Hadoop基准测试(一)
测试对于验证系统的正确性、分析系统的性能来说非常重要,但往往容易被我们所忽视。为了能对系统有更全面的了解、能找到系统的瓶颈所在、能对系统性能做更好的改进,打算先从测试入手,学习Hadoop主要的测试手段。
TestDFSIO
TestDFSIO用于测试HDFS的IO性能,使用一个MapReduce作业来并发地执行读写操作,每个map任务用于读或写每个文件,map的输出用于收集与处理文件相关的统计信息,reduce用于累积统计信息,并产生summary。
NameNode的地址为:10.*.*.131:7180
输入命令 hadoop version,提示hadoop jar包所在路径
进入jar包所在路径,输入命令 hadoop jar hadoop-test-2.6.0-mr1-cdh5.16.1.jar,返回如下信息:
An example program must be given as the first argument. Valid program names are: DFSCIOTest: Distributed i/o benchmark of libhdfs. DistributedFSCheck: Distributed checkup of the file system consistency. MRReliabilityTest: A program that tests the reliability of the MR framework by injecting faults/failures TestDFSIO: Distributed i/o benchmark. dfsthroughput: measure hdfs throughput filebench: Benchmark SequenceFile(Input|Output)Format (block,record compressed and uncompressed), Text(Input|Output)Format (compressed and uncompressed) loadgen: Generic map/reduce load generator mapredtest: A map/reduce test check. minicluster: Single process HDFS and MR cluster. mrbench: A map/reduce benchmark that can create many small jobs nnbench: A benchmark that stresses the namenode. testarrayfile: A test for flat files of binary key/value pairs. testbigmapoutput: A map/reduce program that works on a very big non-splittable file and does identity map/reduce testfilesystem: A test for FileSystem read/write. testmapredsort: A map/reduce program that validates the map-reduce framework's sort. testrpc: A test for rpc. testsequencefile: A test for flat files of binary key value pairs. testsequencefileinputformat: A test for sequence file input format. testsetfile: A test for flat files of binary key/value pairs. testtextinputformat: A test for text input format. threadedmapbench: A map/reduce benchmark that compares the performance of maps with multiple spills over maps with spill
输入并执行命令 hadoop jar hadoop-test-2.6.0-mr1-cdh5.16.1.jar TestDFSIO -write -nrFiles 10 -fileSize 1000
返回如下信息:
// :: INFO fs.TestDFSIO: TestDFSIO.1.7 // :: INFO fs.TestDFSIO: nrFiles = // :: INFO fs.TestDFSIO: nrBytes (MB) = 1000.0 // :: INFO fs.TestDFSIO: bufferSize = // :: INFO fs.TestDFSIO: baseDir = /benchmarks/TestDFSIO // :: INFO fs.TestDFSIO: creating control bytes, files java.io.IOException: Permission denied: user=root, access=WRITE, inode="/":hdfs:supergroup:drwxr-xr-x
报错! java.io.IOException: Permission denied: user=root, access=WRITE, inode="/":hdfs:supergroup:drwxr-xr-x
执行命令 su hdfs 切换用户为 hdfs
输入并执行命令 hadoop jar hadoop-test-2.6.0-mr1-cdh5.16.1.jar TestDFSIO -write -nrFiles 10 -fileSize 1000
返回如下信息:
bash--mr1-cdh5. -fileSize
// :: INFO fs.TestDFSIO: TestDFSIO.1.7
// :: INFO fs.TestDFSIO: nrFiles =
// :: INFO fs.TestDFSIO: nrBytes (MB) = 1000.0
// :: INFO fs.TestDFSIO: bufferSize =
// :: INFO fs.TestDFSIO: baseDir = /benchmarks/TestDFSIO
// :: INFO fs.TestDFSIO: creating control bytes, files
// :: INFO fs.TestDFSIO: created control files files
// :: INFO client.RMProxy: Connecting to ResourceManager at node1/
// :: INFO client.RMProxy: Connecting to ResourceManager at node1/
// :: INFO mapred.FileInputFormat: Total input paths to process :
// :: INFO mapreduce.JobSubmitter: number of splits:
// :: INFO Configuration.deprecation: io.bytes.per.checksum is deprecated. Instead, use dfs.bytes-per-checksum
// :: INFO Configuration.deprecation: dfs.https.address is deprecated. Instead, use dfs.namenode.https-address
// :: INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1552358721447_0002
// :: INFO impl.YarnClientImpl: Submitted application application_1552358721447_0002
// :: INFO mapreduce.Job: The url to track the job: http://node1:8088/proxy/application_1552358721447_0002/
// :: INFO mapreduce.Job: Running job: job_1552358721447_0002
// :: INFO mapreduce.Job: Job job_1552358721447_0002 running in uber mode : false
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: Job job_1552358721447_0002 completed successfully
// :: INFO mapreduce.Job: Counters:
File System Counters
FILE: Number of bytes read=
FILE: Number of bytes written=
FILE: Number of read operations=
FILE: Number of large read operations=
FILE: Number of
HDFS: Number of bytes read=
HDFS: Number of bytes written=
HDFS: Number of read operations=
HDFS: Number of large read operations=
HDFS: Number of
Job Counters
Launched map tasks=
Launched reduce tasks=
Data-local map tasks=
Total
Total
Total
Total
Total vcore-milliseconds taken by all map tasks=
Total vcore-milliseconds taken by all reduce tasks=
Total megabyte-milliseconds taken by all map tasks=
Total megabyte-milliseconds taken by all reduce tasks=
Map-Reduce Framework
Map input records=
Map output records=
Map output bytes=
Map output materialized bytes=
Input
Combine input records=
Combine output records=
Reduce input
Reduce shuffle bytes=
Reduce input records=
Reduce output records=
Spilled Records=
Shuffled Maps =
Failed Shuffles=
Merged Map outputs=
GC
CPU
Physical memory (bytes) snapshot=
Virtual memory (bytes) snapshot=
Total committed heap usage (bytes)=
Shuffle Errors
BAD_ID=
CONNECTION=
IO_ERROR=
WRONG_LENGTH=
WRONG_MAP=
WRONG_REDUCE=
File Input Format Counters
Bytes Read=
File Output Format Counters
Bytes Written=
java.io.FileNotFoundException: TestDFSIO_results.log (Permission denied)
报错! java.io.FileNotFoundException: TestDFSIO_results.log (Permission denied)
这是由于用户hdfs对当前所在文件夹没有足够的访问权限,参考: https://blog.csdn.net/qq_15547319/article/details/53543587 中的评论
解决:新建文件夹 ** (命令:mkdir **),并授予用户hdfs对文件夹**的访问权限(命令:sudo chmod -R 777 **),进入文件夹**,执行命令 hadoop jar ../jars/hadoop-test-2.6.0-mr1-cdh5.16.1.jar TestDFSIO -write -nrFiles 10 -fileSize 1000 ,返回如下信息:
bash--mr1-cdh5. -fileSize
// :: INFO fs.TestDFSIO: TestDFSIO.1.7
// :: INFO fs.TestDFSIO: nrFiles =
// :: INFO fs.TestDFSIO: nrBytes (MB) = 1000.0
// :: INFO fs.TestDFSIO: bufferSize =
// :: INFO fs.TestDFSIO: baseDir = /benchmarks/TestDFSIO
// :: INFO fs.TestDFSIO: creating control bytes, files
// :: INFO fs.TestDFSIO: created control files files
// :: INFO client.RMProxy: Connecting to ResourceManager at node1/
// :: INFO client.RMProxy: Connecting to ResourceManager at node1/
// :: INFO mapred.FileInputFormat: Total input paths to process :
// :: INFO mapreduce.JobSubmitter: number of splits:
// :: INFO Configuration.deprecation: io.bytes.per.checksum is deprecated. Instead, use dfs.bytes-per-checksum
// :: INFO Configuration.deprecation: dfs.https.address is deprecated. Instead, use dfs.namenode.https-address
// :: INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1552358721447_0006
// :: INFO impl.YarnClientImpl: Submitted application application_1552358721447_0006
// :: INFO mapreduce.Job: The url to track the job: http://node1:8088/proxy/application_1552358721447_0006/
// :: INFO mapreduce.Job: Running job: job_1552358721447_0006
// :: INFO mapreduce.Job: Job job_1552358721447_0006 running in uber mode : false
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: Job job_1552358721447_0006 completed successfully
// :: INFO mapreduce.Job: Counters:
File System Counters
FILE: Number of bytes read=
FILE: Number of bytes written=
FILE: Number of read operations=
FILE: Number of large read operations=
FILE: Number of
HDFS: Number of bytes read=
HDFS: Number of bytes written=
HDFS: Number of read operations=
HDFS: Number of large read operations=
HDFS: Number of
Job Counters
Launched map tasks=
Launched reduce tasks=
Data-local map tasks=
Total
Total
Total
Total
Total vcore-milliseconds taken by all map tasks=
Total vcore-milliseconds taken by all reduce tasks=
Total megabyte-milliseconds taken by all map tasks=
Total megabyte-milliseconds taken by all reduce tasks=
Map-Reduce Framework
Map input records=
Map output records=
Map output bytes=
Map output materialized bytes=
Input
Combine input records=
Combine output records=
Reduce input
Reduce shuffle bytes=
Reduce input records=
Reduce output records=
Spilled Records=
Shuffled Maps =
Failed Shuffles=
Merged Map outputs=
GC
CPU
Physical memory (bytes) snapshot=
Virtual memory (bytes) snapshot=
Total committed heap usage (bytes)=
Shuffle Errors
BAD_ID=
CONNECTION=
IO_ERROR=
WRONG_LENGTH=
WRONG_MAP=
WRONG_REDUCE=
File Input Format Counters
Bytes Read=
File Output Format Counters
Bytes Written=
// :: INFO fs.TestDFSIO: ----- TestDFSIO ----- : write
// :: INFO fs.TestDFSIO: Date & :: CST
// :: INFO fs.TestDFSIO: Number of files:
// :: INFO fs.TestDFSIO: Total MBytes processed: 10000.0
// :: INFO fs.TestDFSIO: Throughput mb/sec: 114.77630098937172
// :: INFO fs.TestDFSIO: Average IO rate mb/sec: 115.29634094238281
// :: INFO fs.TestDFSIO: IO rate std deviation: 7.880011777295818
// :: INFO fs.TestDFSIO: Test exec time sec: 27.05
// :: INFO fs.TestDFSIO:
bash-4.2$
测试命令正确执行以后会在Hadoop File System中创建文件夹存放生成的测试文件,如下所示:
并生成了一系列小文件:

将小文件下载到本地,查看文件大小为1KB

用Notepad++打开后,查看内容为:

并不是可读的内容
执行命令: hadoop jar ../jars/hadoop-test-2.6.0-mr1-cdh5.16.1.jar TestDFSIO -read -nrFiles 10 -fileSize 1000
返回如下信息:
bash--mr1-cdh5. -fileSize
// :: INFO fs.TestDFSIO: TestDFSIO.1.7
// :: INFO fs.TestDFSIO: nrFiles =
// :: INFO fs.TestDFSIO: nrBytes (MB) = 1000.0
// :: INFO fs.TestDFSIO: bufferSize =
// :: INFO fs.TestDFSIO: baseDir = /benchmarks/TestDFSIO
// :: INFO fs.TestDFSIO: creating control bytes, files
// :: INFO fs.TestDFSIO: created control files files
// :: INFO client.RMProxy: Connecting to ResourceManager at node1/
// :: INFO client.RMProxy: Connecting to ResourceManager at node1/
// :: INFO mapred.FileInputFormat: Total input paths to process :
// :: INFO mapreduce.JobSubmitter: number of splits:
// :: INFO Configuration.deprecation: io.bytes.per.checksum is deprecated. Instead, use dfs.bytes-per-checksum
// :: INFO Configuration.deprecation: dfs.https.address is deprecated. Instead, use dfs.namenode.https-address
// :: INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1552358721447_0007
// :: INFO impl.YarnClientImpl: Submitted application application_1552358721447_0007
// :: INFO mapreduce.Job: The url to track the job: http://node1:8088/proxy/application_1552358721447_0007/
// :: INFO mapreduce.Job: Running job: job_1552358721447_0007
// :: INFO mapreduce.Job: Job job_1552358721447_0007 running in uber mode : false
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: Job job_1552358721447_0007 completed successfully
// :: INFO mapreduce.Job: Counters:
File System Counters
FILE: Number of bytes read=
FILE: Number of bytes written=
FILE: Number of read operations=
FILE: Number of large read operations=
FILE: Number of
HDFS: Number of bytes read=
HDFS: Number of bytes written=
HDFS: Number of read operations=
HDFS: Number of large read operations=
HDFS: Number of
Job Counters
Launched map tasks=
Launched reduce tasks=
Data-local map tasks=
Total
Total
Total
Total
Total vcore-milliseconds taken by all map tasks=
Total vcore-milliseconds taken by all reduce tasks=
Total megabyte-milliseconds taken by all map tasks=
Total megabyte-milliseconds taken by all reduce tasks=
Map-Reduce Framework
Map input records=
Map output records=
Map output bytes=
Map output materialized bytes=
Input
Combine input records=
Combine output records=
Reduce input
Reduce shuffle bytes=
Reduce input records=
Reduce output records=
Spilled Records=
Shuffled Maps =
Failed Shuffles=
Merged Map outputs=
GC
CPU
Physical memory (bytes) snapshot=
Virtual memory (bytes) snapshot=
Total committed heap usage (bytes)=
Shuffle Errors
BAD_ID=
CONNECTION=
IO_ERROR=
WRONG_LENGTH=
WRONG_MAP=
WRONG_REDUCE=
File Input Format Counters
Bytes Read=
File Output Format Counters
Bytes Written=
// :: INFO fs.TestDFSIO: ----- TestDFSIO ----- : read
// :: INFO fs.TestDFSIO: Date & :: CST
// :: INFO fs.TestDFSIO: Number of files:
// :: INFO fs.TestDFSIO: Total MBytes processed: 10000.0
// :: INFO fs.TestDFSIO: Throughput mb/sec: 897.4243919949744
// :: INFO fs.TestDFSIO: Average IO rate mb/sec: 898.6844482421875
// :: INFO fs.TestDFSIO: IO rate std deviation: 33.68623587810037
// :: INFO fs.TestDFSIO: Test exec time sec: 19.035
// :: INFO fs.TestDFSIO:
bash-4.2$
执行命令: hadoop jar ../jars/hadoop-test-2.6.0-mr1-cdh5.16.1.jar TestDFSIO -clean
返回如下信息:
bash--mr1-cdh5.16.1.jar TestDFSIO -clean // :: INFO fs.TestDFSIO: TestDFSIO.1.7 // :: INFO fs.TestDFSIO: nrFiles = // :: INFO fs.TestDFSIO: nrBytes (MB) = 1.0 // :: INFO fs.TestDFSIO: bufferSize = // :: INFO fs.TestDFSIO: baseDir = /benchmarks/TestDFSIO // :: INFO fs.TestDFSIO: Cleaning up test files bash-4.2$
同时Hadoop File System中删除了TestDFSIO文件夹
nnbench
nnbench用于测试NameNode的负载,它会生成很多与HDFS相关的请求,给NameNode施加较大的压力。这个测试能在HDFS上模拟创建、读取、重命名和删除文件等操作。
nnbench命令的参数说明如下:
NameNode Benchmark 0.4 Usage: nnbench <options> Options: -operation <Available operations are create_write open_read rename delete. This option is mandatory> * NOTE: The open_read, rename and delete operations assume that the files they operate on, are already available. The create_write operation must be run before running the other operations. -maps <number of maps. default is . This is not mandatory> -reduces <number of reduces. default is . This is not mandatory> -startTime < mins. This is not mandatory -blockSize <Block size . This is not mandatory> -bytesToWrite <Bytes to . This is not mandatory> -bytesPerChecksum <Bytes per checksum . This is not mandatory> -numberOfFiles <number of files to create. default is . This is not mandatory> -replicationFactorPerFile <Replication factor . This is not mandatory> -baseDir <base DFS path. default is /becnhmarks/NNBench. This is not mandatory> -readFileAfterOpen <true or false. if true, it reads the file and reports the average time to read. This is valid with the open_read operation. default is false. This is not mandatory> -help: Display the help statement
为了使用12个mapper和6个reducer来创建1000个文件,执行命令: hadoop jar ../jars/hadoop-test-2.6.0-mr1-cdh5.16.1.jar nnbench -operation create_write -maps 12 -reduces 6 -blockSize 1 -bytesToWrite 0 -numberOfFiles 1000 -replicationFactorPerFile 3 -readFileAfterOpen true -baseDir /benchmarks/NNBench
返回如下信息:
bash--mr1-cdh5. -reduces -blockSize -bytesToWrite -numberOfFiles -replicationFactorPerFile hadoop jar ../jars/hadoop-test--mr1-cdh5. -reduces -blockSize -bytesToWrite -numberOfFiles -replicationFactorPerFile -readFileAfterOpen true -baseDir /benchmarks/NNBench
NameNode Benchmark 0.4
// :: INFO hdfs.NNBench: Test Inputs:
// :: INFO hdfs.NNBench: Test Operation: create_write
// :: INFO hdfs.NNBench: Start -- ::,
// :: INFO hdfs.NNBench: Number of maps:
// :: INFO hdfs.NNBench: Number of reduces:
// :: INFO hdfs.NNBench: Block Size:
// :: INFO hdfs.NNBench: Bytes to
// :: INFO hdfs.NNBench: Bytes per checksum:
// :: INFO hdfs.NNBench: Number of files:
// :: INFO hdfs.NNBench: Replication factor:
// :: INFO hdfs.NNBench: Base dir: /benchmarks/NNBench
// :: INFO hdfs.NNBench: Read file after open: true
// :: INFO hdfs.NNBench: Deleting data directory
// :: INFO hdfs.NNBench: Creating control files
// :: INFO Configuration.deprecation: io.bytes.per.checksum is deprecated. Instead, use dfs.bytes-per-checksum
// :: INFO client.RMProxy: Connecting to ResourceManager at node1/
// :: INFO client.RMProxy: Connecting to ResourceManager at node1/
// :: WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
// :: INFO mapred.FileInputFormat: Total input paths to process :
// :: INFO mapreduce.JobSubmitter: number of splits:
// :: INFO Configuration.deprecation: io.bytes.per.checksum is deprecated. Instead, use dfs.bytes-per-checksum
// :: INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1552358721447_0009
// :: INFO impl.YarnClientImpl: Submitted application application_1552358721447_0009
// :: INFO mapreduce.Job: The url to track the job: http://node1:8088/proxy/application_1552358721447_0009/
// :: INFO mapreduce.Job: Running job: job_1552358721447_0009
// :: INFO mapreduce.Job: Job job_1552358721447_0009 running in uber mode : false
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: Job job_1552358721447_0009 completed successfully
// :: INFO mapreduce.Job: Counters:
File System Counters
FILE: Number of bytes read=
FILE: Number of bytes written=
FILE: Number of read operations=
FILE: Number of large read operations=
FILE: Number of
HDFS: Number of bytes read=
HDFS: Number of bytes written=
HDFS: Number of read operations=
HDFS: Number of large read operations=
HDFS: Number of
Job Counters
Launched map tasks=
Launched reduce tasks=
Data-local map tasks=
Total
Total
Total
Total
Total vcore-milliseconds taken by all map tasks=
Total vcore-milliseconds taken by all reduce tasks=
Total megabyte-milliseconds taken by all map tasks=
Total megabyte-milliseconds taken by all reduce tasks=
Map-Reduce Framework
Map input records=
Map output records=
Map output bytes=
Map output materialized bytes=
Input
Combine input records=
Combine output records=
Reduce input
Reduce shuffle bytes=
Reduce input records=
Reduce output records=
Spilled Records=
Shuffled Maps =
Failed Shuffles=
Merged Map outputs=
GC
CPU
Physical memory (bytes) snapshot=
Virtual memory (bytes) snapshot=
Total committed heap usage (bytes)=
Shuffle Errors
BAD_ID=
CONNECTION=
IO_ERROR=
WRONG_LENGTH=
WRONG_MAP=
WRONG_REDUCE=
File Input Format Counters
Bytes Read=
File Output Format Counters
Bytes Written=
// :: INFO hdfs.NNBench: -------------- NNBench -------------- :
// :: INFO hdfs.NNBench: Version: NameNode Benchmark 0.4
// :: INFO hdfs.NNBench: Date & -- ::,
// :: INFO hdfs.NNBench:
// :: INFO hdfs.NNBench: Test Operation: create_write
// :: INFO hdfs.NNBench: Start -- ::,
// :: INFO hdfs.NNBench: Maps to run:
// :: INFO hdfs.NNBench: Reduces to run:
// :: INFO hdfs.NNBench: Block Size (bytes):
// :: INFO hdfs.NNBench: Bytes to
// :: INFO hdfs.NNBench: Bytes per checksum:
// :: INFO hdfs.NNBench: Number of files:
// :: INFO hdfs.NNBench: Replication factor:
// :: INFO hdfs.NNBench: Successful
// :: INFO hdfs.NNBench:
// :: INFO hdfs.NNBench: # maps that missed the barrier:
// :: INFO hdfs.NNBench: # exceptions:
// :: INFO hdfs.NNBench:
// :: INFO hdfs.NNBench: TPS: Create/Write/Close:
// :: INFO hdfs.NNBench: Avg exec time (ms): Create/Write/Close: 0.0
// :: INFO hdfs.NNBench: Avg Lat (ms): Create/Write: NaN
// :: INFO hdfs.NNBench: Avg Lat (ms): Close: NaN
// :: INFO hdfs.NNBench:
// :: INFO hdfs.NNBench: RAW DATA: AL Total #:
// :: INFO hdfs.NNBench: RAW DATA: AL Total #:
// :: INFO hdfs.NNBench: RAW DATA: TPS Total (ms):
// :: INFO hdfs.NNBench: RAW DATA: Longest Map Time (ms): 0.0
// :: INFO hdfs.NNBench: RAW DATA: Late maps:
// :: INFO hdfs.NNBench: RAW DATA: # of exceptions:
// :: INFO hdfs.NNBench:
bash-4.2$
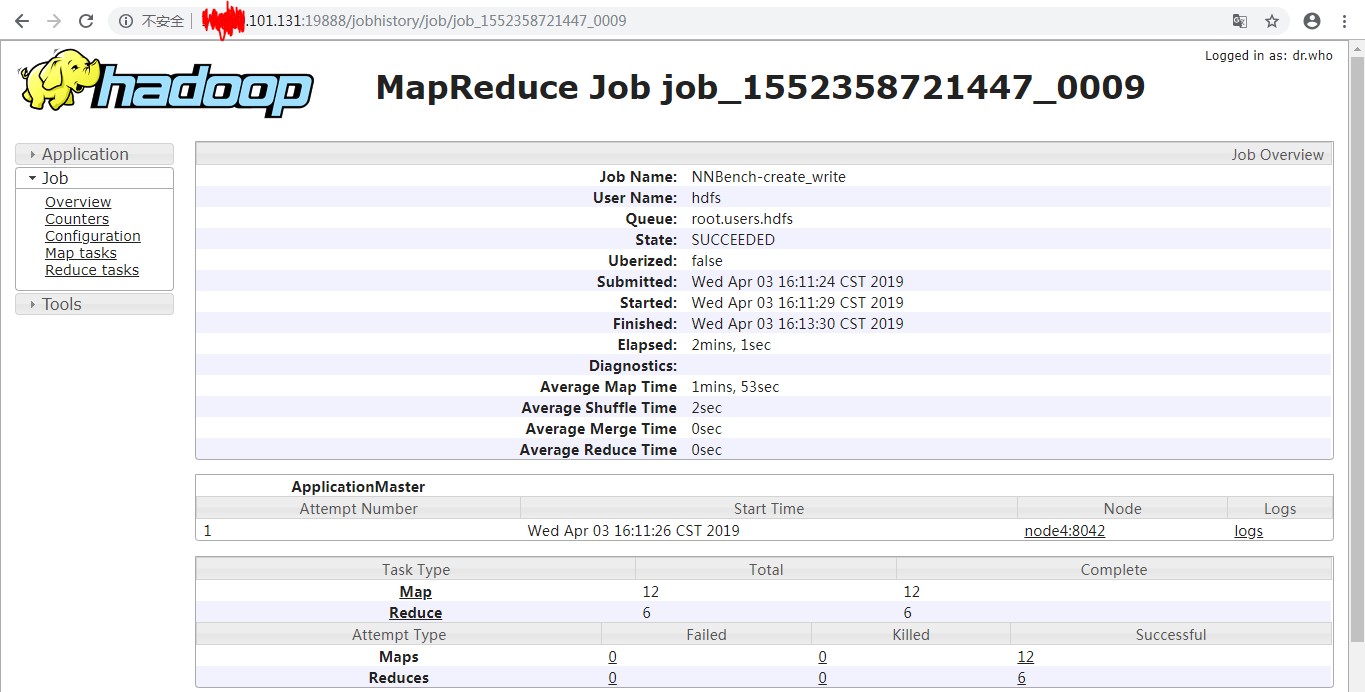
任务执行完以后可以到页面 http://*.*.*.*:19888/jobhistory/job/job_1552358721447_0009 查看任务执行详情,如下:
并且在Hadoop File System中生成文件夹NNBench存储任务产生的文件:
进入目录/benchmarks/NNBench/control,查看某个文件 NNBench_Controlfile_0的元信息,发现文件存在三个节点上:

下载下来用Notepad++打开,发现内容是乱码:

mrbench
mrbench会多次重复执行一个小作业,用于检查在机群上小作业的运行是否可重复以及运行是否高效。mrbench的用法如下:
Usage: mrbench [-baseDir <base DFS path >] [-maps <number of maps >] [-reduces <number of reduces >] [-inputLines <number of input lines to generate, default is >] [-inputType <type of input to generate, one of ascending (default), descending, random>] [-verbose]
执行命令: hadoop jar ../jars/hadoop-test-2.6.0-mr1-cdh5.16.1.jar mrbench -numRuns 50
返回如下信息:
……
Shuffle Errors
BAD_ID=
CONNECTION=
IO_ERROR=
WRONG_LENGTH=
WRONG_MAP=
WRONG_REDUCE=
File Input Format Counters
Bytes Read=
File Output Format Counters
Bytes Written=
// :: INFO mapred.MRBench: Running job : input=hdfs://node1:8020/benchmarks/MRBench/mr_input output=hdfs://node1:8020/benchmarks/MRBench/mr_output/output_299739316
// :: INFO client.RMProxy: Connecting to ResourceManager at node1/
// :: INFO client.RMProxy: Connecting to ResourceManager at node1/
// :: INFO mapred.FileInputFormat: Total input paths to process :
// :: INFO mapreduce.JobSubmitter: number of splits:
// :: INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1552358721447_0059
// :: INFO impl.YarnClientImpl: Submitted application application_1552358721447_0059
// :: INFO mapreduce.Job: The url to track the job: http://node1:8088/proxy/application_1552358721447_0059/
// :: INFO mapreduce.Job: Running job: job_1552358721447_0059
// :: INFO mapreduce.Job: Job job_1552358721447_0059 running in uber mode : false
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: Job job_1552358721447_0059 completed successfully
// :: INFO mapreduce.Job: Counters:
File System Counters
FILE: Number of bytes read=
FILE: Number of bytes written=
FILE: Number of read operations=
FILE: Number of large read operations=
FILE: Number of
HDFS: Number of bytes read=
HDFS: Number of bytes written=
HDFS: Number of read operations=
HDFS: Number of large read operations=
HDFS: Number of
Job Counters
Launched map tasks=
Launched reduce tasks=
Data-local map tasks=
Total
Total
Total
Total
Total vcore-milliseconds taken by all map tasks=
Total vcore-milliseconds taken by all reduce tasks=
Total megabyte-milliseconds taken by all map tasks=
Total megabyte-milliseconds taken by all reduce tasks=
Map-Reduce Framework
Map input records=
Map output records=
Map output bytes=
Map output materialized bytes=
Input
Combine input records=
Combine output records=
Reduce input
Reduce shuffle bytes=
Reduce input records=
Reduce output records=
Spilled Records=
Shuffled Maps =
Failed Shuffles=
Merged Map outputs=
GC
CPU
Physical memory (bytes) snapshot=
Virtual memory (bytes) snapshot=
Total committed heap usage (bytes)=
Shuffle Errors
BAD_ID=
CONNECTION=
IO_ERROR=
WRONG_LENGTH=
WRONG_MAP=
WRONG_REDUCE=
File Input Format Counters
Bytes Read=
File Output Format Counters
Bytes Written=
DataLines Maps Reduces AvgTime (milliseconds)
bash-4.2$
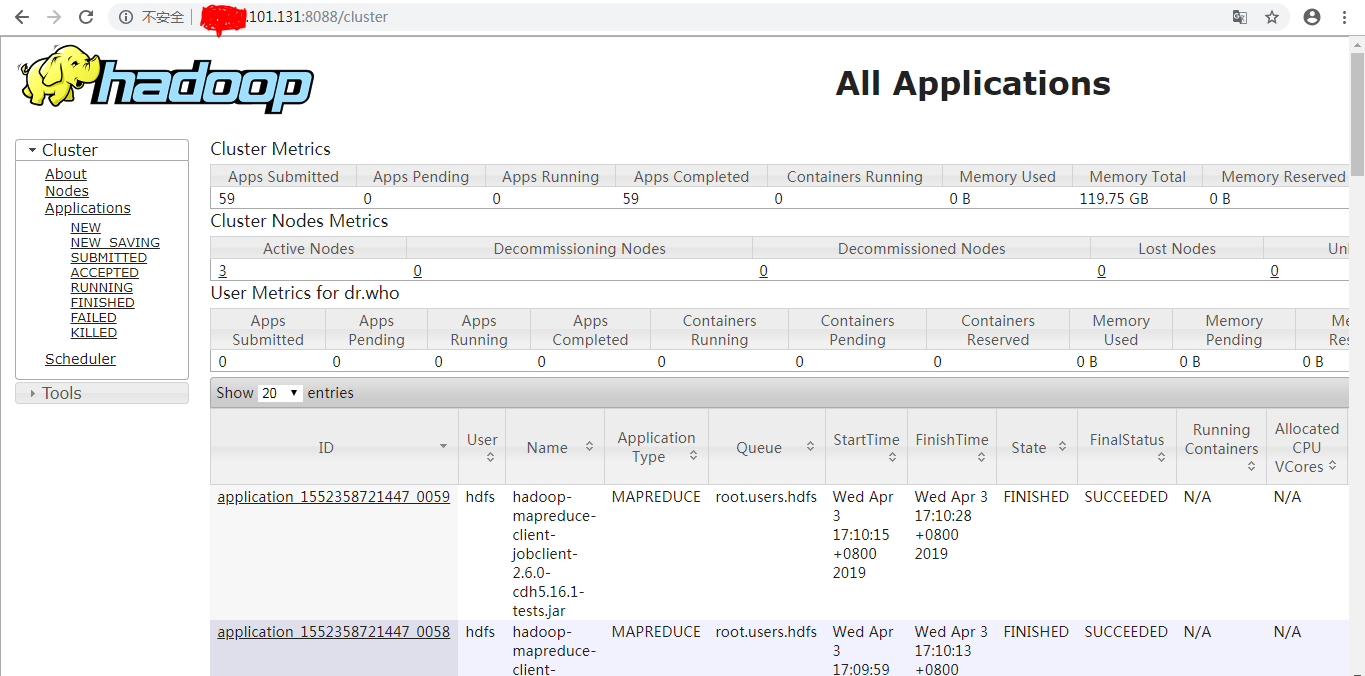
以上结果表示平均作业完成时间是15秒
打开网址 http://*.*.*.*:8088/cluster ,可以查看执行的任务信息:
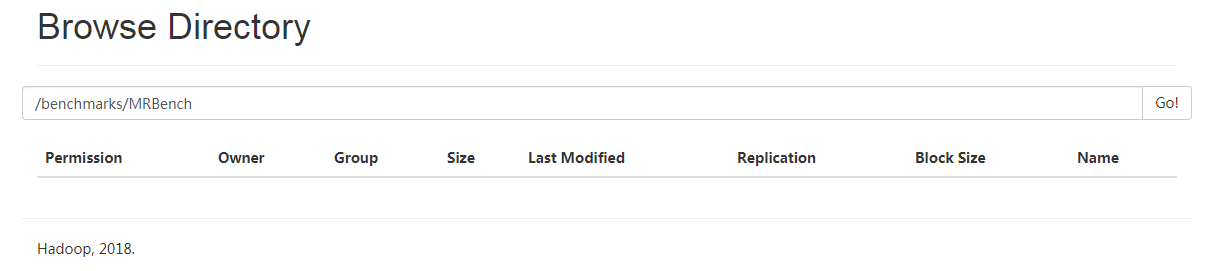
Hadoop File System也生成了相应的目录,但是目录里面的内容是空的,如下:
参考内容: https://blog.51cto.com/7543154/1243883 ; https://www.cnblogs.com/0xcafedaddy/p/8477818.html ; https://blog.csdn.net/flygoa/article/details/52127382
Hadoop基准测试(一)的更多相关文章
- Hadoop基准测试(二)
Hadoop Examples 除了<Hadoop基准测试(一)>提到的测试,Hadoop还自带了一些例子,比如WordCount和TeraSort,这些例子在hadoop-example ...
- Hadoop 基准测试与example
#pi值示例 hadoop jar /app/cdh23502/share/hadoop/mapreduce2/hadoop-mapreduce-examples--cdh5. #生成数据 第一个参数 ...
- Hadoop基准测试(转载)
<hadoop the definitive way>(third version)中的Benchmarking a Hadoop Cluster Test Cases的class在新的版 ...
- Hadoop基准测试
其实就是从网络上copy的吧,在这里做一下记录 这个是看一下有哪些测试方式: hadoop jar /opt/cloudera/parcels/CDH-5.3.6-1.cdh5.3.6.p0.11/ ...
- Hadoop学习笔记四
一.fsimage,edits和datanode的block在本地文件系统中位置的配置 fsimage:hdfs-site.xml中的dfs.namenode.name.dir 值例如file:// ...
- 几个有关Hadoop自带的性能测试工具的应用
http://www.talkwithtrend.com/Question/177983-1247453 一些测试的描述如下内容最为详细,供你参考: 测试对于验证系统的正确性.分析系统的性能来说非常重 ...
- Hadoop理论基础
Hadoop是 Apache 旗下的一个用 java 语言实现开源软件框架,是一个开发和运行处理大规模数据的软件平台.允许使用简单的编程模型在大量计算机集群上对大型数据集进行分布式处理. 特性:扩 ...
- 【Hadoop 分布式部署 六:环境问题解决和集群基准测试】
环境问题: 出现Temporary failure in name resolutionp-senior-zuoyan.com 的原因有很多,主要就是主机没有解析到, 那就在hadoop的sl ...
- hadoop的基准测试
hadoop的基准测试 实际生产环境当中,hadoop的环境搭建完成之后,第一件事情就是进行压力测试,测试我们的集群的读取和写入速度,测试我们的网络带宽是否足够等一些基准测试 测试写入速度 向HDFS ...
随机推荐
- js三种常见的对话框
js中的对话框事通过调用window对象的alert() confirm() 和 prompt()来获得,完成人机交互. 1. 警告框alert() function alert(){ // 弹出 ...
- uniGUI之FDQuery(28)
1]基本设置FDQuery1.Connection2]执行查询SQL语句3]执行 非查询SQL语句4]返回所有数据 和所有 列名 1]基本设置FDQuery1.Connection 一定要 放一个 ...
- 简单桶排序(Bucket Sort)
1.基本思想 桶排序是将待排序集合中处于同一个值域的元素存放在同一个桶中1. 2.算法设计2 假设有一个班级有5个人,这次期末他们分别考了5分,2分,4分,5分,8分(满分为10分).需要将这些分数从 ...
- warmup
先简单了解下源码中的2个函数: <?php echo mb_strpos("朋友比生命还重要?或许是吧" . '?',"?"); echo "\ ...
- 查看KVM宿主机上虚拟机的IP的脚本
查看KVM宿主机上虚拟机的IP的脚本 #!/bin/bash #Auth:liucx #ping当前网段内在线的主机,以便产生arp记录. .{..};do { >& }& do ...
- Django框架之ORM的相关操作之多对多三种方式(五)
在之前的博客中已经讲述了使用ORM的多对多关系表,现在进行总结一下: 1.ORM自动帮助我们创建第三张表 2.手动创建第三张表,第三张表使用ForeignKey指向其他的两张表关联起来 3.手动创建第 ...
- ajax传map,后端接收并解析
前端let map = new Map(); map.set(1, 1); map.set(2, 2); map.set(3, 3); //map转obj let obj= Object.create ...
- 科技 - 5G
科技 - 5G 一.5G的概念 第五代移动通信技术(英语:5th generation mobile networks或5th generation wireless systems.5th-Gene ...
- mysql成功的远程连接
1.在虚拟机上的window7中安装mysql,版本mysql-5.7.27-win32,可以是解压版或者是安装版的, MySQL安装文件分为两种,一种是msi格式的,一种是zip格式的.如果是msi ...
- Top 9 colleges in the world from 2010 to 2020, AI and interdisciplinary areas.
http://csrankings.org/