Teradata 数据库
笔者大学所学计算机专业,读书时接触过Oracle、mysql和SQL SERVER,一度坐井观天觉得数据库应该也就这些了,但自笔者毕业进入数据仓库这个行业,接触的第一个商业数据库即是Teradata,亦是接触到的第一个MPP体系架构,先简单谈谈个人对Teradata的认识吧
产品特点:
1.MPP架构,为提供商业大数据分析处理而设计构建(OLAP)
2.通过PE、BYNET、AMP中间件构建出高效的并行数据库系统(作为行式数据库对硬件资源要求特别在于内存资源需求上优势很明显)
3.通过PI和SI构建数据的均匀分布和高效的读写能力
4.提供了丰富的SQL请求工具(BTEQ、Teradata SQL ASSISTANT、FASTLOAD、MULTILOAD、FASTEXPORT、TPUMP)
5.提供了完备的管理工具(Teradata Manager、DBQM、Teradata Administrator)
6.提供了丰富的二次开发接口(PP2、CLI、ECLI、ODBC、Oracle Transparent Gateway、WinCLI、TS/API)
产品不足
1.过于封闭,在网上很难找到Teradata数据库的相关资料,产生异常或疑问只能咨询Teradata内部人员(或有相关经验人员)
这给后期架构规划和日常异常的处理上带来了很大的不便,随着与Teradata方合作的开展,亦愈发认识到,技术的完全封说的好听点是为了操作的合规性和单一性,说的直白点就是为了最大化专利技术的经济效益(之间产生过几次数据库异常,Teradata中国区的工程师处理不了都是申请美国工程师的技术支持,这也能看出来对于Teradata内部亦是存在比较明显的技术封闭现象)
2.扩展性不足,作为一款MPP体系架构产品,对比开源hadoop以及笔者现在所用的商业Vertica数据库,其扩展性表现十分有限
笔者接触过Teradata 5系列和2系列的架构环境,均采用了共享阵列存储,其最大的问题就在于,阵列插满磁盘就无法有效进行扩容了,节点的扩展没有接触不好妄加评论,当然现在的Teradata可能在这块有了很大的提升和对市场需求积极的调整(在最后一次架构规划中,Teradata方给出了基于X86服务器的2系列架构方案)
3.兼容性不足,这点也可称之为可移植性(当然这类大存储的MPP数据库也不会轻易做移植),当然其缘由还是在于其封闭性
从底层硬件到上层数据库软件以及后期的服务,甚至机柜都是由Teradata定制化的实现,当然现在的Teradata可能在这块有了很大的提升和对市场需求积极的调整(在最后一次架构规划中,Teradata方给出了基于X86服务器的2系列架构方案)
4.IO能力有限,行式存储数据库的通病,在压缩比较低的情况下,加剧了OLAP场景中对于数据库IO能力瓶颈的产生
下面我们就来简单认识认识Teradata吧。
1、Teradata因数据仓库而存在
Teradata 是一个关系型数据库管理系统 (RDBMS).
• 为运行世界上最大的商业数据库而设计;
• 企业级数据仓库的首选解决方案;
• 基于Linux/UNIX与NT的开放式系统平台;
• 完全符合ANSI标准;
• 可以运行于单个或多个节点;
• 可以帮助企业提供自服务端到客户端的所有应用
• 运用并行处理方式来管理Terabytes以上的数据 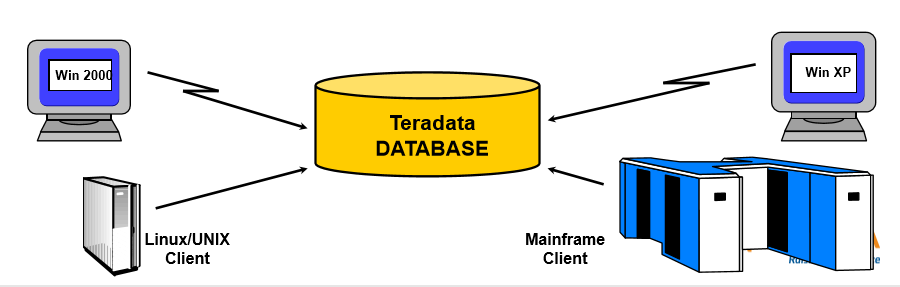
2、Teradata与EDW

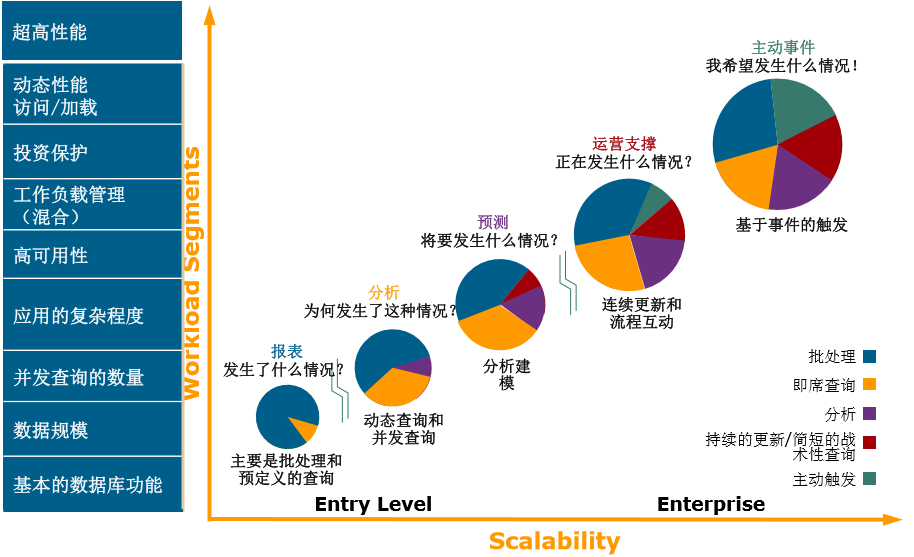
3、数据仓库发展的五个阶段
4、Teradata数据库系统体系架构
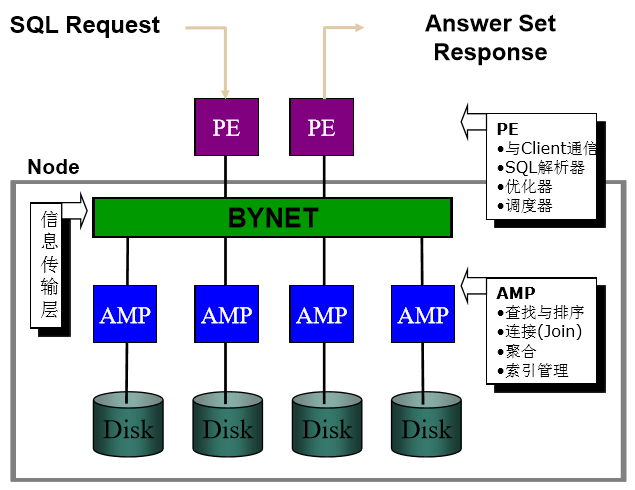
基本读写过程
•解析引擎PE将SQL请求拆分成 各AMP的请求以便幵行处理
• 解析器分解接收到的SQL交易 请求,验证语法、权限等
• 优化器产生最优的查询方案
• 分发所优化的方案到AMP
• 数据通过表PI的HASH值均匀 分布到各AMP管理的磁盘( 写)
• 信息传递层可汇总各AMP数 据,将最终结果返回客户端( 读)
5、The Parsing Engine (PE) 解析器
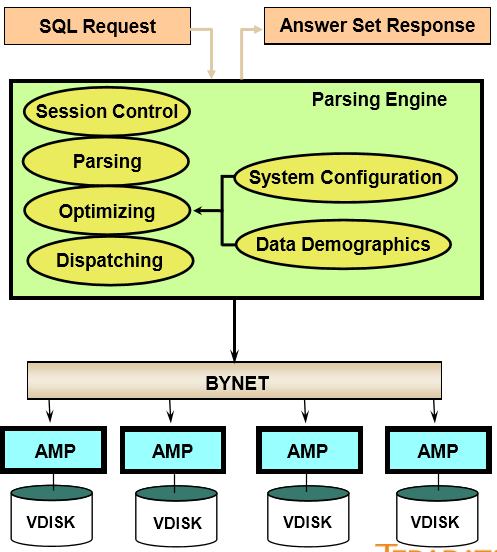
PE的作用:
• 一种VPROC,用亍解释SQL请求、 接收输入记录、审查数据、发送信 息到AMPS
• 每个PE能幵发操作120条会话,每 个会话能处理多个请求
• 当多个用户同时访问系统时, Teradata能够通过PE在各节点间自 劢平衡负载,不需要人工干预
6、BYNET(高速连接网络)
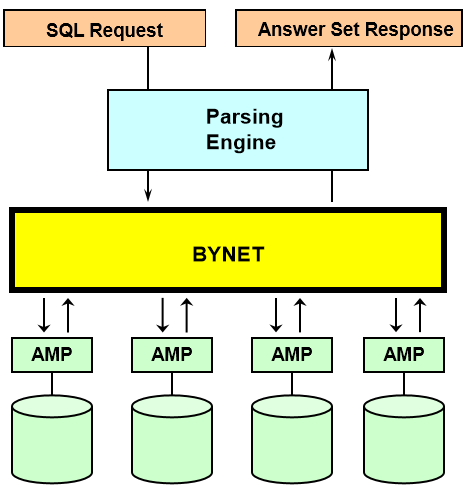
BYNET的作用是:
• 负责AMP与PE之间的通信
• 通信方式可为:Point-to-Point, Multi-Cast, and Broadcast communications
• 将AMP返回给PE的结果集进行合并 • 它的存在使得Teadata的并行成为可能
• BYNET可以是硬件也可以是软件 • 随着节点的增加,BYNET的带宽线性增长
7、AMP - Teradata并行处理的基础
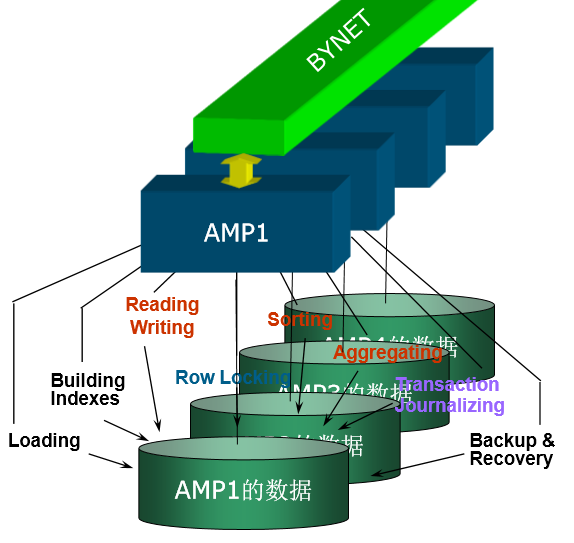
• 一种VPROC,每节点可包含多个 AMP
• 每个AMP拥有独立内存和CPU资 源,与一个VDISK连接,管理数 据库/表的部分数据。
• 控制所有磁盘交互及部分数据库 的操作,如读、写、转换、格式 化等
• 各个AMP幵行处理,互不干扰, 交易处理结果在信息传递层汇总 后,直接返回给应用程序
• 一个请求可以分发到所有AMP一 起共同工作,每个AMP也可以同 步处理多个请求
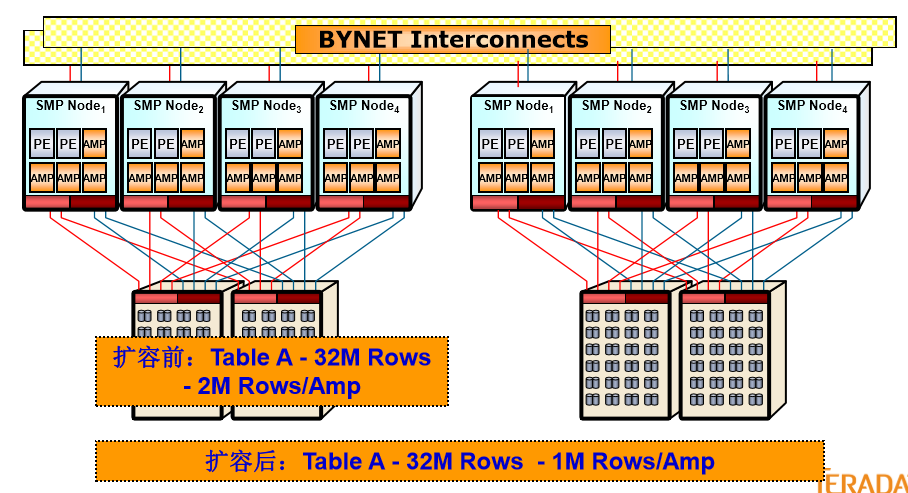
8、Teradata支持MPP架构,通过系统扩展实现并行 处理能力的线性扩展
9、Teradata数据分布
Teradata采用hash算法根据用户建表所选的PI进行数据分布,当然这里有所有MPP体系架构数据库的通病,数据倾斜问题,Terdata为方便DBA的维护管理工作,提供了数据重组功能,当然作为一个大型的MPP数据库,数据库对象量级的过于庞大,数据倾斜问题的处理往往会占用DBA相当大的维护管理成本(靠每个用户遵守PI选择的原则只是理论上的期望)
关于Teradata组件和语法的分享这里就不详述了,如有兴趣欢迎留言交流
后期随着使用的深入,在逐步了解其强大同时也更加了解其封闭,要使用Teradata购买其产品只是一个开始,后续在于配套的维护和扩容上还需源源不断的投入,在这个注重信息安全和成本控制的时代趋势中,伴随着去IOE的深入和开源技术的成熟,Teradata注定淡出大部分国内市场,至少对于笔者所处的通信行业来讲是如此,自然首当其冲的还是企业对投入成本的控制,当然不可否认的是,Teradata作为一个为大数据商业数据库产品,确有其独到之处。
老生常谈,在数据仓库体系架构中,至少在当下,RDBMS仍是核心的一环,笔者所在的环境,在对hadoop生态取代Teradata探索中有过血淋淋的教训,在面对Teradata服务即将到期的时候不得不再次进行基于MPP体系架构的RDBMS招标,事实证明开源与商业的组合架构现阶段最为合适,故而这样的架构沿用至今,只是对于数据仓库环境,基于MPP架构体系的列式存储RDBMS应是首选。
关于MPP体系架构相关知识,我们下期再聊。

我是Mr.Yu,一名数据仓库行业的资深从业者,很高兴与你的这次分享!
Teradata 数据库的更多相关文章
- 【Python实战】使用Python连接Teradata数据库???未完成
1.安装Python 方法详见:[Python 05]Python开发环境搭建 2.安装Teradata客户端ODBC驱动 安装包地址:TTU下载地址 (1)安装TeraGSS和tdicu(ODBC依 ...
- Teradata 认证系列 - 2. Teradata数据库总览
Teradata (以下简称TD) 总览本课的学习目标 描述Teradata数据库产品的功能 知晓支持的操作系统 描述Teradata的并行架构 解释线性可扩展性 列出Teradata DBA永远不需 ...
- Teradata 数据库介绍
Teradata在整体上是按Shared Nothing 架构体系进行组织的,他的定位就是大型数据仓库系统,定位比较高,他的软硬件都是NCR自己的,其他的都不识别:所以一般的企业用不起,价格很贵.由于 ...
- 使用tdload工具将本地数据导入到Teradata数据库中
想把本地的数据文件(比如txt.csv)中的数据导入到Teradata虚拟机中的表中.既可以使用Teradata Assistant中的import功能,也可以使用fastload导入,前者的缺点是一 ...
- TERADATA数据库操作
1.创建一个数据库的命令举例: ,spool; 注释:该命令创建了一个测试数据库testbase,其永久表空间为200mb,spool空间不能超过100mb.在teradata数据库系统的缺省方式下, ...
- JDBC的ResultSet游标转spark的DataFrame,数据类型的映射以TeraData数据库为例
1.编写给ResultSet添加spark的schema成员及DF(DataFrame)成员 /* spark.sc对象因为是全局的,没有导入,需自行定义 teradata的字段类型转换成spark的 ...
- Teradata数据库访问链条
- Teradata中fastload使用
Teradata Fastload Utility 是teradata数据库中一个基于命令行的快速load大量数据到一个空表的工具. 数据可以从以下途径被load: 1) Disk 或 tape; 2 ...
- Teradata 的rank() 和 row_number() 函数
Teradata数据库中也有和oracle类似的分析函数,功能基本一样.示例如下: RANK() 函数 SELECT * FROM salestbl ORDER BY 1,2; storeid p ...
随机推荐
- C 2012年笔试题
1指出程序段中的错误:分析错误的原因,并进行修改 1.1函数 swap 将两个字符串(字符数组作实参,长度不超过 100)的内容进行交换 void swap(char *pa,char *pb) { ...
- Prism 源码解读3-Modules加载
介绍 在软件开发过程中,总想组件式的开发方式,各个组件之间最好互不影响,独立测试.Prism的Modules很好的满足了这一点. 这个架构图很好了讲解了Prism的Modules的概念 Prism支持 ...
- Transformers 库常见的用例 | 三
作者|huggingface 编译|VK 来源|Github 本章介绍使用Transformers库时最常见的用例.可用的模型允许许多不同的配置,并且在用例中具有很强的通用性.这里介绍了最简单的方法, ...
- Git使用的一些问题:.gitignore规则不生效、git同步代码至github和gitee
Git忽略规则及.gitignore规则不生效的解决办法 .gitignore 的基本使用 在git中如果想忽略掉某个文件,不让这个文件提交到版本库中,可以使用修改根目录中 .gitignore 文件 ...
- 服务器上安装.NET Framework 3.5 sp1
操作系统是Windows Server 2008 R2 或 Windows Server 2012 或 Windows Server 2012 R2,可以直接进入“服务器管理器”添加“功能”.
- Hadoop Zookeeper 分布式服务框架
what is Zookeeper? 1,开源的分布式的,为分布式应用提供协调服务的Apache项目2,提供一个简单原语集合,以便于分布式应用可以在它之上构建更高层次的同步服务3,设计非常易于编程,它 ...
- Spring ioc xml 实例化bean 自己实现
public class DefClassPathXmlApplicationContext { private String xmlPath; public DefClassPathXmlAppli ...
- NEKO's Maze Game - Codeforces 题解
题目 NEKO#ΦωΦ has just got a new maze game on her PC! The game's main puzzle is a maze, in the forms o ...
- elasticesearch搜索返回高亮关键字
pre_tags 前缀标签 post_tags 后缀标签 tags_schema 设置为styled可以使用内置高亮样式 require_field_match 多字段高亮需要设置为false 使用h ...
- Educational Codeforces Round 84 (Rated for Div. 2)
A. Sum of Odd Integers(思维) 思路 这一题看完ans之后觉得是真简单,不过有一些地方还是要理解的. 这一题输出YES,有两个条件 kk%2 == n%2k,这个条件的意思是 k ...