【网络结构】VGG-Net论文解析
@
0. 论文链接
1. 概述
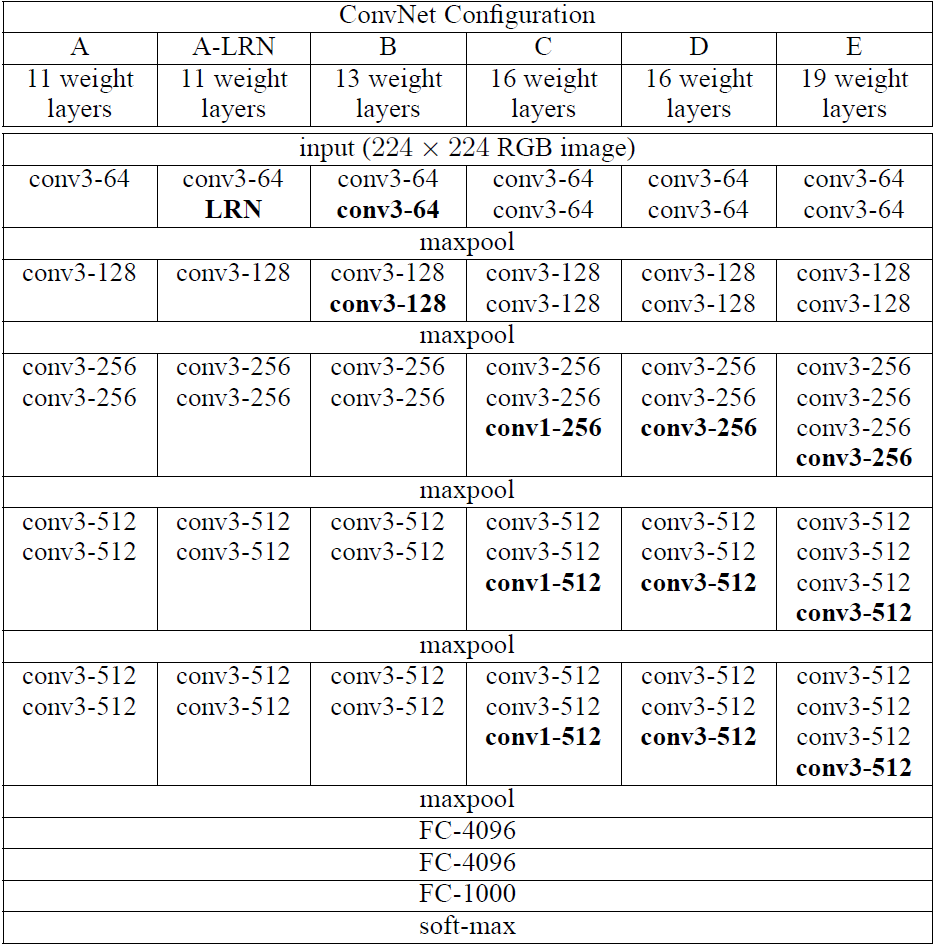
VGG提出了相对AlexNet更深的网络模型,并且通过实验发现网络越深性能越好(在一定范围内)。在网络中,使用了更小的卷积核(3x3),stride为1,同时不单单的使用卷积层,而是组合成了“卷积组”,即一个卷积组包括2-4个3x3卷积层(a stack of 3x3 conv),有的层也有1x1卷积层,因此网络更深,网络使用2x2的max pooling,在full-image测试时候把最后的全连接层(fully-connected)改为全卷积层(fully-convolutional net),重用训练时的参数,使得测试得到的全卷积网络因为没有全连接的限制,因而可以接收任意宽或高为的输入,另外VGGNet卷积层有一个显著的特点:特征图的空间分辨率单调递减,特征图的通道数单调递增,这是为了更好地将HxWx3(1)的图像转换为1x1xC的输出,之后的GoogLeNet与Resnet都是如此。另外上图后面4个VGG训练时参数都是通过pre-trained 网络A进行初始赋值。上图为VGG不同版本的网络模型,较为流行的是VGG-16,与VGG-19。
另外在某篇博客看到一段对VGG-Net与GoogLe-Net的总结,摘取至此(会在最后的参考链接给出引用):
GoogLeNet和VGG的Classification模型从原理上并没有与传统的CNN模型有太大不同。大家所用的Pipeline也都是:训练时候:各种数据Augmentation(剪裁,不同大小,调亮度,饱和度,对比度,偏色),剪裁送入CNN模型,Softmax,Backprop。测试时候:尽量把测试数据又各种Augmenting(剪裁,不同大小),把测试数据各种Augmenting后在训练的不同模型上的结果再继续Averaging出最后的结果。
2. 网络结构
2.1 卷积核
使用3x3小卷积核,是能够获取上下左右中心信息的最小卷积核,同时在某些“卷积组”使用1x1卷积核,stride=1,padding=1(为了保证卷积层后像素保持不变),2个3x3卷积层堆叠起来相当于一个5x5卷积层,3个3x3卷积层堆叠起来相当于一个7x7卷积层。但一些3x3卷积层堆叠起来与直接一个7x7卷积层有什么好处呢?作者给出了如下几个理由:
- 相当于组合了3个非线性修正层而不是只有一个,这样使得决策函数识别性更强。
- 减少了参数的数量,假设有C个3x3卷积组,那么参数各位为:\(3(3^2C^2) = 27C^2\),而C个7x7卷积层他的参数为\(7^2C^2 = 49C^2\)
- 小卷积核代替大卷积核的正则作用带来性能提升。作者用三个conv3x3代替一个conv7x7,认为可以进一步分解(decomposition)原本用7x7大卷积核提到的特征,这里的分解是相对于同样大小的感受野来说的。
1x1卷积核是在保持空间维度不变的情况下,进行了一个线性映射并且多加上了一层非线性修正层,是一种增加决策函数“非线性”(non-linearity)而不影响卷积层感受野的方式。
2.2 池化核
相对于AlexNet使用的3x3池化核,VGG使用2x2池化核,stride为2的max pooling,从而获取更细节的信息。
2.3 全连接层
VGG最后三个全连接层在形式上完全平移AlexNet的最后三层,VGGNet后面三层(三个全连接层)为:
- FC4096-ReLU6-Drop0.5,FC为高斯分布初始化(std=0.005),bias常数初始化(0.1)
- FC4096-ReLU7-Drop0.5,FC为高斯分布初始化(std=0.005),bias常数初始化(0.1)
- FC1000(最后接SoftMax1000分类),FC为高斯分布初始化(std=0.005),bias常数初始化(0.1)
在某个测试阶段(whole-image)作者将FC层利用conv层代替,如下图(上半部分是训练阶段,此时最后三层都是全连接层(输出分别是4096、4096、1000),下半部分是测试阶段(输出分别是1x1x4096、1x1x4096、1x1x1000),最后三层都是卷积层):
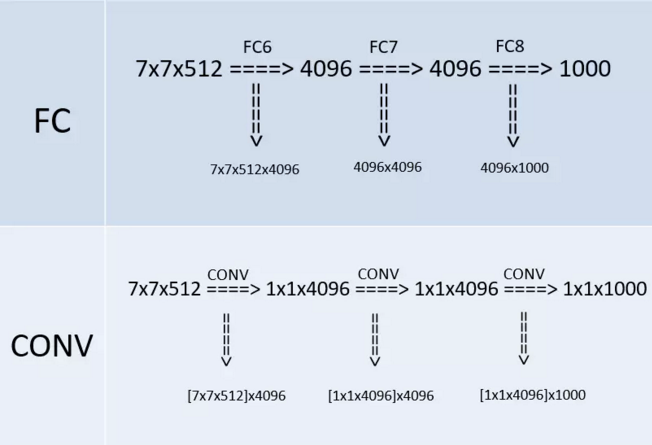
改变之后,整个网络由于没有了全连接层,网络中间的feature map不会固定,所以网络对任意大小的输入都可以处理。
3. 训练
ps:以下来自翻译,因为刚入门,对于训练/测试模型的一些操作还不是很熟悉,所以直接翻译了,积累一些训练方法跟trick。
ConvNet训练过程通常遵循Krizhevsky等人(2012)(除了从多尺度训练图像中对输入裁剪图像进行采样外,如下文所述)。也就是说,通过使用具有动量的小批量梯度下降(基于反向传播(LeCun等人,1989))优化多项式逻辑回归目标函数来进行训练。批量大小设为256,动量为0.9。训练通过权重衰减(L2惩罚乘子设定为)进行正则化,前两个全连接层执行丢弃正则化(丢弃率设定为0.5)。学习率初始设定为,然后当验证集准确率停止改善时,减少10倍。学习率总共降低3次,学习在37万次迭代后停止(74个epochs)。我们推测,尽管与(Krizhevsky等,2012)相比我们的网络参数更多,网络的深度更大,但网络需要更小的epoch就可以收敛,这是由于(a)由更大的深度和更小的卷积滤波器尺寸引起的隐式正则化,(b)某些层的预初始化。
网络权重的初始化是重要的,因为由于深度网络中梯度的不稳定,不好的初始化可能会阻碍学习。为了规避这个问题,我们开始训练配置A(表1),足够浅以随机初始化进行训练。然后,当训练更深的架构时,我们用网络A的层初始化前四个卷积层和最后三个全连接层(中间层被随机初始化)。我们没有减少预初始化层的学习率,允许他们在学习过程中改变。对于随机初始化(如果应用),我们从均值为0和方差为的正态分布中采样权重。偏置初始化为零。值得注意的是,在提交论文之后,我们发现可以通过使用Glorot&Bengio(2010)的随机初始化程序来初始化权重而不进行预训练。
为了获得固定大小的224×224 ConvNet输入图像,它们从归一化的训练图像中被随机裁剪(每个图像每次SGD迭代进行一次裁剪)。为了进一步增强训练集,裁剪图像经过了随机水平翻转和随机RGB颜色偏移(Krizhevsky等,2012)。下面解释训练图像归一化。
训练图像大小。令S是等轴归一化的训练图像的最小边,ConvNet输入从S中裁剪(我们也将S称为训练尺度)。虽然裁剪尺寸固定为224×224,但原则上S可以是不小于224的任何值:对于,裁剪图像将捕获整个图像的统计数据,完全扩展训练图像的最小边;对于,裁剪图像将对应于图像的一小部分,包含小对象或对象的一部分。
我们考虑两种方法来设置训练尺度S。第一种是修正对应单尺度训练的S(注意,采样裁剪图像中的图像内容仍然可以表示多尺度图像统计)。在我们的实验中,我们评估了以两个固定尺度训练的模型:(已经在现有技术中广泛使用(Krizhevsky等人,2012;Zeiler&Fergus,2013;Sermanet等,2014))和。给定ConvNet配置,我们首先使用来训练网络。为了加速网络的训练,用预训练的权重来进行初始化,我们使用较小的初始学习率。
设置S的第二种方法是多尺度训练,其中每个训练图像通过从一定范围(我们使用和)随机采样S来单独进行归一化。由于图像中的目标可能具有不同的大小,因此在训练期间考虑到这一点是有益的。这也可以看作是通过尺度抖动进行训练集增强,其中单个模型被训练在一定尺度范围内识别对象。为了速度的原因,我们通过对具有相同配置的单尺度模型的所有层进行微调,训练了多尺度模型,并用固定的进行预训练。
4. 测试
在测试时,给出训练的ConvNet和输入图像,它按以下方式分类。首先,将其等轴地归一化到预定义的最小图像边,表示为Q(我们也将其称为测试尺度)。我们注意到,Q不一定等于训练尺度S(正如我们在第4节中所示,每个S使用Q的几个值会导致性能改进)。然后,网络以类似于(Sermanet等人,2014)的方式密集地应用于归一化的测试图像上。即,全连接层首先被转换成卷积层(第一FC层转换到7×7卷积层,最后两个FC层转换到1×1卷积层)。然后将所得到的全卷积网络应用于整个(未裁剪)图像上。结果是类得分图的通道数等于类别的数量,以及取决于输入图像大小的可变空间分辨率。最后,为了获得图像的类别分数的固定大小的向量,类得分图在空间上平均(和池化)。我们还通过水平翻转图像来增强测试集;将原始图像和翻转图像的soft-max类后验进行平均,以获得图像的最终分数。
由于全卷积网络被应用在整个图像上,所以不需要在测试时对采样多个裁剪图像(Krizhevsky等,2012),因为它需要网络重新计算每个裁剪图像,这样效率较低。同时,如Szegedy等人(2014)所做的那样,使用大量的裁剪图像可以提高准确度,因为与全卷积网络相比,它使输入图像的采样更精细。此外,由于不同的卷积边界条件,多裁剪图像评估是密集评估的补充:当将ConvNet应用于裁剪图像时,卷积特征图用零填充,而在密集评估的情况下,相同裁剪图像的填充自然会来自于图像的相邻部分(由于卷积和空间池化),这大大增加了整个网络的感受野,因此捕获了更多的上下文。虽然我们认为在实践中,多裁剪图像的计算时间增加并不足以证明准确性的潜在收益,但作为参考,我们还在每个尺度使用50个裁剪图像(5×5规则网格,2次翻转)评估了我们的网络,在3个尺度上总共150个裁剪图像,与Szegedy等人(2014)在4个尺度上使用的144个裁剪图像。
5. 其他
文章最后还有单尺度评估与多尺度评估,多裁剪图像评估等,这里就不细说了。
另外在某篇博客找到了卷积层与全连接层之间的关系:
卷积层和全连接层的唯一区别在于卷积层的神经元对输入是局部连接的, 并且同一个通道(channel)内不同神经元共享权值(weights). 卷积层和全连接层都是进行了一个点乘操作, 它们的函数形式相同. 因此卷积层可以转化为对应的全连接层, 全连接层也可以转化为对应的卷积层.
比如VGGNet[1]中, 第一个全连接层的输入是\(7*7*512\), 输出是4096. 这可以用一个卷积核大小\(7*7\), 步长(stride)为1, 没有填补(padding), 输出通道数4096的卷积层等效表示, 其输出为\(1*1*4096\), 和全连接层等价. 后续的全连接层可以用1x1卷积等效替代. 简而言之, 全连接层转化为卷积层的规则是: 将卷积核大小设置为输入的空间大小.
这样做的好处在于卷积层对输入大小没有限制, 因此可以高效地对测试图像做滑动窗式的预测. 比如训练时对\(224*224\)大小的图像得到\(7*7*512\)的特征, 而对于\(384*384\)大小的测试图像, 将得到\(12*12*512\)的特征, 通过后面3个从全连接层等效过来的卷积层, 输出大小是\(6*6*1000\), 这表示了测试图像在36个空间位置上的各类分数向量. 和分别对测试图像的36个位置使用原始的CNN相比, 由于等效的CNN共享了大量计算, 这种方案十分高效而又达到了相同目的.
全连接层和卷积层的等效表示最早是由[2]提出. [2]将卷积层中的线性核改成由一系列的全连接层组成的小神经网络, 用于在每个卷积层提取更复杂的特征. 在实现时, NIN是由一个传统卷积层后面加一系列1*1卷积得到的.
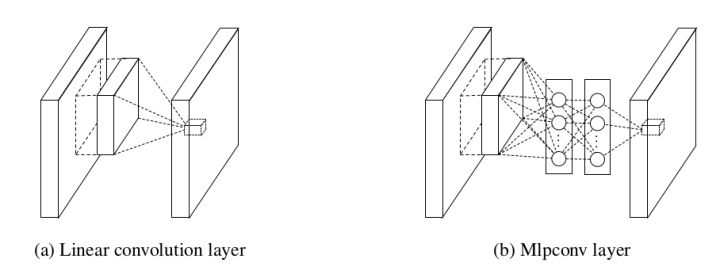
[3]论证了用卷积层替代全连接层的好处, 下图黄色部分是多出来的计算量, 和将一个网络运用在测试图像的多个位置相比, 这种方法十分高效.
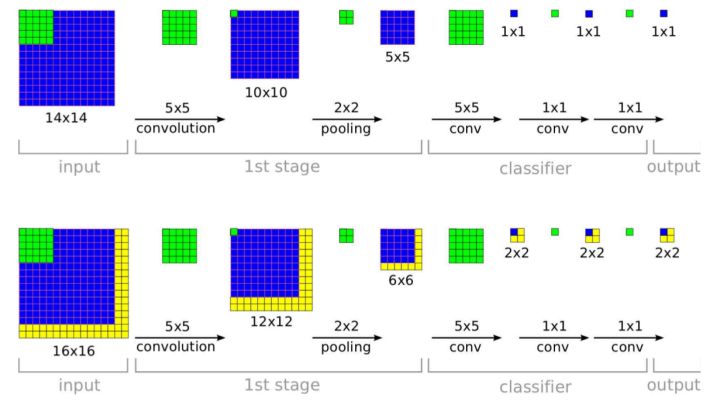
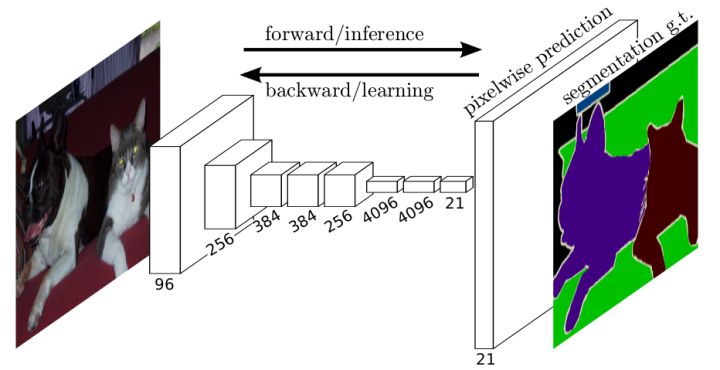
由于卷积层可以处理任意大小输入, 非常适合检测, 分割等任务, 比如[4]提出全卷积网络用于进行语义分割.
6.参考链接
https://blog.csdn.net/abc_138/article/details/80568450
https://blog.csdn.net/qq_31531635/article/details/71170861
https://blog.csdn.net/qq_26591517/article/details/81071393
https://blog.csdn.net/u011440696/article/details/77756776
http://blog.leanote.com/post/dataliu/5d29e67dd0b0
【网络结构】VGG-Net论文解析的更多相关文章
- 摄像头定位:ICCV2019论文解析
摄像头定位:ICCV2019论文解析 SANet: Scene Agnostic Network for Camera Localization 论文链接: http://openaccess.the ...
- [Network Architecture]Mask R-CNN论文解析(转)
前言 最近有一个idea需要去验证,比较忙,看完Mask R-CNN论文了,最近会去研究Mask R-CNN的代码,论文解析转载网上的两篇博客 技术挖掘者 remanented 文章1 论文题目:Ma ...
- 目标形体形状轮廓重建:ICCV2019论文解析
目标形体形状轮廓重建:ICCV2019论文解析 Shape Reconstruction using Differentiable Projections and Deep Priors 论文链接: ...
- 结构感知图像修复:ICCV2019论文解析
结构感知图像修复:ICCV2019论文解析 StructureFlow: Image Inpainting via Structure-aware Appearance Flow 论文链接: http ...
- 对抗性鲁棒性与模型压缩:ICCV2019论文解析
对抗性鲁棒性与模型压缩:ICCV2019论文解析 Adversarial Robustness vs. Model Compression, or Both? 论文链接: http://openacc ...
- 白*衡(Color Constancy,无监督AWB):CVPR2019论文解析
白*衡(Color Constancy,无监督AWB):CVPR2019论文解析 Quasi-Unsupervised Color Constancy 论文链接: http://openaccess. ...
- 将视频插入视频:CVPR2019论文解析
将视频插入视频:CVPR2019论文解析 Inserting Videos into Videos 论文链接: http://openaccess.thecvf.com/content_CVPR_20 ...
- LTMU论文解析
LTMU 第零部分:前景提要 一般来说,单目标跟踪任务可以从以下三个角度解读: A matching/correspondence problem.把其视为前后两帧物体匹配的任务(而不考虑在跟踪过程中 ...
- CVPR2020论文解析:实例分割算法
CVPR2020论文解析:实例分割算法 BlendMask: Top-Down Meets Bottom-Up for Instance Segmentation 论文链接:https://arxiv ...
随机推荐
- mysql json
SELECT name, profile->"$.twitter" AS `twitter` FROM `user` WHERE profile->"$.tw ...
- Yii框架2.0的小部件
小部件是视图里的可重用单元. 小部件是在视图中使用的,但是可能需要使用控制器传给他的模型,比如在渲染表单的时候.比如一般的时间拾取器就可以直接砸视图里加入如下代码就可以: <?php use y ...
- c++ caffe 输出 activation map 、 层参数
python输出activation map与层参数:https://blog.csdn.net/tina_ttl/article/details/51033660 caffe::Net文档: htt ...
- Apache mahout 源码阅读笔记--DataModel之FileDataModel
要做推荐,用户行为数据是基础. 用户行为数据有哪些字段呢? mahout的DataModel支持,用户ID,ItemID是必须的,偏好值(用户对当前Item的评分),时间戳 这四个字段 {@code ...
- jquery prop attr
checked比较特殊,只要设置了属性checked,不管何值都是checked的.例如:<input type="checkbox" checked><inpu ...
- (0.2.4)Mysql安装——yum源安装
转自:https://www.cnblogs.com/jimboi/p/6405560.html Centos6.8通过yum安装mysql5.7 1.下载好对应版本的yum源文件 2.安装用来配置m ...
- IDEA中打包Spark项目提示Error:(16, 48) java: -source 1.5 中不支持 lambda 表达式
在idea中新建了一Spark的项目,在做项目的编译打包的时候,提示如下错误信息: Error:(, ) java: -source 1.5 中不支持 lambda 表达式 (请使用 -source ...
- 练习webpack遇到的一些问题以及解决办法,供自己以后参考
1.利用nodeJs安装webpack时报出以下错误提示: 这个错误我在网上搜了一下,说是npm文件配置问题,也就是权限不够 解决办法:npm config set registry http://r ...
- DataGird 相关
DataGird控件 DataGirdView 控件 DataGird类 他们之间是什么关系??????? DataGridView 控件是替换 DataGrid 控件的新控 ...
- bit,byte,char,位,字节,字符 的区别
bit,byte,char,位,字节,字符 的区别 原创文章,未经作者允许,禁止转载!!!