Python——爬取百度百科关键词1000个相关网页
Python简单爬虫——爬取百度百科关键词1000个相关网页——标题和简介
网站爬虫由浅入深:慢慢来
分析:

链接的URL分析:

数据格式:
爬虫基本架构模型:
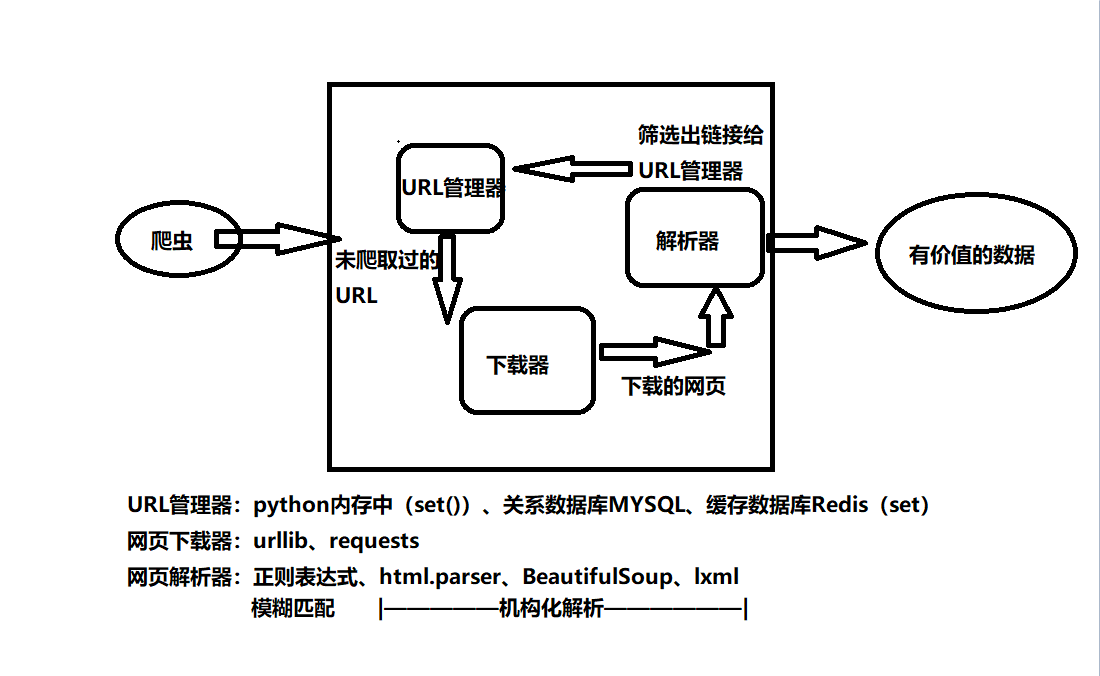
本爬虫架构:

源代码:
# coding:utf8
# author:Jery
# datetime:2019/4/12 19:22
# software:PyCharm
# function:爬取百度百科关键词python1000个相关网页——标题和简介
from urllib.request import urlopen
import re
from bs4 import BeautifulSoup class SpiderMain(object):
def __init__(self):
self.urls = UrlManager()
self.downloader = HtmlDownloader()
self.parser = HtmlParser()
self.outputer = DataOutputer() # 主爬虫,调度四个类的方法执行爬虫
def crawl(self, root_url):
count = 1
self.urls.add_new_url(root_url)
while self.urls.has_new_url():
try:
new_url = self.urls.get_new_url()
print("crawl 第{} :{} ".format(count, new_url))
html_content = self.downloader.download(new_url)
new_urls, new_data = self.parser.parse(new_url, html_content)
# 新网页的url及数据
self.urls.add_new_urls(new_urls)
self.outputer.collect_data(new_data)
if count == 1000:
break
count += 1
except:
print(" crawl failed! ")
self.outputer.output_html() # URL管理器,实现URL的增加与删除
class UrlManager:
def __init__(self):
self.new_urls = set()
self.old_urls = set() def has_new_url(self):
return len(self.new_urls) != 0 def get_new_url(self):
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url def add_new_url(self, url):
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url) def add_new_urls(self, urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.new_urls.add(url) # 下载网页源代码
class HtmlDownloader:
def download(self, url):
if url in None:
return
response = urlopen(url)
if response.getcode() != 200:
return
return response.read() # 下载网页所需内容
class HtmlParser:
def parse(self, page_url, html_content):
if page_url is None or html_content is None:
return
soup = BeautifulSoup(html_content, 'lxml', from_encoding='utf-8')
new_urls = self._get_new_urls(page_url, soup)
new_data = self._get_new_data(page_url, soup)
return new_urls, new_data def _get_new_urls(self, page_url, soup):
new_urls = set()
links = soup.find_all('a', href=re.compile(r'/view/.*'))
for link in links:
new_url = "https://baike.baidu.com" + link['href']
new_urls.add(new_url)
return new_urls def _get_new_data(self, page_url, soup):
res_data = {}
# <dl class="lemmaWgt-lemmaTitle lemmaWgt-lemmaTitle-">
# <dd class="lemmaWgt-lemmaTitle-title">
# <h1>Python</h1>
title_node = soup.find("dl", {"class": "lemmaWgt-lemmaTitle lemmaWgt-lemmaTitle-"}).dd.h1
res_data['title'] = title_node.get_text()
summary_node = soup.find('div', {"class": "lemma-summary"})
res_data['summary'] = summary_node.get_text()
return res_data # 将所搜集数据输出至html的表格中
class DataOutputer:
def __init__(self):
self.datas = [] def collect_data(self, data):
if data is None:
return
self.datas.append(data) def output_html(self):
output = open('output.html', 'w')
output.write("<html>")
output.write("<body>")
output.write("<table>")
for data in self.datas:
output.write("<tr>")
output.write("<td>{}</td>".format(data['url']))
output.write("<td>{}</td>".format(data['title'].encode('utf-8')))
output.write("<td>{}</td>".format(data['summary'].encode('utf-8')))
output.write("</tr>")
output.write("</table>")
output.write("<body>")
output.write("</html>")
output.close() if __name__ == '__main__':
root_url = "https://baike.baidu.com/item/Python/407313"
obj_spider = SpiderMain()
obj_spider.crawl(root_url)
Python——爬取百度百科关键词1000个相关网页的更多相关文章
- 爬虫实战(一) 用Python爬取百度百科
最近博主遇到这样一个需求:当用户输入一个词语时,返回这个词语的解释 我的第一个想法是做一个数据库,把常用的词语和词语的解释放到数据库里面,当用户查询时直接读取数据库结果 但是自己又没有心思做这样一个数 ...
- Python开发简单爬虫(二)---爬取百度百科页面数据
一.开发爬虫的步骤 1.确定目标抓取策略: 打开目标页面,通过右键审查元素确定网页的url格式.数据格式.和网页编码形式. ①先看url的格式, F12观察一下链接的形式;② 再看目标文本信息的标签格 ...
- Python抓取百度百科数据
前言 本文整理自慕课网<Python开发简单爬虫>,将会记录爬取百度百科"python"词条相关页面的整个过程. 抓取策略 确定目标:确定抓取哪个网站的哪些页面的哪部分 ...
- python简单爬虫 用beautifulsoup爬取百度百科词条
目标:爬取“湖南大学”百科词条并处理数据 需要获取的数据: 源代码: <div class="basic-info cmn-clearfix"> <dl clas ...
- Python3爬取百度百科(配合PHP)
用PHP写了一个网页,可以获取百度百科词条.源代码已分享至github:https://github.com/1049451037/xiaobaike/tree/master 那么通过Python来爬 ...
- java 如何爬取百度百科词条内容(java如何使用webmagic爬取百度词条)
这是老师所布置的作业 说一下我这里的爬去并非能把百度词条上的内容一字不漏的取下来(而是它分享链接的一个主要内容概括...)(他的主要内容我爬不到 也不想去研究大家有好办法可以call me) 例如 互 ...
- python 爬取百度url
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Date : 2017-08-29 18:38:23 # @Author : EnderZhou (z ...
- 用Python爬取了考研吧1000条帖子,原来他们都在讨论这些!
写在前面 考研在即,想多了解考研er的想法,就是去找学长学姐或者去网上搜索,贴吧就是一个好地方.而借助强大的工具可以快速从网络鱼龙混杂的信息中得到有价值的信息.虽然网上有很多爬取百度贴吧的教程和例子, ...
- 假期学习【十一】Python爬取百度词条写入csv格式 python 2020.2.10
今天主要完成了根据爬取的txt文档,从百度分类从信息科学类爬取百度词条信息,并写入CSV格式文件. txt格式文件如图: 为自己爬取内容分词后的结果. 代码如下: import requests fr ...
随机推荐
- zigbee初探
什么是zigbee? 1.它是一种通信方式,一种通信协议: 2.其作用就是构建一个类似无线局域网的东西:如果这个局域网用于传感器的数据收集.监控,那么这个网络就叫做无线传感器网络. 应用领域:家居.工 ...
- Java Persistence with MyBatis 3(中文版) 前言
对很多软件系统而言,保存数据到数据库和从数据库中检索数据是其工作流程中至关重要的一部分.在 Java 领域,有很多的实现了数据持久化层的工具和框架,它们每一个都有自己不同的实现方法.而 MyBatis ...
- NET Framework V4.0.30319
http://www.microsoft.com/zh-cn/download/details.aspx?id=17718
- SpringMVC错误集中营
1.eclipse里的错误提示为The import javax.servlet.http.HttpServletRequest cannot be resolved 1.这是因为工程里面web-in ...
- Linq实战 之 DataSet操作详解
Linq实战 之 DataSet操作详解 一:linq to Ado.Net 1. linq为什么要扩展ado.net,原因在于给既有代码增加福利.FCL中在ado.net上扩展了一些方法. 简单一 ...
- Verilog MIPS32 CPU(二)-- Regfiles
Verilog MIPS32 CPU(一)-- PC寄存器 Verilog MIPS32 CPU(二)-- Regfiles Verilog MIPS32 CPU(三)-- ALU Verilog M ...
- SoapUI设置Cookie
因為.NET寫的Web Service的方法是需要驗證session的. 需要先call方法Login之後才能使用其它的方法.最近剛在學用SoapUI測試soap的API,剛好可以通過Groovy S ...
- windows中卸载Jenkins
背景: 之前安装的Jenkins没有pipeline选项,可能是之前安装时没有选择建议插件.后面使用最新版本时还是没有插件 解决: 卸载Jenkins,删除掉C:\Users\用户名\.jenkins ...
- 菜鸟的Xamarin.Forms前行之路——windows下VS运行ios模拟器调试
在Xamarin.Forms项目中,运行安卓模拟器是很方便的,但是想要运行IOS模拟器,相对而言是困难一点. 在参考一些资料后,发现很多是与Xamarin.studio有关的方法,尝试了许久没有成功. ...
- django 快捷代码提示
1.右键项目,Mark Directory As Source Root 2.settings配置 3.import包时可忽略app名了