Hibernate学习9—检索策略
本章,采用Class和Student —— 1 对 多的关系;
Student.java:
package com.cy.model;
public class Student {
private int id;
private String name;
private Class c;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Class getC() {
return c;
}
public void setC(Class c) {
this.c = c;
}
}
Class.java:
package com.cy.model; import java.util.HashSet;
import java.util.Set; public class Class {
private int id;
private String name;
private Set<Student> students = new HashSet<Student>(); public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Set<Student> getStudents() {
return students;
}
public void setStudents(Set<Student> students) {
this.students = students;
} }
Student.hbm.xml:
<hibernate-mapping package="com.cy.model">
<class name="Student" table="t_student">
<id name="id" column="stuId">
<generator class="native"></generator>
</id>
<property name="name" column="stuName"></property>
<many-to-one name="c" column="classId" class="com.cy.model.Class" cascade="save-update" lazy="proxy"></many-to-one>
</class>
</hibernate-mapping>
Class.hbm.xml:
<hibernate-mapping package="com.cy.model">
<class name="Class" table="t_class">
<id name="id" column="classId">
<generator class="native"></generator>
</id>
<property name="name" column="className"></property>
<set name="students" cascade="save-update" inverse="true" lazy="false" batch-size="3" fetch="join">
<key column="classId"></key>
<one-to-many class="com.cy.model.Student" />
</set>
</class>
</hibernate-mapping>
第一节:检索策略属性Lazy

Lazy:true:默认延迟检索:用到才加载
@Test
public void testLazy1(){
//因为在class.hbm中set端,一对多,配置的是lazy=true,加载class的时候,默认是不加载学生的。
Class c = (Class) session.get(Class.class, 1); //等到什么时候会查询学生数据?——等到他用的时候
//等到用到的时候才去检索,这就是延迟检索
Set<Student> students = c.getStudents(); System.out.println(students.size()); // Iterator it = students.iterator(); }


@Test
public void testLazy2(){
//many to one端,默认lazy - proxy。取出的student中的Class是一个代理类。没有实际数据
Student student = (Student) session.get(Student.class, 1); //等到用到class的名字的时候,代理类才去发出sql查询数据。
student.getC().getName();
}
第二节:检索策略属性batch-size
1,批量延迟检索;
对应的class.hbm配置:lazy="true" batch-size="3"
/**
* 批量延迟检索,lazy=true
*/
@Test
public void testBatch1(){
List<Class> classList = session.createQuery("from Class").list();
Iterator<Class> it = classList.iterator();
Class c1 = it.next();
Class c2 = it.next();
Class c3 = it.next();
c1.getStudents().iterator();
c2.getStudents().iterator();
c3.getStudents().iterator(); //先取出所有class,因为set students端配置了lazy=false
//等到c1、c2、c3用到student的时候,才去查找。每个发出一条sql语句。
//假如classList很多很多的话,遍历每个class,然后取每个class下面的students,每个都发出一条sql,这样效率就很低了。
//所以,引入了batch-size,批量检索。batch-size的值为批量的值 //在class.hbm. set studens端,配置batch-size=3,发出的sql就是这样了:
/**
* SELECT
t_student.classId ,
t_student.stuId ,
t_student.stuName
FROM t_student
WHERE t_student.classId IN (1, 2, 3)
*/
}
而未设置批量检索batch-size,发出的sql是下面这样,一条一条的查:

设置了批量检索,batch-size=3后,查询student信息时,一次查3条;
2,批量立即检索;
@Test
public void testBatch2(){
List<Class> classList = session.createQuery("from Class").list();
//这里class.hbm.xml set students中配置lazy=false,batch-size=3,就是批量立即检索了.
//发出的批量sql和上面一样。 }
第三节:检索策略属性Fetch
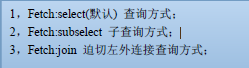
@Test
public void testFetch1(){
List<Class> classList = session.createQuery("from Class").list();
Iterator<Class> it = classList.iterator();
Class c1 = it.next();
Class c2 = it.next();
Class c3 = it.next();
c1.getStudents().iterator();
c2.getStudents().iterator();
c3.getStudents().iterator();
/**
* class.hbm set students 配置fetch="select",是默认的,发出的sql:
* SELECT
t_student.classId ,
t_student.stuId ,
t_student.stuName
FROM t_student
WHERE t_student.classId IN (1, 2, 3) 现在改为fetch=subselect:sql变成了:
SELECT
t_student.classId ,
t_student.stuId ,
t_student.stuName
FROM t_student
WHERE t_student.classId IN
(SELECT classId FROM t_class )
*
*/
}
fetch:join:
@Test
public void testFetch2(){
Class c = (Class) session.get(Class.class, 1);
/**
* 这里class.hbm配置:<set name="students" lazy="false" fetch="join">
* 查询班级的时候,把属于这个班级的学生也一起查出来,这里fetch=join,sql中left outer join:
* 发出的sql:
* SELECT
t_class.classId,
t_class.className,
t_student.stuId,
t_student.stuName,
t_student.classId
FROM t_class
LEFT OUTER JOIN t_student ON t_class.classId = t_student.classId
WHERE t_class.classId = 1 * 可以看到只发出一条sql语句了,t_class表和t_student表关联,将class信息和student信息一起取了出来;
*
* 而如果fetch为select,是先取班级信息;再取student信息
*/
}
Hibernate学习9—检索策略的更多相关文章
- Hibernate学习之检索策略
一.类级别的检索策略 类级别可选的检索策略包括立即检索和延迟检索, 默认为延迟检索 –立即检索: 立即加载检索方法指定的对象 –延迟检索: 延迟加载检索方法指定的对象,在使用具体的属性时,再进行加载 ...
- Hibernate学习总汇
Hibernate的基础知识 什么是框架? 什么是Hibernate框架? |--1.应用在javaee三层结构中的dao层 |--2.在dao层里面做对数据库进行crud操作,使用hibernate ...
- [原创]java WEB学习笔记88:Hibernate学习之路-- -Hibernate检索策略(立即检索,延迟检索,迫切左外连接检索)
本博客的目的:①总结自己的学习过程,相当于学习笔记 ②将自己的经验分享给大家,相互学习,互相交流,不可商用 内容难免出现问题,欢迎指正,交流,探讨,可以留言,也可以通过以下方式联系. 本人互联网技术爱 ...
- [原创]java WEB学习笔记91:Hibernate学习之路-- -HQL 迫切左外连接,左外连接,迫切内连接,内连接,关联级别运行时的检索策略 比较。理论,在于理解
本博客的目的:①总结自己的学习过程,相当于学习笔记 ②将自己的经验分享给大家,相互学习,互相交流,不可商用 内容难免出现问题,欢迎指正,交流,探讨,可以留言,也可以通过以下方式联系. 本人互联网技术爱 ...
- Hibernate学习(八)———— Hibernate检索策略(类级别,关联级别,批量检索)详解
序言 很多看起来很难的东西其实并不难,关键是看自己是否花费了时间和精力去看,如果一个东西你能看得懂,同样的,别人也能看得懂,体现不出和别人的差距,所以当你觉得自己看了很多书或者学了很多东西的时候,你要 ...
- Hibernate —— 检索策略
一.Hibernate 的检索策略本质上是为了优化 Hibernate 性能. 二.Hibernate 检索策略包括类级别的检索策略.和关联级别的检索策略(<set> 元素) 三.类级别的 ...
- hibernate学习(6)——加载策略(优化)
1. 检索方式 1 立即检索:立即查询,在执行查询语句时,立即查询所有的数据. 2 延迟检索:延迟查询,在执行查询语句之后,在需要时在查询.(懒加载) 2. 检查策略 1 类级别检索:当前的类的 ...
- hibernate(八) Hibernate检索策略(类级别,关联级别,批量检索)详解
序言 很多看起来很难的东西其实并不难,关键是看自己是否花费了时间和精力去看,如果一个东西你能看得懂,同样的,别人也能看得懂,体现不出和别人的差距,所以当你觉得自己看了很多书或者学了很多东西的时候,你要 ...
- 攻城狮在路上(壹) Hibernate(十二)--- Hibernate的检索策略
本文依旧以Customer类和Order类进行说明.一.引言: Hibernate检索Customer对象时立即检索与之关联的Order对象,这种检索策略为立即检索策略.立即检索策略存在两大不足: A ...
随机推荐
- eclipse背景设置什么颜色缓解眼睛疲劳之一
Eclipse操作界面默认颜色为白色.对于我们长期使用电脑编程的人来说,白色很刺激我们的眼睛,如果把颜色改成绿色的颜色就会缓解眼睛的疲劳. 设置方法如下: 1.打开window->Prefere ...
- Data truncated for column
数据类型不合法造成的.检查插入的数据.
- 1. Java EE简介 - JavaEE基础系列
什么是Java EE? 真的是你理解的那样吗? Java EE, 原名J2EE, 其核心由一系列抽象的标准规范所组成, 是针对目前软件开发中所普遍面临问题的解决方案. 注意以上定义中的"抽象 ...
- 使用tr1的bind函数模板
最近把公司的VS2008统一升级为SP1了,虽然还是有些跟不上时代,毕竟C++17标准都出了,但是,对于成熟的商业软件开发而言,追求更新的C++标准肯定不是正道.升级SP1的VS2008可以支持TR1 ...
- Android中的sp和wp指针
经常会在android的framework代码中发现sp<xxx>和wp<xxx>这样的指针,平时看的时候都把他当成一个普通的指针封装过掉了,这几天终于忍不住了,想深入了解一下 ...
- 【剑指offer】顺时针打印矩阵,C++实现
原创文章,转载请注明出处! 博客文章索引地址 1.题目 输入一个矩阵,按照从外向里以顺时针的顺序依次打印出每一个数字,例如,如果输入如下矩阵,则依次打印出数字1,2,3,4,8,12,16,15,14 ...
- java小知识点 2015/10/6
java中length,length(),size()区别: 1 java中的length属性是针对数组说的,比如说你声明了一个数组,想知道这个数组的长度 2 java中的length()方法是针对字 ...
- wampserver2.5的php.ini位置在wamp\bin\apache\apache2.4.9\bin
wampserver2.5的php.ini位置在wamp\bin\apache\apache2.4.9\bin php.ini有多个地方,C:\wamp\bin\php\php5.5.12下面有php ...
- windows中的oracle12SE后启动的系统服务的列表
下图是我安装在windows 10下安装好oracle12.10SE之后的启动的系统服务的列表. 通常,我是将其全部修改为手动启动.当需要用oracle服务的时候,只需要启动对应的实例的服务和tnsl ...
- JavaScript 中 OnLoad事件用法总结
还差一天现在手头上的这套网站就写完了,中午蹭了半天还是没睡好,干脆爬起来把今天上午写到的onload事件给整理一下. 一般用到比较多的就是初始化数据或者效果. 1.直接写在<body>标签 ...