吴裕雄--天生自然PYTHON爬虫:爬虫攻防战

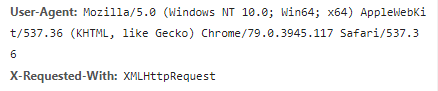

我们在开发者模式下不仅可以找到URL、Form Data,还可以在Request headers 中构造浏览器的请求头,封装自己。服务器识别浏览器访问的方法就是判断keywor是否为Request headers下的User-Agent,因此我们只需要构造这个请求头的参数。创建请求头部信息即可。
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36'
}
response = requests.get(url,headers=headers)
写到这里,或许许多人认为修改User-Agent很简单,也确实是简单,但是正常人1秒看一张图片,而如果是代码爬虫的话1秒就可以抓取好多张图,比如1秒就抓取了一百张图片,那么服务器的压力必然会增大。也就是说如果在一个IP下批量访问下载图片,这个行为不符合正常人类的行为,这个访问IP肯定要被封的。其原理也很简单,就是统计每个IP的访问率,该频率超过了阈值,就会返回一个验证码,如果真的是用户访问的话,用户就会填写,然后继续访问,如果是代码访问的话,就会封IP。
这个问题的解决方案有两个,第一个就是常用的增设延时,每三秒抓取一次,代码如下:
import time
time.sleep(3)
不管如何访问,服务器的目的就是要查出哪些访问是代码访问,然后封IP,解决避免被封IP,在数据采集时经常会使用代理。当然,requests也有相应的proxies属性。首先,构建自己的代理IP池,将其以字典的形式赋值给proxies,然后传输给requests,代码如下:
proxies = {
'http':'http://10.10.1.10:3128',
'https':'http://10.10.1.10:1080'
}
response = requests.get(url,proxies=proxies)
吴裕雄--天生自然PYTHON爬虫:爬虫攻防战的更多相关文章
- 吴裕雄--天生自然PYTHON爬虫:使用Selenium爬取大型电商网站数据
用python爬取动态网页时,普通的requests,urllib2无法实现.例如有些网站点击下一页时,会加载新的内容,但是网页的URL却没有改变(没有传入页码相关的参数),requests.urll ...
- 吴裕雄--天生自然PYTHON爬虫:爬取某一大型电商网站的商品数据(效率优化以及代码容错处理)
这篇博文主要是对我的这篇https://www.cnblogs.com/tszr/p/12198054.html爬虫效率的优化,目的是为了提高爬虫效率. 可以根据出发地同时调用多个CPU,每个CPU运 ...
- 吴裕雄--天生自然PYTHON爬虫:使用Scrapy抓取股票行情
Scrapy框架它能够帮助提升爬虫的效率,从而更好地实现爬虫.Scrapy是一个为了抓取网页数据.提取结构性数据而编写的应用框架,该框架是封装的,包含request异步调度和处理.下载器(多线程的Do ...
- 吴裕雄--天生自然python学习笔记:编写网络爬虫代码获取指定网站的图片
我们经常会在网上搜索井下载图片,然而一张一张地下载就太麻烦了,本案例 就是通过网络爬虫技术, 一次性下载该网站所有的图片并保存 . 网站图片下载并保存 将指定网站的 .jpg 和 .png 格式的图片 ...
- 吴裕雄--天生自然python学习笔记:python爬虫PM2.5 实时监测显示器
PM2.5 对人体的健康影响很大,所以空气中的 PM2.5 实时信息受到越来越多的关注. Python 的 Pandas 套件不但可以自动读取网页中的表格 数据 , 还可对数据进行修改.排序等处理,也 ...
- 吴裕雄--天生自然python学习笔记:python爬虫与网页分析
我们所抓取的网页源代码一般都是 HTML 格式的文件,只要研究明白 HTML 中 的标签( Tag )结构,就很容易进行解析并取得所需数据 . HTML 网页结构 HTML 网 页是由许多标签( Ta ...
- 吴裕雄--天生自然PYTHON爬虫:安装配置MongoDBy和爬取天气数据并清洗保存到MongoDB中
1.下载MongoDB 官网下载:https://www.mongodb.com/download-center#community 上面这张图选择第二个按钮 上面这张图直接Next 把bin路径添加 ...
- 吴裕雄--天生自然PYTHON爬虫:用API爬出天气预报信息
天气预报网址:https://id.heweather.com/,这个网站是需要注册获取一个个人认证后台密钥key的,并且每个人都有访问次数的限制,这个key就是访问API的钥匙. 这个key现在是要 ...
- 吴裕雄--天生自然PYTHON爬虫:使用BeautifulSoup解析中国旅游网页数据
import requests from bs4 import BeautifulSoup url = "http://www.cntour.cn/" strhtml = requ ...
随机推荐
- Centos610安装MVN
1.下载mav安装 下载免安装版上传linux cd /opt/maven mkdir repository cd apche-maven-3.3.9/conf vi settings.xml 设置 ...
- Codeforces Round #611 (Div. 3) E
Oh, New Year. The time to gather all your friends and reflect on the heartwarming events of the past ...
- ElasticSearch应用
1.什么是ElasticSearch Elaticsearch,简称为es, es是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储.检索数据:本 身扩展性很好,可以扩展到上百台服务器,处理 ...
- 修改oracle数据库用户密码的方法
WIN+R打开运行窗口,输入cmd进入命令行: 输入sqlplus ,输入用户名,输入口令(如果是超级管理员SYS的话需在口令之后加上as sysdba)进入sql命令行: 连接成功后,输入“s ...
- 基础总结篇之七:ContentProvider之读写短消息
转自:http://blog.csdn.net/wellsoho/article/details/49494167 今天我们来讲一下如何利用ContentProvider读写短消息. 上次我们讲了如何 ...
- 获取 AppStore 中 应用 的 IPA 包文件(Mac OS 13+)
在 Mac OS 12.7 之前,可以通过 iTunes 直接下载 App Store 中应用的 IPA 包,可以提取其他应用的资源图片,查看信息等操作.之后 苹果 公司禁用了这一功能,不能直接通过 ...
- ajax的XmlHttpRequest对象常用方法
onreadystatechange用于检测readyState状态的改变,当readyState的状态发生改变的时候调用回调
- linux压缩包管理
1.gzip 文件 ----> .gz格式的压缩包 2.bzip2 文件 ----> .bz2格式的压缩包 3.tar -- 不使用z/j参数 该命令只能对文件或目录打包 参数: c -- ...
- 「JSOI2010」挖宝藏
「JSOI2010」挖宝藏 传送门 由于题目中说道挖一个位置的前提是挖掉它上面的三个,以此类推可以发现,挖掉一个点就需要挖掉这个点往上的整个倒三角,那么也就会映射到 \(x\) 轴上的一段区间(可以发 ...
- sqllab less-1
1.访问sqllab 的less-1 按提示加入http://10.9.2.81/Less-1/?id=1 2. 后面加入单引号,发生报错http://10.9.2.81/Less-1/?id=1‘ ...