jupter nootbok 快捷键、NumPy模块、Pandas模块初识
jupter nootbok 快捷键
- 插入cell:a b
- 删除cell:x
- cell模式的切换:m:Markdown模式 y:code模式
- 运行cell:shift+enter
- tab:补全
- shift+tab:打开帮助文档
NumPy
NumPy(Numerical Python) 是 Python 语言的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
一、创建ndarray
- 1. 使用np.array()创建
- 一维数据创建
- import numpy as np
- np.array([1,2,3,4,5],dtype=int)
- 二维数组创建
- np.array([[1,2,3],[4,5,6],[7.7,8,9]])
注意:
numpy默认ndarray的所有元素的类型是相同的
如果传进来的列表中包含不同的类型,则统一为同一类型,优先级:str>float>int
使用matplotlib.pyplot获取一个numpy数组,数据来源于一张图片
- import matplotlib.pyplot as plt
- img_arr = plt.imread('bobo.jpg')#当前目录下的图片
- plt.imshow(img_arr)
- img.shape
- #(626, 413, 3)#前面两个数字表示像素,最后一个表示颜色
使用np的routines函数创建数组
- 包含以下常见创建方法:
- 1) np.ones(shape, dtype=None, order='C')
- np.ones(shape=(4,5),dtype=float)#默认为1
- np.zeros(shape, dtype=None, order='C')#默认为0
- np.full(shape, fill_value, dtype=None, order='C')
- np.full(shape=(6,7),fill_value=999)
- np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None) 等差数列
- np.linspace(0,100,20)#返回20个数,等差是5的一维数组
- np.arange([start, ]stop, [step, ]dtype=None)
- arr1 = np.arange(3,10,2) #3是开始,10是结束,2是步长 的一维数组
- np.random.seed(10)#固定时间因子
- np.random.randint(0,100,size=(3,4))#产生的随机数固定
- array([[ 9, 15, 64, 28],
- [89, 93, 29, 8],
- [73, 0, 40, 36]])
注意:只有arange和linspace产生一维数组,其他的都可产生一维或者多维数组
ndarray的属性
- 4个必记参数: ndim:维度 shape:形状(各维度的长度) size:总长度 dtype:元素类型
ndarray的基本操作
- 1. 索引
- 一维与列表完全一致 多维时同理
- np.random.seed(1)
- arr = np.random.randint(0,100,size=(5,5))
- #根据索引修改数据
- arr[1][2] = 6666444
- #获取二维数组前两行
- arr[0:2]
- #获取二维数组前两列
- arr[:,0:2]
- #获取二维数组前两行和前两列数据
- arr[0:2,0:2]
- #将数组的行倒序
- arr[::-1]
- #列倒序
- arr[:,::-1]
- #全部倒序
- arr[::-1,::-1]
- #将图片进行全倒置操作
- plt.imshow(img_arr[::-1,::-1,::-1])
- 变形
- .将一维数组变形成多维数组
- array([[ 37, 12, 72, 9, 75],
- [ 5, 79, 6666444, 16, 1],
- [ 76, 71, 6, 25, 50],
- [ 20, 18, 84, 11, 28],
- [ 29, 14, 50, 68, 87]])
- arr.shape
- (5, 5)
使用arr.reshape()函数,注意参数是一个tuple!数组元素变形前后要统一!
- a.reshape((5,-1)) #-1表示的是自动计算行或列
- array([[ 37, 12, 72, 9, 75],
- [ 5, 79, 9999, 16, 1],
- [ 76, 71, 6, 25, 50],
- [ 20, 18, 84, 11, 28],
- [ 29, 14, 50, 68, 87]])
- 将多维数组变形成一维数组
- a = arr.reshape((25,))
- a.shape
- (25,)
- 图片倒置
- img_arr.shape
- (626, 413, 3)
- img_arr.size
- 775614
- #将原数据三维数组变形成一维数组
- arr_1 = img_arr.reshape((775614,))
- #将arr_1元素倒置
- arr_1 = arr_1[::-1]
- #将arr_1变形成三维数组
- a_img = arr_1.reshape((626, 413, 3))
- plt.imshow(a_img)
级联
- np.concatenate((arr,arr),axis=1) #0 纵轴 1 横轴
- 级联需要注意的点:
- 级联的参数是列表:一定要加中括号或小括号
- 维度必须相同
- 形状相符:在维度保持一致的前提下,如果进行横向(axis=1)级联,必须保证进行级联的数组行数保持一致。如果进行纵向(axis=0)级联,必须保证进行级联的数组列数保持一致。
- 可通过axis参数改变级联的方向
- np.vstack():在竖直方向上堆叠
- np.hstack():在水平方向上平铺
切分
- 与级联类似,三个函数完成切分工作:
- np.split(arr,行/列号,轴):参数2是一个列表类型
- plt.imshow(np.split(img,(400,),axis=0)[0])
- np.vsplit
- np.hsplit
副本
- 所有赋值运算不会为ndarray的任何元素创建副本。对赋值后的对象的操作也对原来的对象生效。
- 可使用copy()函数创建副本
- c_arr = arr.copy()
- c_arr[1][4] = 100100
ndarray的聚合操作
- 求和np.sum
- arr.sum(axis=1)#求行的和
- 最大最小值:np.max/ np.min
- 平均值:np.mean()
- 其他聚合操作
- Function Name NaN-safe Version Description
- np.sum np.nansum Compute sum of elements
- np.prod np.nanprod Compute product of elements
- np.mean np.nanmean Compute mean of elements
- np.std np.nanstd Compute standard deviation
- np.var np.nanvar Compute variance
- np.min np.nanmin Find minimum value
- np.max np.nanmax Find maximum value
- np.argmin np.nanargmin Find index of minimum value
- np.argmax np.nanargmax Find index of maximum value
- np.median np.nanmedian Compute median of elements
- np.percentile np.nanpercentile Compute rank-based statistics of elements
- np.any N/A Evaluate whether any elements are true
- np.all N/A Evaluate whether all elements are true
- np.power 幂运算
广播机制
【重要】ndarray广播机制的三条规则:缺失维度的数组将维度补充为进行运算的数组的维度。缺失的数组元素使用已有元素进行补充。
规则一:为缺失的维度补1(进行运算的两个数组之间的维度只能相差一个维度)
规则二:缺失元素用已有值填充
规则三:缺失维度的数组只能有一行或者一列
- m = np.ones((2, 3))
- a = np.arange(3)
- display(m,a)
- array([[1., 1., 1.],
- [1., 1., 1.]])
- array([0, 1, 2])
- m+a
- array([[1., 2., 3.],
- [1., 2., 3.]])
ndarray的排序
- 快速排序
- np.sort()与ndarray.sort()都可以,但有区别:
- np.sort()不改变输入
- ndarray.sort()本地处理,不占用空间,但改变输入
Pandas的数据结构
1、Series
Series是一种类似与一维数组的对象,由下面两个部分组成:
values:一组数据(ndarray类型)
index:相关的数据索引标签
1)Series的创建
- import pandas as pd
- from pandas import Series,DataFrame
- import numpy as np
- 两种创建方式:
- (1) 由列表或numpy数组创建
- 默认索引为0到N-1的整数型索引
- #使用列表创建Series
- Series(data=[1,2,3,4,5],name='bobo')
- #使用numpy创建Series
- Series(data=np.random.randint(0,10,size=(5,)))
- #还可以通过设置index参数指定索引
- s = Series(data=np.random.randint(0,10,size=(5,)),index=['a','b','c','d','e'])
- 由字典创建:不能在使用index.但是依然存在默认索引
- dic = {
- '语文':100,
- '数学':90
- }
- s = Series(data=dic)
Series的索引和切片
可以使用中括号取单个索引(此时返回的是元素类型),或者中括号里一个列表取多个索引(此时返回的是一个Series类型)。
- (1) 显式索引:
- - 使用index中的元素作为索引值
- - 使用s.loc[](推荐):注意,loc中括号中放置的一定是显示索引
- 注意,此时是闭区间,能取到尾
- (2) 隐式索引:
- - 使用整数作为索引值
- - 使用.iloc[](推荐):iloc中的中括号中必须放置隐式索引
- 注意,此时是半开区间,取不到尾
- 切片:隐式索引切片和显示索引切片
- 显示索引切片:index和loc
- s['a':'d']
- s.loc['a':'c']
- 隐式索引切片:整数索引值和iloc
- s.iloc[0:3]
Series的基本概念
- 可以把Series看成一个定长的有序字典
- 向Series增加一行:相当于给字典增加一组键值对
- s['g'] = 10
- 可以通过shape,size,index,values等得到series的属性
- s.index
- s.values
- 可以使用s.head(),tail()分别查看前n个和后n个值
- s.head(3)
- 对Series元素进行去重
- s.unique() #返回的是一个ndarray
- 当索引没有对应的值时,可能出现缺失数据显示NaN(not a number)的情况
- 使得两个Series进行相加
- In [41]:
- s1 = Series([1,2,3],index=['a','b','c'])
- s2 = Series([1,2,3],index=['a','b','d'])
- s = s1+s2
- a 2.0
- b 4.0
- c NaN
- d NaN
- dtype: float64
- 可以使用pd.isnull(),pd.notnull(),或s.isnull(),notnull()函数检测缺失数据
- s.isnull()
- a False
- b False
- c True
- d True
- dtype: bool
- s.notnull()
- a True
- b True
- c False
- d False
- dtype: bool
- s[s.notnull()]#过滤掉空的数据
- a 2.0
- b 4.0
- dtype: float64
Series的运算
- (1) + - * /
(2) add() sub() mul() div()
(3) Series之间的运算- 在运算中自动对齐不同索引的数据
- 如果索引不对应,则补NaN
- s1 = Series([1,2,31,2],index=["a","d","s","r"])
- s2 = Series([11,2,2,3],index=["a","d","s","b"])
- s = s1+s2
- a 12.0
- b NaN
- d 4.0
- r NaN
- s 33.0
- dtype: float64
- s1.add(s2,fill_value=1)
- a 2.0
- b 4.0
- c 4.0
- d 4.0
- dtype: float64
DataFrame
DataFrame是一个【表格型】的数据结构。DataFrame由按一定顺序排列的多列数据组成。设计初衷是将Series的使用场景从一维拓展到多维。DataFrame既有行索引,也有列索引。
- 行索引:index
- 列索引:columns
- 值:values
DataFrame的创建
最常用的方法是传递一个字典来创建。DataFrame以字典的键作为每一【列】的名称,以字典的值(一个数组)作为每一列。
此外,DataFrame会自动加上每一行的索引。
使用字典创建的DataFrame后,则columns参数将不可被使用。
同Series一样,若传入的列与字典的键不匹配,则相应的值为NaN。
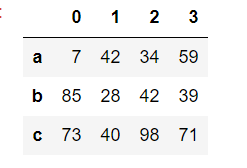
使用ndarray创建DataFrame
- DataFrame(data=np.random.randint(,,size=(,)),index=['a','b','c'])
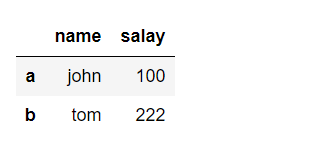
使用字典创建DataFrame
- dic={
- "name":["john","tom"],
- "salay":[100,222]
- }
- df = DataFrame(data=dic,index=["a","b"])
- df
DataFrame属性:values、columns、index、shape

DataFrame的索引
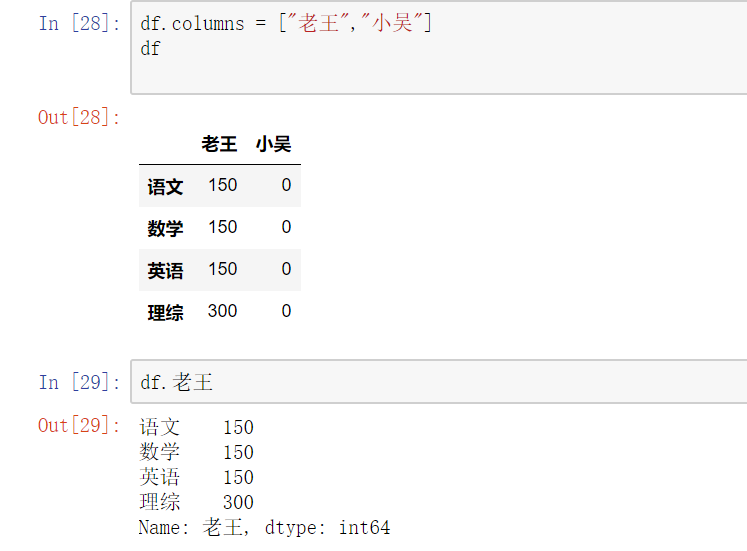
(1) 对列进行索引
- 通过类似字典的方式 df['q']- 通过属性的方式 df.q
可以将DataFrame的列获取为一个Series。返回的Series拥有原DataFrame相同的索引,且name属性也已经设置好了,就是相应的列名。
#修改列索引
#获取前两列
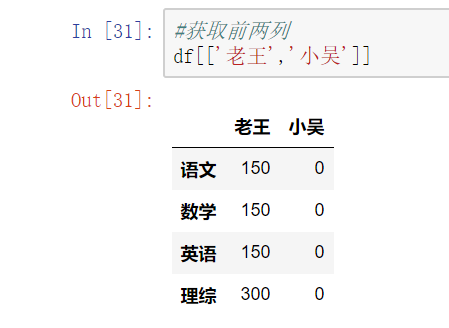
(2) 对行进行索引
- 使用.loc[]加index来进行行索引- 使用.iloc[]加整数来进行行索引
同样返回一个Series,index为原来的columns。

(3) 对元素索引的方法
- 使用列索引- 使用行索引(iloc[3,1] or loc['C','q']) 行索引在前,列索引在后
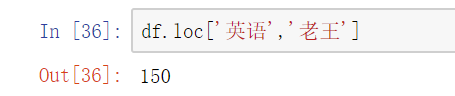
更改某个元素
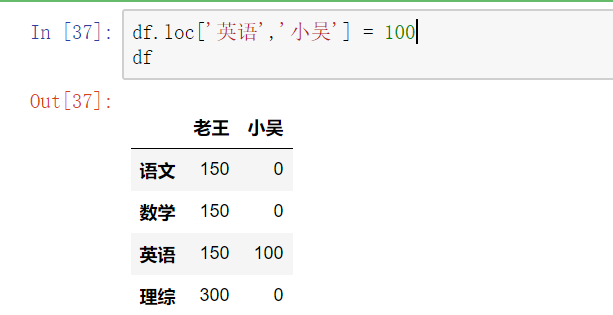
切片
【注意】 直接用中括号时:
- 索引表示的是列索引
- 切片表示的是行切片
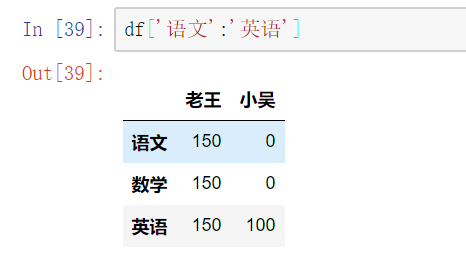
在loc和iloc中使用切片(切列)

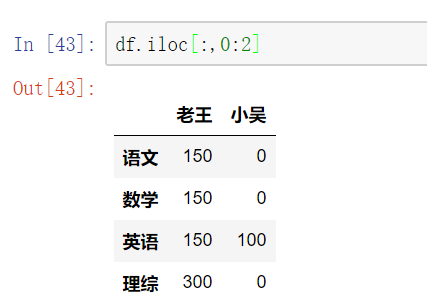
DataFrame的运算
(1) DataFrame之间的运算
同Series一样:
- 在运算中自动对齐不同索引的数据
- 如果索引不对应,则补NaN

处理丢失数据
有两种丢失数据:
- None
- np.nan(NaN)
1. None
None是Python自带的,其类型为python object。因此,None不能参与到任何计算中。
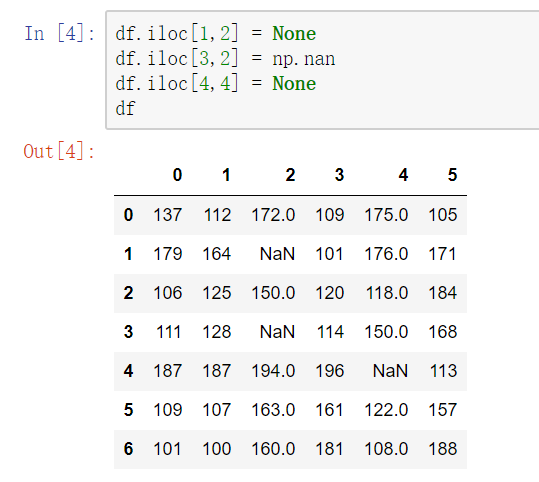
np.nan(NaN)
np.nan是浮点类型,能参与到计算中。但计算的结果总是NaN。

pandas中的None与NaN
1) pandas中None与np.nan都视作np.nan
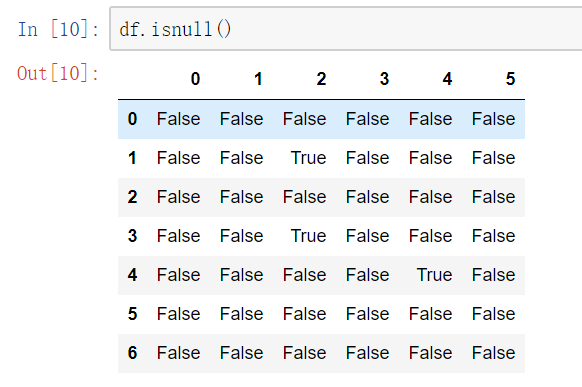
2) pandas处理空值操作
isnull()notnull()dropna(): 过滤丢失数据fillna(): 填充丢失数据
(1)判断函数
isnull()notnull()
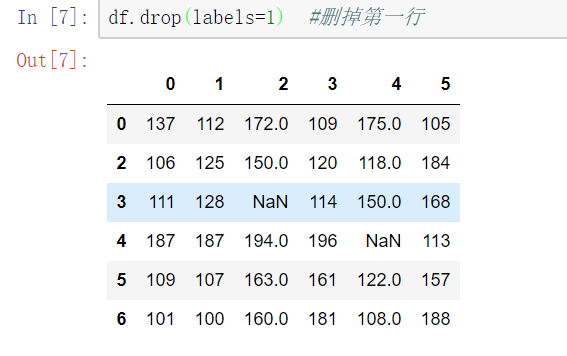
df.notnull/isnull().any()/all()

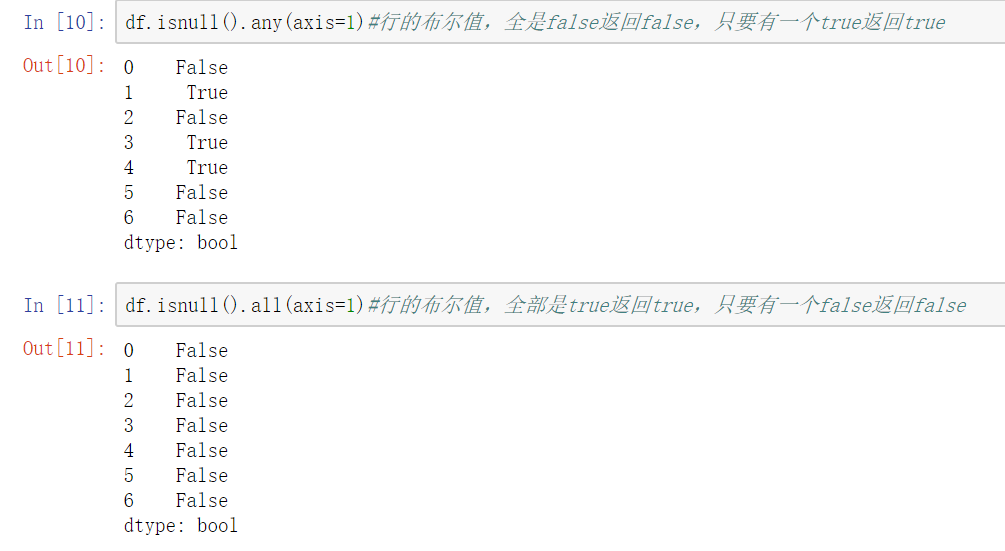
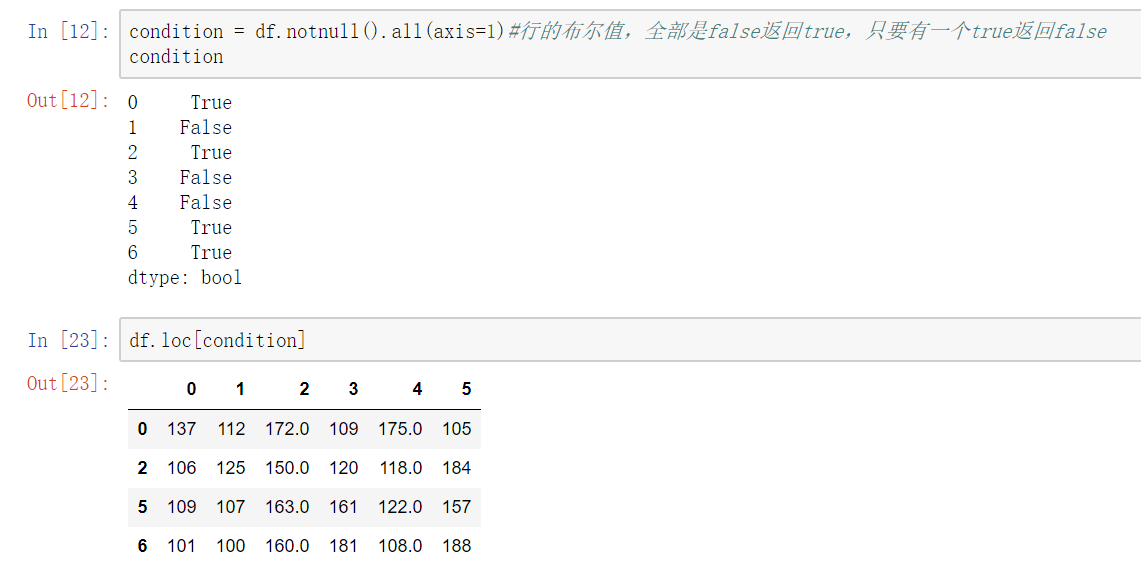


df.dropna() 可以选择过滤的是行还是列(默认为行):axis中0表示行,1表示的列
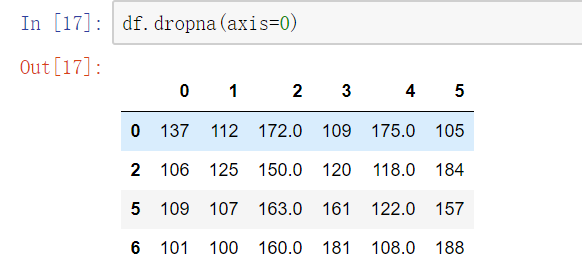
只有函数名含有drop的函数的axis中0表示行,1表示的列
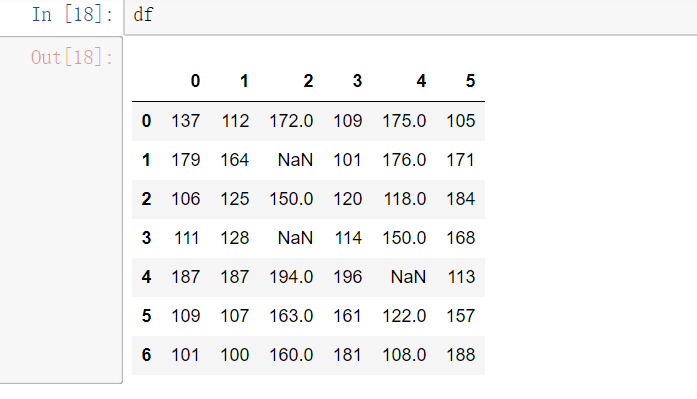
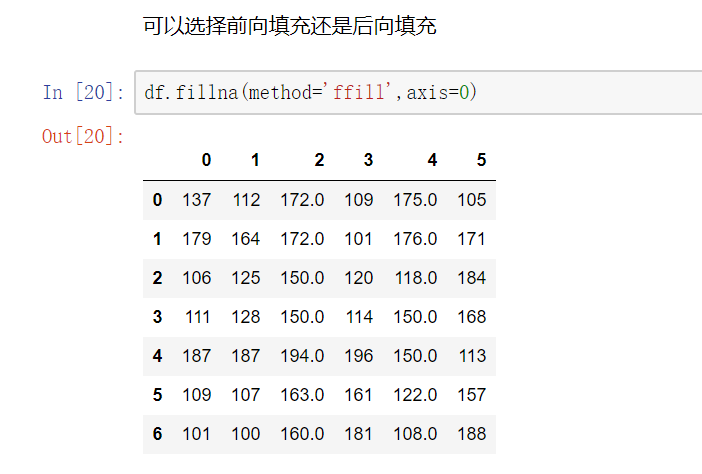
(3) 填充函数 Series/DataFrame
fillna():value和method参数
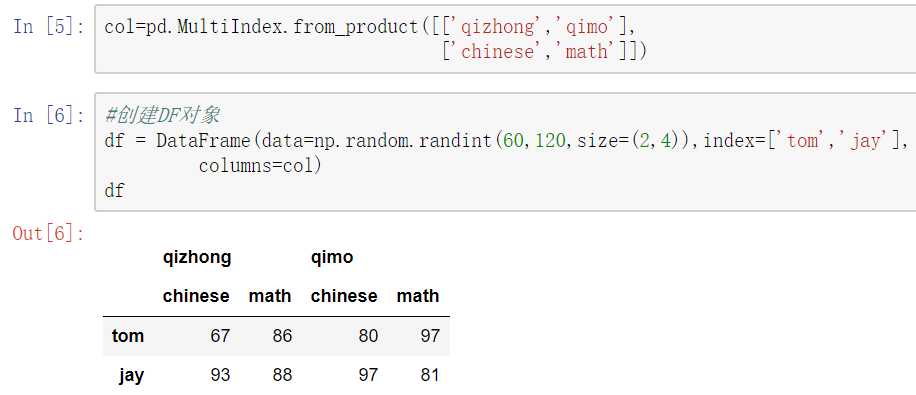
创建多层列索引
1) 隐式构造
最常见的方法是给DataFrame构造函数的index或者columns参数传递两个或更多的数组

2) 显示构造pd.MultiIndex.from
使用product:最简单,推荐使用
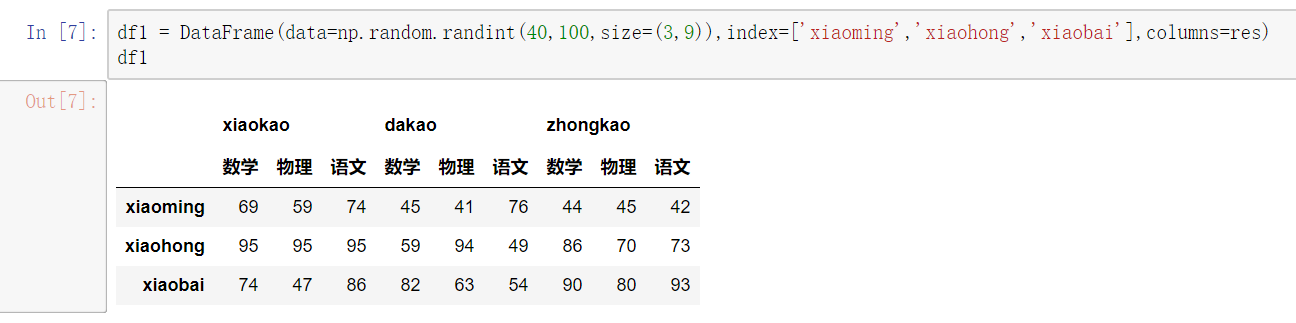
多层索引对象的索引与切片操作
DataFrame的操作

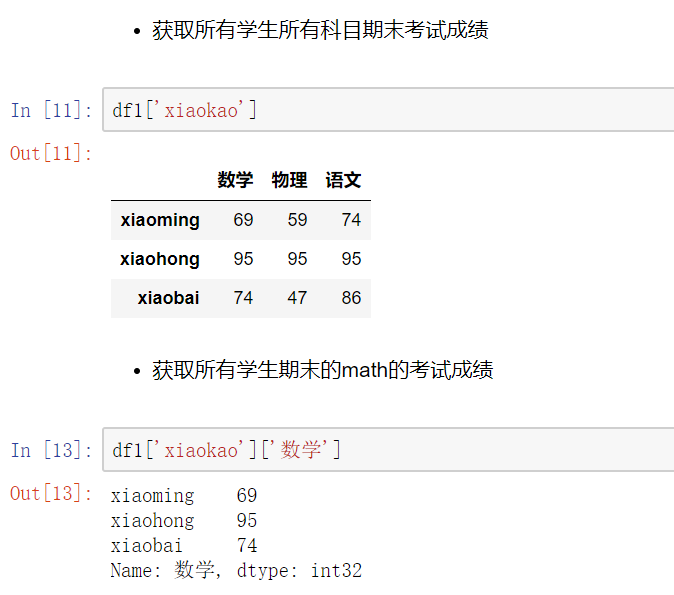


- # 总结:
- #直接使用[],索引是列索引,切片是行切片
- # 访问一列或多列 直接用中括号[columnname] [[columname1,columnname2...]]
- #访问一行或多行 .loc[inexname]/.loc[[indexname1,indexname2]]
- # 访问某一个元素 .loc[indexname,columnname]
- # 行切片 .loc[index1:index2]
- # 列切片 .loc[:,column1:column2]
聚合操作
所谓的聚合操作:平均数,方差,最大值,最小值……

pandas的拼接操作
pandas的拼接分为两种:
- 级联:pd.concat, pd.append
- 合并:pd.merge, pd.join
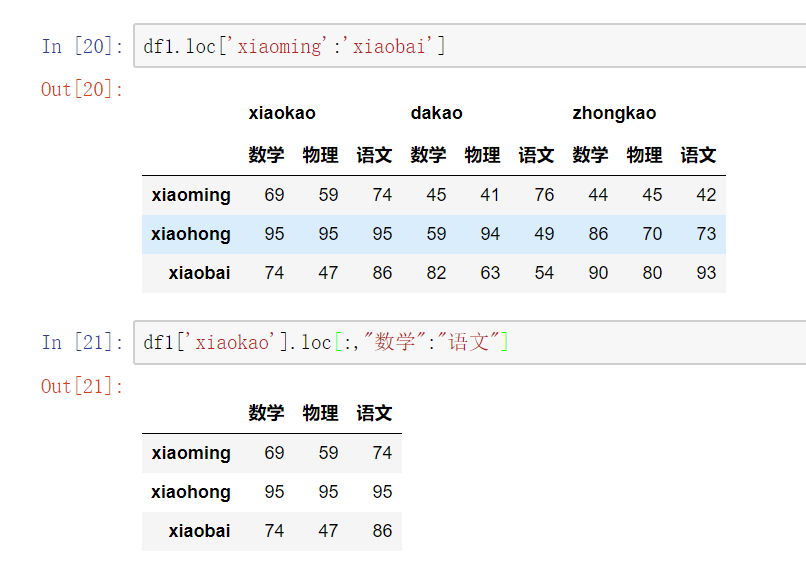
使用pd.concat()级联
pandas使用pd.concat函数,与np.concatenate函数类似,只是多了一些参数:
objsaxis=0 #横向还是纵向级联keys #标识,跟级联的表的个数一致join='outer' / 'inner':表示的是级联的方式,outer会将所有的项进行级联(忽略匹配和不匹配),而inner只会将匹配的项级联到一起,不匹配的不级联ignore_index=False #忽略行索引

不匹配级联
不匹配指的是级联的维度的索引不一致。例如纵向级联时列索引不一致,横向级联时行索引不一致
有2种连接方式:
- 外连接:补NaN(默认模式)
- 内连接:只连接匹配的项
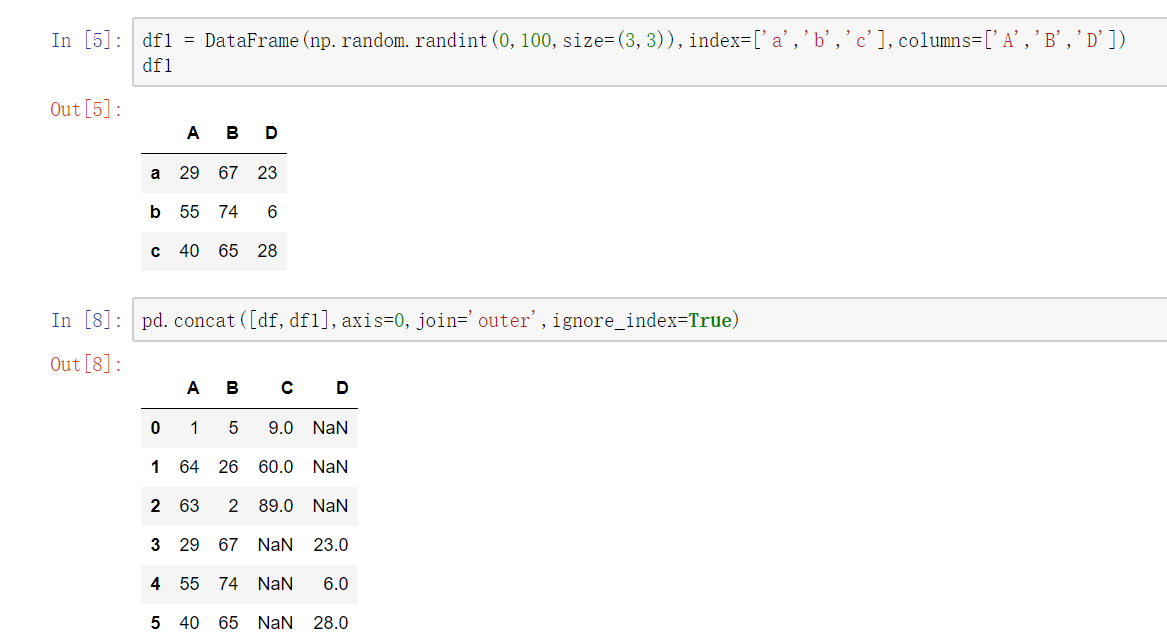
使用df.append()函数添加
由于在后面级联的使用非常普遍,因此有一个函数append专门用于在后面纵向添加

使用pd.merge()合并
merge与concat的区别在于,merge需要依据某一共同的列来进行合并
使用pd.merge()合并时,会自动根据两者相同column名称的那一列,作为key来进行合并。
注意每一列元素的顺序不要求一致
参数:
- how:out取并集 inner取交集
- on:当有多列相同的时候,可以使用on来指定使用那一列进行合并,on的值为一个列表
一对一合并
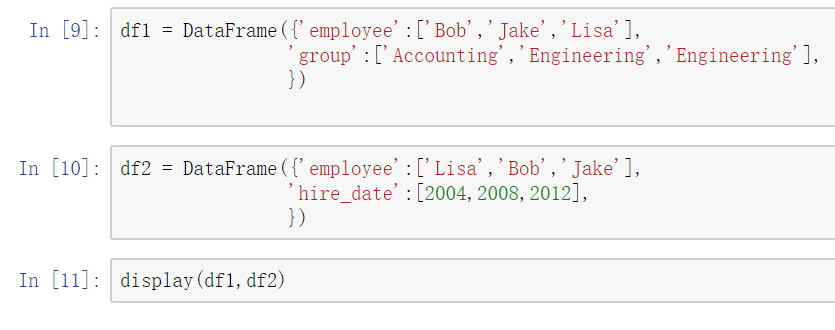
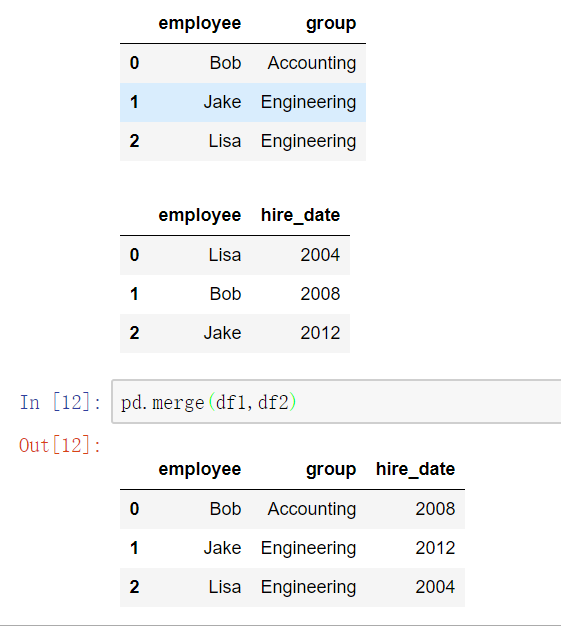
多对一合并
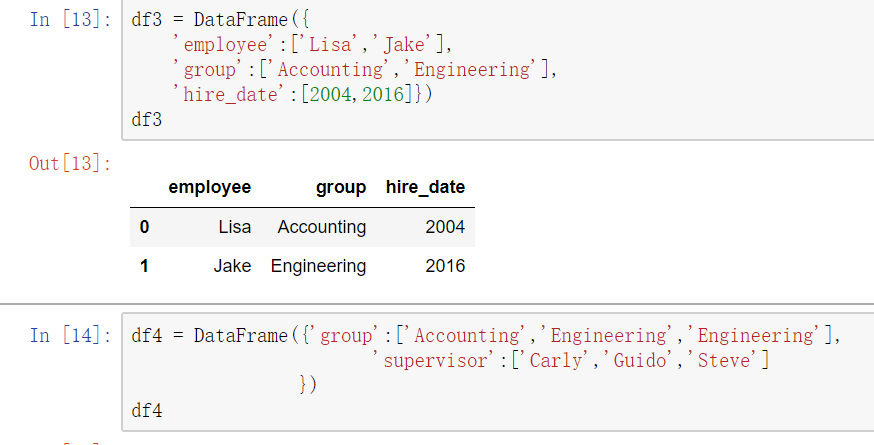
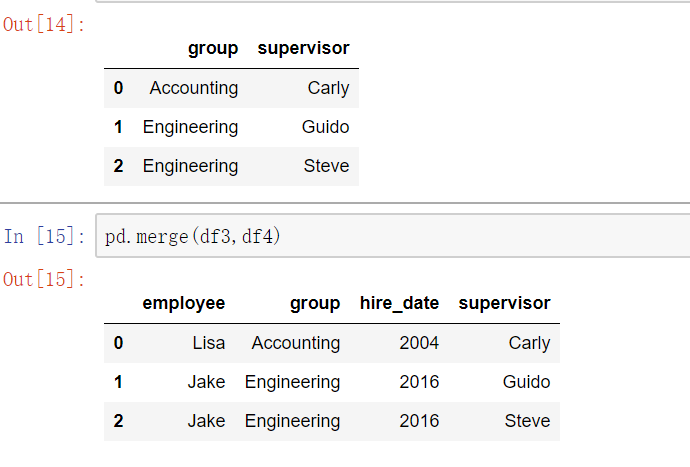
多对多合并
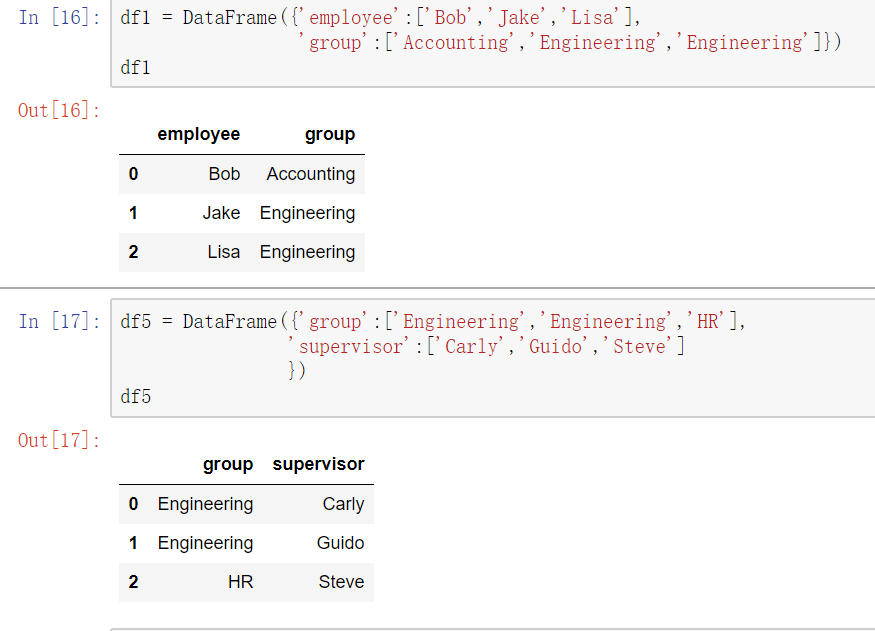
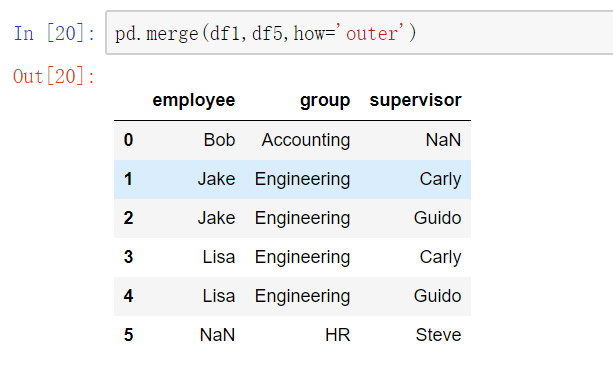
key的规范化
- 当列冲突时,即有多个列名称相同时,需要使用on=来指定哪一个列作为key,配合suffixes指定冲突列名
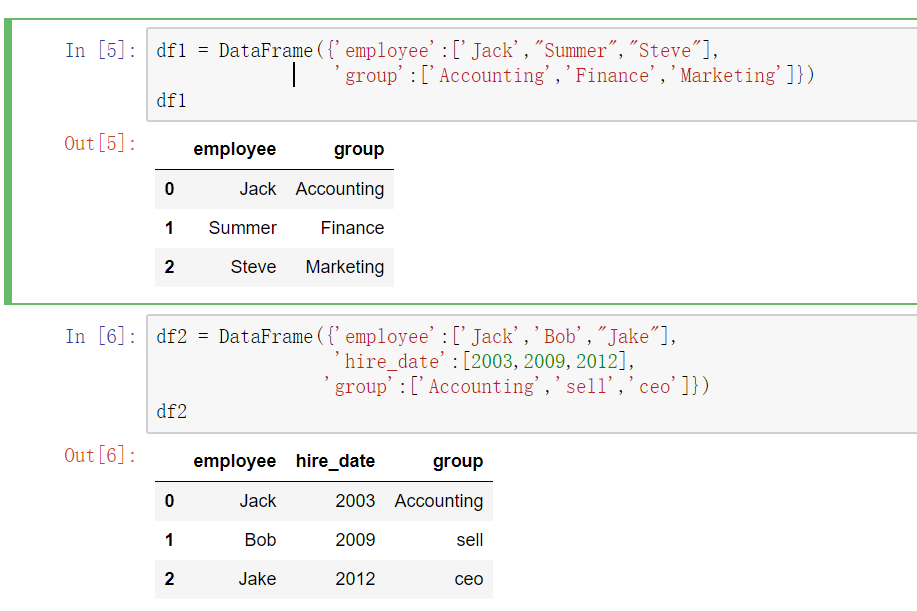
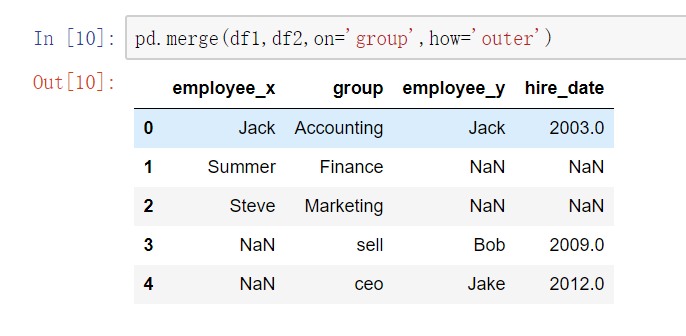
- 当两张表没有可进行连接的列时,可使用left_on和right_on手动指定merge中左右两边的哪一列列作为连接的列
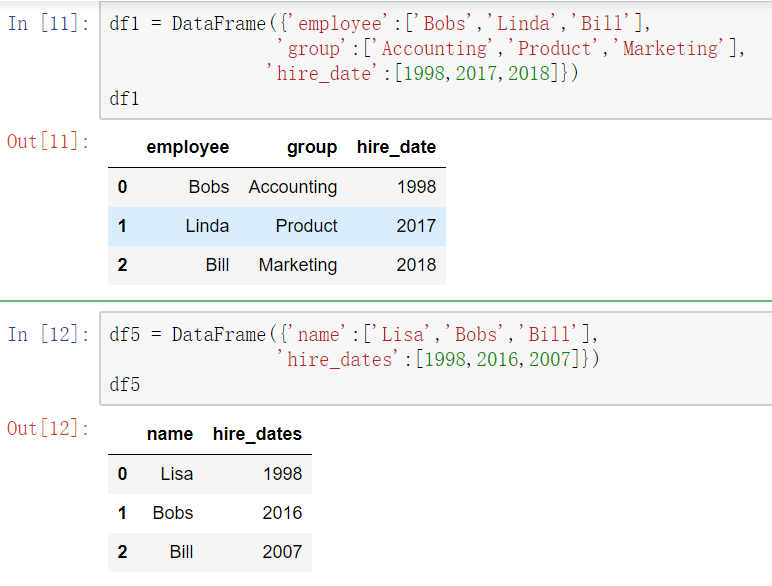

内合并与外合并:out取并集 inner取交集
- 内合并:只保留两者都有的key(默认模式)

- 外合并 how='outer':补NaN

pandas数据处理
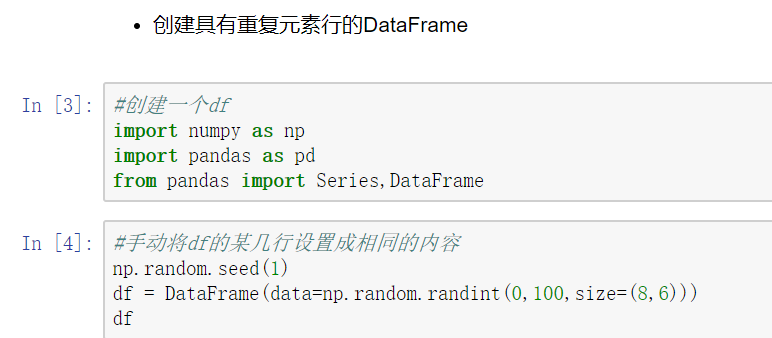
删除重复元素
使用duplicated()函数检测重复的行,返回元素为布尔类型的Series对象,每个元素对应一行,如果该行不是第一次出现,则元素为True
- keep参数:指定保留哪一重复的行数据,first:第一行 last:最后一行 False全部删
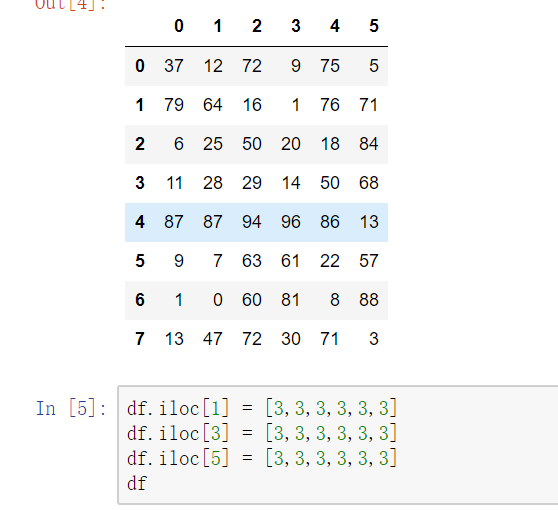

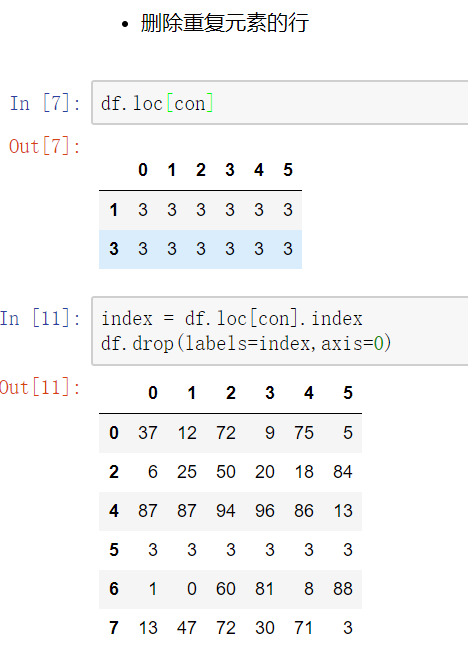
使用drop_duplicates()函数删除重复的行
drop_duplicates(keep='first/last'/False)

映射
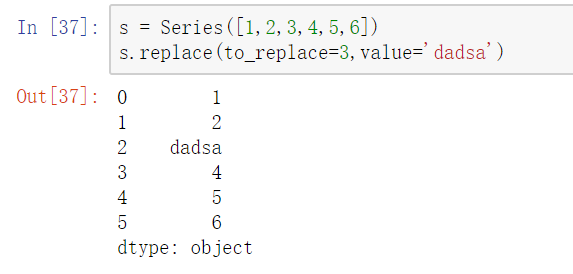
replace()函数:替换元素
使用replace()函数,对values进行映射操作
replace参数说明:
- method:对指定的值使用相邻的值填充替换
Series替换操作
- 单值替换
- 普通替换
- 字典替换(推荐)
- 多值替换
- 列表替换
- 字典替换(推荐)
- 参数
- to_replace:被替换的元素
- 单值普通替换
- 多值列表替换

单值字典替换
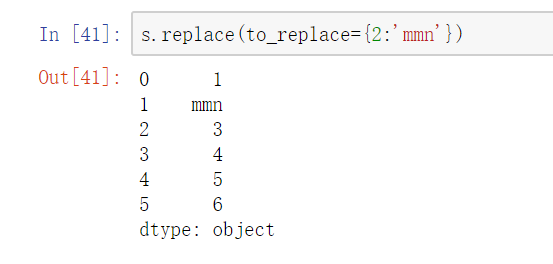
- 多值字典替换
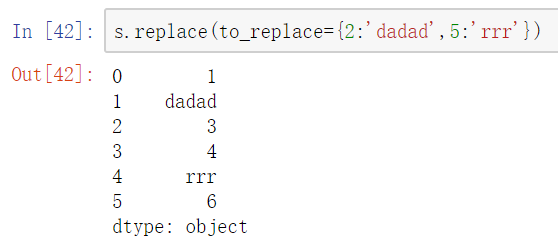
DataFrame替换操作
- 单值替换
- 普通替换: 替换所有符合要求的元素:to_replace=15,value='e'
- 按列指定单值替换: to_replace={列标签:替换值} value='value'
- 多值替换
- 列表替换: to_replace=[] value=[]
- 字典替换(推荐) to_replace={to_replace:value,to_replace:value}

按列指定单值替换

字典替换

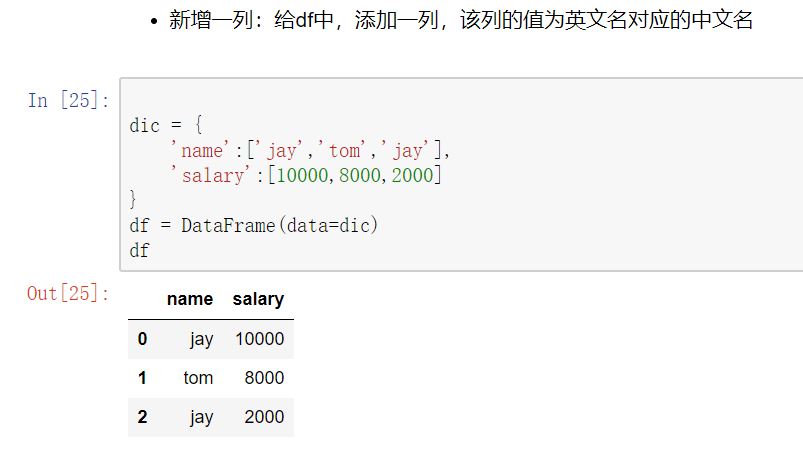
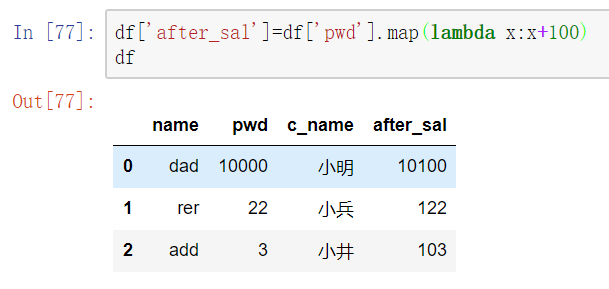
map()函数
新建一列 , map函数并不是df的方法,而是series的方法
- map()可以映射新一列数据
- map()中可以使用lambd表达式
map()中可以使用方法,可以是自定义的方法
eg:map({to_replace:value})
- 注意 map()中不能使用sum之类的函数,for循环
注意:并不是任何形式的函数都可以作为map的参数。只有当一个函数具有一个参数且有返回值,那么该函数才可以作为map的参数。

map当做一种运算工具,至于执行何种运算,是由map函数的参数决定的(参数:lambda,函数)
使用lambda表达式
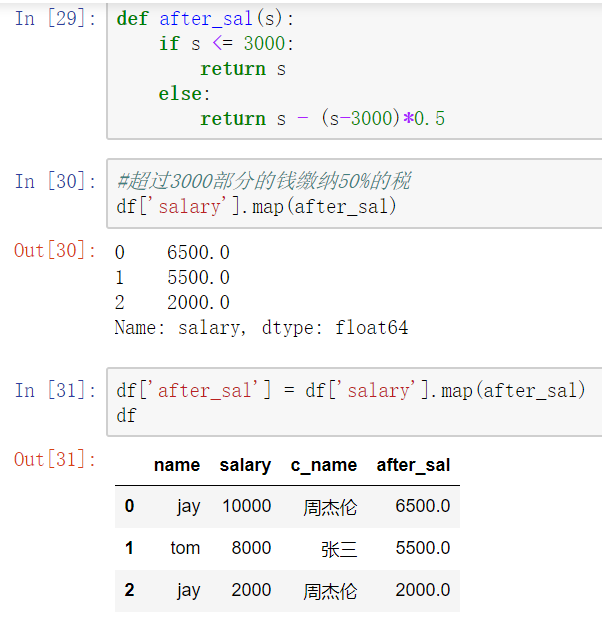
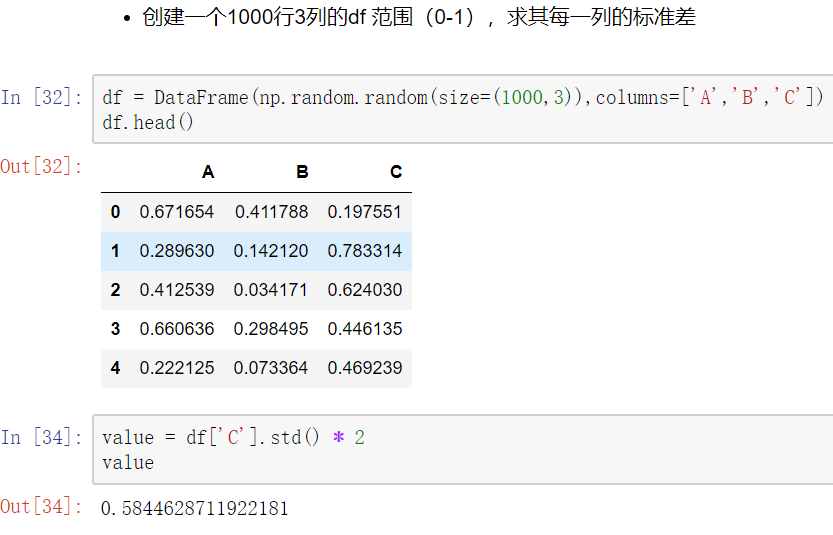
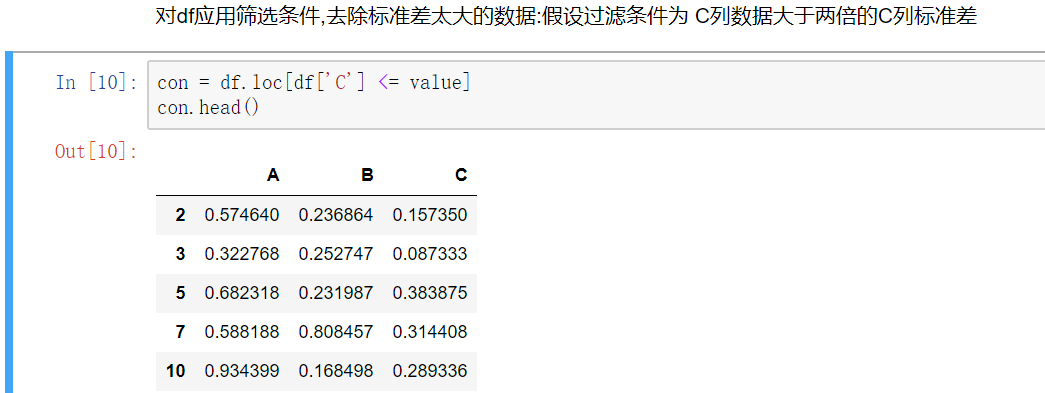
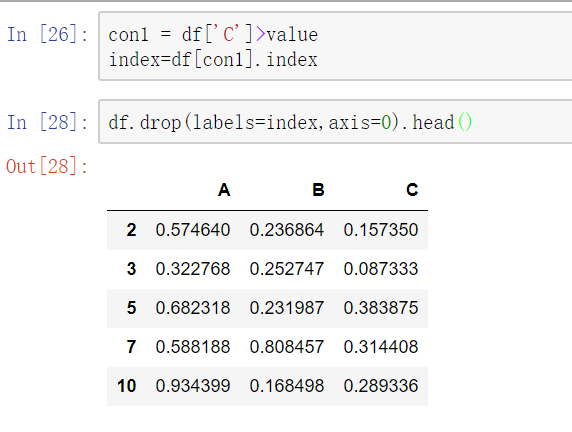
使用聚合操作对数据异常值检测和过滤
使用df.std()函数可以求得DataFrame对象每一列的标准差
第一种方法
- 第二种方法
排序
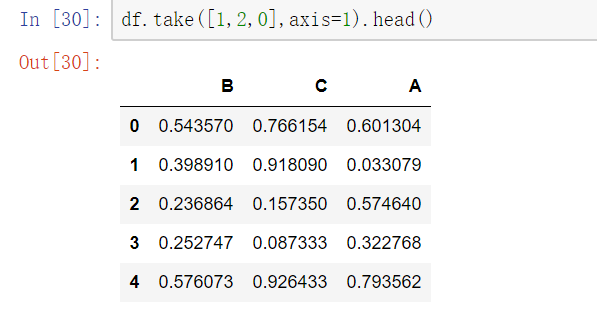
使用.take()函数排序
- take()函数接受一个索引列表,用数字表示,使得df根据列表中索引的顺序进行排序- eg:df.take([1,3,4,2,5])
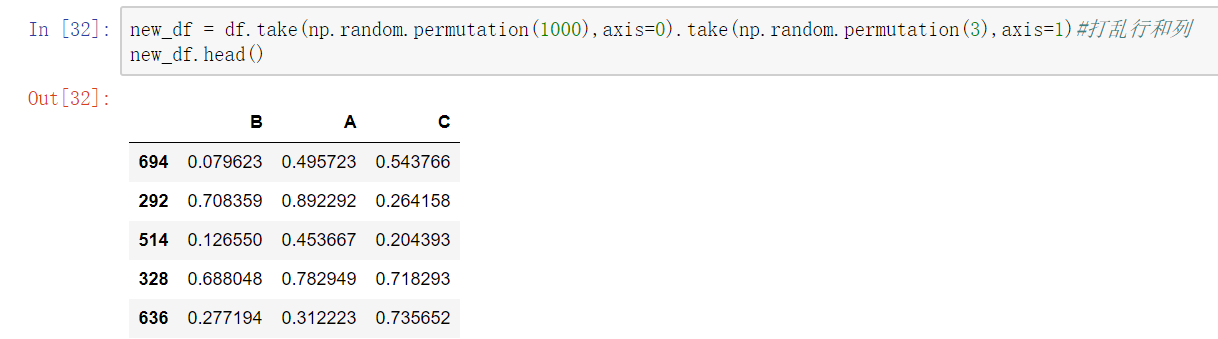
可以借助np.random.permutation()函数随机排序
- np.random.permutation(x)可以生成x个从0-(x-1)的随机数列
数据分类处理【重点】
数据聚合是数据处理的最后一步,通常是要使每一个数组生成一个单一的数值。
数据分类处理:
- 分组:先把数据分为几组
- 用函数处理:为不同组的数据应用不同的函数以转换数据
- 合并:把不同组得到的结果合并起来
数据分类处理的核心:
- groupby()函数- groups属性查看分组情况- eg: df.groupby(by='item').groups



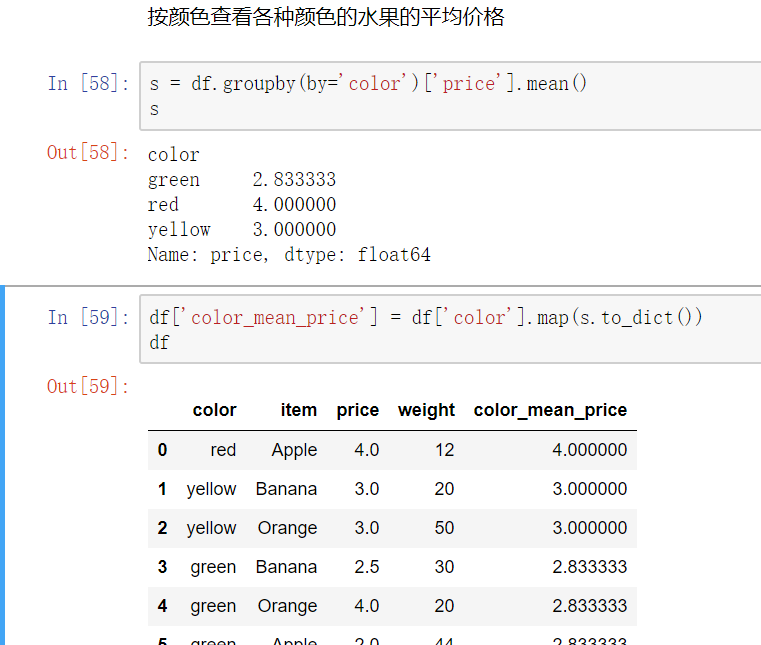
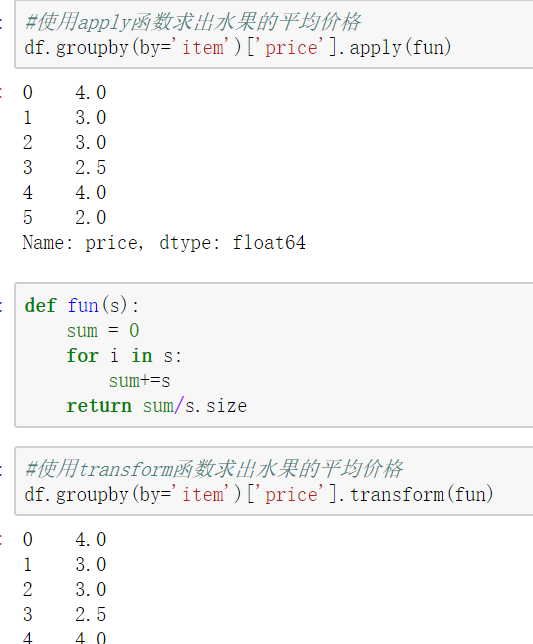
高级数据聚合
使用groupby分组后,也可以使用transform和apply提供自定义函数实现更多的运算
- df.groupby('item')['price'].sum() <==> df.groupby('item')['price'].apply(sum)
- transform和apply都会进行运算,在transform或者apply中传入函数即可
- transform和apply也可以传入一个lambda表达式
jupter nootbok 快捷键、NumPy模块、Pandas模块初识的更多相关文章
- numpy模块&pandas模块
目录 numpy模块 pandas模块 numpy模块 import pandas as pd import numpy as np df=pd.Series(np.array(['a','b'])) ...
- Python 数据处理扩展包: numpy 和 pandas 模块介绍
一.numpy模块 NumPy(Numeric Python)模块是Python的一种开源的数值计算扩展.这种工具可用来存储和处理大型矩阵,比Python自身的嵌套列表(nested list str ...
- numpy模块、matplotlib模块、pandas模块
目录 1. numpy模块 2. matplotlib模块 3. pandas模块 1. numpy模块 numpy模块的作用 用来做数据分析,对numpy数组(既有行又有列)--矩阵进行科学计算 实 ...
- Pandas模块:表计算与数据分析
目录 Pandas之Series Pandas之DataFrame 一.pandas简单介绍 1.pandas是一个强大的Python数据分析的工具包.2.pandas是基于NumPy构建的. 3.p ...
- 数组与pandas模块
'''数组与pandas模块''' # numpy模块:用来做数据分析,对numpy数组(既有行又有列)--矩阵进行科学运算 # tensorflow/pytorch(数学专业/物理专业/计科专业硕士 ...
- day18-常用模块III (numpy、pandas、matplotlib)
目录 numpy模块 创建矩阵 获取矩阵的行列数 切割矩阵 矩阵元素替换 矩阵的合并 通过函数创建矩阵 矩阵的运算 矩阵的点乘与转置 矩阵的逆 矩阵的其他操作 numpy.random生成随机数 pa ...
- logging,numpy,pandas,matplotlib模块
logging模块 日志总共分为以下五个级别,这五个级别自下而上进行匹配debug->info->warning->error->critical,默认的最低级别warning ...
- python之pandas模块
一.pandas模块是基于Numpy模块的,pandas的主要数据结构是Series和DadaFrame,下面引入这样的约定: from pandas import Series,DataFrame ...
- 关于Python pandas模块输出每行中间省略号问题
关于Python数据分析中pandas模块在输出的时候,每行的中间会有省略号出现,和行与行中间的省略号....问题,其他的站点(百度)中的大部分都是瞎写,根本就是复制黏贴以前的版本,你要想知道其他问题 ...
随机推荐
- VBA 获得绝对地址控制焦点的设置
先上代码,有时间再补上说明. Dim Mefoucs As String MsgBox "你选定的当前单元格是:" & Selection.Address Mefoucs ...
- 连接数据库通过配置文件app.config
ConfigurationManager类 public static class ConfigurationManager 命名空间: System.Configuration 程序集: Syste ...
- Redis学习笔记——数据类型及操作
数据操作 redis是key-value的数据,所以每个数据都是一个键值对 键的类型是字符串 值的类型分为五种: 字符串string 哈希hash 列表list 集合set 有序集合zset 数据操作 ...
- C#调用SQL Server有参的存储过程
一.使用SqlParameter的方式 代码: using System; using System.Collections.Generic; using System.ComponentModel; ...
- 原生Orcale数据库连接
package tj.test.demo; import java.sql.Connection;import java.sql.DriverManager;import java.sql.Prepa ...
- Thinlphp 模版 foreach 嵌套在 另一个循环出现不能在次循环问题。
把 foreach 循环改成 volist 就可以重置循环所以的数据.
- sql one
查询的话 子查询什么的都很正常 添加的话 尽量把东西都添加在一个表单里 这是源头 有个这个方便的源头 查询和删除都会方便很多 组建一个网站,不可避免的要进行调试,有些功能需要添加或者删除,对于后台来讲 ...
- Spring Cloud体系介绍
上图只是Spring Cloud体系的一部分,Spring Cloud共集成了19个子项目,里面都包含一个或者多个第三方的组件或者框架! Spring Cloud 工具框架 1.Spring Clou ...
- 漫游Kafka入门篇之简单介绍(1)
介绍 Kafka是一个分布式的.可分区的.可复制的消息系统.它提供了普通消息系统的功能,但具有自己独特的设计.这个独特的设计是什么样的呢? 首先让我们看几个基本的消息系统术语: Kafka将消息以 ...
- Spring boot Junit Test单元测试
Spring boot 1.40 JUnit 4 需要依赖包 spring-boot-starter-test.spring-test 建立class,加上如下注解,即可进行单元测试,别的帖子里说要加 ...