新闻网大数据实时分析可视化系统项目——13、Cloudera HUE大数据可视化分析
1.Hue 概述及版本下载
1)概述
Hue是一个开源的Apache Hadoop UI系统,最早是由Cloudera Desktop演化而来,由Cloudera贡献给开源社区,它是基于Python Web框架Django实现的。通过使用Hue我们可以在浏览器端的Web控制台上与Hadoop集群进行交互来分析处理数据,例如操作HDFS上的数据,运行MapReduce Job等等。
2)下载
CDH版本下载
官网下载
2.编译安装
1)解压
tar -zxf hue-3.9.0-cdh5.5.0.tar.gz -C /opt/modules/
2)安装依赖包
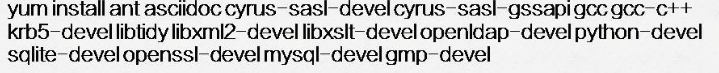
依赖包参考此连接。
3)编译
cd hue-3.9.0-cdh5.5.0
make apps
3.Hue 基本配置与服务启动
1)修改配置文件
cd desktop
cd conf
vi hue.ini
#秘钥
secret_key=jFE93j;2[290-eiw.KEiwN2s3['d;/.q[eIW^y#e=+Iei*@Mn < qW5o
#host port
http_host=bigdata-pro03.kfk.com
http_port=8888
#时区
time_zone=Asia/Shanghai
2)修改desktop.db 文件权限
chmod o+w desktop/desktop.db
3)启动Hue服务
/opt/modules/hue-3.9.0-cdh5.5.0/build/env/bin/supervisor
4)查看Hue web界面
bigdata-pro03.kfk.com:8888
4.Hue与HDFS集成
1)修改core-site.xml配置文件,添加如下内容
<property>
<name>hadoop.proxyuser.hue.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hue.groups</name>
<value>*</value>
</property>
2)修改hue.ini配置文件
fs_defaultfs=hdfs://ns
webhdfs_url=http://bigdata-pro01.kfk.com:50070/webhdfs/v1
hadoop_hdfs_home=/opt/modules/hadoop-2.5.0
hadoop_bin=/opt/modules/hadoop-2.5.0/bin
hadoop_conf_dir=/opt/modules/hadoop-2.5.0/etc/hadoop
3)将core-site.xml配置文件分发到其他节点
scp core-site.xml bigdata-pro02.kfk.com:/opt/modules/hadoop-2.5.0/etc/hadoop
scp core-site.xml bigdata-pro01.kfk.com:/opt/modules/hadoop-2.5.0/etc/hadoop
4)重新启动hue
/opt/modules/hue-3.9.0-cdh5.5.0/build/env/bin/supervisor
5.Hue与YARN集成
1)修改hue.ini配置文件
resourcemanager_host=rs
resourcemanager_port=8032
submit_to=true
resourcemanager_api_url=http://bigdata-pro01.kfk.com:8088
proxy_api_url=http://bigdata-pro01.kfk.com:8088
history_server_api_url=http://bigdata-pro01.kfk.com:19888
2)重新启动hue
/opt/modules/hue-3.9.0-cdh5.5.0/build/env/bin/supervisor
5.Hue与Hive集成
1)修改hue.ini配置文件
hive_server_host=bigdata-pro03.kfk.com
hive_server_port=10000
hive_conf_dir=/opt/modules/hive-0.13.1-bin/conf
2)重新启动hue
/opt/modules/hue-3.9.0-cdh5.5.0/build/env/bin/supervisor
6.Hue与mysql集成
1)修改hue.ini配置文件
nice_name="My SQL DB"
name=metastore
engine=mysql
host=bigdata-pro01.kfk.com
port=3306
user=root
password=123456
2)重新启动hue
/opt/modules/hue-3.9.0-cdh5.5.0/build/env/bin/supervisor
7.Hue与HBase集成
1)修改hue.ini配置文件
hbase_clusters=(Cluster|bigdata-pro01.kfk.com:9090)
hbase_conf_dir=/opt/modules/hbase-0.98.6-cdh5.3.0/conf
2)HBase中启动thrift服务
bin/hbase-daemon.sh start thrift
7.Hue使用注意事项
1)hive 启动使用后台启动
nohup bin/hiveserver2 &
2)hue使用稳定版本:hue-3.7.0-cdh5.3.6
新闻网大数据实时分析可视化系统项目——13、Cloudera HUE大数据可视化分析的更多相关文章
- 新闻网大数据实时分析可视化系统项目——18、Spark SQL快速离线数据分析
1.Spark SQL概述 1)Spark SQL是Spark核心功能的一部分,是在2014年4月份Spark1.0版本时发布的. 2)Spark SQL可以直接运行SQL或者HiveQL语句 3)B ...
- 新闻网大数据实时分析可视化系统项目——8、Flume数据采集准备
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据:同时,Flume提供对数据进行简单处理,并 ...
- 新闻网大数据实时分析可视化系统项目——19、Spark Streaming实时数据分析
1.Spark Streaming功能介绍 1)定义 Spark Streaming is an extension of the core Spark API that enables scalab ...
- 新闻网大数据实时分析可视化系统项目——2、linux环境准备与设置
1.Linux系统常规设置 1)设置ip地址 使用界面修改ip比较方便,如果Linux没有安装操作界面,需要使用命令:vi /etc/sysconfig/network-scripts/ifcfg-e ...
- 新闻网大数据实时分析可视化系统项目——21、大数据Web可视化分析系统开发
1.基于业务需求的WEB系统设计 2.下载Tomcat并创建Web工程并配置相关服务 下载tomcat,解压并启动tomcat服务. 1)新建web app项目 创建好之后的效果 2)对tomcat进 ...
- 新闻网大数据实时分析可视化系统项目——15、基于IDEA环境下的Spark2.X程序开发
1.Windows开发环境配置与安装 下载IDEA并安装,可以百度一下免费文档. 2.IDEA Maven工程创建与配置 1)配置maven 2)新建Project项目 3)选择maven骨架 4)创 ...
- 新闻网大数据实时分析可视化系统项目——12、Hive与HBase集成进行数据分析
(一)Hive 概述 (二)Hive在Hadoop生态圈中的位置 (三)Hive 架构设计 (四)Hive 的优点及应用场景 (五)Hive 的下载和安装部署 1.Hive 下载 Apache版本的H ...
- 新闻网大数据实时分析可视化系统项目——7、Kafka分布式集群部署
Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用.目前越来越多的开源分布式处理系统如Cloudera.Apache Storm.Spa ...
- 新闻网大数据实时分析可视化系统项目——4、Zookeeper分布式集群部署
ZooKeeper 是一个针对大型分布式系统的可靠协调系统:它提供的功能包括:配置维护.名字服务.分布式同步.组服务等: 它的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效.功能稳定的 ...
随机推荐
- 带你了解MyBatis一二级缓存
在对数据库进行噼里啪啦的查询时,可能存在多次使用相同的SQL语句去查询数据库,并且结果可能还一样,这时,如果不采取一些措施,每次都从数据库查询,会造成一定资源的浪费,所以Mybatis中提供了一级缓存 ...
- 忘记SYS密码
进入控制台录入 sqlplus /nolog; connect / as sysdba alter user sys identified by ; alter user system ident ...
- PHP的isset(),is_null,empty()你了解了没?
这几个变量判断函数在PHP开发中用的其实挺多的,而且粗看上去都差不多,但其实还是有不少的区别的,如果搞不清楚,也许就会遗留一些潜在的bug, 包括我自已也遇到过这样的坑,比如有一次我就遇到过用empt ...
- 6.Python字符串
#header { display: none !important; } } #header-spacer { width: 100%; visibility: hidden; } @media p ...
- map或者对象转换
map或者对象转换为具有相同字段的对象 List<Example> errorCodeExcelBeanList = JSONObject.parseArray(((JSONObject) ...
- "%Error opening tftp://255.255.255.255/network config"
问题:服务配置错误消息(Service Configuration Error Messages) 有时,在通过Cisco IOS软件启动Cisco设备期间,会显示与这些类似的错误消息: %Error ...
- Linux终端的一些快捷键命令
一.初识linux的终端种类:本地.远程 查看本终端命令: #tty 命令,看到当前所处的终端 #(w)who 命令,看到系统中所有登录的用户 其中,tty 终端为表示在本地命令行模式下打开的终端:p ...
- maven设置jdk版本
方法一:在maven文件夹下的settings.xml中添加 <profile> <id>jdk-1.8</id> <activation> <a ...
- 2.9 logistic回归中的梯度下降法(非常重要,一定要重点理解)
怎么样计算偏导数来实现logistic回归的梯度下降法 它的核心关键点是其中的几个重要公式用来实现logistic回归的梯度下降法 接下来开始学习logistic回归的梯度下降法 logistic回归 ...
- selenium webdriver 操作RadioButton
@Test public void testRadio() { WebDriver driver = ExplorerBase.IESetting(); try { Thread.sleep(500) ...