015:索引、B+树
一. 索引
1. 索引的定义
索引是一种单独的、物理的对数据库表中
一列或多列的值进行排序的一种存储结构,它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容。
2. 二分查找
二分查找法(binary search)也称为折半查找法,用来查找一组有序的记录数组中的某一记录,其基本思想是:将记录按有序化(递增或递减)排列,在查找过程中采用跳跃式方式查找,即先以有序数列的中点位置作为比较对象,如果要找的元素值小于该中点元素,则将待查序列缩小为左半部分,否则为右半部分。通过一次比较,将查找区间缩小一半。(O(logN)的时间复杂度)
# 给出一个例子,注意该例子已经是升序排序的,且查找 数字 48
数据:5, 10, 19, 21, 31, 37, 42, 48, 50, 52
下标:0, 1, 2, 3, 4, 5, 6, 7, 8, 9
步骤一:设
low为下标最小值0,high为下标最大值9;步骤二:通过
low和high得到mid,mid=(low + high)/ 2,初始时mid为下标4(也可以=5,看具体算法实现);步骤三:
mid=4对应的数据值是31,31 < 48(我们要找的数字);步骤四:通过二分查找的思路,将
low设置为31对应的下标4,high保持不变为9,此时mid为6;步骤五:
mid=6对应的数据值是42,42 < 48(我们要找的数字);步骤六:通过二分查找的思路,将
low设置为42对应的下标6,high保持不变为9,此时mid为7;步骤七:
mid=7对应的数据值是48,48 == 48(我们要找的数字),查找结束;
- 通过3次
二分查找就找到了我们所要的数字,而顺序查找需8次.
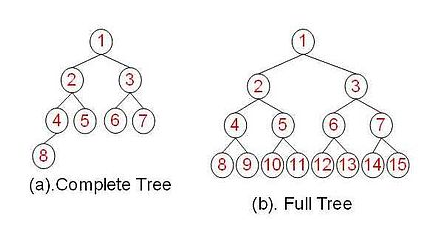
二. Binary Tree(二叉树)
1. 二叉树的定义
每个节点至多只有
二棵子树;二叉树的子树有
左右之分,次序不能颠倒;一棵深度为
k,且有$2^k-1$个节点,称为满二叉树(Full Tree);一棵深度为
k,且root到k-1层的节点树都达到最大,第k层的所有节点都连续集中在最左边,此时为完全二叉树(Complete Tree)
2. 平衡二叉树(AVL-树)
左子树和右子树都是平衡二叉树;
左子树和右子树的高度差绝对值不超过1;
- 平衡二叉树
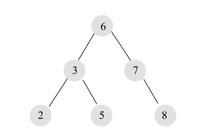
- 非平衡二叉树
平衡二叉树的遍历
以上面平衡二叉树的图例为样本,进行遍历:
前序:6, 3, 2, 5, 7, 8(ROOT节点在开头,中-左-右 顺序)中序:2, 3, 5,6, 7, 8(中序遍历即为升序,左-中-右 顺序)后序:2, 5, 3, 8, 7,6(ROOT节点在结尾,左-右-中顺序)
1:可以通过
前序和中序或者是后序和中序来推导出一个棵树
2:
前序或者后序用来得到ROOT节点,中序可以区分左右子树
- 平衡二叉树的旋转
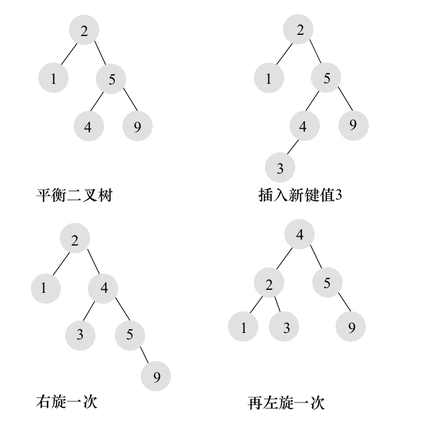
需要通过旋转(左旋,右旋)来维护平衡二叉树的平衡,在添加和删除的时候需要有额外的开销。
三. B树/B+树
注意:B树和B+树开头的
B不是Binary,而是Balance
3.1. B树的定义
阶为M (节点上关键字(Keys)的个数) 的B树的定义:
每个节点最多
有M个孩子;除了
root节点外,每个非叶子(non-leaf)节点至少含有(M/2)个孩子;如果
root节点不为空,则root节点至少要有两个孩子节点;一
个非叶子(non-leaf)节点如果含有K个孩子,则包含k-1个keys;所有叶子节点都在
同一层;B树中的
非叶子(non-leaf)节点也包含了数据部分;
3.2. B+树的定义
在B树的基础上,B+树做了如下改进
数据只存储在叶子节点上,非叶子节点只保存索引信息;
非叶子节点(索引节点)存储的只是一个Flag,不保存实际数据记录;索引节点指示该节点的左子树比这个Flag小,而右子树大于等于这个Flag
叶子节点本身按照数据的升序排序进行链接(串联起来);
- 叶子节点中的数据在
物理存储上是无序的,仅仅是在逻辑上有序(通过指针串在一起);
- 叶子节点中的数据在
3.3. B+树的作用
在
块设备上,通过B+树可以有效的存储数据;所有记录都存储在
叶子节点上,非叶子(non-leaf)存储索引(keys)信息;B+树含有非常高的
扇出(fanout),通常超过100,在查找一个记录时,可以有效的减少IO操作;
3.4. B+树的操作
- B+树的插入
B+树的插入必须保证插入后
叶子节点中的记录依然排序。插入操作步骤
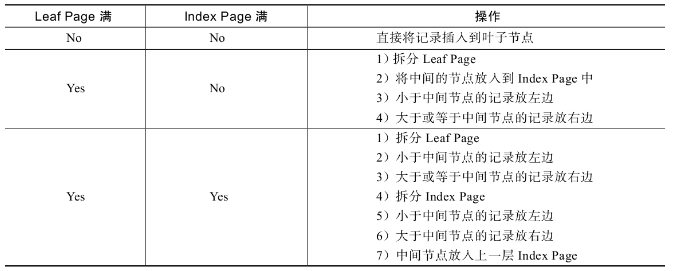
>B+树总是会保持平衡。但是为了保持平衡对于新插入的键值可能需要做大量的拆分页(split)操作;部分情况下可以通过B+树的旋转来替代拆分页操作,进而达到平衡效果。
B+树的删除
- B+树使用
填充因子(fill factor)来控制树的删除变化,50%是填充因子可设的最小值。B+树的删除操作同样必须保证删除后叶子节点中的记录依然排序。与插入不同的是,删除根据填充因子的变化来衡量。 - 删除操作步骤
- B+树使用

3.5. B+树的扇出(fan out)
- B+树图例
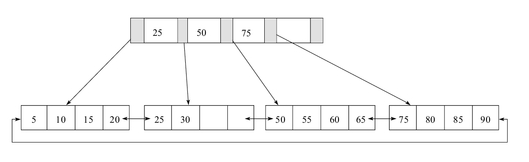
该 B+ 树高度为 2
每叶子页(LeafPage)4条记录
扇出数为5叶子节点(LeafPage)由小到大(有序)串联在一起
扇出是每个索引节点(Non-LeafPage)指向每个叶子节点(LeafPage)的指针扇出数= 索引节点(Non-LeafPage)可存储的最大关键字个数 + 1图例中的
索引节点(Non-LeafPage)最大可以存放4个关键字,但实际使用了3个;
3.6. B+树存储数据举例
假设B+树中页的大小是16K,每行记录是200Byte大小,求出树的高度为1,2,3,4时,分别可以存储多少条记录。
- 查看数据表中每行记录的平均大小
mysql gcdb@localhost:employees> show table status like '%employees%'\G;
***************************[ 1. row ]***************************
Name | employees
Engine | InnoDB
Version | 10
Row_format | Dynamic
Rows | 299423
Avg_row_length | 50 --平均一行记录
Data_length | 15220736
Max_data_length | 0
Index_length | 0
Data_free | 4194304
Auto_increment | <null>
Create_time | 2017-12-06 16:59:37
Update_time | 2017-12-06 16:59:43
Check_time | <null>
Collation | utf8_general_ci
Checksum | <null>
Create_options |
Comment |
高度为1
- 16K/200B 约等于
80个记录(数据结构元信息如指针等忽略不计)
- 16K/200B 约等于
高度为2
非叶子节点中存放的仅仅是一个索引信息,包含了
Key和Point指针;Point指针在MySQL中固定为6Byte。而Key我们这里假设为8Byte,则单个索引信息即为14个字节,KeySize = 14Byte高度为2,即有一个索引节点(索引页),和N个叶子节点
一个索引节点可以存放 16K / KeySize = 16K / 14B = 1142个索引信息,即有(1142 + 1)个扇出,以及有(1142 + 1)个叶子节点(数据页) (可以简化为1000)
数据记录数 = (16K / KeySize + 1)x (16K / 200B) 约等于 80W 个记录
高度为3
高度为3的B+树,即ROOT节点有1000个扇出,每个扇出又有1000个扇出指向叶子节点。每个节点是80个记录,所以一共有 8000W个记录
高度为4
同高度3一样,高度为4时的记录书为(8000 x 1000)W
上述的8000W等数据只是一个理论值。线上实际使用单个页的记录数字要乘以70%,即第二层需要70% x 70% ,依次类推。
因此在数据库中,B+树的高度一般都在2~4层,这也就是说查找某一键值的行记录时最多只需要2到4次IO,2~4次的IO意味着查询时间只需0.02~0.04秒(假设IOPS=100,当前SSD可以达到50000IOPS)。
从5.7开始,页的预留大小可以设置了,以减少split操作的概率(空间换时间)
四. MySQL索引
4.1. MySQL 创建索引
mysql gcdb@localhost:mytest> create table t_index01(id int,age int,name varchar(10));
Query OK, 0 rows affected
Time: 0.137s
mysql gcdb@localhost:mytest> select * from t_index01;
+----+-----+----------+
| id | age | name |
+----+-----+----------+
| 1 | 10 | xuliuyan |
| 2 | 20 | haozong |
| 3 | 30 | wudi |
+----+-----+----------+
3 rows in set
Time: 0.012s
mysql gcdb@localhost:mytest> explain select * from t_index01 \G;
***************************[ 1. row ]***************************
id | 1
select_type | SIMPLE
table | t_index01
partitions | <null>
type | ALL -- 看执行计划,使用的是扫描整张表的方式
possible_keys | <null>
key | <null>
key_len | <null>
ref | <null>
rows | 3
filtered | 100.0
Extra | <null>
1 row in set
Time: 0.012s
mysql gcdb@localhost:mytest> alter table t_index01 add index t_index01_inx_id(id); -- 给字段id添加普通索引。
Query OK, 0 rows affected
Time: 0.074s
mysql gcdb@localhost:mytest> explain select * from t_index01 where id =3 \G;
***************************[ 1. row ]***************************
id | 1
select_type | SIMPLE
table | t_index01
partitions | <null>
type | ref -- 看执行计划,使用索引t_index01_inx_id
possible_keys | t_index01_inx_id
key | t_index01_inx_id
key_len | 5
ref | const
rows | 1
filtered | 100.0
Extra | <null>
1 row in set
Time: 0.012s
-- 使用create index
mysql gcdb@localhost:mytest> explain select * from t_index01 where age =20\G; -- 同样age字段也没有索引
***************************[ 1. row ]***************************
id | 1
select_type | SIMPLE
table | t_index01
partitions | <null>
type | ALL
possible_keys | <null>
key | <null>
key_len | <null>
ref | <null>
rows | 3
filtered | 33.33
Extra | Using where
1 row in set
Time: 0.012s
mysql gcdb@localhost:mytest> create index t_index01_age on t_index01(age); -- 给age字段增加索引
Query OK, 0 rows affected
Time: 0.028s
mysql gcdb@localhost:mytest> explain select * from t_index01 where age =20\G;
***************************[ 1. row ]***************************
id | 1
select_type | SIMPLE
table | t_index01
partitions | <null>
type | ref
possible_keys | t_index01_age
key | t_index01_age -- 查看执行计划,使用的key为t_index01_age,走了索引
key_len | 5
ref | const
rows | 1
filtered | 100.0
Extra | <null>
1 row in set
Time: 0.012s
mysql gcdb@localhost:mytest>
4.2. MySQL 查看索引
--
-- 方式一
--
mysql gcdb@localhost:mytest> use dbt3;
You are now connected to database "dbt3" as user "gcdb"
Time: 0.002s
mysql gcdb@localhost:dbt3> desc orders;
+-----------------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------------+-------------+------+-----+---------+-------+
| o_orderkey | int(11) | NO | PRI | NULL | | -- 索引
| o_custkey | int(11) | YES | MUL | NULL | | -- 索引
| o_orderstatus | char(1) | YES | | NULL | |
| o_totalprice | double | YES | | NULL | |
| o_orderDATE | date | YES | MUL | NULL | | -- 索引
| o_orderpriority | char(15) | YES | | NULL | |
| o_clerk | char(15) | YES | | NULL | |
| o_shippriority | int(11) | YES | | NULL | |
| o_comment | varchar(79) | YES | | NULL | |
+-----------------+-------------+------+-----+---------+-------+
9 rows in set (0.00 sec)
--
-- 方式二
--
mysql gcdb@localhost:dbt3> show create table orders \G;
***************************[ 1. row ]***************************
Table | orders
Create Table | CREATE TABLE `orders` (
`o_orderkey` int(11) NOT NULL,
`o_custkey` int(11) DEFAULT NULL,
`o_orderstatus` char(1) DEFAULT NULL,
`o_totalprice` double DEFAULT NULL,
`o_orderDATE` date DEFAULT NULL,
`o_orderpriority` char(15) DEFAULT NULL,
`o_clerk` char(15) DEFAULT NULL,
`o_shippriority` int(11) DEFAULT NULL,
`o_comment` varchar(79) DEFAULT NULL,
PRIMARY KEY (`o_orderkey`), -- 索引
KEY `i_o_orderdate` (`o_orderDATE`), -- 索引
KEY `i_o_custkey` (`o_custkey`) -- 索引
) ENGINE=InnoDB DEFAULT CHARSET=latin1
1 row in set
Time: 0.038s
mysql gcdb@localhost:dbt3>
--
-- 方式三
--
mysql gcdb@localhost:dbt3> show index from orders\G;
***************************[ 1. row ]***************************
Table | orders
Non_unique | 0 -- 表示唯一
Key_name | PRIMARY -- key的name是primary
Seq_in_index | 1
Column_name | o_orderkey
Collation | A
Cardinality | 1369767 -- 基数,这个列上不同值的记录数
Sub_part | <null>
Packed | <null>
Null |
Index_type | BTREE -- 索引类型是BTree
Comment |
Index_comment |
***************************[ 2. row ]***************************
Table | orders
Non_unique | 1 -- Non_unique为True,表示不唯一
Key_name | i_o_orderdate
Seq_in_index | 1
Column_name | o_orderDATE
Collation | A
Cardinality | 2566
Sub_part | <null>
Packed | <null>
Null | YES
Index_type | BTREE
Comment |
Index_comment |
***************************[ 3. row ]***************************
Table | orders
Non_unique | 1
Key_name | i_o_custkey
Seq_in_index | 1
Column_name | o_custkey
Collation | A
Cardinality | 100450
Sub_part | <null>
Packed | <null>
Null | YES
Index_type | BTREE
Comment |
Index_comment |
(END)
mysql gcdb@localhost:dbt3> select count(*) from orders;
+----------+
| count(*) |
+----------+
| 1500000 | -- orders中有1500000条记录,和Cardinality 是不一致的
+----------+
1 row in set
Time: 3.682s
mysql gcdb@localhost:dbt3>
4.3. Cardinality(基数)
Cardinality表示该索引列上有多少不同的记录,这个是一个预估的值,是采样得到的(由InnoDB触发,采样20个页,进行预估),该值越大越好,即当Cardinality / RowNumber 越接近1越好,表示该列是高选择性的。
- 高选择性:身份证 、手机号码、姓名、订单号等
- 低选择性:性别、年龄等
即该列是否适合创建索引,就看该字段是否具有高选择性
mysql gcdb@localhost:dbt3> show create table lineitem\G
***************************[ 1. row ]***************************
Table | lineitem
Create Table | CREATE TABLE `lineitem` (
`l_orderkey` int(11) NOT NULL,
`l_partkey` int(11) DEFAULT NULL,
`l_suppkey` int(11) DEFAULT NULL,
`l_linenumber` int(11) NOT NULL,
`l_quantity` double DEFAULT NULL,
`l_extendedprice` double DEFAULT NULL,
`l_discount` double DEFAULT NULL,
`l_tax` double DEFAULT NULL,
`l_returnflag` char(1) DEFAULT NULL,
`l_linestatus` char(1) DEFAULT NULL,
`l_shipDATE` date DEFAULT NULL,
`l_commitDATE` date DEFAULT NULL,
`l_receiptDATE` date DEFAULT NULL,
`l_shipinstruct` char(25) DEFAULT NULL,
`l_shipmode` char(10) DEFAULT NULL,
`l_comment` varchar(44) DEFAULT NULL,
PRIMARY KEY (`l_orderkey`,`l_linenumber`), --两个列复合主键
KEY `i_l_shipdate` (`l_shipDATE`),
KEY `i_l_suppkey_partkey` (`l_partkey`,`l_suppkey`),
KEY `i_l_partkey` (`l_partkey`),
KEY `i_l_suppkey` (`l_suppkey`),
KEY `i_l_receiptdate` (`l_receiptDATE`),
KEY `i_l_orderkey` (`l_orderkey`),
KEY `i_l_orderkey_quantity` (`l_orderkey`,`l_quantity`),
KEY `i_l_commitdate` (`l_commitDATE`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
1 row in set
Time: 0.010s
mysql gcdb@localhost:dbt3> show index from lineitem\G
***************************[ 1. row ]***************************
Table | lineitem
Non_unique | 0
Key_name | PRIMARY
Seq_in_index | 1 -- 主键索引中的顺序,该列的顺序为1
Column_name | l_orderkey
Collation | A
Cardinality | 1352854
Sub_part | <null>
Packed | <null>
Null |
Index_type | BTREE
Comment |
Index_comment |
***************************[ 2. row ]***************************
Table | lineitem
Non_unique | 0
Key_name | PRIMARY
Seq_in_index | 2 -- 主键索引中的顺序,该列的顺序为2
Column_name | l_linenumber
Collation | A
Cardinality | 5629794
Sub_part | <null>
Packed | <null>
Null |
Index_type | BTREE
Comment |
Index_comment |
***************************[ 3. row ]***************************
Table | lineitem
Non_unique | 1
Key_name | i_l_shipdate
Seq_in_index | 1
Column_name | l_shipDATE
Collation | A
Cardinality | 2495
Sub_part | <null>
Packed | <null>
Null | YES
Index_type | BTREE
Comment |
对应当前例子
第一个索引(Seq_in_index = 1)的Cardinality的值表示当前列(l_orderkey)的不重复的值,
第二个索引(Seq_in_index = 2)的Cardinality的值表示前两列(l_orderkey)和(l_linenumber)不重复的值
--
-- SQL-1
--
mysql gcdb@localhost:dbt3> select l_orderkey,l_partkey,l_suppkey,l_linenumber,l_quantity,l_extendedprice,l_discount,l_tax,l_returnflag,l_linestatus,l_shipDATE,l_commitDATE,l_receiptDATE fr
-> om lineitem limit 10;
+------------+-----------+-----------+--------------+------------+-----------------+------------+-------+--------------+--------------+------------+--------------+---------------+
| l_orderkey | l_partkey | l_suppkey | l_linenumber | l_quantity | l_extendedprice | l_discount | l_tax | l_returnflag | l_linestatus | l_shipDATE | l_commitDATE | l_receiptDATE |
+------------+-----------+-----------+--------------+------------+-----------------+------------+-------+--------------+--------------+------------+--------------+---------------+
| 1 | 155190 | 7706 | 1 | 17.0 | 21168.23 | 0.04 | 0.02 | N | O | 1996-03-13 | 1996-02-12 | 1996-03-22 |
| 1 | 67310 | 7311 | 2 | 36.0 | 45983.16 | 0.09 | 0.06 | N | O | 1996-04-12 | 1996-02-28 | 1996-04-20 |
| 1 | 63700 | 3701 | 3 | 8.0 | 13309.6 | 0.1 | 0.02 | N | O | 1996-01-29 | 1996-03-05 | 1996-01-31 |
| 1 | 2132 | 4633 | 4 | 28.0 | 28955.64 | 0.09 | 0.06 | N | O | 1996-04-21 | 1996-03-30 | 1996-05-16 |
| 1 | 24027 | 1534 | 5 | 24.0 | 22824.48 | 0.1 | 0.04 | N | O | 1996-03-30 | 1996-03-14 | 1996-04-01 |
| 1 | 15635 | 638 | 6 | 32.0 | 49620.16 | 0.07 | 0.02 | N | O | 1996-01-30 | 1996-02-07 | 1996-02-03 |
| 2 | 106170 | 1191 | 1 | 38.0 | 44694.46 | 0.0 | 0.05 | N | O | 1997-01-28 | 1997-01-14 | 1997-02-02 |
| 3 | 4297 | 1798 | 1 | 45.0 | 54058.05 | 0.06 | 0.0 | R | F | 1994-02-02 | 1994-01-04 | 1994-02-23 |
| 3 | 19036 | 6540 | 2 | 49.0 | 46796.47 | 0.1 | 0.0 | R | F | 1993-11-09 | 1993-12-20 | 1993-11-24 |
| 3 | 128449 | 3474 | 3 | 27.0 | 39890.88 | 0.06 | 0.07 | A | F | 1994-01-16 | 1993-11-22 | 1994-01-23 |
+------------+-----------+-----------+--------------+------------+-----------------+------------+-------+--------------+--------------+------------+--------------+---------------+
10 rows in set
Time: 0.016s
--
-- SQL-2
--
mysql gcdb@localhost:dbt3> select l_orderkey, l_linenumber from lineitem limit 10;
+------------+--------------+
| l_orderkey | l_linenumber |
+------------+--------------+
| 721220 | 2 |
| 842980 | 4 |
| 904677 | 1 |
| 990147 | 1 |
| 1054181 | 1 |
| 1111877 | 3 |
| 1332613 | 1 |
| 1552449 | 2 |
| 2167527 | 3 |
| 2184032 | 5 |
+------------+--------------+
10 rows in set
Time: 0.011s
--- SQL-1和SQL-2其实都是在没有排序的情况下,取出前10条数据。但是结果不一样
--
-- SQL-3
--
mysql gcdb@localhost:dbt3> select l_orderkey, l_linenumber from lineitem order by l_orderkey limit 10;
-- 和上面的sql相比,多了一个order by的操作
+------------+--------------+
| l_orderkey | l_linenumber |
+------------+--------------+
| 1 | 1 | -----
| 1 | 2 | -- 看orderkey为1,对应的linenumber有6条
| 1 | 3 | -- 这就是orderkey的Cardinality仅为140W
| 1 | 4 | -- 而(orderkey + linenumber)就有580W
| 1 | 5 |
| 1 | 6 | -----
| 2 | 1 |
| 3 | 1 |
| 3 | 2 |
| 3 | 3 |
+------------+--------------+
10 rows in set (0.01 sec)
--- SQL-3 和SQL-2 不同的原因是 他们走了不同的索引
mysql gcdb@localhost:dbt3> explain select l_orderkey, l_linenumber from lineitem limit 10 \G;
***************************[ 1. row ]***************************
id | 1
select_type | SIMPLE
table | lineitem
partitions | <null>
type | index
possible_keys | <null>
key | i_l_shipdate -- 使用了shipdate进行了索引
key_len | 4
ref | <null>
rows | 5630402
filtered | 100.0
Extra | Using index
1 row in set
Time: 0.010s
mysql gcdb@localhost:dbt3> explain select l_orderkey, l_linenumber from lineitem order by l_orderkey limit 10\G;
***************************[ 1. row ]***************************
id | 1
select_type | SIMPLE
table | lineitem
partitions | <null>
type | index
possible_keys | <null>
key | i_l_orderkey -- 使用了orderkey进行了查询
key_len | 4
ref | <null>
rows | 10
filtered | 100.0
Extra | Using index
1 row in set
Time: 0.012s
mysql gcdb@localhost:dbt3> explain select * from lineitem limit 10\G
***************************[ 1. row ]***************************
id | 1
select_type | SIMPLE
table | lineitem
partitions | <null>
type | ALL -- 显示进行了全表扫描
possible_keys | <null>
key | <null>
key_len | <null>
ref | <null>
rows | 5630402
filtered | 100.0
Extra | <null>
1 row in set
Time: 0.012s
mysql gcdb@localhost:dbt3>
mysql gcdb@localhost:dbt3> analyze table lineitem;
+---------------+---------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+---------------+---------+----------+----------+
| dbt3.lineitem | analyze | status | OK |
+---------------+---------+----------+----------+
1 row in set
Time: 2.252s
mysql gcdb@localhost:dbt3>
innodb_on_state = off
在MySQL5.5之前,执行show create table操作会触发采样,而5.5之后将该参数off后,需要主动执行analyze table才会去采样。采样不会锁表或者锁记录。
4.4 复合索引
mysql gcdb@localhost:dbt3> show create table lineitem\G
***************************[ 1. row ]***************************
Table | lineitem
Create Table | CREATE TABLE `lineitem` (
`l_orderkey` int(11) NOT NULL,
`l_partkey` int(11) DEFAULT NULL,
`l_suppkey` int(11) DEFAULT NULL,
`l_linenumber` int(11) NOT NULL,
`l_quantity` double DEFAULT NULL,
`l_extendedprice` double DEFAULT NULL,
`l_discount` double DEFAULT NULL,
`l_tax` double DEFAULT NULL,
`l_returnflag` char(1) DEFAULT NULL,
`l_linestatus` char(1) DEFAULT NULL,
`l_shipDATE` date DEFAULT NULL,
`l_commitDATE` date DEFAULT NULL,
`l_receiptDATE` date DEFAULT NULL,
`l_shipinstruct` char(25) DEFAULT NULL,
`l_shipmode` char(10) DEFAULT NULL,
`l_comment` varchar(44) DEFAULT NULL,
PRIMARY KEY (`l_orderkey`,`l_linenumber`), --两个列复合主键
KEY `i_l_shipdate` (`l_shipDATE`),
KEY `i_l_suppkey_partkey` (`l_partkey`,`l_suppkey`),
KEY `i_l_partkey` (`l_partkey`),
KEY `i_l_suppkey` (`l_suppkey`),
KEY `i_l_receiptdate` (`l_receiptDATE`),
KEY `i_l_orderkey` (`l_orderkey`),
KEY `i_l_orderkey_quantity` (`l_orderkey`,`l_quantity`),
KEY `i_l_commitdate` (`l_commitDATE`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
1 row in set
Time: 0.010s
--
-- 复合索引举例
--
mysql gcdb@localhost:dbt3> use mytest;
You are now connected to database "mytest" as user "gcdb"
Time: 0.002s
mysql gcdb@localhost:mytest> create index idx_index01_id_age on t_index01(id,age); --创建复合索引
Query OK, 0 rows affected
Time: 0.009s
mysql gcdb@localhost:mytest> insert t_index01 values(1,11,'dangdangxu'),(2,12,'quannenghao'),(3,13,'paogeb
-> an'),(4,14,'xiaolaopo');
Query OK, 4 rows affected
Time: 0.003s
mysql gcdb@localhost:mytest> select * from t_index01;
+----+-----+------------+
| id | age | name |
+----+-----+------------+
| 1 | 10 | xuliuyan |
| 2 | 20 | haozong |
| 3 | 30 | wudi |
| 1 | 11 | dangdangxu |
| 2 | 12 | quannengha |
| 3 | 13 | paogeban |
| 4 | 14 | xiaolaopo |
+----+-----+------------+
7 rows in set
Time: 0.011s
mysql gcdb@localhost:mytest> drop index t_index01_inx_id on t_index01; --删除原先id列上索引t_index01_inx_id
You're about to run a destructive command.
Do you want to proceed? (y/n): y
Your call!
Query OK, 0 rows affected
Time: 0.055s
mysql gcdb@localhost:mytest> drop index t_index01_age on t_index01; --删除原先age列上索引t_index01_inx_age
You're about to run a destructive command.
Do you want to proceed? (y/n): y
Your call!
Query OK, 0 rows affected
Time: 0.005s
mysql gcdb@localhost:mytest> select * from t_index01 where id =2;
+----+-----+------------+
| id | age | name |
+----+-----+------------+
| 2 | 12 | quannengha |
| 2 | 20 | haozong |
+----+-----+------------+
2 rows in set
Time: 0.011s
mysql gcdb@localhost:mytest> explain select * from t_index01 where id =2 \G;
***************************[ 1. row ]***************************
id | 1
select_type | SIMPLE
table | t_index01
partitions | <null>
type | ref
possible_keys | idx_index01_id_age
key | idx_index01_id_age --走复合索引
key_len | 5
ref | const
rows | 2
filtered | 100.0
Extra | <null>
1 row in set
Time: 0.011s
mysql gcdb@localhost:mytest> explain select * from t_index01 where id =2 and age=12 \G;
***************************[ 1. row ]***************************
id | 1
select_type | SIMPLE
table | t_index01
partitions | <null>
type | ref
possible_keys | idx_index01_id_age
key | idx_index01_id_age --走复合索引
key_len | 10
ref | const,const
rows | 1
filtered | 100.0
Extra | <null>
1 row in set
Time: 0.012s
mysql gcdb@localhost:mytest> explain select * from t_index01 where age=12 \G;
***************************[ 1. row ]***************************
id | 1
select_type | SIMPLE
table | t_index01
partitions | <null>
type | ALL --不走索引,全表扫描
possible_keys | <null>
key | <null>
key_len | <null>
ref | <null>
rows | 7
filtered | 14.29
Extra | Using where
1 row in set
Time: 0.012s
mysql gcdb@localhost:mytest>
mysql gcdb@localhost:mytest> explain select * from t_index01 where id =2 or age=12 \G; --求并集
***************************[ 1. row ]***************************
id | 1
select_type | SIMPLE
table | t_index01
partitions | <null>
type | ALL -- 没有使用索引,因为age列没有索引,所以age列是走全表扫描的
possible_keys | idx_index01_id_age
key | <null>
key_len | <null>
ref | <null>
rows | 7
filtered | 35.71
Extra | Using where
1 row in set
Time: 0.013s
--
-- 覆盖索引
--
---- 还是只使用age列去做范围查询,发现是走索引了
mysql gcdb@localhost:mytest> explain select id,age from t_index01 where age>12 \G;
***************************[ 1. row ]***************************
id | 1
select_type | SIMPLE
table | t_index01
partitions | <null>
type | index
possible_keys | <null>
key | idx_index01_id_age
key_len | 10
ref | <null>
rows | 7
filtered | 33.33
Extra | Using where; Using index -- 覆盖索引
1 row in set
Time: 0.011s
mysql gcdb@localhost:mytest>
-- 因为要求select id列和age列,idx_index01_id_age索引包含了id的全部的记录的,即同过idx_index01_id_age索引也是可以得到id,age列的结果集
mysql gcdb@localhost:mytest> explain select id,age,name from t_index01 where age>12 \G;
***************************[ 1. row ]***************************
id | 1
select_type | SIMPLE
table | t_index01
partitions | <null>
type | ALL -- 查询 (id,age,name) 就没法使用(id,age)索引了,需要全表扫描age的值。
possible_keys | <null>
key | <null>
key_len | <null>
ref | <null>
rows | 7
filtered | 33.33
Extra | Using where
1 row in set
Time: 0.012s
mysql gcdb@localhost:mytest>
mysql gcdb@localhost:mytest> explain select id,age from t_index01 where id=1 and name='xuliuyan' \G;
***************************[ 1. row ]***************************
id | 1
select_type | SIMPLE
table | t_index01
partitions | <null>
type | ref
possible_keys | idx_index01_id_age
key | idx_index01_id_age -- 先用走索引通过id得到结果集,再用去name='xuliuyan'过滤
key_len | 5
ref | const
rows | 2
filtered | 14.29
Extra | Using where
1 row in set
Time: 0.013s
mysql gcdb@localhost:mytest>
mysql gcdb@localhost:mytest> explain select id,age from t_index01 where age =10 and name='xuliuyan' \G;
***************************[ 1. row ]***************************
id | 1
select_type | SIMPLE
table | t_index01
partitions | <null>
type | ALL --age和name列顺序age列开始,idx_index01_id_age索引扫描id列开始
possible_keys | <null>
key | <null>
key_len | <null>
ref | <null>
rows | 7
filtered | 14.29
Extra | Using where
1 row in set
Time: 0.012s
mysql gcdb@localhost:mytest>
五. information_schema
- information_schema 数据库相当于一个数据字典。保存了表的元信息。
mysql gcdb@localhost:mytest> use information_schema
You are now connected to database "information_schema" as user "gcdb"
Time: 0.002s
mysql gcdb@localhost:information_schema> show tables
+---------------------------------------+
| Tables_in_information_schema |
+---------------------------------------+
| CHARACTER_SETS |
| COLLATIONS |
| COLLATION_CHARACTER_SET_APPLICABILITY |
| COLUMNS |
| COLUMN_PRIVILEGES |
| ENGINES |
| EVENTS |
| FILES |
| GLOBAL_STATUS |
| GLOBAL_VARIABLES |
| KEY_COLUMN_USAGE |
| OPTIMIZER_TRACE |
| PARAMETERS |
| PARTITIONS |
| PLUGINS |
| PROCESSLIST |
| PROFILING |
| REFERENTIAL_CONSTRAINTS |
| ROUTINES |
| SCHEMATA |
| SCHEMA_PRIVILEGES |
| SESSION_STATUS |
| SESSION_VARIABLES |
| STATISTICS |
| TABLES |
| TABLESPACES |
| TABLE_CONSTRAINTS |
| TABLE_PRIVILEGES |
| TRIGGERS |
| USER_PRIVILEGES |
| VIEWS |
| INNODB_LOCKS |
| INNODB_TRX |
| INNODB_SYS_DATAFILES |
| INNODB_FT_CONFIG |
| INNODB_SYS_VIRTUAL |
| INNODB_CMP |
| INNODB_FT_BEING_DELETED |
| INNODB_CMP_RESET |
| INNODB_CMP_PER_INDEX |
| INNODB_CMPMEM_RESET |
| INNODB_FT_DELETED |
| INNODB_BUFFER_PAGE_LRU |
| INNODB_LOCK_WAITS |
| INNODB_TEMP_TABLE_INFO |
| INNODB_SYS_INDEXES |
| INNODB_SYS_TABLES |
| INNODB_SYS_FIELDS |
| INNODB_CMP_PER_INDEX_RESET |
| INNODB_BUFFER_PAGE |
| INNODB_FT_DEFAULT_STOPWORD |
| INNODB_FT_INDEX_TABLE |
| INNODB_FT_INDEX_CACHE |
| INNODB_SYS_TABLESPACES |
| INNODB_METRICS |
| INNODB_SYS_FOREIGN_COLS |
| INNODB_CMPMEM |
| INNODB_BUFFER_POOL_STATS |
| INNODB_SYS_COLUMNS |
| INNODB_SYS_FOREIGN |
| INNODB_SYS_TABLESTATS |
+---------------------------------------+
61 rows in set
Time: 0.011s
--例如:查看employees表的索引信息
mysql gcdb@localhost:information_schema> select CONSTRAINT_SCHEMA,CONSTRAINT_NAME,TABLE_SCHEMA,COLUMN_NAME,ORDINAL_POSITION from key_column_usage where table_schema='employees' limit 10; -- 显示索引的信息
+-------------------+---------------------+--------------+-------------+------------------+
| CONSTRAINT_SCHEMA | CONSTRAINT_NAME | TABLE_SCHEMA | COLUMN_NAME | ORDINAL_POSITION |
+-------------------+---------------------+--------------+-------------+------------------+
| employees | PRIMARY | employees | dept_no | 1 |
| employees | dept_name | employees | dept_name | 1 |
| employees | PRIMARY | employees | emp_no | 1 |
| employees | PRIMARY | employees | dept_no | 2 |
| employees | dept_emp_ibfk_1 | employees | emp_no | 1 |
| employees | dept_emp_ibfk_2 | employees | dept_no | 1 |
| employees | PRIMARY | employees | emp_no | 1 |
| employees | PRIMARY | employees | dept_no | 2 |
| employees | dept_manager_ibfk_1 | employees | emp_no | 1 |
| employees | dept_manager_ibfk_2 | employees | dept_no | 1 |
+-------------------+---------------------+--------------+-------------+------------------+
10 rows in set
Time: 0.013s
mysql gcdb@localhost:information_schema>
5.1 问题
5.1.1 哪张数据表中记录了Cardinality信息?
mysql gcdb@localhost:information_schema> select * from `STATISTICS` limit 2 \G;
***************************[ 1. row ]***************************
TABLE_CATALOG | def
TABLE_SCHEMA | dbt3
TABLE_NAME | customer
NON_UNIQUE | 0
INDEX_SCHEMA | dbt3
INDEX_NAME | PRIMARY
SEQ_IN_INDEX | 1
COLUMN_NAME | c_custkey
COLLATION | A
CARDINALITY | 148473
SUB_PART | <null>
PACKED | <null>
NULLABLE |
INDEX_TYPE | BTREE
COMMENT |
INDEX_COMMENT |
***************************[ 2. row ]***************************
TABLE_CATALOG | def
TABLE_SCHEMA | dbt3
TABLE_NAME | customer
NON_UNIQUE | 1
INDEX_SCHEMA | dbt3
INDEX_NAME | i_c_nationkey
SEQ_IN_INDEX | 1
COLUMN_NAME | c_nationkey
COLLATION | A
CARDINALITY | 24
SUB_PART | <null>
PACKED | <null>
NULLABLE | YES
INDEX_TYPE | BTREE
COMMENT |
INDEX_COMMENT |
2 rows in set
Time: 0.032s
5.1.2 判断线上的索引是否有创建的必要?
MySQL 5.7 STATISTICS表记录了各个索引的CARDINALITY值
SQL如下:
SELECT
t.TABLE_SCHEMA,
t.TABLE_NAME,
INDEX_NAME,
CARDINALITY,
TABLE_ROWS,
CARDINALITY / TABLE_ROWS AS SELECTIVITY
FROM
TABLES t,
(SELECT
table_schema, table_name, index_name, cardinality
FROM
STATISTICS
WHERE
(table_schema , table_name, index_name, seq_in_index) IN (SELECT
table_schema, table_name, index_name, MAX(seq_in_index)
FROM
STATISTICS
GROUP BY table_schema , table_name , index_name)) s
WHERE
t.table_schema = s.table_schema
AND t.table_name = s.table_name
AND t.table_schema = 'employees'
ORDER BY SELECTIVITY;
- SQL解释:
- 从
information_schema.TABLES表中获取table_schema,table_name,table_rows等信息。
mysql gcdb@localhost:information_schema> show create table TABLES\G
***************************[ 1. row ]***************************
Table | TABLES
Create Table | CREATE TEMPORARY TABLE `TABLES` (
`TABLE_CATALOG` varchar(512) NOT NULL DEFAULT '',
`TABLE_SCHEMA` varchar(64) NOT NULL DEFAULT '', -- 表所在的库
`TABLE_NAME` varchar(64) NOT NULL DEFAULT '', -- 表名
`TABLE_TYPE` varchar(64) NOT NULL DEFAULT '',
`ENGINE` varchar(64) DEFAULT NULL,
`VERSION` bigint(21) unsigned DEFAULT NULL,
`ROW_FORMAT` varchar(10) DEFAULT NULL,
`TABLE_ROWS` bigint(21) unsigned DEFAULT NULL, -- 表的记录数
`AVG_ROW_LENGTH` bigint(21) unsigned DEFAULT NULL,
`DATA_LENGTH` bigint(21) unsigned DEFAULT NULL,
`MAX_DATA_LENGTH` bigint(21) unsigned DEFAULT NULL,
`INDEX_LENGTH` bigint(21) unsigned DEFAULT NULL,
`DATA_FREE` bigint(21) unsigned DEFAULT NULL,
`AUTO_INCREMENT` bigint(21) unsigned DEFAULT NULL,
`CREATE_TIME` datetime DEFAULT NULL,
`UPDATE_TIME` datetime DEFAULT NULL,
`CHECK_TIME` datetime DEFAULT NULL,
`TABLE_COLLATION` varchar(32) DEFAULT NULL,
`CHECKSUM` bigint(21) unsigned DEFAULT NULL,
`CREATE_OPTIONS` varchar(255) DEFAULT NULL,
`TABLE_COMMENT` varchar(2048) NOT NULL DEFAULT ''
) ENGINE=MEMORY DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
2.从information.STATISTICS获取table_schema和 table_name 信息
mysql gcdb@localhost:information_schema> show create table STATISTICS \G;
***************************[ 1. row ]***************************
Table | STATISTICS
Create Table | CREATE TEMPORARY TABLE `STATISTICS` (
`TABLE_CATALOG` varchar(512) NOT NULL DEFAULT '',
`TABLE_SCHEMA` varchar(64) NOT NULL DEFAULT '', -- 表所在的库
`TABLE_NAME` varchar(64) NOT NULL DEFAULT '', -- 表名
`NON_UNIQUE` bigint(1) NOT NULL DEFAULT '0',
`INDEX_SCHEMA` varchar(64) NOT NULL DEFAULT '',
`INDEX_NAME` varchar(64) NOT NULL DEFAULT '', -- 索引名
`SEQ_IN_INDEX` bigint(2) NOT NULL DEFAULT '0',
`COLUMN_NAME` varchar(64) NOT NULL DEFAULT '',
`COLLATION` varchar(1) DEFAULT NULL,
`CARDINALITY` bigint(21) DEFAULT NULL,
`SUB_PART` bigint(3) DEFAULT NULL,
`PACKED` varchar(10) DEFAULT NULL,
`NULLABLE` varchar(3) NOT NULL DEFAULT '',
`INDEX_TYPE` varchar(16) NOT NULL DEFAULT '',
`COMMENT` varchar(16) DEFAULT NULL,
`INDEX_COMMENT` varchar(1024) NOT NULL DEFAULT ''
) ENGINE=MEMORY DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
- 将
TABLES和STATISTICS表中的table_schema和table_name相关联并通过Cardinality和table_rows计算,即可得到对应索引名
- 3.1 因为存在
复合索引,所以我们要取出复合索引中seq最大的哪个值,取出的cardinality值才是最大的
mysql gcdb@localhost:information_schema> SELECT
-> table_schema, table_name, index_name, MAX(seq_in_index)
-> FROM
-> information_schema.STATISTICS
-> GROUP BY table_schema , table_name , index_name limit 10;
+--------------+------------+-----------------------+-------------------+
| table_schema | table_name | index_name | MAX(seq_in_index) |
+--------------+------------+-----------------------+-------------------+
| dbt3 | customer | i_c_nationkey | 1 |
| dbt3 | customer | PRIMARY | 1 |
| dbt3 | lineitem | i_l_commitdate | 1 |
| dbt3 | lineitem | i_l_orderkey | 1 |
| dbt3 | lineitem | i_l_orderkey_quantity | 2 |
| dbt3 | lineitem | i_l_partkey | 1 |
| dbt3 | lineitem | i_l_receiptdate | 1 |
| dbt3 | lineitem | i_l_shipdate | 1 |
| dbt3 | lineitem | i_l_suppkey | 1 |
| dbt3 | lineitem | i_l_suppkey_partkey | 2 |
+--------------+------------+-----------------------+-------------------+
10 rows in set
Time: 0.023s
mysql gcdb@localhost:information_schema>
- 3.2 得到了
最大的seq值,从而可以取出对应的cardinality值
mysql gcdb@localhost:information_schema>SELECT
-> table_schema,
-> table_name,
-> index_name,
-> cardinality
-> FROM
-> information_schema.STATISTICS
-> WHERE
-> ( table_schema, table_name, index_name, seq_in_index ) IN ( SELECT table_schema, table_name, index_name, MAX( seq_in_index ) FROM information_schema.STATISTICS GROUP BY table_schema, table_name, index_name )
-> LIMIT 10;
+--------------+------------+-----------------------+-------------+
| table_schema | table_name | index_name | cardinality |
+--------------+------------+-----------------------+-------------+
| dbt3 | customer | PRIMARY | 148473 |
| dbt3 | customer | i_c_nationkey | 24 |
| dbt3 | lineitem | PRIMARY | 5945476 |
| dbt3 | lineitem | i_l_shipdate | 2496 |
| dbt3 | lineitem | i_l_suppkey_partkey | 804391 |
| dbt3 | lineitem | i_l_partkey | 204210 |
| dbt3 | lineitem | i_l_suppkey | 12014 |
| dbt3 | lineitem | i_l_receiptdate | 2501 |
| dbt3 | lineitem | i_l_orderkey | 1503736 |
| dbt3 | lineitem | i_l_orderkey_quantity | 5293710 |
+--------------+------------+-----------------------+-------------+
10 rows in set
Time: 0.130s
mysql gcdb@localhost:information_schema>
- 3.3 最后通过
table_schema和table_name让上述的信息和TABLES表进行关联,获取employees库的所有使用情况
mysql gcdb@localhost:information_schema> SELECT
-> t.TABLE_SCHEMA,
-> t.TABLE_NAME,
-> INDEX_NAME,
-> CARDINALITY,
-> TABLE_ROWS,
-> CARDINALITY / TABLE_ROWS AS SELECTIVITY
-> FROM
-> TABLES t,
-> (
-> SELECT
-> table_schema,
-> table_name,
-> index_name,
-> cardinality
-> FROM
-> STATISTICS
-> WHERE
-> ( table_schema, table_name, index_name, seq_in_index ) IN ( SELECT table_schema, table_name, index_name, MAX( seq_in_index ) FROM STATISTICS GROUP BY table_schema, table_name, index_name )
-> ) s
-> WHERE
-> t.table_schema = s.TABLE_schema
-> AND t.table_name = s.table_name
-> AND t.table_schema = 'employees'
-> ORDER BY
-> SELECTIVITY;
+--------------+--------------+------------+-------------+------------+-------------+
| TABLE_SCHEMA | TABLE_NAME | index_name | cardinality | TABLE_ROWS | SELECTIVITY |
+--------------+--------------+------------+-------------+------------+-------------+
| employees | dept_emp | dept_no | 8 | 331143 | 0.0000 |
| employees | dept_manager | dept_no | 9 | 24 | 0.3750 |
| employees | departments | dept_name | 9 | 9 | 1.0000 |
| employees | titles | PRIMARY | 442843 | 442843 | 1.0000 |
| employees | dept_manager | PRIMARY | 24 | 24 | 1.0000 |
| employees | newsal | PRIMARY | 2838045 | 2838045 | 1.0000 |
| employees | dept_emp | PRIMARY | 331143 | 331143 | 1.0000 |
| employees | departments | PRIMARY | 9 | 9 | 1.0000 |
| employees | salaries | PRIMARY | 2838426 | 2838426 | 1.0000 |
| employees | employees | PRIMARY | 299423 | 299423 | 1.0000 |
+--------------+--------------+------------+-------------+------------+-------------+
10 rows in set
Time: 1.589s
mysql gcdb@localhost:information_schema>
- 通过最后一列的
SELECTIVITY是否接近1,判断该索引创建是否合理 - 注意:
Cardinality和table_rows的值,都是通过随机采样,预估得到的- 当
analyze前后,Cardinality值相差较多,说明该索引是不应该被创建的(页上的记录数值分布不平) - 推荐
SELECTIVITY 15%以上是适合的
015:索引、B+树的更多相关文章
- MySQL索引-B+树(看完你就明白了)
索引是一种数据结构,用于帮助我们在大量数据中快速定位到我们想要查找的数据.索引最形象的比喻就是图书的目录了.注意这里的大量,数据量大了索引才显得有意义,如果我想要在 [1,2,3,4] 中找到 4 这 ...
- 数据库索引B+树
面试时无意间被问到了这个问题:数据库索引的存储结构一般是B+树,为什么不适用红黑树等普通的二叉树? 经过和同学的讨论,得到如下几个情况: 1. 数据库文件是放在硬盘上,每次读取数据库都需要在磁盘上搜索 ...
- mysql索引 b+树
1.B+树基本概念 B+树的语言定义比较复杂,简单的说是为磁盘存取设计的平衡二叉树 网上经典图,黄色p1 p2 p3代表指针,蓝色的代表磁盘,里面包含数据项,第一层17,35,p1就代表小于17的,p ...
- MySQL 深入理解索引B+树存储 (转载))
出处:http://blog.codinglabs.org/articles/theory-of-mysql-index.html 摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一 ...
- 数据库索引 B+树
问题1.数据库为什么要设计索引?索引类似书本目录,用于提升数据库查找速度.问题2.哈希(hash)比树(tree)更快,索引结构为什么要设计成树型?加快查找速度的数据结构,常见的有两类:(1)哈希,例 ...
- 好文 | MySQL 索引B+树原理,以及建索引的几大原则
Java技术栈 www.javastack.cn 优秀的Java技术公众号 来源:小宝鸽 blog.csdn.net/u013142781/article/details/51706790 MySQL ...
- 怎么得到InnoDB主键索引B+树的高度?
上面我们通过推断得出B+树的高度通常是1-3,下面我们从另外一个侧面证明这个结论.在InnoDB的表空间文件中,约定page number为3的代表主键索引的根页,而在根页偏移量为64的地方存放了该B ...
- 搞懂MySQL InnoDB B+树索引
一.InnoDB索引 InnoDB支持以下几种索引: B+树索引 全文索引 哈希索引 本文将着重介绍B+树索引.其他两个全文索引和哈希索引只是做简单介绍一笔带过. 哈希索引是自适应的,也就是说这个不能 ...
- [MySQL] 索引中的b树索引
1.索引如果没有特别指明类型,一般是说b树索引,b树索引使用b树数据结构存储数据,实际上很多存储引擎使用的是b+树,每一个叶子节点都包含指向下一个叶子节点的指针,从而方便叶子节点的范围遍历 2.底层的 ...
- 一步步分析为什么B+树适合作为索引的结构
在MySQL中,主要有四种类型的索引,分别为:B-Tree索引,Hash索引,Fulltext索引和R-Tree索引,本文讲的是B-Tree索引. 什么是索引 索引(Index)是帮助数据库高效获取数 ...
随机推荐
- 启动Windows防火墙提示“0x8007042c"
win8.1 启动防火墙是报错:启动Windows防火墙提示“0x8007042c" 一.检查服务 1,右击开始->运行->输入“services.msc” 打开服务 在框中找到 ...
- 轻量级网络 - PVANet & SuffleNet
一. PVANet 论文:PVANET: Deep but Lightweight Neural Networks for Real-time Object Detection [点击下载] C ...
- Ubuntu循环登录libGL error: fbConfigs swrast等
Ubuntu16.04更新NVIDIA驱动后,无法进入桌面,使用vim .xsession-errors 查看错误信息,如下: libGL error: No matching fbConfigs o ...
- vim 强大复制链接
参考文献: http://blog.csdn.net/xiyuan1999/article/details/5680102 vi编辑器中的整行(多行)复制与粘贴就非常必要了. 1.复制 1)单行复制 ...
- Python3 移动文件——合集
文件/文件夹操作头文件 import os import shutil 参考 Python3批量移动指定文件到指定文件夹
- 用pip安装python 模块OpenSSL
windows下 1.配置好pip命令 下载安装 pip‑1.5.6.win‑amd64‑py2.7.exeor pip‑1.5.6.win32‑py2.7.exe 装好在C:\Python27\Sc ...
- phpcms v9取消验证码
phpcms/modules/admin/index.php// $code = isset($_POST['code']) && trim($_POST['code']) ? tri ...
- [持续更新]Python 笔记
本文以 Python 2.7 为基础. lambda 函数实现递归 方法一:传递一个 self 参数 求阶乘: frac = lambda self, x: self(self, x - 1) * x ...
- BZOJ5281: [Usaco2018 Open]Talent Show(01分数规划&DP)
5281: [Usaco2018 Open]Talent Show Time Limit: 10 Sec Memory Limit: 128 MBSubmit: 166 Solved: 124[S ...
- 剑指offer第六章
剑指offer第六章 1.数字在排序数组中出现的次数 统计一个数字在排序数组中出现的次数.例如输入排序数组{1,2,3,3,3,3,4,5}和数字3,由于3在数组中出现了4次,所以输出4 分析:思路1 ...