python笔记-12 redis缓存
一、redis引入
1、简要概括redis
1.1 redis默认端口:6379
1.2 redis实现的效果:资源共享
1.3 redis实现的基本原理:不同的进程和一个公共的进程之间建立socket,用来实现完成不同进程之间的资源共享
1.4 redis是一个单线程异步执行的程序,其效率为每秒处理50-80w个请求
2、redis需要掌握的几大块内容
2.1 string操作
2.2 hash操作
2.3 list操作
2.4 set操作
2.5 sore set操作 (有序集合)
2.6 管道
2.7 发布订阅
3、redis的使用(安装方式及使用方式)
安装方式:此处不描述redis的安装方法了,windows使用msi格式直接安装后运行redis-cli.exe即可,linux中方式类似
使用方式:set与get
作为引入,此处先介绍set与get,set为设置一个string类型的变量,get为获取这个string类型变量的值
127.0.0.1:[]> set k1
OK
127.0.0.1:[]> set k2
OK
127.0.0.1:[]> get k1
""
127.0.0.1:[]> get k2
""
4、python中对redis的操作模块---redis
同样此处先描述get与set的使用,需要建立一个连接,标明redis服务器的ip和端口号
import redis
conn=redis.Redis(host='192.168.99.106',port='')
#正常的set和get
conn.set('k1','v1')
print(conn.get('k1'))
5、socket池的使用
通常,我们在进行redis操作的时候,需要多次设置值和取值,如果每次操作都进行socket连接,会有大量时间被浪费在建立连接的过程中。
此时,我们建立一个socket_pool,可以理解为预先将连接建立好,我们要对redis操作时,直接从pool中取出已有的连接即可操作,可以节省时间
import redis
pool=redis.ConnectionPool(host='127.0.0.1',port='')
conn=redis.Redis(connection_pool=pool)
二、redis中对string的操作
1、set与get,string类型的变量的设置与取值
linux或windows环境中
127.0.0.1:[]> set k1
OK
127.0.0.1:[]> set k2
OK
127.0.0.1:[]> get k1
""
127.0.0.1:[]> get k2
""
在python中
import redis
conn=redis.Redis(host='192.168.99.106',port='')
#正常的set和get
conn.set('k1','v1')
print(conn.get('k1'))
2、ex/px/nx/xx的使用,变量的一些附属参数
ex,设置变量的超时时间,单位为s
ps,设置变量的超时时间,单位为毫秒,ps
nx,设置变量,当变量不存在时,创建并设置变量,如果变量存在,不改变原来变量的值
xx,设置变量,如果变量不存在,不创建,如果变量存在,改变原来的变量值
linux或windows环境中
127.0.0.1:[]> set k1 nx
(nil)
127.0.0.1:[]> get k1
""
127.0.0.1:[]> set k1 xx
OK
127.0.0.1:[]> get k1
""
127.0.0.1:[]>
在python中
#ex px nx xx
conn.set('key2','value',ex=4)
conn.set('key3','value',px=4)
conn.set('newname','value',xx=True)
conn.set('keyxx','value',nx=True)
3、setex/psetex/setnx(ex px nx的另一种使用方式)
linux或windows环境中
127.0.0.1:[]> setex k1 v1
OK
127.0.0.1:[]> psetex k2 v2
OK
在python中
#setex psetex setnx
conn.setex('keyex','xx',3)
conn.psetex('keypx',10000,'xx')#注意顺序
conn.setnx('keyxxx','xxx')
4、mset/mget 批量操作string变量的方法
linux或windows环境中
127.0.0.1:[]> mset k3 k4
OK
127.0.0.1:[]> mget k3 k4
) ""
) ""
在python中
#批量获取或修改mset mget
#mset两种形式 key=value 或 字典
#mget两种形式 key,key 或列表
conn.mset(key1='',key2=2)
conn.mset({'key3':'','key4':''})
print(conn.mget('key1','key2'))#[b'1', b'2']
print(conn.mget(['key3','key4']))#[b'3', b'4']
5、getset 先获取原值再更改值
linux或windows环境中
127.0.0.1:[]> keys *
) "k4"
) "k3"
127.0.0.1:[]> get k4
""
127.0.0.1:[]> getset k4
""
127.0.0.1:[]> get k4
""
在python中
print(conn.getset('key1',''))
6、Getrange、setrange 切片与覆盖
linux或windows环境中
127.0.0.1:[]> set kk
OK
127.0.0.1:[]> get kk
""
127.0.0.1:[]> getrange kk
""
127.0.0.1:[]> setrange kk
(integer)
127.0.0.1:[]> get kk
""
在python中
x='西班牙'.encode('utf-8')
conn.set('country',x)
print(conn.getrange('country',0,2).decode())#西
print(conn.getrange('country',0,8).decode())#西班
y='葡萄'.encode('utf-8')
conn.setrange('country',0,y)
print(conn.getrange('country',0,8).decode())#按字节来计算 汉字三个字节
7、Getbit、setbit、bitcount的组合使用
比较有趣的功能
0 1 1 0 0 0 0 1 -> a
0 1 1 0 0 0 1 0 -> b
0 1 1 0 0 0 1 1 -> c
0 1 1 0 0 1 0 0 -> d
linux或windows环境中
127.0.0.1:6379[1]> set xxx abcd
OK
127.0.0.1:6379[1]> setbit xxx 6 1
(integer) 0
127.0.0.1:6379[1]> get xxx
"cbcd"
127.0.0.1:6379[1]>
在python中,通过getbit,setbit,bitcount来统计在线人数,在线状态。有效节省空间
for i in range(23):
print(i,'---》',conn.getbit('key1',i))
#知道保存在线人数的方法
print(conn.get('key1'))
print(conn.bitcount('key1'))#字符1和数字1在ascii码的不同表示
8、Incr,decr 自增、自减的使用
linux或windows环境中
127.0.0.1:6379[1]> incr k
(integer) 1
127.0.0.1:6379[1]> incr k
(integer) 2
127.0.0.1:6379[1]> incr k
(integer) 3
127.0.0.1:6379[1]> get k
""
127.0.0.1:6379[1]> decr k
(integer) 2
127.0.0.1:6379[1]> get k
""
127.0.0.1:6379[1]>
在python中
>>> import redis
>>> x=redis.Redis('127.0.0.1',port='')
>>> x.incr('i1')
1
>>> x.incr('i1')
2
>>> x.incr('i1')
3
>>>
9、Append string拼接的使用
linux或windows环境中
127.0.0.1:[]> set app1
OK
127.0.0.1:[]> append app1
(integer)
127.0.0.1:[]> get app1
""
127.0.0.1:[]>
在python中
conn.set('appendtest','abc')
conn.append('appendtest','def')
print(conn.get('appendtest'))#b'abcdef'
10、strlen 获取string长度,要注意中文字符因为编码的不同长度不同
linux或windows环境中
127.0.0.1:[]> strlen k
(integer)
在python中
#strlen字符长度 一个汉字长3
print(conn.strlen('key1'))
print(conn.strlen('country'))
print(conn.get('country').decode())
三、redis中对hash的操作
1、redis中hash的含义
redis中的hash如同字典一样,一个key其中又包含多个key,如我们可以把一个变量表示为一个人p1,其类型为hash,那么p1中可以继续包含name,age,weight等信息。
2、Hset、hget、hgetall、hkeys、hvals 变量的赋值及取值
linux或windows环境中
127.0.0.1:[]> hset p1 name alex
(integer)
127.0.0.1:[]> hset p1 age
(integer)
127.0.0.1:[]> hset p1 weight
(integer)
127.0.0.1:[]> hget p1 name
"alex"
127.0.0.1:[]> hget p1 age
""
127.0.0.1:[]> hgetall p1
) "name"
) "alex"
) "age"
) ""
) "weight"
) ""
127.0.0.1:[]> hkeys p1
) "name"
) "age"
) "weight"
127.0.0.1:[]> hvals p1
) "alex"
) ""
) ""
127.0.0.1:[]>
在python中
conn_obj.hset('S1','name','xiaoming')
conn_obj.hset('S1','age','')
conn_obj.hset('S1','sex','male')
print(conn_obj.hgetall('S1'))#{b'name': b'xiaoming', b'age': b'22', b'sex': b'male'}
print(conn_obj.hget('S1','name'))#b'xiaoming'
print(conn_obj.keys())#[b'S1']
print(conn_obj.hkeys('S1'))#[b'name', b'age', b'sex']
print(conn_obj.hvals('S1'))#[b'xiaoming', b'22', b'male']
3、hmget、hmset 批量操作变量
linux或windows环境中
127.0.0.1:[]> hmset p2 name tom age weight
OK
127.0.0.1:[]> hmget p2 name age weight
) "tom"
) ""
) ""
127.0.0.1:[]>
在python中
conn_obj.hmset('S1',{'x1':'xxx1','x2':'xxx2'})
print(conn_obj.hmget("S1",'x1','x2'))
4、hlen、hexists、hdel hash变量的长度判断,元素存在判断及元素删除
linux或windows环境中
127.0.0.1:6379[1]> hgetall p2
1) "name"
2) "tom"
3) "age"
4) ""
5) "weight"
6) ""
127.0.0.1:6379[1]> hlen p2
(integer) 3
127.0.0.1:6379[1]> hexists p2 sex
(integer) 0
127.0.0.1:6379[1]> hexists p2 name
(integer) 1
127.0.0.1:6379[1]> hdel p2 name
(integer) 1
127.0.0.1:6379[1]> hexists p2 name
(integer) 0
127.0.0.1:6379[1]>
在python中
print(conn_obj.hlen('S1'),conn_obj.hkeys('S1'))
print(conn_obj.hexists('S1','x1'),conn_obj.hexists('S1','x3'))
print(conn_obj.hexists('S1','x1'))
5、Hash的自增自减 hincrby
127.0.0.1:6379[1]> hincrby p2 age 1
(integer) 21
127.0.0.1:6379[1]> hincrby p2 age 3
(integer) 24
6、hscan的匹配过滤
一个hash中可能会存在非常多的元素,一些时候我们需要将这些元素过滤出来
linux或windows环境中(注意此处0可以忽略)
127.0.0.1:6379[1]> hscan p2 0 match *
1) ""
2) 1) "age"
2) ""
3) "weight"
4) ""
127.0.0.1:6379[1]> hscan p2 0 match *ge
1) ""
2) 1) "age"
2) "" 127.0.0.1:6379[1]> hscan p1 0 match *e
1) ""
2) 1) "name"
2) "alex"
3) "age"
4) ""
127.0.0.1:6379[1]>
在python中
print(conn_obj.hscan('S1',0,'x*'))
四、redis中对list的操作
即,将list类型的变量保存到redis中
1、 Lpush、lrange、rpush、rpushx、lpushx 放入与取出(注意区分方向)
其中rpushx、lpushx只有在list变量存在的时候才会放入(不具有创建功能)
linux或windows环境中
127.0.0.1:6379[1]> lpush list1 k1 k2 k3
(integer) 3
127.0.0.1:6379[1]> lrange list1 0 -1
1) "k3"
2) "k2"
3) "k1"
127.0.0.1:6379[1]> rpush list1 k4
(integer) 4
127.0.0.1:6379[1]> lrange list1 0 -1
1) "k3"
2) "k2"
3) "k1"
4) "k4"
127.0.0.1:6379[1]>
在python中
import redis
x=redis.ConnectionPool(host='192.168.99.106',port='')
xx=redis.Redis(connection_pool=x)
#lpush rpush lrange
xx.lpush('list1',1,2,3)
xx.rpush('list2',1,2,3)
print(xx.lrange('list1',0,-1))#[b'3', b'2', b'1']
print(xx.lrange('list2',0,-1))#[b'1', b'2', b'3']
#lpush 新来元素往左放 rpush 新来元素往右放
#lrange 切片查看
#lpushx
xx.lpushx('list1',4)
#列表存在才能存放 同理 rpushx
print(xx.lrange('list1',0,-1))#[b'4', b'3', b'2', b'1',]
2、 Llen 长度查看
linux或windows环境中
127.0.0.1:6379[1]> llen list1
(integer) 4
在python中
print(xx.llen('list2'),xx.lrange('list2',0,-1))
3、 Linsert 元素插入 (重复元素的处理情况:从左匹配,处理左边第一次出现的元素)
linux或windows环境中
127.0.0.1:6379[1]> lrange list1 0 -1
1) "k1"
2) "k1"
3) "k1"
4) "k3"
5) "k2"
6) "k1"
7) "k4"
127.0.0.1:6379[1]> linsert list1 before k1 0
(integer) 8
127.0.0.1:6379[1]> lrange list1 0 -1
1) ""
2) "k1"
3) "k1"
4) "k1"
5) "k3"
6) "k2"
7) "k1"
8) "k4"
127.0.0.1:6379[1]>
在python中
xx.linsert('list1','before','','a')
4、 Lset 指定位置修改
linux或windows环境中
127.0.0.1:6379[1]> lrange list1 0 -1
1) ""
2) "k1"
3) "k1"
4) "k1"
5) "k3"
6) "k2"
7) "k1"
8) "k4"
127.0.0.1:6379[1]> lset list1 3 3333
OK
127.0.0.1:6379[1]> lrange list1 0 -1
1) ""
2) "k1"
3) "k1"
4) ""
5) "k3"
6) "k2"
7) "k1"
8) "k4"
127.0.0.1:6379[1]>
在python中
xx.lset('list1',0,'change')
5、 lrem 指定值删除
linux或windows环境中
127.0.0.1:6379[1]> lrange list1 0 -1
1) ""
2) "k1"
3) "k1"
4) ""
5) "k3"
6) "k2"
7) "k1"
8) "k4"
127.0.0.1:6379[1]> lrem list1 20 k1
(integer) 3
127.0.0.1:6379[1]> lrange list1 0 -1
1) ""
2) ""
3) "k3"
4) "k2"
5) "k4"
127.0.0.1:6379[1]>
在python中(注意windows中从count和python中的count的位置不同)
print(xx.lrange('list1',0,-1))#[b'change', b'3', b'2', b'a', b'1', b'4', b'3', b'2', b'a', b'1', b'4', b'3', b'2', b'1',
xx.lrem('list1','',20)
xx.lrem('list1','',20)
xx.lrem('list1','',20)#可以超出次数不会报错
xx.lrem('list1','change',20)
print(xx.lrange('list1',0,-1))#[b'a']
6、 Lpop rpop 获取并弹出左弹出与右弹出
linux或windows环境中
127.0.0.1:6379[1]> lrange list1 0 -1
1) ""
2) ""
3) "k3"
4) "k2"
5) "k4"
127.0.0.1:6379[1]> lpop list1
""
127.0.0.1:6379[1]> rpop list1
"k4"
127.0.0.1:6379[1]> lrange list1 0 -1
1) ""
2) "k3"
3) "k2"
127.0.0.1:6379[1]>
在python中
print(xx.lpop('list1'))
7、 Lindex 指定下标获取值
127.0.0.1:6379[1]> lrange list1 0 -1
1) ""
2) "k3"
3) "k2"
127.0.0.1:6379[1]> lindex list1 -1
"k2"
127.0.0.1:6379[1]> lindex list1 2
"k2"
127.0.0.1:6379[1]>
8、 ltrim 截取, 其余元素删除 trim: vt. 装饰; 修剪; 整理;
linux或windows环境中
127.0.0.1:6379[1]> lrange list1 0 -1
1) "k7"
2) "k6"
3) "k5"
4) "k4"
5) "k3"
6) "k2"
7) "k1"
127.0.0.1:6379[1]> ltrim list1 2 5
OK
127.0.0.1:6379[1]> lrange list1 0 -1
1) "k5"
2) "k4"
3) "k3"
4) "k2"
127.0.0.1:6379[1]>
在python中
xx.ltrim('list2',2,5)#只保留2-5
9、 rpoplpush 循环,或转移
我们可以将pop的元素重新放回这个list中,或者可以将这个pop的元素放到一个新的list中
即实现两个效果,一个是元素的转移,一个是元素的循环
linux或windows环境中
127.0.0.1:6379[1]> lrange list1 0 -1
1) "k5"
2) "k4"
3) "k3"
4) "k2"
127.0.0.1:6379[1]> rpoplpush list1 list1
"k2"
127.0.0.1:6379[1]> rpoplpush list1 list1
"k3"
127.0.0.1:6379[1]> rpoplpush list1 list1
"k4"
127.0.0.1:6379[1]> rpoplpush list1 list1
"k5"
127.0.0.1:6379[1]> rpoplpush list1 list1
"k2"
127.0.0.1:6379[1]>
在python中
xx.rpoplpush('list2','list1')
10、 Redis Blpop 命令移出并获取列表的第一个元素
如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。 阻塞的弹出
作为了解,此处不做演示
五、redis中对set的操作
集合的特点:无序,唯一
1、sadd、smembers、scard 插入 获取与计数(可以注意插入重复数据的情况)
linux或windows环境中
127.0.0.1:6379[1]> sadd tmpset k1 k2 k3 k1 k4 k1 k1 k1
(integer) 4
127.0.0.1:6379[1]> smembers tmpset
1) "k1"
2) "k2"
3) "k3"
4) "k4"
127.0.0.1:6379[1]> scard tmpset
(integer) 4
127.0.0.1:6379[1]>
python中
import redis
x=redis.Redis(host='192.168.99.106',port='')
# sadd smembers
x.sadd('set1','set1','xxx',1,1,2,2,'xxx',3,4,)
print(x.smembers('set1'))#去重复,无序 {b'2', b'3', b'4', b'set1', b'xxx', b'1'}
print(x.scard('set1'))#
2、差集、交集、并集的运算 sdiff、sinter、sunion、sdiffstore、sinterstore、sunionstroe
linux或windows环境中
127.0.0.1:6379> sdiff tmpset tmpset1
1) "v1"
2) "v2"
127.0.0.1:6379> sinter tmpset tmpset1
1) "v4"
2) "v3"
127.0.0.1:6379> sunion tmpset tmpset1
1) "v2"
2) "v6"
3) "v3"
4) "v4"
5) "v1"
6) "v5"
127.0.0.1:6379> sdiffstore diff1 tmpset tmpset1
(integer) 2
127.0.0.1:6379> smembers diff1
1) "v1"
2) "v2"
127.0.0.1:6379> sinterstore inter1 tmpset tmpset1
(integer) 2
127.0.0.1:6379> smembers inter1
1) "v3"
2) "v4"
127.0.0.1:6379> sunionstore union1 tmpset tmpset1
(integer) 6
127.0.0.1:6379> smembers union1
1) "v2"
2) "v6"
3) "v3"
4) "v4"
5) "v1"
6) "v5"
127.0.0.1:6379>
python中
print(x.sdiff('set1','set2'))#{b'set1', b'xxx', b'4'}
x.sdiffstore('set3','set1','set2')
print(x.smembers('set3'))#和上一条结果输出结果一致 {b'set1', b'xxx', b'4'}
print(x.sinter('set1','set2'))#{b'3', b'1', b'2'}
3、Spop随机弹出,srandmember随机取数
127.0.0.1:6379> spop tmpset
"v3"
127.0.0.1:6379> smembers tmpset
1) "v2"
2) "v4"
3) "v1"
127.0.0.1:6379> srandmember tmpset 2
1) "v1"
2) "v2"
127.0.0.1:6379> srandmember tmpset 2
1) "v1"
2) "v2"
127.0.0.1:6379> srandmember tmpset 2
1) "v1"
2) "v4"
127.0.0.1:6379> srandmember tmpset 2
1) "v1"
2) "v4"
127.0.0.1:6379>
4、Srem 删除
127.0.0.1:6379> smembers union1
1) "v2"
2) "v6"
3) "v3"
4) "v4"
5) "v1"
6) "v5"
127.0.0.1:6379> srem union1 v5 v1
(integer) 2
127.0.0.1:6379> smembers union1
1) "v2"
2) "v6"
3) "v3"
4) "v4"
5、sscan搜索
127.0.0.1:6379> smembers union1
1) "v2"
2) "v6"
3) "v3"
4) "v4"
127.0.0.1:6379> sscan union1 0 match *6
1) ""
2) 1) "v6"
127.0.0.1:6379> sscan union1 0 match v*
1) ""
2) 1) "v2"
2) "v6"
3) "v3"
4) "v4"
127.0.0.1:6379>
6. sismember 成员判断
print(x.sismember('set1','xxx'))
六、redis中对有序集合的操作
有序集合和普通集合一样,有集合的特征:唯一性 ,但是有序集合有顺序,它依靠score来排序,同score的元素,在显示上有先后顺序,但是实际他们的顺序是一样的。可以用相应的指令查看排序确定。
1、zadd zrange添加和查询(需要添加权重)with scores (集合的覆盖,分数的修改)
如果zadd一个已有的元素,并赋予了新的score,则此操作的实质是修改元素的score
linux或windows环境中
127.0.0.1:6379> zadd z1 10 xiaoming 20 xiaodong 20 xiaotan 30 xiaowang
(integer) 4
127.0.0.1:6379> zrange z1 0 -1
1) "xiaoming"
2) "xiaodong"
3) "xiaotan"
4) "xiaowang"
127.0.0.1:6379> zrange z1 0 -1 withscores
1) "xiaoming"
2) ""
3) "xiaodong"
4) ""
5) "xiaotan"
6) ""
7) "xiaowang"
8) ""
127.0.0.1:6379>
127.0.0.1:6379> zadd z1 20 xiaoming #重新赋值
(integer) 0
127.0.0.1:6379> zrange z1 0 -1
1) "xiaodong"
2) "xiaoming"
3) "xiaotan"
4) "xiaowang"
127.0.0.1:6379> zrange z1 0 -1 withscores
1) "xiaodong"
2) ""
3) "xiaoming"
4) ""
5) "xiaotan"
6) ""
7) "xiaowang"
8) ""
127.0.0.1:6379>
python中
import redis
import time
x=redis.ConnectionPool(host='192.168.106.128',port='')
xx=redis.Redis(connection_pool=x) xx.zadd('z1','B',20,'A',10,'C',30)
print(xx.zrange('z1',0,-1))#[b'A', b'B', b'C']
xx.zadd('z1','D',15)
print(xx.zrange('z1',0,-1))#[b'A', b'D', b'B', b'C']
xx.zadd('z1','D',40)
print(xx.zrange('z1',0,-1))#[b'A', b'B', b'C', b'D'] 有序集合 不重复 如果重复 则添加新的删旧的位置 print(xx.zrange('z1',0,-1,withscores=True))
#最直接的应用就是学生的成绩和排名
# [(b'A', 10.0), (b'B', 20.0), (b'C', 30.0), (b'D', 40.0)]
2、zcard zcount计数 zcard 计算有序集合的元素总数,zcount可以指定分数区间进行计数(用于统计学生分数区间,相当方便)
linux或windows环境中
127.0.0.1:6379> zcount z1 25 30
(integer) 1
127.0.0.1:6379> zcount z1 10 25
(integer) 3
127.0.0.1:6379> zcard z1
(integer) 4
127.0.0.1:6379>
python中
print(xx.zcard('z1'))#输出集合中 元素的数量 4
print(xx.zcount('z1',20,30))#获取 区间数 [a,b]的关系 可以等于,应用于判断分数区间
3、zincrby 自增
linux或windows环境中
127.0.0.1:6379> zincrby z1 1 xiaoming
""
python中
#print(xx.zincrby('z1',1,50)) 不好使先不深入
4、zrank 算排名 同分同排名
linux或windows环境中
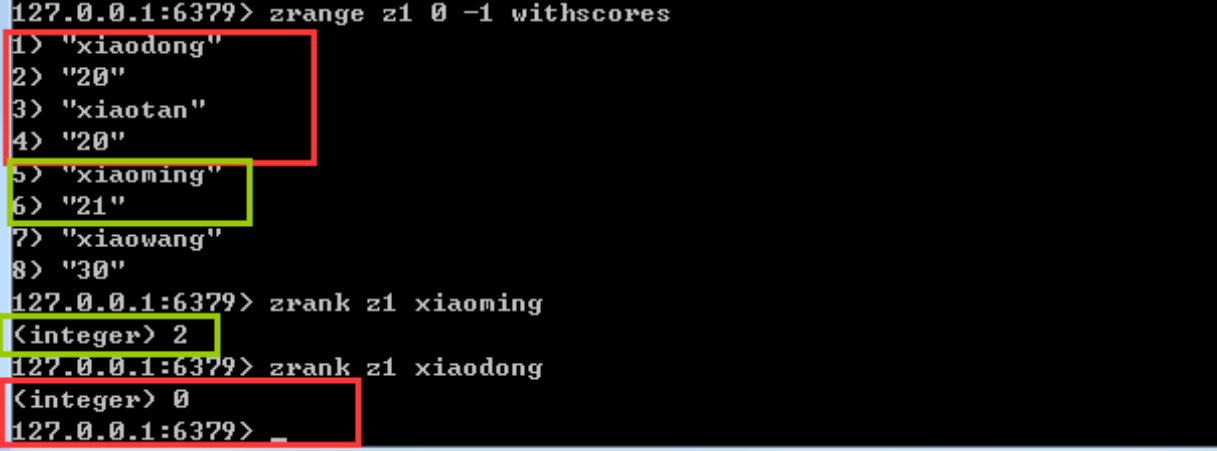
python中
print(xx.zrank('z1','D'))
5、zrem/zremrangebyrank z1 min max /zremrangebyscore z1 min max 几种删除
zrem 指定元素删除
zremramrangebyrank 按排名删除
zremrangebyscore 按分数区间删除
linux或windows环境中
zrem key member
zremrangebyrank z1 min max
zremrangebyscore z1 min max
python中
#zrem 删除
#按照排行删除 zremrangebyrank
xx.zremrangebyrank('z1',0,1)
print(xx.zrange('z1',0,-1))
xx.zremrangebyscore('z1',30,31)
6、zscore 获取某元素的score值
linux或windows环境中
127.0.0.1:6379> zscore z1 xiaotan
""
python中
print(xx.zscore('z1','D'))
7、zinterstore 几个有序集合的组合
可以用来计算学生的总分
linux或windows环境中
127.0.0.1:6379> zadd math 110 xiaoming 120 xiaotan 150 xiaodong
(integer) 3
127.0.0.1:6379> zadd english 90 xiaoming 130 xiaotan 134 xiaodong
(integer) 3
127.0.0.1:6379> zadd chinese 100 xiaoming 95 xiaotan 120 xiaodong
(integer) 3
127.0.0.1:6379> zinterstore allscores 3 match english chinese
(integer) 0
127.0.0.1:6379> zinterstore allscores 3 math english chinese
(integer) 3
127.0.0.1:6379> zrange allscores 0 -1
1) "xiaoming"
2) "xiaotan"
3) "xiaodong"
127.0.0.1:6379> zrange allscores 0 -1 withscores
1) "xiaoming"
2) ""
3) "xiaotan"
4) ""
5) "xiaodong"
6) ""
127.0.0.1:6379>
python中
xx.zadd('english','tom',120,'alex',110,'jack',110)#[(b'alex', 110.0), (b'jack', 110.0), (b'tom', 120.0)]
xx.zadd('math','tom',150,'alex',110,'jack',90)
xx.zadd('chinese','tom',100,'alex',90,'jack',100)#[(b'alex', 90.0), (b'jack', 100.0), (b'tom', 100.0)]
print(xx.zrange('english',0,-1,withscores=True))
print(xx.zrange('math',0,-1,withscores=True))
print(xx.zrange('chinese',0,-1,withscores=True))
xx.zinterstore('x1',('math','english','chinese'),aggregate="SUM")
#xx.zinterstore('x2','x1','chinese',aggregate="SUM")
print(xx.zrange('x1',0,-1,withscores=True))#[(b'jack', 300.0), (b'alex', 310.0), (b'tom', 370.0)]
8、zscan搜索
127.0.0.1:6379> zscan z1 0 match *ming
1) ""
2) 1) "xiaoming"
2) ""
127.0.0.1:6379>
七、redis中的一些基本操作
1、del 删除某个key
del k1
2、Exists 存在为1 不存在为0
127.0.0.1:6379> exists k2
(integer) 1
127.0.0.1:6379> exists kkk123
(integer) 0
3、Keys 列出所有的key
127.0.0.1:6379> keys *
1) "diff1"
2) "name"
3) "k1"
4) "tmplist"
5) "union1"
4、Type 列出key的类型
127.0.0.1:6379[1]> type list1
list
127.0.0.1:6379[1]> type p1
hash
127.0.0.1:6379[1]> type k3
string
127.0.0.1:6379[1]> type app1
string
127.0.0.1:6379[1]> type tmpset
set
127.0.0.1:6379[1]> zadd zzz 100 x
(integer) 1
127.0.0.1:6379[1]> type zzz
zset
127.0.0.1:6379[1]>
5、Expire 给key设置超时时间 超过时间后 key的类型为none 值被清空,但是key名还存在
127.0.0.1:6379> expire z1 3
(integer) 1
127.0.0.1:6379> type z1
none
6、Rename 重命名
rename k1 kk1
7、 Move 与select key与db的操作
move key db 将某个key转移到其他的db中
redis中有16个db 分别为0-15 可以通过move将某个值移动到某个db中
通过select 切换db
8、 scan 搜索key *k*为中间有k但前后都要有东西
127.0.0.1:6379> keys *
1) "diff1"
2) "kk1"
3) "name"
4) "tmplist"
5) "union1"
6) "english"
7) "tmplist1"
8) "tmpset"
9) "info"
10) "agenew"
11) "tmpset1"
12) "test"
13) "age"
14) "math"
15) "chinese"
16) ""
17) "allscores"
18) "inter1"
127.0.0.1:6379> scan 0 match *k*
1) ""
2) 1) "kk1"
127.0.0.1:6379>
八、redis中的管道操作
作为了解,我们可以将同时将多步redis操作同时交给pipeline,之后再由pipeline统一执行,p.execute()时才执行指令
xxx=redis.ConnectionPool(host='192.168.106.128',port='',db=5)
xxxx=redis.Redis(connection_pool=xxx,db=5)
p=xxxx.pipeline()
p.set('x1','')
time.sleep(20)
p.set('x2','')
p.execute()
九、redis中的发布订阅操作

1、publish、pubsub、subscribe、parse_response的使用
import redis
#建立连接
pool=redis.ConnectionPool(host='127.0.0.1',port='')
conn=redis.Redis(connection_pool=pool)
#publish
conn.publish('fm999','你好'.encode('utf-8')) import redis
pool=redis.ConnectionPool(host='127.0.0.1',port='')
conn=redis.Redis(connection_pool=pool)
#打开收音机
tmp_fm=conn.pubsub()
#调到频道
tmp_fm.subscribe('fm999')
#开始收听
tmp_fm.parse_response()
#真正接收-》收到就打印 没收到就卡住
data=tmp_fm.parse_response()
#打印消息
print(data[0].decode(),data[1].decode(),data[2].decode())
2、一个综合的例子
2.1 lib
import redis class MyRadio(object):
def __init__(self):
self.pool=redis.ConnectionPool(host='192.168.106.128',port='')
self.conn=redis.Redis(connection_pool=self.pool)
self.conn_pub='fm996'
self.conn_sub='fm996' def publish(self,mes):
self.conn.publish(self.conn_pub,mes.encode('utf-8'))
return True
def subscribe(self):
tmp_sub=self.conn.pubsub()#打开收音机
tmp_sub.subscribe(self.conn_sub)#调频道
tmp_sub.parse_response() #准备接收
return tmp_sub
2.2 发布
from mylib import MyRadio x=MyRadio()
while True:
tmp_str=input('>>:').strip()
if not tmp_str:continue
x.publish(tmp_str)
2.3 订阅
from mylib import MyRadio x=MyRadio()
real_redio=x.subscribe()#实体化收音机
while True:
msg=real_redio.parse_response()#等待消息
print('原始数据:',msg)
print('加工后:',msg[0].decode(),msg[1].decode(),msg[2].decode())
python笔记-12 redis缓存的更多相关文章
- python进阶12 Redis
python进阶12 Redis 一.概念 #redis是一种nosql(not only sql)数据库,他的数据是保存在内存中,同时redis可以定时把内存数据同步到磁盘,即可以将数据持久化,还提 ...
- SpringBoot学习笔记:Redis缓存
SpringBoot学习笔记:Redis缓存 关于Redis Redis是一个使用ANSI C语言编写的免费开源.支持网络.可基于内存亦可以持久化的日志型.键值数据库.其支持多种存储类型,包括Stri ...
- 基于Python项目的Redis缓存消耗内存数据简单分析(附详细操作步骤)
目录 1 准备工作 2 具体实施 1 准备工作 什么是Redis? Redis:一个高性能的key-value数据库.支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使 ...
- python笔记12
day12 今日内容 函数中高级(闭包/高阶函数) 内置函数 内置模块(.py文件) 内容回顾 函数基础概念 函数基本结构 def func(arg): return arg; v1 = func(1 ...
- Python笔记 #12# Dictionary & Pandas: Object Creation
Document of Dictionaries 10 Minutes to pandas tutorialspoint import pandas as pd data = [['Alex',10] ...
- 第三百零一节,python操作redis缓存-管道、发布订阅
python操作redis缓存-管道.发布订阅 一.管道 redis-py默认在执行每次请求都会创建(连接池申请连接)和断开(归还连接池)一次连接操作,如果想要在一次请求中指定多个命令,则可以使用pi ...
- 第二百九十九节,python操作redis缓存-SortSet有序集合类型,可以理解为有序列表
python操作redis缓存-SortSet有序集合类型,可以理解为有序列表 有序集合,在集合的基础上,为每元素排序:元素的排序需要根据另外一个值来进行比较,所以,对于有序集合,每一个元素有两个值, ...
- PHP 开发 APP 接口 学习笔记与总结 - Redis 缓存
Redis 可以定期将数据备份到磁盘中(持久化),同时不仅仅支持简单的key/value 类型的数据,同时还提供list,set,hash等数据结构的存储:Memcache 只是简单的key/valu ...
- Python 基于python+mysql浅谈redis缓存设计与数据库关联数据处理
基于python+mysql浅谈redis缓存设计与数据库关联数据处理 by:授客 QQ:1033553122 测试环境 redis-3.0.7 CentOS 6.5-x86_64 python 3 ...
随机推荐
- less文件的运行
例:在任意处创建一个.less文件,比如在桌面2017.06.28文件中创建了一个main.less文件,然后通过命令行编译main.less,步骤: win+R,cmd打开命令面板,切换到main. ...
- 基于哈夫曼编码的压缩解压程序(C 语言)
这个程序是研一上学期的课程大作业.当时,跨专业的我只有一点 C 语言和数据结构基础,为此,我查阅了不少资料,再加上自己的思考和分析,实现后不断调试.测试和完善,耗时一周左右,在 2012/11/19 ...
- EasyUI datagrid 多条件查询
<script type="text/javascript"> $(function () { $("#dg").datagrid({ url: ' ...
- C语言实现顺序表
C语言实现顺序表代码 文件SeqList.cpp #pragma warning(disable: 4715) #include"SeqList.h" void ShowSeqLi ...
- Ansible 手册系列 一(介绍)
一 介绍 Ansible 是一个配置管理和应用部署工具,功能类似于目前业界的配置管理工具 Chef,Puppet,Saltstack.Ansible 是通过 Python 语言开发.Ansible 平 ...
- iptables详解(8):iptables扩展模块之state扩展
当我们通过http的url访问某个网站的网页时,客户端向服务端的80端口发起请求,服务端再通过80端口响应我们的请求,于是,作为客户端,我们似乎应该理所应当的放行80端口,以便服务端回应我们的报文可以 ...
- 利用expect和sshpass完美非交互性执行远端命令
yum install expect -y expect 参考:http://blog.csdn.net/snow_114/article/details/53245466 yum install s ...
- angular2 post以“application/x-www-form-urlencoded”形式传参的解决办法
angular2 post以“application/x-www-form-urlencoded”形式传参的解决办法 http://blog.csdn.net/tianjun2012/article/ ...
- RMAN中format的参数
(转自:http://blog.chinaunix.net/uid-23079711-id-2554290.html) format 的替换变量,注意大小写! 1. %d --数据库的db_n ...
- 添加git 忽略文件
在使用Git的过程中,我们喜欢有的文件比如日志,临时文件,编译的中间文件等不要提交到代码仓库,这时就要设置相应的忽略规则,来忽略这些文件的提交. Git 忽略文件提交的方法 有三种方法可以实现忽略Gi ...