常用RDD
只作为我个人笔记,没有过多解释
Transfor
map
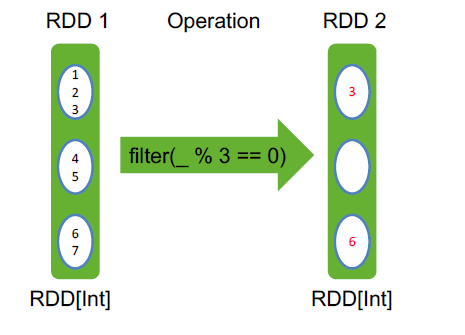
filter filter之后,依然有三个分区,第二个分区为空,但不会消失
flatMap
reduceByKey
groupByKey()
sortByKey()
val pets = sc.parallelize(
List((“cat”, 1), (“dog”, 1), (“cat”, 2))
)
pets.reduceByKey(_ + _) // => {(cat, 3), (dog, 1)}
pets.groupByKey() // => {(cat, Seq(1, 2)), (dog, Seq(1)}
pets.sortByKey() // => {(cat, 1), (cat, 2), (dog, 1)}
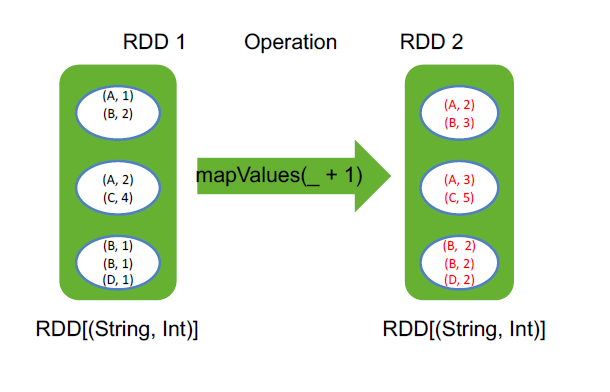
mapValues(_ + 1) mapvalues是忽略掉key,只把value进行操作
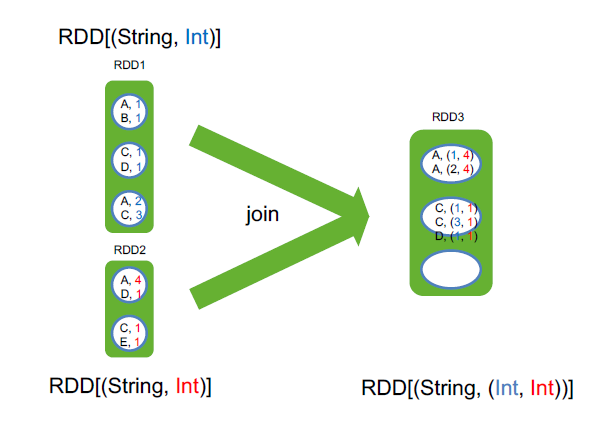
join RDD[(String, Int)].join(RDD[(String, Long)]) => RDD[(String, (Int, Long))]
join这两个rdd的value类型可以不一样,至于分区是根据hash来指定的
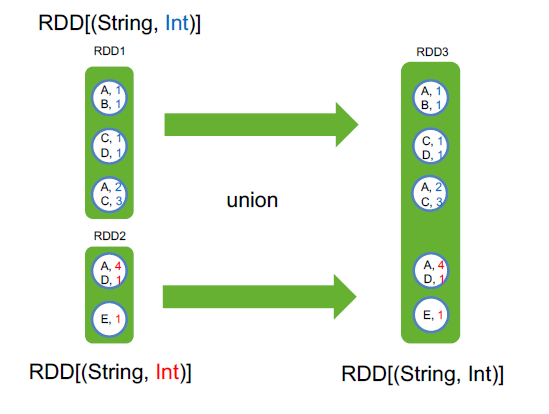
union
cogroup

用 cogroup 实现 join


sample() 从数据集中采样
cartesian() 求笛卡尔积
pipe() 传入一个外部程序
coalesce(口莱斯) 合并一个RDD的分区
rdd4 = rdd1 ++ rdd2 ++ rdd3
rdd4.coalesce(3)
rdd4.coalesce(3,true)
repartition 合并分区 rdd3.repartition(10)
并不是真的将分区合并,而是让一个task处理多个分区,如1k、10k、100k、1m、10m这五种文件,一共10w个,在hdfs上会有10w个block,取数据的时候会有10w个分区,同样有10w个task,这并不合适,如果能将这些分区合并,比如有10个task,每个task读1w个文件,速度会快很多,这个时候,有两种合并方式,coalesce和repartition
coalesce优点是简单粗暴,合并分区速度很快,缺点是很可能每个task所处理的数据不均匀。如果文件天生是比较均匀的,那coalesce合适
repartition优点是合并很均匀,用的是归并排序,缺点是计算开销比较大
举例,repartition合并的方法,10w个文件如何均匀的分成3个分区?
将每个文件均匀分成3分份,然后每一个分区从每个文件中拿一份
zip 将两个RDD的元素一一映射,合在一起
Action
collect()
take(2)
count()
reduce
foreach(println)
常用RDD的更多相关文章
- 08、Spark常用RDD变换
08.Spark常用RDD变换 8.1 概述 Spark RDD内部提供了很多变换操作,可以使用对数据的各种处理.同时,针对KV类型的操作,对应的方法封装在PairRDDFunctions trait ...
- 04、常用RDD操作整理
常用Transformation 注:某些函数只有PairRDD只有,而普通的RDD则没有,比如gropuByKey.reduceByKey.sortByKey.join.cogroup等函数要根据K ...
- Spark常用RDD操作总结
aggregate 函数原型:aggregate(zeroValue, seqOp, combOp) seqOp相当于Map combOp相当于Reduce zeroValue是seqOp每一个par ...
- 033 Java Spark的编程
1.Java SparkCore编程 入口是:JavaSparkContext 基本的RDD是:JavaRDD 其他常用RDD: JavaPairRDD JavaRDD和JavaPairRDD转换: ...
- Spark常用函数讲解之键值RDD转换
摘要: RDD:弹性分布式数据集,是一种特殊集合 ‚ 支持多种来源 ‚ 有容错机制 ‚ 可以被缓存 ‚ 支持并行操作,一个RDD代表一个分区里的数据集RDD有两种操作算子: Trans ...
- Spark学习之路(四)—— RDD常用算子详解
一.Transformation spark常用的Transformation算子如下表: Transformation算子 Meaning(含义) map(func) 对原RDD中每个元素运用 fu ...
- Spark 系列(四)—— RDD常用算子详解
一.Transformation spark 常用的 Transformation 算子如下表: Transformation 算子 Meaning(含义) map(func) 对原 RDD 中每个元 ...
- spark学习(10)-RDD的介绍和常用算子
RDD(弹性分布式数据集,里面并不存储真正要计算的数据,你对RDD的操作,他会在Driver端转换成Task,下发到Executor计算分散在多台集群上的数据) RDD是一个代理,你对代理进行操作,他 ...
- sparkRDD:第3节 RDD常用的算子操作
4. RDD编程API 4.1 RDD的算子分类 Transformation(转换):根据数据集创建一个新的数据集,计算后返回一个新RDD:例如:一个rdd进行map操作后生了一个新的rd ...
随机推荐
- 安装wampserver时提示丢失MSVCR110.dll
安装Wampserver 2后启动的时候提示系统错误:MSVCR110.dll丢失. 在wampserver官网上有例如以下提示: 于是卸载原来的WAMPSERVER 2 ,在http://www.m ...
- ios开发之--PDF文件生成
写项目的时候,碰到一个需求,就是在手机端根据指定的文件内容生成PDF文件,并可以保存到手机上,因为以前只是听说过,没有真正的去了解过这个需求,通过查阅资料,可以实现这个功能,话不多说,代码如下: -( ...
- Android项目混淆打包
以下为我此期项目中的关于混淆打包的总结:(本人第一次混淆打包,呵呵,错误很多!列了一些比较头疼的)一.项目混淆过程中注意事项:由于我的sdk版本较高,因此新建android项目下只有proguard- ...
- 转载hiberinate的懒加载
Hibernate的强大之处之一是懒加载功能,可以有效的降低数据库访问次数和内存使用量.但用的不好就会出现org.hibernate.LazyInitializationException. 这个异常 ...
- 【python】-- RabbitMQ 队列消息持久化、消息公平分发
RabbitMQ 队列消息持久化 假如消息队列test里面还有消息等待消费者(consumers)去接收,但是这个时候服务器端宕机了,这个时候消息是否还在? 1.队列消息非持久化 服务端(produc ...
- 时间序列模式——ARIMA模型
ARIMA模型全称为自回归积分滑动平均模型(Autoregressive Integrated Moving Average Model,简记ARIMA),是由博克思(Box)和詹金斯(Jenkins ...
- csv的文件excel打开长数字后面位变0的解决方法
对于有大数字的CSV文件,应使用导入,而不是打开.这里以Excel2010为例,其它版本也可以参照: 打开Excel,此时Excel内为空白文档 点击工具栏中的[数据]→[自文本] 在“导入文本文件” ...
- String Problem --- hdu3374(kmp、字典序最大与最小)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=3374 题意很简单,输出的是最小字典序的编号,最小字典序个数,最大字典序编号,最大字典序个数. 可以想一 ...
- Seek the Name, Seek the Fame---poj2752(kmp中的Next数组)
题目链接:http://poj.org/problem?id=2752 题意就是求出是已知s串的前缀的长度x,并且要求此前缀也是s串的后缀:求出所有的 x : Next[i]的含义是前i个元素的前缀和 ...
- 解决hung_task_timeout_secs问题【方法待校验】
问题描述: kernel: "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this messag ...