Webharvest网络爬虫应用总结,web-harvest 编写脚本 读取 百度 博客 实例
Web-Harvest是一个Java开源Web数据抽取工具。它能够收集指定的Web页面并从这些页面中提取有用的数据。其实现原理是,根据预先定义的配置文件用httpclient获取页面的全部内容(关于httpclient的内容,本博有些文章已介绍),然后运用XPath、XQuery、正则表达式等这些技术来实现对text/xml的内容筛选操作,选取精确的数据。前两年比较火的垂直搜索(比如:酷讯等)也是采用类似的原理实现的。Web-Harvest应用,关键就是理解和定义配置文件,其他的就是考虑怎么处理数据的Java代码。当然在爬虫开始前,也可以把Java变量填充到配置文件中,实现动态的配置。
(友情提示:本博文章欢迎转载,但请注明出处:陈新汉,http://www.blogjava.net/hankchen)
现在以爬取天涯论坛的所有版面信息为例,介绍Web-Harvest的用法,特别是其配置文件。
天涯的版块地图页面时:http://www.tianya.cn/bbs/index.shtml
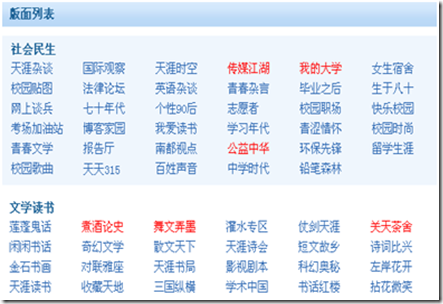
[天涯的部分版面列表]
我们的目标就是要抓取全部的版块信息,包括版块之间的父子关系。
先查看版块地图的页面源代码,寻求规律:
<div class="backrgoundcolor">
<div class="bankuai_list">
<h3>社会民生</h3>
<ul>
<li><a href="http://www.tianya.cn/publicforum/articleslist/0/free.shtml" id="item天涯杂谈">天涯杂谈</a></li>
<li><a href="http://www.tianya.cn/publicforum/articleslist/0/worldlook.shtml" id="item国际观察">国际观察</a></li>
<li><a href="http://www.tianya.cn/publicforum/articleslist/0/news.shtml" id="item天涯时空">天涯时空</a></li>
<li><a href="http://www.tianya.cn/publicforum/articleslist/0/no06.shtml" id="item传媒江湖">传媒江湖</a></li>
…… //省略
</ul>
</div>
<div class="clear"></div>
</div>
<div class="nobackrgoundcolor">
<div class="bankuai_list">
<h3>文学读书</h3>
<ul>
<li><a href="http://www.tianya.cn/techforum/articleslist/0/16.shtml" id="item莲蓬鬼话">莲蓬鬼话</a></li>
<li><a href="http://www.tianya.cn/publicforum/articleslist/0/no05.shtml" id="item煮酒论史">煮酒论史</a></li>
<li><a href="http://www.tianya.cn/publicforum/articleslist/0/culture.shtml" id="item舞文弄墨">舞文弄墨</a></li>
……. //省略
</ul>
</div>
<div class="clear"></div>
</div>
……. //省略
通过页面源码分析,发现每个大板块都是在<div class="bankuai_list"></div>的包括之下,而大板块下面的小版块都是下面的形式包含的。
<li><a href="xxx" id="xxx">xxx</a></li>,这些规律就是webharvest爬数据的规则。
下面先给出全部的配置:(tianya.xml)
<config charset="utf-8">
<var-def name="start">
<html-to-xml>
<http url="http://www.tianya.cn/bbs/index.shtml" charset="utf-8" />
</html-to-xml>
</var-def>
<var-def name="ulList">
<xpath expression="//div[@class='bankuai_list']">
<var name="start" />
</xpath>
</var-def>
<file action="write" path="tianya/siteboards.xml" charset="utf-8">
<![CDATA[ <site> ]]>
<loop item="item" index="i">
<list><var name="ulList"/></list>
<body>
<xquery>
<xq-param name="item">
<var name="item"/>
</xq-param>
<xq-expression><![CDATA[
declare variable $item as node() external;
<board boardname="{normalize-space(data($item//h3/text()))}" boardurl="">
{
for $row in $item//li return
<board boardname="{normalize-space(data($row//a/text()))}" boardurl="{normalize-space(data($row/a/@href))}" />
}
</board>
]]></xq-expression>
</xquery>
</body>
</loop>
<![CDATA[ </site> ]]>
</file>
</config>
这个配置文件分为三个部分:
1. 定义爬虫入口:
<var-def name="start">
<html-to-xml>
<http url="http://www.tianya.cn/bbs/index.shtml" charset="utf-8" />
</html-to-xml>
</var-def>
爬虫的入口URL是:http://www.tianya.cn/bbs/index.shtml
同时,指定了爬虫的爬数据的编码,这个编码应该根据具体的页面编码来定,例如上面的入口页面的编码就是utf-8。其实,有很多的中文页面的编码是gbk或者gb2312,那么这个地方的编码就要相应设置,否则会出现数据乱码。
2. 定义数据的过滤规则:
<var-def name="ulList">
<xpath expression="//div[@class='bankuai_list']">
<var name="start" />
</xpath>
</var-def>
上面配置就是根据XPath从爬得的数据中筛选合适的内容。这里需要得到所有的<div class="bankuai_list"></div>信息。有关XPath和XQuery的语法请网上查询。
3. 最后一步就是处理数据。可以写入XML文件,也可以使用SetContextVar的方式把收集的数据塞到一个集合变量中,供Java代码调用(比如:数据直接入库)。
这里是直接写入XML文件,然后解析XML即可。
注意下面的for循环,这是XQuery的语法,提供遍历的功能。由于大版面小版块是一个树状结构,需要这种遍历。
<board boardname="{normalize-space(data($item//h3/text()))}" boardurl="">
{
for $row in $item//li return
<board boardname="{normalize-space(data($row//a/text()))}" boardurl="{normalize-space(data($row/a/@href))}" />
}
</board>
相关的Java代码如下:
/**
* Copyright(C):2009
* @author陈新汉
* Sep4,20093:24:58PM
*/
String configFile="tianya.xml";
ScraperConfiguration config = new ScraperConfiguration(configFile);
String targetFolder="c:\\chenxinhan";
Scraper scraper = new Scraper(config,targetFolder);
//设置爬虫代理
scraper.getHttpClientManager().setHttpProxy("218.56.64.210","8080");
scraper.setDebug(true);
scraper.execute();
上面代码执行完成后,收集的数据文件地址为:c:\chenxinhan\tianya\siteboards.xml
web-harvest简介:
翻看博文的时候看到之前写的这个了,是帮大学生在线写的,整个项目组成员来自大江南北,也就没问什么时候可以上线,现在把上线后的图贴上来吧,由于个人是实名认证的,所以都擦除了
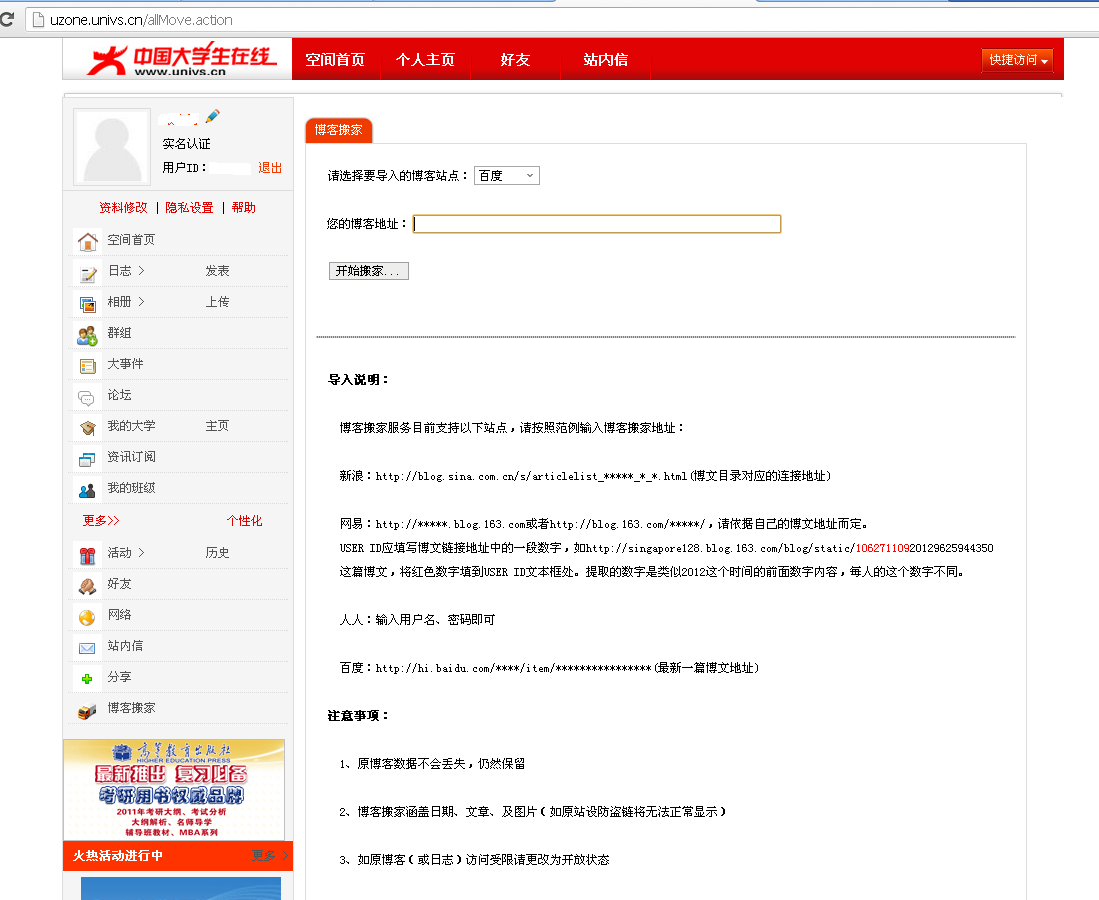
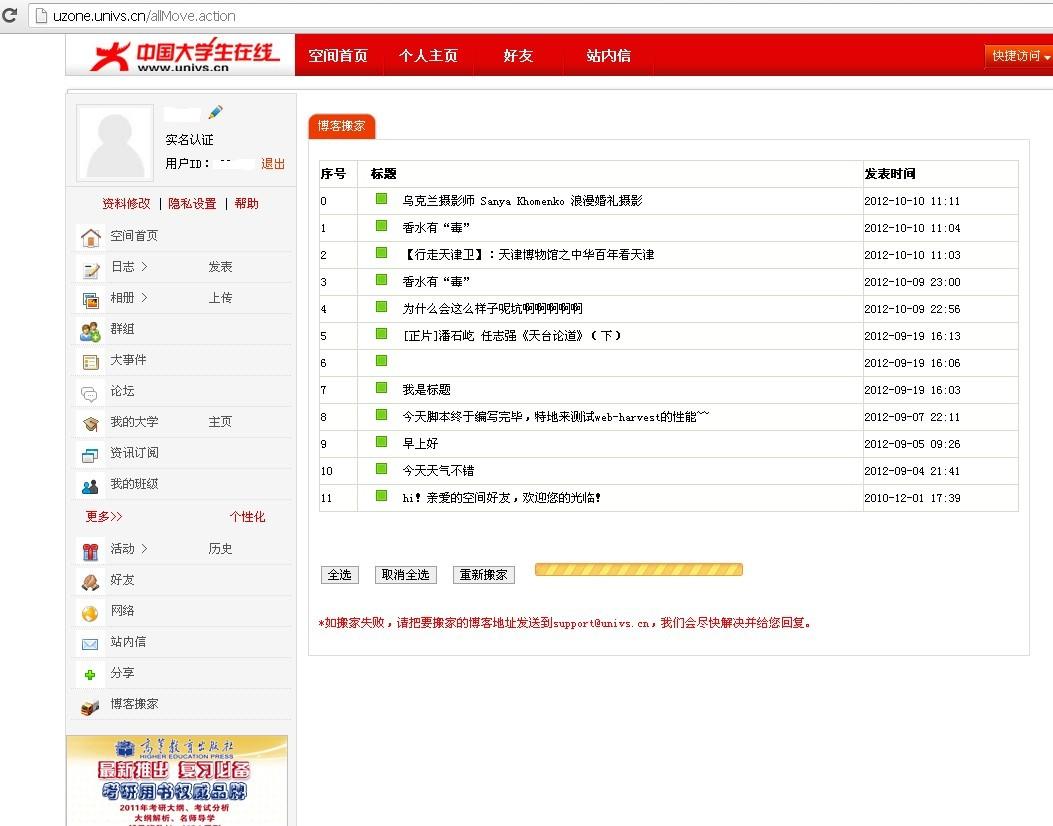
下面是项目的代码:其中用xpath匹配节点xquery获取内容,然后匹配下一篇的链接用html-to-xml获取下一篇,继续上面的循环,整个空间内容就扒下来了
1 <?xml version="1.0" encoding="UTF-8"?>
2 <config charset="UTF-8">
3 <!--
4 var-def path 存放路径
5 var-def maxloops 取出数目 填写0则为无限制 取出所有blog
6 var-def nextLinkUrl 第一篇链接
7 -->
8 <var-def name="path">/home/shaopeng/webharvest/axiong2007_12.xml</var-def>
9 <var-def name="maxloops">15</var-def>
10 <var-def name="nextLinkUrl"><template>http://hi.baidu.com/shaopeng1131/item/fc9f240e75f8eed0dde5b07a</template></var-def>
11 <file action="write" path="${path}" charset="utf-8">
12 <![CDATA[
13 <?xml version="1.0" encoding="UTF-8"?>
14 <bolgList>
15
16 ]]>
17 </file>
18
19 <while condition="${nextLinkUrl.toString().length() != 0}" maxloops="${maxloops}" index="i">
20 <empty>
21 <var-def name="content">
22 <html-to-xml>
23 <http url="${nextLinkUrl}" charset="utf8"/>
24 </html-to-xml>
25 </var-def>
26 <var-def name="pageUrl">
27 <var name="nextLinkUrl"/>
28 </var-def>
29 <var-def name="nextLinkUrl">
30 <xpath expression="//div[@class='detail-nav-pre']/a/@href">
31 <var name="content"/>
32 </xpath>
33 </var-def>
34 </empty>
35 <var-def name="ulList">
36
37 <xpath expression="//div[@class='mod-blogpage-wraper']">
38 <var name="content"/>
39 </xpath>
40 </var-def>
41 <loop item="item" index="i">
42 <list><var name="ulList"/></list>
43 <body>
44 <file action="append" path="${path}" charset="utf-8">
45
46 <xquery>
47 <xq-param name="blogURL" type="string">
48 <var name= "pageUrl"/>
49 </xq-param>
50 <xq-param name="item" type="node()"><var name="item"/></xq-param>
51 <xq-expression><![CDATA[
52 declare variable $item as node() external;
53 declare variable $blogURL as xs:string+ external;
54 let $date := data($item//div[@class='content-other-info']/span/text())
55 let $title := data($item//h2[@class='title content-title']/text())
56 let $content := data($item//div[@id='content'])
57
58 return
59 <blog>
60 <blogURL>{data($blogURL)}</blogURL>
61 <blogTitle>{data($title)}</blogTitle>
62 <blogDate>{data($date)}</blogDate>
63 <blogContent>{data($content)}</blogContent>
64 </blog>
65
66 ]]></xq-expression>
67 </xquery>
68 </file>
69 </body>
70 </loop>
71 </while>
72 <file action="append" path="${path}" charset="utf-8"><![CDATA[
73 </bolglist> ]]></file>
74 </config>
下面是测试出来的结果:http://hi.baidu.com/new/shaopeng1131
<?xml version="1.0" encoding="UTF-8"?>
<bolgList><blog>
<blogURL>http://hi.baidu.com/shaopeng1131/item/09c4dff06e0603ce0dd1c887</blogURL>
<blogTitle>今天脚本终于编写完毕,特地来测试web-harvest的性能~~</blogTitle>
<blogDate>2012-09-07 22:11</blogDate>
<blogContent>
经历了这么多天我写的脚本终于可以上阵了,虽然有的地方还是不太好
比如图片不支持,等等一系列问题,
好在可以备份文字内容了,
有需要的可以和我说一声哈~~,
帮你把所有的博客下载下来
</blogContent>
</blog><blog>
<blogURL>http://hi.baidu.com/shaopeng1131/item/fc9f240e75f8eed0dde5b07a</blogURL>
<blogTitle>早上好</blogTitle>
<blogDate>2012-09-05 09:26</blogDate>
<blogContent>
早上好啊
</blogContent>
</blog><blog>
<blogURL>http://hi.baidu.com/shaopeng1131/item/68a77e147edc0d6271d5e8bf</blogURL>
<blogTitle>今天天气不错</blogTitle>
<blogDate>2012-09-04 21:41</blogDate>
<blogContent>
今天天气不错今天天气不错
</blogContent>
</blog><blog>
<blogURL>http://hi.baidu.com/shaopeng1131/item/ec7b2fbb7f68024e2aebe3fd</blogURL>
<blogTitle>hi!亲爱的空间好友,欢迎您的光临!</blogTitle>
<blogDate>2010-12-01 17:39</blogDate>
<blogContent>
亲爱的hier们,
今天是个值得纪念的日子,因为我在百度空间上安了家。
我来自百度空间,很高兴成为空间大家庭的一员,今后我会在空间上用文字、图片、动感影集记录和展示一个最真实的我;我也会与真诚的hier们交流分享我的心情和身边趣闻,我希望能在这里认识新朋友,开始一段新的旅程!
希望大家常来看看,我一定会回访哦^_^!如果觉得不错,就把我加为您的好友吧,我期待认识更多新朋友!
我的主页网址是http://hi.baidu.com/shaopeng1131,欢迎常来!
</blogContent>
</blog></bolglist>
这是刚刚接触这个行业所进行的第一个项目,虽然那时候啥也不懂,都是在网上找各种介绍,看web-harvest 的文档,花费了好多时间,不过都值得,
仍然有一点儿,就是不知道web-harvest怎么整合进去的,通过web运行后台的程序抓取?
web-harvest下载链接 http://web-harvest.sourceforge.net/download.php
Webharvest网络爬虫应用总结,web-harvest 编写脚本 读取 百度 博客 实例的更多相关文章
- 网络爬虫:使用Scrapy框架编写一个抓取书籍信息的爬虫服务
上周学习了BeautifulSoup的基础知识并用它完成了一个网络爬虫( 使用Beautiful Soup编写一个爬虫 系列随笔汇总 ), BeautifulSoup是一个非常流行的Python网 ...
- 知道创宇爬虫题--代码持续更新中 - littlethunder的专栏 - 博客频道 - CSDN.NET
知道创宇爬虫题--代码持续更新中 - littlethunder的专栏 - 博客频道 - CSDN.NET undefined 公司介绍 - 数人科技 undefined
- Extjs 3.4 和 web SSH(Ajaxterm)-howge-ChinaUnix博客
Extjs 3.4 和 web SSH(Ajaxterm)-howge-ChinaUnix博客 Extjs 3.4 和 web SSH(Ajaxterm) 2013-04-07 15:20:17 ...
- selenium-java web自动化测试工具抓取百度搜索结果实例
selenium-java web自动化测试工具抓取百度搜索结果实例 这种方式抓百度的搜索关键字结果非常容易抓长尾关键词,根据热门关键词去抓更多内容可以用抓google,百度的这种内容容易给屏蔽,用这 ...
- 简单的网络爬虫程序(Web Crawlers)
程序比较简单,但是能体现基本原理. package com.wxisme.webcrawlers; import java.io.*; import java.net.*; /** * Web Cra ...
- [Python]网络爬虫(六):一个简单的百度贴吧的小爬虫
转自:http://blog.csdn.net/pleasecallmewhy/article/details/8927832 # -*- coding: utf-8 -*- #----------- ...
- [Python]网络爬虫(四):Opener与Handler的介绍和实例应用
在开始后面的内容之前,先来解释一下urllib2中的两个个方法:info and geturl urlopen返回的应答对象response(或者HTTPError实例)有两个很有用的方法info() ...
- [Python]网络爬虫(四):Opener与Handler的介绍和实例应用(转)
在开始后面的内容之前,先来解释一下urllib2中的两个个方法:info and geturl urlopen返回的应答对象response(或者HTTPError实例)有两个很有用的方法info() ...
- 网络搬砖是件苦力活 CMS推荐GHOS博客程序
搬砖不是技术活,而是苦力(bi)活,富有技术含量的苦力活说不定就是一门可以持续的生意. 我们不生产内容,我们只是互联网的内容搬运工,这是大部分不具备原创能力个人站长的心声.虽然原创能力不够,但是服务目 ...
随机推荐
- 洛谷 P1202 [USACO1.1]黑色星期五Friday the Thirteenth 题解
题目传送门 这道题暴力就能解决. #include<bits/stdc++.h> using namespace std; int xi; ,ans[]; int main() { int ...
- [你必须知道的.NET]第二十三回:品味细节,深入.NET的类型构造器
发布日期:2008.11.2 作者:Anytao © 2008 Anytao.com ,Anytao原创作品,转贴请注明作者和出处. 说在,开篇之前 今天Artech兄在<关于Type Init ...
- java中Property类的基本用法
1 配置.properties文件 2 获取输入流的方法 1)FileInputStream fi = new FileInputStream(properties文件路径); 2)InputStre ...
- python lxml教程
目前有很多xml,html文档的parser,如标准库的xml.etree , beautifulsoup , 还有lxml. 都用下来感觉lxml不错,速度也还行,就他了. 围绕三个问题: 问题 ...
- java EE : http 协议之请求报文、响应报文
1 HTTP协议特点 1)客户端->服务端(请求request)有三部份 a)请求行 b)请求头 c)请求的内容,如果没有,就是空白字符 2)服务端->客户端(响应response)有三部 ...
- Codeforces Round #491 (Div. 2) E - Bus Number + 反思
E - Bus Number 最近感觉打CF各种车祸.....感觉要反思一下, 上次读错题,这次想当然地以为18!肯定暴了longlong 而没有去实践, 这个题我看到就感觉是枚举每个数字的个数,但是 ...
- ref:使用Dezender对zend加密后的php文件进行解密
ref:http://www.cnblogs.com/88223100/ 使用Dezender对zend加密后的php文件进行解密 在开发中需要修改一些php文件,部分是通过zend加密的,记事本 ...
- PBR Step by Step(三)BRDFs
BRDF BRDF(Bidirectional Reflectance Distribution Function)双向反射分布函数,用来描述给定入射方向上的入射辐射度以及反射方向上的出辐射度分布,B ...
- am335xSD卡启动--文件系统制作
1.网上下载busybox工具https://busybox.net/downloads/ 2.根据此文章提示制作自己的跟文件系统 链接: https://pan.baidu.com/s/1bp6GK ...
- 使用JDBC连接数据库的一些BUG
题记:前几天用JDBC连接MYSQL数据库的时候,出现了一些BUG,有代码层次的,也有设置层次的, 下面的解决方法时我目前所遇到的,后期如果还有遇到的会进行补充. 一.出现:远程mysql_java. ...