Hadoop序列化与Writable接口(一)
Hadoop序列化与Writable接口(一)
序列化
序列化(serialization)是指将结构化的对象转化为字节流,以便在网络上传输或者写入到硬盘进行永久存储;相对的反序列化(deserialization)是指将字节流转回到结构化对象的过程。
在分布式系统中进程将对象序列化为字节流,通过网络传输到另一进程,另一进程接收到字节流,通过反序列化转回到结构化对象,以达到进程间通信。在Hadoop中,Mapper,Combiner,Reducer等阶段之间的通信都需要使用序列化与反序列化技术。举例来说,Mapper产生的中间结果(<key: value1, value2...>)需要写入到本地硬盘,这是序列化过程(将结构化对象转化为字节流,并写入硬盘),而Reducer阶段读取Mapper的中间结果的过程则是一个反序列化过程(读取硬盘上存储的字节流文件,并转回为结构化对象),需要注意的是,能够在网络上传输的只能是字节流,Mapper的中间结果在不同主机间洗牌时,对象将经历序列化和反序列化两个过程。
序列化是Hadoop核心的一部分,在Hadoop中,位于org.apache.hadoop.io包中的Writable接口是Hadoop序列化格式的实现。
Writable接口
Hadoop Writable接口是基于DataInput和DataOutput实现的序列化协议,紧凑(高效使用存储空间),快速(读写数据、序列化与反序列化的开销小)。Hadoop中的键(key)和值(value)必须是实现了Writable接口的对象(键还必须实现WritableComparable,以便进行排序)。
以下是Hadoop(使用的是Hadoop 1.1.2)中Writable接口的声明:
1 |
|
Writable类
Hadoop自身提供了多种具体的Writable类,包含了常见的Java基本类型(boolean、byte、short、int、float、long和double等)和集合类型(BytesWritable、ArrayWritable和MapWritable等)。这些类型都位于org.apache.hadoop.io包中。
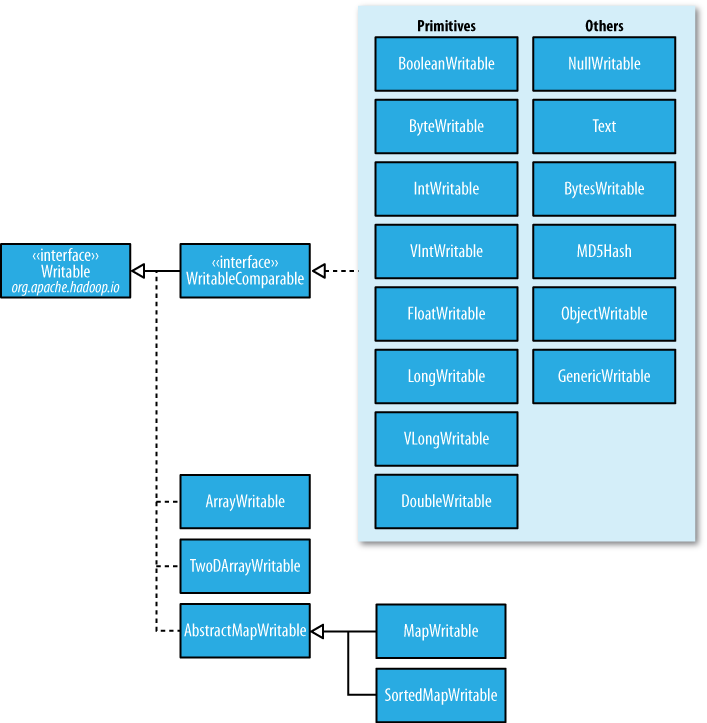
(图片来源:safaribooksonline.com)
定制Writable类
虽然Hadoop内建了多种Writable类提供用户选择,Hadoop对Java基本类型的包装Writable类实现的RawComparable接口,使得这些对象不需要反序列化过程,便可以在字节流层面进行排序,从而大大缩短了比较的时间开销,但是当我们需要更加复杂的对象时,Hadoop的内建Writable类就不能满足我们的需求了(需要注意的是Hadoop提供的Writable集合类型并没有实现RawComparable接口,因此也不满足我们的需要),这时我们就需要定制自己的Writable类,特别将其作为键(key)的时候更应该如此,以求达到更高效的存储和快速的比较。
下面的实例展示了如何定制一个Writable类,一个定制的Writable类首先必须实现Writable或者WritableComparable接口,然后为定制的Writable类编写write(DataOutput out)和readFields(DataInput in)方法,来控制定制的Writable类如何转化为字节流(write方法)和如何从字节流转回为Writable对象。
1 |
|
未完待续,下一篇中将介绍Writable对象序列化为字节流时占用的字节长度以及其字节序列的构成。
参考资料
Tom White, Hadoop: The Definitive Guide, 3rd Edition
---To Be Continued---
Hadoop序列化与Writable接口(一)的更多相关文章
- Hadoop序列化与Writable接口(二)
Hadoop序列化与Writable接口(二) 上一篇文章Hadoop序列化与Writable接口(一)介绍了Hadoop序列化,Hadoop Writable接口以及如何定制自己的Writable类 ...
- Hadoop阅读笔记(六)——洞悉Hadoop序列化机制Writable
酒,是个好东西,前提要适量.今天参加了公司的年会,主题就是吃.喝.吹,除了那些天生话唠外,大部分人需要加点酒来作催化剂,让一个平时沉默寡言的码农也能成为一个喷子!在大家推杯换盏之际,难免一些画面浮现脑 ...
- hadoop中的序列化与Writable接口
本文地址:http://www.cnblogs.com/archimedes/p/hadoop-writable-interface.html,转载请注明源地址. 简介 序列化和反序列化就是结构化对象 ...
- Hadoop中序列化与Writable接口
学习笔记,整理自<Hadoop权威指南 第3版> 一.序列化 序列化:序列化是将 内存 中的结构化数据 转化为 能在网络上传输 或 磁盘中进行永久保存的二进制流的过程:反序列化:序列化的逆 ...
- Hadoop序列化
遗留问题: Hadoop序列化可以复用对象,是在哪里复用的? 介绍Hadoop序列化机制 Hadoop序列化机制详解 Hadoop序列化的核心 Hadoop序列化的比较接口 ObjectWrita ...
- Hadoop基础-序列化与反序列化(实现Writable接口)
Hadoop基础-序列化与反序列化(实现Writable接口) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.序列化简介 1>.什么是序列化 序列化也称串行化,是将结构化 ...
- Hadoop Serialization hadoop序列化详解(最新版) (1)【java和hadoop序列化比较和writable接口】
初学java的人肯定对java序列化记忆犹新.最开始很多人并不会一下子理解序列化的意义所在.这样子是因为很多人还是对java最底层的特性不是特别理解,当你经验丰富,对java理解更加深刻之后,你就会发 ...
- 为什么hadoop中用到的序列化不是java的serilaziable接口去序列化而是使用Writable序列化框架
继上一个模块之后,此次分析的内容是来到了Hadoop IO相关的模块了,IO系统的模块可谓是一个比较大的模块,在Hadoop Common中的io,主要包括2个大的子模块构成,1个是以Writable ...
- eclipse 提交作业到JobTracker Hadoop的数据类型要求必须实现Writable接口
问:在eclipse中的写的代码如何提交作业到JobTracker中的哪?答:(1)在eclipse中调用的job.waitForCompletion(true)实际上执行如下方法 connect() ...
随机推荐
- iptables详解(9):iptables的黑白名单机制
注意:在参照本文进行iptables实验时,请务必在个人的测试机上进行,因为如果iptables规则设置不当,有可能使你无法连接到远程主机中. 前文中一直在强调一个概念:报文在经过iptables的链 ...
- 浅谈js数据类型识别方法
js有6种基本数据类型 Undefined , Null , Boolean , Number , String ,Symbol和一种引用类型Object,下面我们就来一一看穿,哦不,识别他们. t ...
- 十二、dbms_logmnr(分析重做日志和归档日志)
1.概述 作用:通过使用包DBMS_LOGMNR和DBMS_LOGMNR_D,可以分析重做日志和归档日志所记载的事务变化,最终确定误操作(例如DROP TABLE)的时间,跟踪用户事务操作,跟踪并还原 ...
- LeetCode OJ:Rotate List(旋转链表)
Given a list, rotate the list to the right by k places, where k is non-negative. For example:Given 1 ...
- myeclipes快捷键
package com.Test02;//alt+shift+s+s 自动创建toString()//ctrl+ shift+ o 自动导包//* alt+ shift +s+o 有参构造//* a ...
- MoreEffectiveC++Item35(异常)(条款9-15)
条款9 使用析构函数防止内存泄漏 条款10 在构造函数中防止内存泄漏 条款11 禁止异常信息传递到析构函数外 条款12 理解"抛出一个异常''与"传递一个参数"或调用一个 ...
- L163
Chickens slaughtered in the United States, claim officials in Brussels, are not fit to grace Europea ...
- Echart--百度地图(散点图)
参考:http://blog.csdn.net/xieweikun7/article/details/52766676 1.首先,下载嘛 Echarts http://echarts.baidu.co ...
- iOS runloop 自定义输入源
创建自定义输入源需要定义以下内容 1)输入源要处理的信息 2)使感兴趣的客户端知道如何和输入源交互的调度例程 3)处理其他任何客户发送请求的例程 4)使输入源失效的取消例程 上图的处理流程:主线程(M ...
- 类的初始化__init__使用
初始化方法: 作用: 对新创建的对象添加属性 语法: class 类名(继承列表): def __init__(self [, 形参列表]): 语句块 [] 代表中的内容可省略 说明: 1. 实始化方 ...