数据
val pair = elem.asInstanceOf[Product2[Any, Any]]
val bucketId = dep.partitioner.getPartition(pair._1) // 根据pair的key进行shuffle, 得到目标bucketid
buckets.writers(bucketId).write(pair) // 将pair数据写入bucket.writer (BlockObjectWriter)
} // Commit这些buckets到block, 其他的RDD会从通过shuffleid找到这些block, 并读取数据
// Commit the writes. Get the size of each bucket block (total block size).
var totalBytes = 0L
val compressedSizes: Array[Byte] = buckets.writers.map { writer: BlockObjectWriter =>
writer.commit()
writer.close()
val size = writer.size()
totalBytes += size
MapOutputTracker.compressSize(size)
}
ShuffleBlockManager
ShuffleBlockManager的核心函数就是forShuffle, 这个函数返回ShuffleBlocks对象
ShuffleBlocks对象的函数acquireWriters, 返回ShuffleWriterGroup, 其中封装所有partition所对应的BlockObjectWriter
这里的问题是,
由于Spark的调度是基于task的, task其实对应于partition
如果有m个partitions, 而需要shuffle到n个partition上, 其实就是m个mapper task和n个reducer task
当然在spark中不可能所有的mapper task一起运行, task的并行度取决于core number
1. 如果每个mapper task都要产生n个files, 那么最终产生的文件数就是n*m, 文件数过多...
在Spark 0.8.1中已经优化成使用shuffle consolidation, 即多个mapper task公用一个bucket文件, 怎么公用?
取决于并行度, 因为并行的task是无法公用一个bucket文件的, 所以至少会产生corenum * bucketnum个文件, 而后面被执行的task就可以重用前面创建的bucketfile, 而不用重新创建
2. 在打开文件写的时候, 每个文件的write handler默认需要100KB内存缓存, 所以同时需要corenum * bucketnum * 100kb大小的内存消耗, 这个问题还没有得到解决
其实就是说spark在shuffle的时候碰到了扩展性问题, 这个问题为什么Hadoop没有碰到?
因为hadoop可用容忍多次的磁盘读写, 多次的文件merge, 所以它可以在每次从buffer spill的时候, 把内容写到一个新的文件中, 然后后面再去做文件merge
private[spark]
class ShuffleWriterGroup(val id: Int, val writers: Array[BlockObjectWriter])
private[spark]
trait ShuffleBlocks {
def acquireWriters(mapId: Int): ShuffleWriterGroup
def releaseWriters(group: ShuffleWriterGroup)
} private[spark]
class ShuffleBlockManager(blockManager: BlockManager) { def forShuffle(shuffleId: Int, numBuckets: Int, serializer: Serializer): ShuffleBlocks = {
new ShuffleBlocks {
// Get a group of writers for a map task.
override def acquireWriters(mapId: Int): ShuffleWriterGroup = {
val bufferSize = System.getProperty("spark.shuffle.file.buffer.kb", "100").toInt * 1024
val writers = Array.tabulate[BlockObjectWriter](numBuckets) { bucketId => // 根据需要shuffle的partition数目创建writers
val blockId = ShuffleBlockManager.blockId(shuffleId, bucketId, mapId) // blockid = "shuffle_" + shuffleId + "_" + mapId + "_" + bucketId
blockManager.getDiskBlockWriter(blockId, serializer, bufferSize) // 从blockManager得到DiskBlockWriter
}
new ShuffleWriterGroup(mapId, writers)
} override def releaseWriters(group: ShuffleWriterGroup) = {
// Nothing really to release here.
}
}
}
}
读
PairRDDFunctions.combineByKey
关于这部分参考, Spark源码分析 – PairRDD
关键的一点是, 在reduce端的处理中 (可以看没有mapSideCombine的部分, 更清晰一些)
mapPartitions其实是使用的MapPartitionsRDD, 即对于每个item调用aggregator.combineValuesByKey
可以看到这里和Hadoop最大的不同是, Hadoop在reduce时得到的是一个key已经merge好的集合, 所以一次性reduce处理完后, 就可以直接存掉了
而Spark没有merge这块, 所以数据是一个个来的, 所以你必须在内存里面维持所有的key的hashmap, 这里就可能有扩展性问题, Spark在PR303中实现外部排序的方案来应对这样的问题
//RDD本身的partitioner和传入的partitioner相等时, 即不需要重新shuffle, 直接map即可
if (self.partitioner == Some(partitioner)) {
self.mapPartitions(aggregator.combineValuesByKey, preservesPartitioning = true) //2. mapPartitions, map端直接调用combineValuesByKey
} else if (mapSideCombine) { //如果需要mapSideCombine
val combined = self.mapPartitions(aggregator.combineValuesByKey, preservesPartitioning = true) //先在partition内部做mapSideCombine
val partitioned = new ShuffledRDD[K, C, (K, C)](combined, partitioner).setSerializer(serializerClass) //3. ShuffledRDD, 进行shuffle
partitioned.mapPartitions(aggregator.combineCombinersByKey, preservesPartitioning = true) //Shuffle完后, 在reduce端再做一次combine, 使用combineCombinersByKey
} else {
// Don't apply map-side combiner.和上面的区别就是不做mapSideCombine
val values = new ShuffledRDD[K, V, (K, V)](self, partitioner).setSerializer(serializerClass)
values.mapPartitions(aggregator.combineValuesByKey, preservesPartitioning = true)
}
ShuffledRDD
override def compute(split: Partition, context: TaskContext): Iterator[P] = {
val shuffledId = dependencies.head.asInstanceOf[ShuffleDependency[K, V]].shuffleId
SparkEnv.get.shuffleFetcher.fetch[P](shuffledId, split.index, context.taskMetrics, //使用shuffleFetcher.fetch得到shuffle过数据的iterator
SparkEnv.get.serializerManager.get(serializerClass))
}
ShuffleFetcher
从mapOutputTracker查询到(根据shuffleId, reduceId)需要读取的shuffle partition的地址
然后从blockManager获取所有这写block的fetcher的iterator
private[spark] abstract class ShuffleFetcher {
/**
* Fetch the shuffle outputs for a given ShuffleDependency.
* @return An iterator over the elements of the fetched shuffle outputs.
*/
def fetch[T](shuffleId: Int, reduceId: Int, metrics: TaskMetrics, // reduceId, 就是reduce端的partitionid
serializer: Serializer = SparkEnv.get.serializerManager.default): Iterator[T]
/** Stop the fetcher */
def stop() {}
}
private[spark] class BlockStoreShuffleFetcher extends ShuffleFetcher with Logging {
override def fetch[T](shuffleId: Int, reduceId: Int, metrics: TaskMetrics, serializer: Serializer)
: Iterator[T] =
{
val blockManager = SparkEnv.get.blockManager
val statuses = SparkEnv.get.mapOutputTracker.getServerStatuses(shuffleId, reduceId) // 从mapOutputTracker获取shuffleid的Array[MapStatus]
val splitsByAddress = new HashMap[BlockManagerId, ArrayBuffer[(Int, Long)]] // 由于有多个map在同一个node上, 有相同的BlockManagerId, 需要合并
for (((address, size), index) <- statuses.zipWithIndex) { // 这里index指,在map端的partitionid
splitsByAddress.getOrElseUpdate(address, ArrayBuffer()) += ((index, size)) // {BlockManagerId,((mappartitionid, size),…)}
}
val blocksByAddress: Seq[(BlockManagerId, Seq[(String, Long)])] = splitsByAddress.toSeq.map { // (BlockManagerId, (blockfile地址, size))
case (address, splits) =>
(address, splits.map(s => ("shuffle_%d_%d_%d".format(shuffleId, s._1, reduceId), s._2))) // 可以看到blockfile地址,由shuffleId, mappartitionid, reduceId决定
}
val blockFetcherItr = blockManager.getMultiple(blocksByAddress, serializer) // Iterator of (block ID, value)
val itr = blockFetcherItr.flatMap(unpackBlock) // unpackBlock会拆开(block ID, value)取出value, 以生成最终获取到数据的iterater CompletionIterator[T, Iterator[T]](itr, { // 和普通Iterator的区别是,迭代完时, 会调用后面的completion逻辑
val shuffleMetrics = new ShuffleReadMetrics
shuffleMetrics.shuffleFinishTime = System.currentTimeMillis
shuffleMetrics.remoteFetchTime = blockFetcherItr.remoteFetchTime
shuffleMetrics.fetchWaitTime = blockFetcherItr.fetchWaitTime
shuffleMetrics.remoteBytesRead = blockFetcherItr.remoteBytesRead
shuffleMetrics.totalBlocksFetched = blockFetcherItr.totalBlocks
shuffleMetrics.localBlocksFetched = blockFetcherItr.numLocalBlocks
shuffleMetrics.remoteBlocksFetched = blockFetcherItr.numRemoteBlocks
metrics.shuffleReadMetrics = Some(shuffleMetrics)
})
}
private def convertMapStatuses(
shuffleId: Int,
reduceId: Int,
statuses: Array[MapStatus]): Array[(BlockManagerId, Long)] = {
assert (statuses != null)
statuses.map {
status =>
if (status == null) {
throw new FetchFailedException(null, shuffleId, -1, reduceId,
new Exception("Missing an output location for shuffle " + shuffleId))
} else {
(status.location, decompressSize(status.compressedSizes(reduceId))) // 关键转化就是, 将decompressSize只取该reduce partition的部分
}
}
}
}
Shuffle信息注册 - MapOutputTracker
前面有个问题没有说清楚, 当shuffle完成后, reducer端的task怎么知道应该从哪里获取当前partition所需要的所有shuffled blocks
在Hadoop中是通过JobTracker, Mapper会通过Hb告诉JobTracker执行的状况, Reducer不断的去询问JobTracker, 并知道需要copy哪些HDFS文件
而在Spark中就通过将shuffle信息注册到MapOutputTracker
MapOutputTracker
首先每个节点都可能需要查询shuffle信息, 所以需要MapOutputTrackerActor用于通信
参考SparkContext中的逻辑, 只有在master上才创建Actor对象, 其他slaver上只是创建Actor Ref
private[spark] class MapOutputTrackerActor(tracker: MapOutputTracker) extends Actor with Logging {
def receive = {
case GetMapOutputStatuses(shuffleId: Int, requester: String) => // 提高用于查询shuffle信息的接口
logInfo("Asked to send map output locations for shuffle " + shuffleId + " to " + requester)
sender ! tracker.getSerializedLocations(shuffleId)
case StopMapOutputTracker =>
logInfo("MapOutputTrackerActor stopped!")
sender ! true
context.stop(self)
}
}
注意, 只有master上的MapOutputTracker会有所有的最新shuffle信息
但是对于slave, 出于效率考虑, 也会buffer从master得到的shuffle信息, 所以getServerStatuses中会先在local的mapStatuses取数据, 如果没有, 再取remote的master上获取
private[spark] class MapOutputTracker extends Logging {
var trackerActor: ActorRef = _ // MapOutputTrackerActor
private var mapStatuses = new TimeStampedHashMap[Int, Array[MapStatus]] // 用于buffer所有的shuffle信息
def registerShuffle(shuffleId: Int, numMaps: Int) { // 注册shuffle id, 初始化Array[MapStatus]
if (mapStatuses.putIfAbsent(shuffleId, new Array[MapStatus](numMaps)).isDefined) {
throw new IllegalArgumentException("Shuffle ID " + shuffleId + " registered twice")
}
}
def registerMapOutput(shuffleId: Int, mapId: Int, status: MapStatus) { // 当task完成时, 注册MapOutput信息
var array = mapStatuses(shuffleId)
array.synchronized {
array(mapId) = status
}
}
// Remembers which map output locations are currently being fetched on a worker
private val fetching = new HashSet[Int]
// Called on possibly remote nodes to get the server URIs and output sizes for a given shuffle
def getServerStatuses(shuffleId: Int, reduceId: Int): Array[(BlockManagerId, Long)] = {
val statuses = mapStatuses.get(shuffleId).orNull
if (statuses == null) { // local的mapStatuses中没有
logInfo("Don't have map outputs for shuffle " + shuffleId + ", fetching them")
var fetchedStatuses: Array[MapStatus] = null
fetching.synchronized {
if (fetching.contains(shuffleId)) { // 已经在fetching中, 所以只需要wait
// Someone else is fetching it; wait for them to be done
while (fetching.contains(shuffleId)) {
try {
fetching.wait()
} catch {
case e: InterruptedException =>
}
}
} // Either while we waited the fetch happened successfully, or
// someone fetched it in between the get and the fetching.synchronized.
fetchedStatuses = mapStatuses.get(shuffleId).orNull
if (fetchedStatuses == null) {
// We have to do the fetch, get others to wait for us.
fetching += shuffleId // 如果还没有就加到fetching, 继续fetching
}
} if (fetchedStatuses == null) {
// We won the race to fetch the output locs; do so
val hostPort = Utils.localHostPort()
// This try-finally prevents hangs due to timeouts:
try {
val fetchedBytes =
askTracker(GetMapOutputStatuses(shuffleId, hostPort)).asInstanceOf[Array[Byte]] // 从remote master上fetching
fetchedStatuses = deserializeStatuses(fetchedBytes)
logInfo("Got the output locations")
mapStatuses.put(shuffleId, fetchedStatuses) // 把结果buffer到local
} finally {
fetching.synchronized {
fetching -= shuffleId
fetching.notifyAll()
}
}
}
if (fetchedStatuses != null) {
fetchedStatuses.synchronized {
return MapOutputTracker.convertMapStatuses(shuffleId, reduceId, fetchedStatuses)
}
}
else{
throw new FetchFailedException(null, shuffleId, -1, reduceId,
new Exception("Missing all output locations for shuffle " + shuffleId))
}
} else { // 在local找到, 直接返回
statuses.synchronized {
return MapOutputTracker.convertMapStatuses(shuffleId, reduceId, statuses)
}
}
}
注册
注册工作都是在master上的DAGScheduler完成的
Spark中是以shuffleid来标识每个shuffle, 不同于Hadoop, 一个job中可能有多个shuffle过程, 所以无法通过jobid
分两步来注册,
1. 在new stage的时候, 需要注册shuffleid, 由于new stage一定是由于遇到shuffleDep
private def newStage(
rdd: RDD[_],
shuffleDep: Option[ShuffleDependency[_,_]],
jobId: Int,
callSite: Option[String] = None)
: Stage =
{
if (shuffleDep != None) {
// Kind of ugly: need to register RDDs with the cache and map output tracker here
// since we can't do it in the RDD constructor because # of partitions is unknown
mapOutputTracker.registerShuffle(shuffleDep.get.shuffleId, rdd.partitions.size) // 注册shuffleid和map端RDD的partitions数目
}
2. 在handle TaskCompletion事件的时候, 当一个ShuffleMapTask完成的时候, 即mapOutput产生的时候, 就可以注册MapStatus(BlockManagerId, compressedSizes)
通过BlockManagerId+partitionid+reduceid就可以知道blockid, 从而读到数据
private def handleTaskCompletion(event: CompletionEvent) {
event.reason match {
case Success =>
task match {
case rt: ResultTask[_, _] =>
case smt: ShuffleMapTask =>
val status = event.result.asInstanceOf[MapStatus] // 在ShuffleTask的run的返回值本身就是MapStatus, 所以这里做下类型转换
val execId = status.location.executorId // class MapStatus(var location: BlockManagerId, var compressedSizes: Array[Byte])
if (failedEpoch.contains(execId) && smt.epoch <= failedEpoch(execId)) {
logInfo("Ignoring possibly bogus ShuffleMapTask completion from " + execId)
} else {
stage.addOutputLoc(smt.partition, status) // 把MapStatus buffer到stage中outputLocs上去
}
if (stage.shuffleDep != None) {
// We supply true to increment the epoch number here in case this is a
// recomputation of the map outputs. In that case, some nodes may have cached
// locations with holes (from when we detected the error) and will need the
// epoch incremented to refetch them.
// TODO: Only increment the epoch number if this is not the first time
// we registered these map outputs.
mapOutputTracker.registerMapOutputs( // 注册到mapOutputTracker中的mapStatuses上
stage.shuffleDep.get.shuffleId,
stage.outputLocs.map(list => if (list.isEmpty) null else list.head).toArray,
changeEpoch = true)
}
Spark源码分析 – Shuffle的更多相关文章
- Spark源码分析 – 汇总索引
http://jerryshao.me/categories.html#architecture-ref http://blog.csdn.net/pelick/article/details/172 ...
- Spark 源码分析 -- task实际执行过程
Spark源码分析 – SparkContext 中的例子, 只分析到sc.runJob 那么最终是怎么执行的? 通过DAGScheduler切分成Stage, 封装成taskset, 提交给Task ...
- Spark源码分析 – BlockManager
参考, Spark源码分析之-Storage模块 对于storage, 为何Spark需要storage模块?为了cache RDD Spark的特点就是可以将RDD cache在memory或dis ...
- Spark源码分析 – DAGScheduler
DAGScheduler的架构其实非常简单, 1. eventQueue, 所有需要DAGScheduler处理的事情都需要往eventQueue中发送event 2. eventLoop Threa ...
- Spark源码分析 – Dependency
Dependency 依赖, 用于表示RDD之间的因果关系, 一个dependency表示一个parent rdd, 所以在RDD中使用Seq[Dependency[_]]来表示所有的依赖关系 Dep ...
- Spark源码分析之九:内存管理模型
Spark是现在很流行的一个基于内存的分布式计算框架,既然是基于内存,那么自然而然的,内存的管理就是Spark存储管理的重中之重了.那么,Spark究竟采用什么样的内存管理模型呢?本文就为大家揭开Sp ...
- Spark源码分析之八:Task运行(二)
在<Spark源码分析之七:Task运行(一)>一文中,我们详细叙述了Task运行的整体流程,最终Task被传输到Executor上,启动一个对应的TaskRunner线程,并且在线程池中 ...
- Spark源码分析之六:Task调度(二)
话说在<Spark源码分析之五:Task调度(一)>一文中,我们对Task调度分析到了DriverEndpoint的makeOffers()方法.这个方法针对接收到的ReviveOffer ...
- Spark源码分析之五:Task调度(一)
在前四篇博文中,我们分析了Job提交运行总流程的第一阶段Stage划分与提交,它又被细化为三个分阶段: 1.Job的调度模型与运行反馈: 2.Stage划分: 3.Stage提交:对应TaskSet的 ...
随机推荐
- 每日英语:Who Ruined The Humanities?
You've probably heard the baleful reports. The number of college students majoring in the humanities ...
- jMiniLang设计思路
前言 项目地址:https://github.com/bajdcc/jMiniLang 演示视频:https://www.bilibili.com/video/av13294962 jMiniLang ...
- VBOX Ubuntu设置与Windows的共享文件夹
参考资料: http://jingyan.baidu.com/article/2fb0ba40541a5900f2ec5f07.html http://zycao.com/virtualbox-ubu ...
- Pyhton 列表转字典
1.一个list 2.两个list
- linux查看匹配内容的前后几行(转)
linux系统中,利用grep打印匹配的上下几行 如果在只是想匹配模式的上下几行,grep可以实现. $grep -5 'parttern' inputfile //打印匹配行的前后5行 ...
- Spring MVC添加支持Http的delete、put请求!(HiddenHttpMethodFilter)
浏览器form表单只支持GET与POST请求,而DELETE.PUT等method并不支持,spring3.0添加了一个过滤器,可以将这些请求转换为标准的http方法,使得支持GET.POST.PUT ...
- [Shell Script]关于source和sh对于脚本执行不同
当我修改了/etc/profile文件,我想让它立刻生效,而不用重新登录:这时就想到用source命令,如:source /etc/profile对source进行了学习,并且用它与sh 执行脚本进行 ...
- gpio 灯的对应关系
1 点灯验证通过: GPIO160 TX1-LED GPIO161 RX1-LED GPIO163 TX2-LED GPIO164 RX2-LED GPIO ...
- AtomicReference与volatile的区别
首先volatile是java中关键字用于修饰变量,AtomicReference是并发包java.util.concurrent.atomic下的类.首先volatile作用,当一个变量被定义为vo ...
- 重启php
注意这是重启php,不是重启apache service php-fpm restart