hadoop知识整理(2)之MapReduce
之前写的关于MR的文章的前半部分已丢。
所以下面重点从3个部分来谈MR:
1)Job任务执行过程,以及主要进程-ResourceManager和NodeManager作用;
2)shuffle过程;
3)主要代码;
一、Job任务执行过程
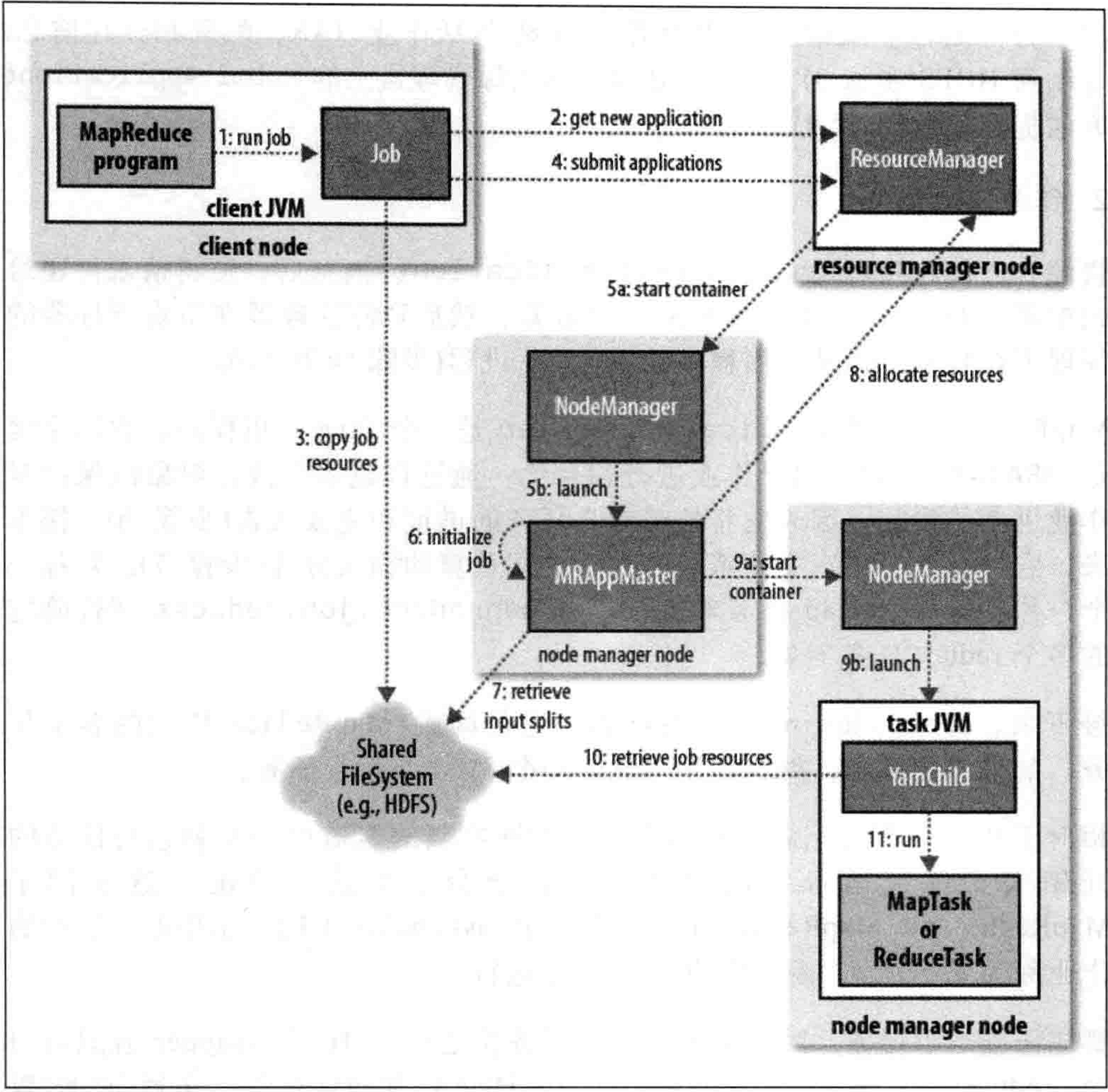
这里是hadoop2.0-ResourceManager的Job的执行过程:
1)run job阶段,由提交Job客户端JVM完成,主要做job环境信息的收集,各个组件类,如Mapper、Reducer类,输出输入的K-V类型做检验是否合法,并且检验输入hdfs路径的合法性,还有输出hdfs目录是否已经存在,检测不通过,则Job停止。
2)1阶段通过后,Job会获取一个Application对象,同时给一个应用ID,用于MapReduce的作业ID;
3)再次检查输入输出目录的合法性,hdfs目录的合法性,计算作业的输入分片,如果分片无法计算,作业将不会提交,错误将返回给MR客户端程序,如果没有问题,将运行作业的所需资源,包括MR程序的JAR文件,配置文件以及输入分片,复制到一个以应用ID命名的hdfs目录下的共享文件系统中,JOB的jar的副本较多,所以在运行job时,集群的所有节点都可访问job的副本;
4)MR客户端通过调用submitApplication()方法提交Job给RM;
5)RM即资源管理器(ResourceManager)收到Job作业后,并将请求传递给YARN的调度器(scheduler),调度器会分配一个容器container,然后资源管理器在节点管理器(NodeManager)中启动application master进程;
6)application master是一个java应用程序,主类为MRAppMaster,他将接收来自Job的进度和完成报告;
7)application master对Job的初始化,是创建了很多薄记对象,以保持对于job进度的跟踪,然后他将从hdfs共享存储中获得由MR客户端计算的输入分片,然后对每一个split创建一个Map任务,以及确定有几个redece任务;
8)分配资源,application master程序,会计算构成MR的job的所有任务,判断是在一个节点上进行还是多个节点进行并行计算,简单来说,通过MR的数量来将这个job定性为小任务还是超级(uber)任务;
小job指的是,少于10个mapper且只有1个reducer,且输入大小小于一个HDFS块的job。通过设置mapreduce.job.ubertask.enable设置为true才可确保启动超级任务作业。
如果非uber任务,application master会向资源管理器RM请求需要的所有容器资源;当然,请求中先为map任务请求,然后是reduce任务,通常,完成有5%的map任务完成之后,为reduce任务请求资源的信息才会发出;
reduce任务可以在集群的任何节点运行,但是map任务尽量本着本地化的策略在进行,尽量减少磁盘的IO操作,通常情况之下,每个map任务和reduce任务都会申请获得1核的cpu以及1GB的内存,参数可配。
9)一旦RM分配了一个特定节点的容器,那么application master就与该nodeManager进行通信来启动容器;
10)执行任务的主类为YarnChild,一个JAVA程序,在运行任务之前,首先将需要的资源本地化,从共享的hdfs中取得,包括作业的配置,jar包和其他所有缓存文件等等;
11)执行MR任务。
以上是整个Job的生命周期。
ResourceManager(RM)
RM是一个全局的资源管理器,负责整个系统的资源管理和分配。它主要由两个组件构成:调度器(Scheduler)和应用程序管理器(Applications Manager,ASM)。
调度器 调度器根据容量、队列等限制条件(如每个队列分配一定的资源,最多执行一定数量的作业等),将系统中的资源分配给各个正在运行的应用程序。需要注意的是,该调度器是一个“纯调度器”,它不再从事任何与具体应用程序相关的工作,比如不负责监控或者跟踪应用的执行状态等,也不负责重新启动因应用执行失败或者硬件故障而产生的失败任务,这些均交由应用程序相关的ApplicationMaster完成。调度器仅根据各个应用程序的资源需求进行资源分配,而资源分配单位用一个抽象概念“资源容器”(Resource Container,简称Container)表示,Container是一个动态资源分配单位,它将内存、CPU资源封装在一起,从而限定每个任务使用的资源量。
应用程序管理器(Applications Manager)负责管理整个系统中所有应用程序,包括应用程序提交、与调度器协商资源以启动ApplicationMaster、监控ApplicationMaster运行状态并在失败时重新启动它等。
ApplicationMaster(AM)
用户提交的每个应用程序均包含一个AM,主要功能包括:
与RM调度器协商以获取资源(用Container表示);
将得到的任务进一步分配给内部的任务(资源的二次分配);
与NM通信以启动/停止任务;
监控所有任务运行状态,并在任务运行失败时重新为任务申请资源以重启任务。
NodeManager(NM)
NM是每个节点上的资源和任务管理器,一方面,它会定时地向RM汇报本节点上的资源使用情况和各个Container的运行状态;另一方面,它接收并处理来自AM的Container启动/停止等各种请求。
Container
Container是YARN中的资源抽象,它封装了某个节点上的内存、CPU资源,当AM向RM申请资源时,RM为AM返回的资源便是用Container表示。YARN会为每个任务分配一个Container,且该任务只能使用该Container中描述的资源。
二、shuffle
MapReduce确保每个reducer的输入都是按照Key来进行排序的。系统执行排序,且将Map输出作为输入给Reduce的过程称之为shuffer。
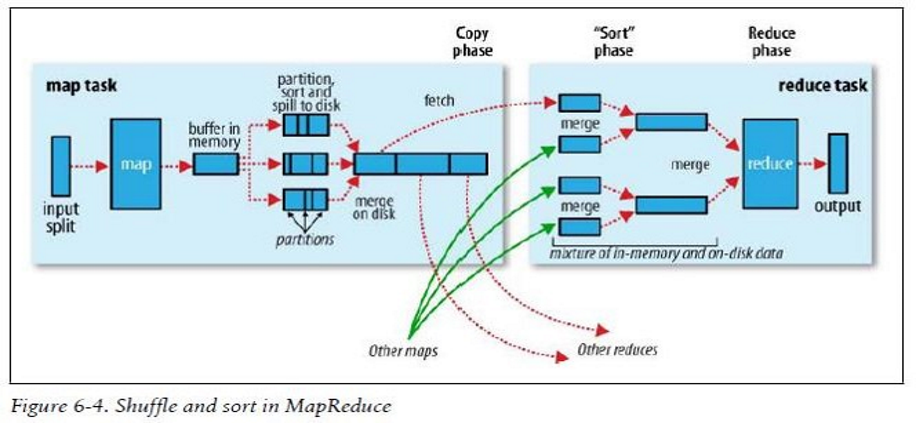
1)map端在输出时,会首先输出到一个内存缓冲区,英文名字为spill,他的默认大小为100M,可以理解为在内存中一部分首尾相连的内存区域,这个内存缓冲区的阈值为80%,可通过mapreduce.task.io.spill.percent参数改变,当map的输出达到阈值时,会把溢出的旧输出内容写入磁盘,新的输出继续往缓冲区去写,至于为什么是80%,是因为内存区的IO远快于物理磁盘的IO速度,所以在达到阈值时,开始溢写,如果spill写满时,仍未写到物理磁盘上,那么map会处于wait状态;
2)而在将map输出结果写磁盘之前,会根据最后返回给reduce的数据划分成对应的分区,且在每个分区中,后台线程会按照key进行排序,这个时候如果存在一个conbiner,那么conbiner的函数redece是在排序后进行的。运行combiner会使map的输出结果更加紧凑,因此会减少写磁盘IO的压力。
3)这时的疑问在于,当spill内存缓冲区不足以支撑map的输出时,那么会将输出溢写到本地磁盘中,那么map的输出会有多个磁盘文件,所以,在map任务完成之前,会对他们进行合并排序。
至于存在combine的情况时, 任务会判断溢出文件的数量,假如溢出文件的数量大于3,那么有必要再对此进行一次combine操作,这个操作的时间是,map任务的最终输出准备向磁盘上写时。所以由此判断,combine可以在map任务中多次执行,也不会影响最终的结果,至于是否再次进行combine操作,那么由map来进行判断,通过溢出文件的数量来进行判断,其主要目的时判断进行combine带来的开销是否足够抵消IO磁盘操作。
4)在这里,map任务的输出,对这个输出文件进行压缩,然后放到磁盘会更好,这是一个典型的节省磁盘IO的有效操作。这样同样可以减少通过网络IO传输给reduce的文件大小。压缩的配置参数为:mapreduce.map.output.compress设置为true,hadoop便会启动map结果的压缩功能。
5)至于reduce任务,前面在分析job的执行过程的时候,知道有一个参数会影响application master向RM为reduce申请资源的时间,那便是map任务完成的比率,比率默认是5%,即有5%的map任务完成时,那么reduce任务将开始进行工作。在上图中,reduce是通过fetch(抓)过来map的输出结果,其实是通过网络通信将map的输出结果复制过来。reduce任务有少量的复制线程,默认值为5个,这5个线程可以从多个执行完毕的map任务中复制过来其输出结果。而这个线程的数量,可以通过mapreduce.reduce.shuffle.parallelcopies属性。
6)这里的问题关键点在于,reduce任务如何得知map任务已经结束,且从哪里获得其输出结果?其实还在于强大的application master,全程负责所有任务的调度工作,当map任务完成后,会通过心跳机制,告知application master,而reduce任务一旦开启,也会有一个线程,不停轮询application master的map任务完成情况,这里推测,完成的map任务的网络主机情况,输出结果的磁盘存储情况,会保存在application master的一个对象中,大概率是一个(HashMap),而当reduce取得map的输出结果之后,并不会马上删除此map的结果释放资源,他会等待application master的通知,这是在整体job完成后执行的。
7)下一步当reduce取得map任务的输出结果只会,需要进行的就是不停的merge工作。
如果,map的输出结果非常小,那么直接在reduce任务的jvm内存中进行合并了,但往往这种情况并不会经常发生。
当有很多个map的输出,且输出文件都比较大,redece会将map的输出结果复制到磁盘,如果磁盘上的副本太多了,那么reduce会将这些个文件合并成更大的文件,而之前在于被压缩的map输出,都会在内存中被解压缩。
直到将所有的map复制完毕,那么下一步会进行真正的reduce合并操作。
reduce合并这一块很有意思,hadoop为了减少磁盘的IO,做了很多构想,很巧妙。
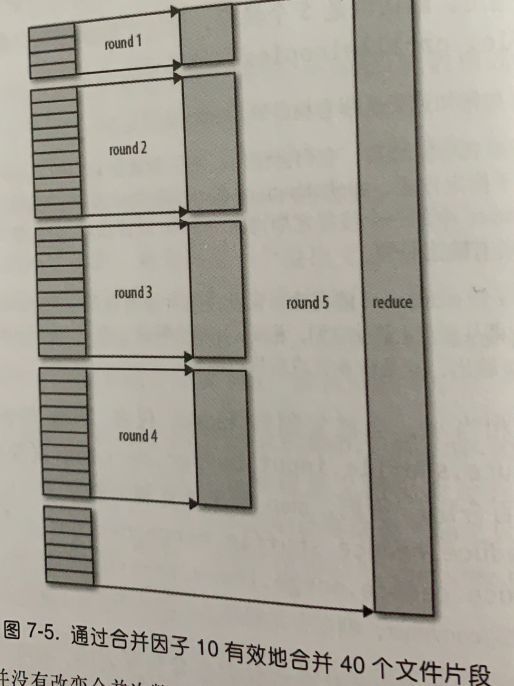
首先有一个指定参数,名字为合并因子,通过:mapreduce.task.io.sort.factor属性设置,默认为10。
这个因子决定你的map输出数量合并多少次,假如有40个map的输出结果,那么将会合并4次。
如上图所看,一共有40个map输出,那么hadoop不会每10个文件合并一次,将合并完成的4个文件交给reduce task。
他会第一次合并4个文件形成s1,第二次、三次、四次分别合并10个文件形成s2和s3以及s4,然后它会将s1、s2、s3、s4以及剩下未合并的6个文件直接交给reduce函数。
因为map输出结果本身为排序状态,这样操作可以减少了6个map结果文件的多一次通过磁盘IO进行合并的操作,而hadoop这样做,也只是为了减少磁盘IO,多用内存。
而做完这个操作之后,reduce调用reduce函数,将输出结果复用到HDFS之前配置地输出目录当中。至此,shuffle结束。
而MR任务的魔幻点就在于shuffle过程,他神奇地将乱序地文件,通过一系列map和reduce操作,通过强大地设计application master地控制中心,完美的完成了整理数据工作。
所以,知晓了MR任务地执行过程和shuffle内容,那么MR任务地优化点也来了,不论是通过参数还是在编码中刻意进行改变,都会很好地优化MR。
推测执行:application master会跟踪每个task的执行情况,当某个task执行过慢时,会创建出这个task的副本,从而进一步判定task是否存在执行失误的情况,假如副本task先行执行完成,那么会废掉原task。
从中体现application master强大的task线程调度能力。而这个参数的配置方法为:mapreduce.map.speculative/reduce.speculative->true。
这个推测执行功能有点过于屌了,但并不推荐使用,因为它是以整个集群的资源为代价的,应该根据具体情况开启此功能。
参数优化点:
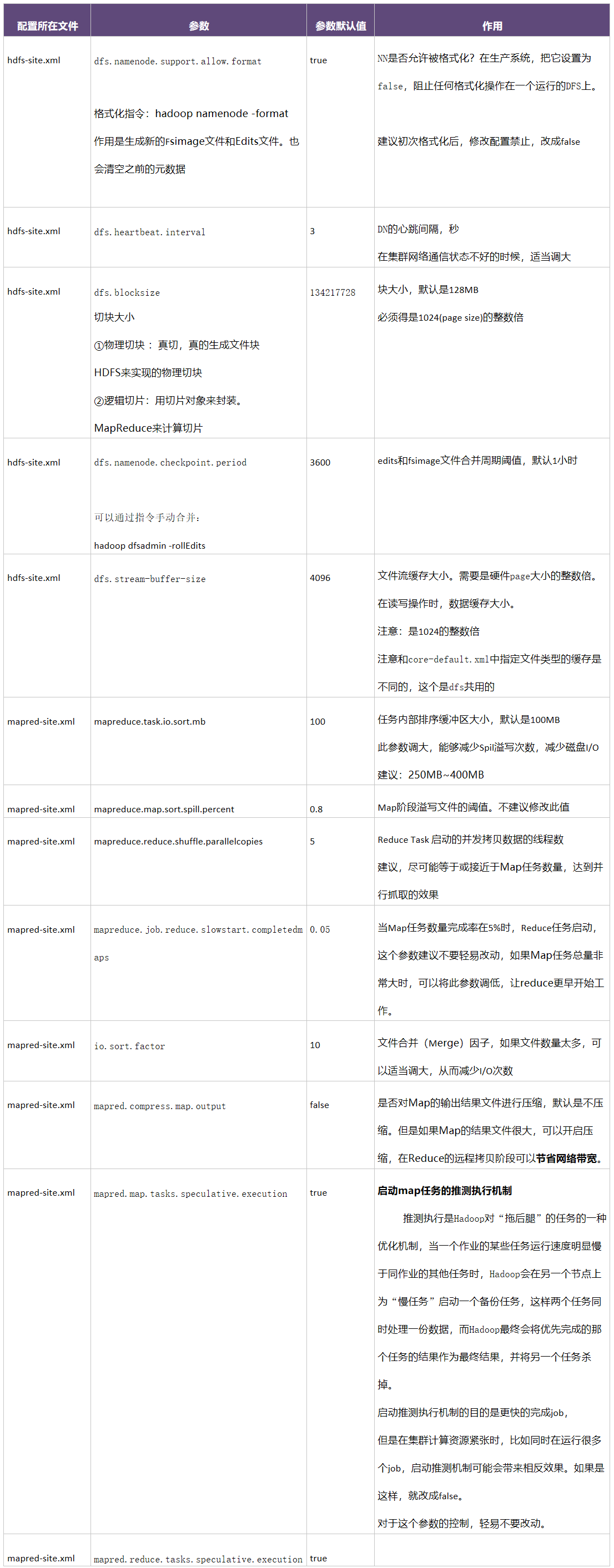
调优的总体纲领为:
1)减少数据传输--》增加conbine操作和map输出压缩操作;
2)尽量使用内存-》增加spill内存缓冲区的大小-增加map和reduce的jvm内存参数->mapred.child.java.opts,这个是task任务执行时的jvm内存大小;
3)减少磁盘IO-》压缩map输出,减少reduce合并次数,即增大合并因子参数;
4)增大任务并行数-》增加reduce的fetch数量,尽量更改此参数数量与map数量一致,达到并行抽取;
5)剩下就是推测执行了,根据集群网络情况和机器性能进行调优操作。
jvm调优,jvm重用机制:
1)默认不允许JVM重用;
2)一旦开启JVM的重用,所有的task都将在一个jvm中执行,简单表达,即是,所有的包括application master、map task、reduce task都会在一个jvm-container中执行;
3)此种情况适用于小的MR任务,默认为10个及其以下的map任务,1个的reduce任务,且reduce输入大小为小于一个hdfs文件块的任务。
4)此种情况依旧适用于海量小文件的情况,减少jvm的频繁启停;
对于海量的小文件,应该将多个小文件处理成为一个文件,以减少map的任务数量。
三、部分源码,主要代码
MapTask部分,即map小任务部分:
启动map任务,调用的是其中的run方法
@Override
public void run(final JobConf job, final TaskUmbilicalProtocol umbilical)
throws IOException, ClassNotFoundException, InterruptedException {
this.umbilical = umbilical; if (isMapTask()) {
// If there are no reducers then there won't be any sort. Hence the map
// phase will govern the entire attempt's progress.
if (conf.getNumReduceTasks() == ) {
mapPhase = getProgress().addPhase("map", 1.0f);
} else {
// If there are reducers then the entire attempt's progress will be
// split between the map phase (67%) and the sort phase (33%).
mapPhase = getProgress().addPhase("map", 0.667f);
sortPhase = getProgress().addPhase("sort", 0.333f);
}
}
TaskReporter reporter = startReporter(umbilical); boolean useNewApi = job.getUseNewMapper();
initialize(job, getJobID(), reporter, useNewApi); // check if it is a cleanupJobTask
if (jobCleanup) {
runJobCleanupTask(umbilical, reporter);
return;
}
if (jobSetup) {
runJobSetupTask(umbilical, reporter);
return;
}
if (taskCleanup) {
runTaskCleanupTask(umbilical, reporter);
return;
} if (useNewApi) {
runNewMapper(job, splitMetaInfo, umbilical, reporter);
} else {
runOldMapper(job, splitMetaInfo, umbilical, reporter);
}
done(umbilical, reporter);
}
这里启动了taskReporter,向application master报告执行情况,并且初始化了整个Job任务,且在2.0中,调用了runNewMapper方法;
@SuppressWarnings("unchecked")
private <INKEY,INVALUE,OUTKEY,OUTVALUE>
void runNewMapper(final JobConf job,
final TaskSplitIndex splitIndex,
final TaskUmbilicalProtocol umbilical,
TaskReporter reporter
) throws IOException, ClassNotFoundException,
InterruptedException {
// make a task context so we can get the classes
org.apache.hadoop.mapreduce.TaskAttemptContext taskContext =
new org.apache.hadoop.mapreduce.task.TaskAttemptContextImpl(job,
getTaskID(),
reporter);
// make a mapper
org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE> mapper =
(org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE>)
ReflectionUtils.newInstance(taskContext.getMapperClass(), job);
// make the input format
org.apache.hadoop.mapreduce.InputFormat<INKEY,INVALUE> inputFormat =
(org.apache.hadoop.mapreduce.InputFormat<INKEY,INVALUE>)
ReflectionUtils.newInstance(taskContext.getInputFormatClass(), job);
// rebuild the input split
org.apache.hadoop.mapreduce.InputSplit split = null;
split = getSplitDetails(new Path(splitIndex.getSplitLocation()),
splitIndex.getStartOffset());
LOG.info("Processing split: " + split);
org.apache.hadoop.mapreduce.RecordReader<INKEY,INVALUE> input =
new NewTrackingRecordReader<INKEY,INVALUE>
(split, inputFormat, reporter, taskContext);
job.setBoolean(JobContext.SKIP_RECORDS, isSkipping());
org.apache.hadoop.mapreduce.RecordWriter output = null;
// get an output object
if (job.getNumReduceTasks() == 0) {
output =
new NewDirectOutputCollector(taskContext, job, umbilical, reporter);
} else {
output = new NewOutputCollector(taskContext, job, umbilical, reporter);
}
org.apache.hadoop.mapreduce.MapContext<INKEY, INVALUE, OUTKEY, OUTVALUE>
mapContext =
new MapContextImpl<INKEY, INVALUE, OUTKEY, OUTVALUE>(job, getTaskID(),
input, output,
committer,
reporter, split);
org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE>.Context
mapperContext =
new WrappedMapper<INKEY, INVALUE, OUTKEY, OUTVALUE>().getMapContext(
mapContext);
try {
input.initialize(split, mapperContext);
mapper.run(mapperContext);
mapPhase.complete();
setPhase(TaskStatus.Phase.SORT);
statusUpdate(umbilical);
input.close();
input = null;
output.close(mapperContext);
output = null;
} finally {
closeQuietly(input);
closeQuietly(output, mapperContext);
}
}
在代码中可见, 在这个方法中解析了job中的计算出的,InputSplit信息,这里面封装了所有的map文件的切片信息,而InputSplit对象的初始化,由 private <T> T getSplitDetails(Path file, long offset)方法获得。
这个方法里去获取 T split = deserializer.deserialize(null);切片信息,而切片信息,又通过AvroSerialization获得,代码如下,现在就可以串起来,Job客户端从RM获取了一个输入流,而这个输入流中存储了map所需输入文件的切片信息,类似上文讲的,从hdfs文件系统中下载文件的过程之一,先从NN节点获取文件的切片信息:
@Override
public T deserialize(T t) throws IOException {
return reader.read(t, decoder);
}
InputSplit中包含了切片信息,拿到本map任务需要的切片后,通过RecordReader,获取文件内容,然后反射调用程序员缩写的Mapper类。此项代码在runNewMapper方法的第722行:
org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE> mapper =
(org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE>)
ReflectionUtils.newInstance(taskContext.getMapperClass(), job);
然后在最后有如下代码:
try {
input.initialize(split, mapperContext);
mapper.run(mapperContext);
mapPhase.complete();
setPhase(TaskStatus.Phase.SORT);
statusUpdate(umbilical);
input.close();
input = null;
output.close(mapperContext);
output = null;
} finally {
closeQuietly(input);
closeQuietly(output, mapperContext);
}
这里,初始化输入文件切片,然后run程序员写的mapper再之后输出结果,关闭资源。
需要注意的是,NewOutputCollector这个在上文代码中的作用:
他会每次收集调用map新的kv对,然后将他们spill到内存或者文件中,还可以做进一步的partition和sort和combine操作,当存在reduce的时候,此类代码如下:
private class NewOutputCollector<K,V>
extends org.apache.hadoop.mapreduce.RecordWriter<K,V> {
private final MapOutputCollector<K,V> collector;
private final org.apache.hadoop.mapreduce.Partitioner<K,V> partitioner;
private final int partitions; @SuppressWarnings("unchecked")
NewOutputCollector(org.apache.hadoop.mapreduce.JobContext jobContext,
JobConf job,
TaskUmbilicalProtocol umbilical,
TaskReporter reporter
) throws IOException, ClassNotFoundException {
collector = createSortingCollector(job, reporter);
partitions = jobContext.getNumReduceTasks();
if (partitions > 1) {
partitioner = (org.apache.hadoop.mapreduce.Partitioner<K,V>)
ReflectionUtils.newInstance(jobContext.getPartitionerClass(), job);
} else {
partitioner = new org.apache.hadoop.mapreduce.Partitioner<K,V>() {
@Override
public int getPartition(K key, V value, int numPartitions) {
return partitions - 1;
}
};
}
} @Override
public void write(K key, V value) throws IOException, InterruptedException {
collector.collect(key, value,
partitioner.getPartition(key, value, partitions));
} @Override
public void close(TaskAttemptContext context
) throws IOException,InterruptedException {
try {
collector.flush();
} catch (ClassNotFoundException cnf) {
throw new IOException("can't find class ", cnf);
}
collector.close();
}
}
还有一个MapOutputBuffer需要注意,他是在实例化NewOutputCollector时被创建的:
构造方法:
private final MapOutputCollector<K,V> collector;
collector = createSortingCollector(job, reporter);
然后在
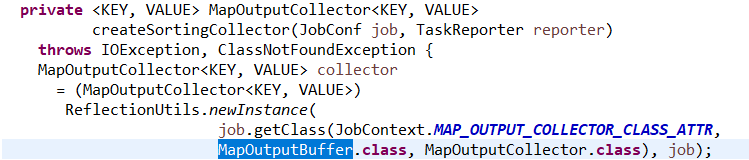
创建了这个buffer对象,在这个对象中

ReduceTask部分源码:

hadoop知识整理(2)之MapReduce的更多相关文章
- 转:hadoop知识整理
文章来自于:http://tianhailong.com/hadoop%E7%9F%A5%E8%AF%86%E6%95%B4%E7%90%86.html 按照what.how.why整理了下文章,帮助 ...
- hadoop知识整理(3)之MapReduce之代码编写
前面2篇文章知道了HDFS的存储原理,知道了上传和下载文件的过程,同样也知晓了MR任务的执行过程,以及部分代码也已经看到,那么下一步就是程序员最关注的关于MR的业务代码(这里不说太简单的): 一.关于 ...
- hadoop知识整理(4)之zookeeper
一.介绍 一个分布式协调服务框架: 一个精简的文件系统,每个节点大小最好不大于1MB: 众多hadoop组件依赖于此,比如hdfs,kafka,hbase,storm等: 旨在,分布式应用中,提供一个 ...
- hadoop知识整理(1)之HDFS
一.HDFS是一个分布式文件系统 体系架构: hdfs主要包含了3部分,namenode.datanode和secondaryNameNode namenode主要作用和运行方式: 1)管理hdfs的 ...
- hadoop知识整理(5)之kafka
一.简介 来自官网介绍: 翻译:kafka,是一个分布式的流处理平台.LinkedIn公司开发.scala语言编写. 1.支持流处理的发布订阅模式,类似一个消息队列系统: 2.多备份存储,副本冗余 ...
- Hadoop学习基础之三:MapReduce
现在是讨论这个问题的不错的时机,因为最近媒体上到处充斥着新的革命所谓“云计算”的信息.这种模式需要利用大量的(低端)处理器并行工作来解决计算问题.实际上,这建议利用大量的低端处理器来构建数据中心,而不 ...
- js事件(Event)知识整理
事件(Event)知识整理,本文由网上资料整理而来,需要的朋友可以参考下 鼠标事件 鼠标移动到目标元素上的那一刻,首先触发mouseover 之后如果光标继续在元素上移动,则不断触发mousemo ...
- Kali Linux渗透基础知识整理(四):维持访问
Kali Linux渗透基础知识整理系列文章回顾 维持访问 在获得了目标系统的访问权之后,攻击者需要进一步维持这一访问权限.使用木马程序.后门程序和rootkit来达到这一目的.维持访问是一种艺术形式 ...
- Kali Linux渗透基础知识整理(二)漏洞扫描
Kali Linux渗透基础知识整理系列文章回顾 漏洞扫描 网络流量 Nmap Hping3 Nessus whatweb DirBuster joomscan WPScan 网络流量 网络流量就是网 ...
随机推荐
- 3.6 Go String型
1. Go String型 Unicode是一种字符集,code point UTF8是unicode的存储实现,转换为字节序列的规则 go的rune类型 可以取出字符串里的unicode 字符串是一 ...
- deno+mongo实战踩坑记
自从 deno 1.0 发布以来,有关 deno 的文章很多,大多数都是在讨论怎么安装 deno .deno 有哪些特点 .deno 和 node 有哪些异同.deno是不是 node 的替代品等.咱 ...
- 【K8S】基于Docker+K8S+GitLab/SVN+Jenkins+Harbor搭建持续集成交付环境(环境搭建篇)
写在前面 最近在 K8S 1.18.2 版本的集群上搭建DevOps环境,期间遇到了各种坑.目前,搭建环境的过程中出现的各种坑均已被填平,特此记录,并分享给大家! 服务器规划 IP 主机名 节点 操作 ...
- MyCat垂直分库
一.什么是垂直分库 将一类功能的表从一个实例切分到另一个实例,横向扩展实例,增加写负载 目标:将1个实例的4类表拆分多4个实例中 二.垂直切分步骤 2.1收集分析业务模块间的关系,能分几个库 2.2全 ...
- SSH启动Tomcat:The requested resource is not available
原因:请求的资源不可用. 解决方法: (1)单词拼写错误,可能出现在 ——路径名称 ——配置文件名称 ——包名 ——类名 ——文件内的单词 (2)项目里文件的位置错误 (3)SSH相关的类文件里,定义 ...
- oracle 11g 用户名和密码默认区分大小写
oracle 11g 用户名和密码默认区分大小写,可更改alter system set sec_case_sensitive_logon=false 设置改为不区分大小写.
- 设计MyTime类 代码参考
#include <iostream> #include <cstdio> using namespace std; class MyTime { private: int h ...
- Gauge框架在JS中的简单应用
gauge框架简介 Gauge是一个轻量级的跨平台测试自动化工具. gauge安装[Win10 64位下测试] [百度网盘链接]https://pan.baidu.com/s/1bidE34gLLrS ...
- MySql Oracle SqlServer 数据库的数据类型列表
Oracle数据类型 一.概述 在ORACLE8中定义了:标量(SCALAR).复合(COMPOSITE).引用(REFERENCE)和LOB四种数据类型,下面详细介绍它们的特性. 二.标量(SCA ...
- 轻松实现记录与撤销——C#中的Command模式
Command模式属于行为模式,作为大名鼎鼎的23个设计模式之一,Command模式理解起来不如工厂模式,单例模式等那么简单直白.究其原因,行为模式着重于使用,如果没有编程实践,确实不如创造模式那么直 ...