MySQL常见面试题索引、表设计
正确使用索引的条件
1.建立索引的列的重复度不能太高
2.条件列不能参与计算
3.不能使用函数
4.条件中不能使用范围
5.不要使用like '%c'
6.条件中用or
a=0 or b=1 or c=2 or d=4 只要其中一列没有索引就无法命中
7.最左前缀(a,b,c,d) 只适用于and条件的列,如果出现范围,从出现范围的字段开始就失效,必须带着最左侧的列
只要不带a就无法命中索引
a = 1 or b = 2 无法命中索引
a = 1 and b>100 a可以命中索引 b,c,d无法命中
a>200 无法命中索引 因为联合索引一旦使用范围,从使用范围开始之后的索引都不生效
1
索引概念、索引模型
Q:你们每天这么大的数据量,都是保存在关系型数据库中吗?
A:是的,我们线上使用的是MySQL数据库
Q:每天几百万数据,一个月就是几千万了,那你们有没有对于查询做一些优化呢?
A:我们在数据库中创建了一些索引(我现在非常后悔我当时说了这句话)
Q:那你能说说什么是索引吗?
A:索引其实是一种数据结构,能够帮助我们快速的检索数据库中的数据
Q:那么索引具体采用的哪种数据结构呢?
A:常见的MySQL主要有两种结构:Hash索引和B+ Tree索引,我们使用的是InnoDB引擎,默认的是B+树
Q:既然你提到InnoDB使用的B+ 树的索引模型,那么你知道为什么采用B+ 树吗?这和Hash索引比较起来有什么优缺点吗?
A:因为Hash索引底层是哈希表,哈希表是一种以key-value存储数据的结构,所以多个数据在存储关系上是完全没有任何顺序关系的,所以,对于区间查询是无法直接通过索引查询的,就需要全表扫描。所以,哈希索引只适用于等值查询的场景。而B+ 树是一种多路平衡查询树,所以他的节点是天然有序的(左子节点小于父节点、父节点小于右子节点),所以对于范围查询的时候不需要做全表扫描
Q:除了上面这个范围查询的,你还能说出其他的一些区别吗?
A:
B+Tree索引和Hash索引区别?
哈希索引适合等值查询,但是无法进行范围查询
哈希索引没办法利用索引完成排序
哈希索引不支持多列联合索引的最左匹配规则
如果有大量重复键值的情况下,哈希索引的效率会很低,因为存在哈希碰撞问题
2
聚簇索引、覆盖索引
Q:刚刚我们聊到B+ Tree ,那你知道B+ Tree的叶子节点都可以存哪些东西吗?
A:InnoDB的B+ Tree可能存储的是整行数据,也有可能是主键的值
Q:那这两者有什么区别吗?
A:在 InnoDB 里,索引B+ Tree的叶子节点存储了整行数据的是主键索引,也被称之为聚簇索引。而索引B+ Tree的叶子节点存储了主键的值的是非主键索引,也被称之为非聚簇索引
Q:那么,聚簇索引和非聚簇索引,在查询数据的时候有区别吗?
A:聚簇索引查询会更快?
Q:为什么呢?
A:因为主键索引树的叶子节点直接就是我们要查询的整行数据了。而非主键索引的叶子节点是主键的值,查到主键的值以后,还需要再通过主键的值再进行一次查询
Q:刚刚你提到主键索引查询只会查一次,而非主键索引需要回表查询多次。是所有情况都是这样的吗?非主键索引一定会查询多次吗?
A:通过覆盖索引也可以只查询一次。覆盖索引(covering index)指一个查询语句的执行只用从索引中就能够取得,不必从数据表中读取。也可以称之为实现了索引覆盖。
当一条查询语句符合覆盖索引条件时,MySQL只需要通过索引就可以返回查询所需要的数据,这样避免了查到索引后再返回表操作,减少I/O提高效率。如,表covering_index_sample中有一个普通索引 idx_key1_key2(key1,key2)。当我们通过SQL语句:select key2 from covering_index_sample where key1 = 'keytest';的时候,就可以通过覆盖索引查询,无需回表。
3
联合索引、最左前缀匹配
Q:不知道的话没关系,想问一下,你们在创建索引的时候都会考虑哪些因素呢?
A:我们一般对于查询概率比较高,经常作为where条件的字段设置索引
Q: 那你们有用过联合索引吗?
A:用过呀,我们有对一些表中创建过联合索引
Q:那你们在创建联合索引的时候,需要做联合索引多个字段之间顺序你们是如何选择的呢?
A:我们把识别度最高的字段放到最前面
Q:为什么这么做呢?
A:这样的话可能命中率会高一点吧。。。
Q: 那你知道最左前缀匹配吗?
A:在创建多列索引时,我们根据业务需求,where子句中使用最频繁的一列放在最左边,因为MySQL索引查询会遵循最左前缀匹配的原则,即最左优先,在检索数据时从联合索引的最左边开始匹配。所以当我们创建一个联合索引的时候,如(key1,key2,key3),相当于创建了(key1)、(key1,key2)和(key1,key2,key3)三个索引,这就是最左匹配原则
4
索引下推、查询优化
Q:你们线上用的MySQL是哪个版本啊呢?
A:我们MySQL是5.7
Q:那你知道在MySQL 5.6中,对索引做了哪些优化吗?
A:Index Condition Pushdown(索引下推)
MySQL 5.6引入了索引下推优化,默认开启,使用SET optimizer_switch = 'index_condition_pushdown=off';可以将其关闭。官方文档中给的例子和解释如下:
people表中(zipcode,lastname,firstname)构成一个索引
SELECT * FROM people WHERE zipcode='95054' AND lastname LIKE '%etrunia%' AND address LIKE '%Main Street%';
如果没有使用索引下推技术,则MySQL会通过zipcode='95054'从存储引擎中查询对应的数据,返回到MySQL服务端,然后MySQL服务端基于lastname LIKE '%etrunia%'和address LIKE '%Main Street%'来判断数据是否符合条件。
如果使用了索引下推技术,则MYSQL首先会返回符合zipcode='95054'的索引,然后根据lastname LIKE '%etrunia%'和address LIKE '%Main Street%'来判断索引是否符合条件。如果符合条件,则根据该索引来定位对应的数据,如果不符合,则直接reject掉。有了索引下推优化,可以在有like条件查询的情况下,减少回表次数。
Q:你们创建的那么多索引,到底有没有生效,或者说你们的SQL语句有没有使用索引查询你们有统计过吗?
A:这个还没有统计过,除非遇到慢SQL的时候我们才会去排查
Q:那排查的时候,有什么手段可以知道有没有走索引查询呢?
A:可以通过explain查看sql语句的执行计划,通过执行计划来分析索引使用情况
Q:那什么情况下会发生明明创建了索引,但是执行的时候并没有通过索引呢?
A:查询优化器?
一条SQL语句的查询,可以有不同的执行方案,至于最终选择哪种方案,需要通过优化器进行选择,选择执行成本最低的方案。
在一条单表查询语句真正执行之前,MySQL的查询优化器会找出执行该语句所有可能使用的方案,对比之后找出成本最低的方案。
这个成本最低的方案就是所谓的执行计划。优化过程大致如下:
1、根据搜索条件,找出所有可能使用的索引
2、计算全表扫描的代价
3、计算使用不同索引执行查询的代价
4、对比各种执行方案的代价,找出成本最低的那一个
问题1:为什么一定要设一个主键?
回答:因为你不设主键的情况下,innodb也会帮你生成一个隐藏列,作为自增主键。所以啦,反正都要生成一个主键,那你还不如自己指定一个主键,在有些情况下,就能显式的用上主键索引,提高查询效率!
问题2:主键是用自增还是UUID?
回答:肯定答自增啊。innodb 中的主键是聚簇索引。如果主键是自增的,那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置,当一页写满,就会自动开辟一个新的页。如果不是自增主键,那么可能会在中间插入,就会引发页的分裂,产生很多表碎片!。
上面那句话看不懂没事,大白话一句就是:用自增插入性能好!
另外,附一个测试表给你们,表名带uuid的就是用uuid作为主键。大家看一下就知道性能差距了:
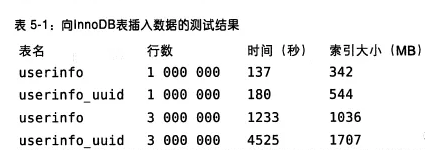
如上图所示,当主键是UUID的时候,插入时间更长,而且占用空间更大!
额,大家千万不要忘了,当你回答自增主键后,想一下《自增主键用完该怎么办?》
ps:这个问题,你要是能把UUID讲出合理的理由也行。
问题3:主键为什么不推荐有业务含义?
回答:有如下两个原因
(1)因为任何有业务含义的列都有改变的可能性,主键一旦带上了业务含义,那么主键就有可能发生变更。主键一旦发生变更,该数据在磁盘上的存储位置就会发生变更,有可能会引发页分裂,产生空间碎片。
(2)带有业务含义的主键,不一定是顺序自增的。那么就会导致数据的插入顺序,并不能保证后面插入数据的主键一定比前面的数据大。如果出现了,后面插入数据的主键比前面的小,就有可能引发页分裂,产生空间碎片。
问题4:表示枚举的字段为什么不用enum类型?
回答:在工作中表示枚举的字段,一般用tinyint类型。
那为什么不用enum类型呢?下面两个原因
(1)ENUM类型的ORDER BY操作效率低,需要额外操作
(2)如果枚举值是数值,有陷阱
举个例子,表结构如下
CREATE TABLE test (foobar ENUM('0', '1', '2'));
此时,你执行语句
mysql> INSERT INTO test VALUES (1);
查询出的结果为
| foobar |
|---|
| 0 |
就产生了一个坑爹的结果。
插入语句应该像下面这么写,插入的才是1
mysql> INSERT INTO test VALUES (`1`);
问题5:货币字段用什么类型?
回答:如果货币单位是分,可以用Int类型。如果坚持用元,用Decimal。
千万不要答float和double,因为float和double是以二进制存储的,所以有一定的误差。
打个比方,你建一个列如下
CREATE TABLE `t` (
`price` float(10,2) DEFAULT NULL,
) ENGINE=InnoDB DEFAULT CHARSET=utf8
然后insert给price列一个数据为1234567.23,你会发现显示出来的数据变为1234567.25,精度失准!
问题6:时间字段用什么类型?
回答:此题无固定答案,应结合自己项目背景来答!把理由讲清楚就行!
(1)varchar,如果用varchar类型来存时间,优点在于显示直观。但是坑的地方也是挺多的。比如,插入的数据没有校验,你可能某天就发现一条数据为2013111的数据,请问这是代表2013年1月11日,还是2013年11月1日?
其次,做时间比较运算,你需要用STR_TO_DATE等函数将其转化为时间类型,你会发现这么写是无法命中索引的。数据量一大,是个坑!
(2)timestamp,该类型是四个字节的整数,它能表示的时间范围为1970-01-01 08:00:01到2038-01-19 11:14:07。2038年以后的时间,是无法用timestamp类型存储的。
但是它有一个优势,timestamp类型是带有时区信息的。一旦你系统中的时区发生改变,例如你修改了时区
SET TIME_ZONE = "america/new_york";
你会发现,项目中的该字段的值自己会发生变更。这个特性用来做一些国际化大项目,跨时区的应用时,特别注意!
(3)datetime,datetime储存占用8个字节,它存储的时间范围为1000-01-01 00:00:00 ~ 9999-12-31 23:59:59。显然,存储时间范围更大。但是它坑的地方在于,他存储的是时间绝对值,不带有时区信息。如果你改变数据库的时区,该项的值不会自己发生变更!
(4)bigint,也是8个字节,自己维护一个时间戳,表示范围比timestamp大多了,就是要自己维护,不大方便。
问题7:为什么不直接存储图片、音频、视频等大容量内容?
回答:我们在实际应用中,都是用HDFS来存储文件。然后mysql中,只存文件的存放路径。mysql中有两个字段类型被用来设计存放大容量文件,也就是text和blob类型。但是,我们在生产中,基本不用这两个类型!
主要原因有如下两点
(1)Mysql内存临时表不支持TEXT、BLOB这样的大数据类型,如果查询中包含这样的数据,在排序等操作时,就不能使用内存临时表,必须使用磁盘临时表进行。导致查询效率缓慢
(2)
binlog内容太多。因为你数据内容比较大,就会造成binlog内容比较多。大家也知道,主从同步是靠binlog进行同步,binlog太大了,就会导致主从同步效率问题!
因此,不推荐使用text和blob类型!
问题8:字段为什么要定义为NOT NULL?
回答:OK,这问题从两个角度来答
(1)索引性能不好
Mysql难以优化引用可空列查询,它会使索引、索引统计和值更加复杂。可空列需要更多的存储空间,还需要mysql内部进行特殊处理。可空列被索引后,每条记录都需要一个额外的字节,还能导致MYisam 中固定大小的索引变成可变大小的索引。 —— 出自《高性能mysql第二版》
(2)查询会出现一些不可预料的结果
这里举一个例子,大家就懂了。假设,表结构如下
create table table_2 (
`id` INT (11) NOT NULL,
name varchar(20) NOT NULL
)
表数据是这样的
| id | name |
|---|---|
| 1 | 孤独烟 |
| 3 | null |
| 5 | 肥朝 |
| 7 | null |
你执行语句
select count(name) from table_2;
你会发现结果为2,但是实际上是有四条数据的!类似的查询问题,其实有很多,不一一列举。
记住,因为null列的存在,会出现很多出人意料的结果,从而浪费开发时间去排查Bug.
MySQL常见面试题索引、表设计的更多相关文章
- 100道MySQL常见面试题总结,看完直接收藏
前言 本文主要受众为开发人员,所以不涉及到MySQL的服务部署等操作,且内容较多,大家准备好耐心和瓜子矿泉水. 前一阵系统的学习了一下MySQL,也有一些实际操作经验,偶然看到一篇和MySQL相关的面 ...
- 100道MySQL常见面试题总结
原文链接:https://juejin.im/post/5d351303f265da1bd30596f9 前言 本文主要受众为开发人员,所以不涉及到MySQL的服务部署等操作,且内容较多,大家准备好耐 ...
- mysql 常见面试题
附录: https://mp.weixin.qq.com/s/pC0_Y7M7BkoUmlRwneZZdA 一.为什么用自增列作为主键 1.如果我们定义了主键(PRIMARY KEY),那么InnoD ...
- MySQL常见面试题
1. 主键 超键 候选键 外键 主 键: 数据库表中对储存数据对象予以唯一和完整标识的数据列或属性的组合.一个数据列只能有一个主键,且主键的取值不能缺失,即不能为空值(Null). 超 键: 在关系中 ...
- 【重要】MySQL常见面试题
1. 主键 超键 候选键 外键 主 键: 数据库表中对储存数据对象予以唯一和完整标识的数据列或属性的组合.一个数据列只能有一个主键,且主键的取值不能缺失,即不能为空值(Null). 超 键: 在关系中 ...
- 整理的最全 python常见面试题(基本必考)
整理的最全 python常见面试题(基本必考) python 2018-05-17 作者 大蛇王 1.大数据的文件读取 ① 利用生成器generator ②迭代器进行迭代遍历:for line in ...
- 整理的最全 python常见面试题
整理的最全 python常见面试题(基本必考)① ②③④⑤⑥⑦⑧⑨⑩ 1.大数据的文件读取: ① 利用生成器generator: ②迭代器进行迭代遍历:for line in file; 2.迭代 ...
- iOS常见面试题汇总
iOS常见面试题汇总 1. 什么是 ARC? (ARC 是为了解决什么问题而诞生的?) ARC 是 Automatic Reference Counting 的缩写, 即自动引用计数. 这是苹果在 i ...
- Mybatis常见面试题
Mybatis常见面试题 #{}和${}的区别是什么? #{}和${}的区别是什么? 在Mybatis中,有两种占位符 #{}解析传递进来的参数数据 ${}对传递进来的参数原样拼接在SQL中 #{}是 ...
随机推荐
- opencv-6-图像绘制与opencv Line 函数剖析
opencv-6-图像绘制与opencv Line 函数剖析 opencvc++qt 开始之前 越到后面, 写的越慢, 之前还抽空去看了下 学堂在线那篇文章提供的方法, 博客第一个人评论的我, 想想还 ...
- 13个Python图形库
By Django中国社区 at 2013-04-27 07:49 Python的13大图形库,matplotlib功能最强大,Cairoplot最漂亮,django-chartit与Django集成 ...
- python的sqlalchemy框架
先看一下sqlalchemy框架中的映射,sqlalchemy一共有三种映射方式:传统映射(classic).现代化映射(modern).自定义映射.在这里,只为大家讲一下classic映射和mode ...
- 编写C#程序的IDE
编写C#程序,在Windows平台下,除了昂贵的Visual Studio.NET这个正宗的工具外,你还了解哪些? 听说有个Eclipse,IBM投钱开发的开源工具,有人也做了个for .NET的pl ...
- HDU Problem D [ Humble number ]——基础DP丑数序列
Problem D Time Limit : 2000/1000ms (Java/Other) Memory Limit : 65536/32768K (Java/Other) Total Submi ...
- RF(作用与目的)
1.robotframework 自动化原理 通过 ride 工具编写脚本,加载指定的 UI 测试库,再通过 pybot 程序去运行指定脚本,调用浏览器驱动,打开浏览器,操作浏览器页面元素,达到模拟用 ...
- libevent(五)event
libevent使用struct event来表示一个事件. #define evutil_socket_t int #define ev_uint8_t unsigned char #define ...
- IoTClient开发6 - S7-200SmarTcp协议客户端实现
环境和工具 服务端电脑IP:192.168.1.130 客户端电脑IP:192.168.1.120 1.在服务端电脑运行IoTClientTool 2.运行Wireshark 3.在客户端电脑运行Io ...
- thinkphp历史漏洞
https://github.com/pochubs/pochubs/blob/master/ThinkPHP.md tp 历史漏洞 路由控制類RCE/think/App.php if (!preg_ ...
- 李婷华 201771010113 《面向对象程序设计(java)》 第三周学习总结
第一部分:理论知识回顾 第一章 再次了解了java“白皮书”的关键术语,java的常见术语,对于“白皮书”的关键术语依然环游不太理解的. 第二章 在使用命令行工具运行java程序的过程中,依然会有环境 ...