“淘宝技术这十年”
“少时淘气,大时淘宝”
时势造英雄
起因
eBay 易趣 在资本方面对仗,阿里想趁此崛起新项目
就要求能在短时间内做出一个 个人对个人的商品交易网站(C2C)
2003年4月7日-5月10日 一个月 淘宝技术团队采取购买方案
需求分析
自建|购入
:-:|:-
时间成本高,故不采用|要求比较低的维护成本;方便扩展和二次开发;轻量、简单
LAMP Linux+Apache+MySQL+PHP
优点:无须编译,发布快速;PHP语言功能强大,能做到从页面渲染到数据访问所有的事情,且用到的技术都是开源免费的
提供淘宝网站系统的官网:PHPAuction
购入后修改
增加后台管理功能、修改页面模板、页眉页脚加上自己站点简介;
数据库拆分:拆分成一个主库+连个从库,并且读写分离
数据库拆分优点
存储容量增加;备份提高数据安全性;读写分离提升读写效率
淘宝网”个人网站”即横空出世了
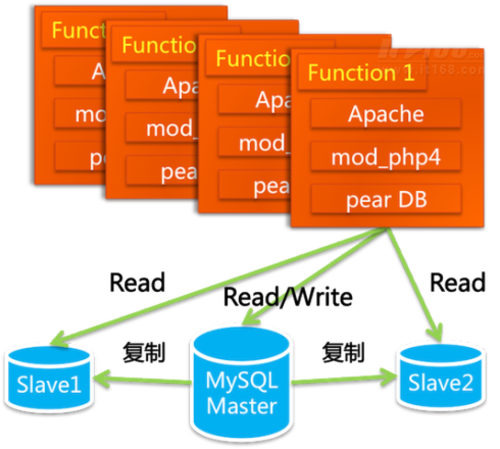
这个第一版系统中包含商品发布、管理、搜索、商品详情、出价购买、评价投诉、我的淘宝等功能
系统改进
背景:用户需求、流量增长、数据库资源增大
服务器:由一台变成了三台 Email + 运行数据库 + 运行WebApp
数据库搜索: like → isearch
问题短板
访问量和数据量的飞涨,数据库的性能缺陷突出:
1 当Master同步数据到Slave时,会引起Slave写,此时的Slave读操作都需要等待。
2 同时会发生Slave的主键冲突,经常导致同步停止,使得查询失败。
打怪升级
在前述的问题短板的情况下,阿里必须提出技术解决方案:
把MySQL换成Oracle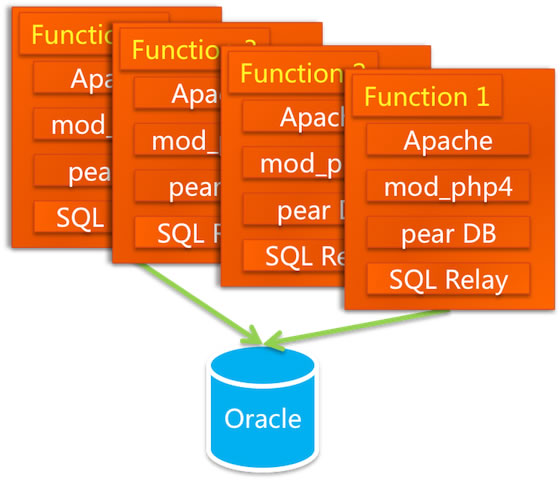
Oracle
优点:容量大、稳定、安全、性能高
人才条件:阿里有顶尖团队
更换数据库
访问方式 + SQL语法 + 连接池设计(关键)
存在的问题
连接池
连接池中放的是长连接,是进程级别的,在创建进程的时候,要独占一分部分内存空间,这部分连接数在固定内存的Oracle server上是有限的,任何一个请求只需要从连接池中取得一个连接即可,用完后释放,不需要频发地创建和断开连接,要知道连接的创建与断开开销是非常大的。PHP语言
对数据库的访问很直接,每一个请求都需要一个连接。如果是长连接,应用故武器增多时,连接数就多了,就会把数据库拖挂;而如果是短连接,频繁得连接再断开 数据库性能会非常差
解决方案
开源的连接池代理服务 SQL Relay
遗留问题
SQL Relay死锁 只能靠重启服务解决
存储扩容
NAS 数据库存储设备(Network Appliance)+ Oracle RAC(Real Application Clusters,实时应用集群)实现负载均衡NAS的NFS文件系统协议传输延迟很严重↓
改用了Dell和EMC合作的SAN低端存储数据量的增大→存储结点的不断拆分↓RAC出现问题
购买小型机
支付手段创新-支付宝
安全交易、第三方托管、开发与银行网关对接功能
交流方式创新-淘宝旺旺
脱胎换骨 边换边跑
“好的架构图充满美感”。第二幅架构图显得头重脚轻,不是个稳定的版本,打怪的时候还是留下了祸根,SQL relay的问题无法解决,数据库必须使用oracle。
换开发语言 PHP → JAVA
JAVA
成熟的网站开发语言 比较良好的企业开发框架 开发经验人才多 后续维护成本比较低 有很多现成的连接池Sun公司
创建java语言的开发公司,eBay的网站也经历过从C++到java的类似开发语言换骨,也是由Sun公司完成的。淘宝也请了Sun公司为淘宝主刀
要求
迁移过程中不停止服务,原系统的bugfix和功能改进不受影响。
方案
给业务分模块,一个一个模块地渐进式替换。如用户模块,老的member.taobao.com继续维护,不添加新功能,新的功能先在新的模块上开发,跟老的共用一个数据库,开发完毕之后放到不同的应用集群上,另开个域名 member1.taobao.com,同时替换老的功能,替换一个,把老的模块上的功能关闭一个,逐渐的把用户引导到 member1.taobao.com,等所有功能都替换完毕之后,关闭 member.taobao.com。
小问题
二级域名member1.taobao.com应该是个过度状态,但却很难把member1切换回member,因为有些地方连接已经写死了
开发模式
Java MVC struts1.x
在多人协作方面有很多致命弱点,没有轻量框架作为基础,很难扩展WebX
阿里巴巴 周悦虹 在 JAkarta Turbine 的基础上做了很多扩展 打造了一个阿里巴巴自己用的MVC框架 WebX。该框架易于扩展 方便组件化开发,页面模板支持 JSP 和 Velocity ,持久层支持ibatis 和 hibernate 等,控制层可以用EJB和Spring
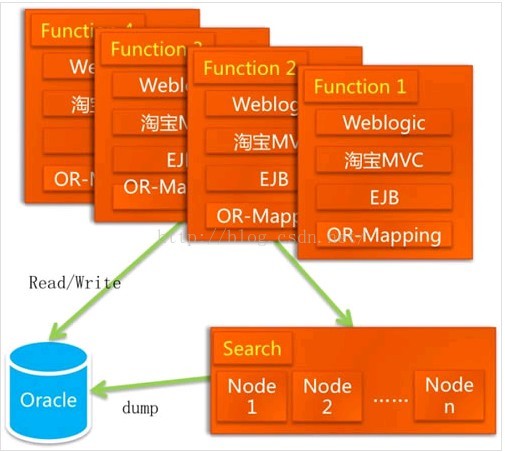
性能 容量 成本的进化
数据库扩展
Oracle “分库分表”:把用户的信息按照ID来存放到两个数据库汇总DB1DB2,把商品信息和卖家信息放在两个对应的数据库里面,把商品类目等通用信息放在第三个库里面(DBcommon)。这么做的目的除了增加了数据库的容量之外,还有一个就是做容灾,万一一个数据库挂了,整个网站上还有一半的数据能操作。 数据的合并、排序、分页
DBRoute,统一数据的合并、排序、分页,该框架一直延续在Oracle时段。Spring
EJB → Spring 系统精简了代码缓存 CDN(内容分发网络)
缓存初型:Berkeley DB缓存系统,该缓存系统性能比较弱,存放不太变动的只读信息。
CDN 起初采用China Cache 后改用自己开发的CDN
脱胎换骨架构图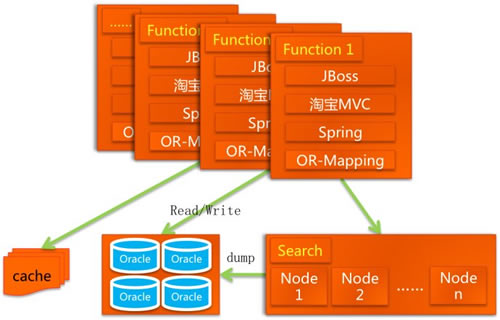
去IOE (IBM小型机 Oracle EMC存储)
创新技术
“用钱能解决的问题 都不是问题” 业务推动创新 创新推动业务
淘宝文件系统TFS
商用存储系统的局限
1 没有对小文件存储和读取环境进行针对性优化
2 文件数量大 网络存储设备无法支撑
3 系统所连接服务器越来越多
4 商用存储系统扩容成本高,存在单点故障,容灾和安全性无法得到保障
商用系统和自主研发之间的经济效益对比
1 商用软件很难满足大规模系统的应用需求,无论存储还是CDN还是负载均衡,因为在厂商实验室端,很难实现如此大的数据规模测试。
2 研发过程中,将开源和自主开发相结合,会有更好的可控性,系统出问题了,完全可以从底层解决问题,系统扩展性也更高。
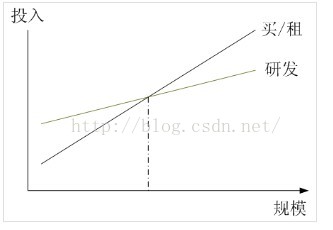
3 在一定规模效应基础上,研发的投入都是值得的。上图是一个自主研发和购买商用系统的投入产出比对比,实际上,在上图的交叉点左边,购买商用系统都是更加实际和经济性更好的选择,只有在规模超过交叉点的情况下,自主研发才能收到较好的经济效果。实际上,规模化达到如此程度的公司其实并不多,不过淘宝网已经远远超过了交叉点。
TFS存储需求
文件比较小;并发量高;读操作远大于写操作;访问随机;没有文件修改的操作;要求存储成本低;能容灾能备份。应对这种需求,显然要用分布式存储系统;由于文件大小比较统一,可以采用专有文件系统;并发量高,读写随机性强,需要更少的 IO 操作;考虑到成本和备份,需要用廉价的存储设备;考虑到容灾,需要能平滑扩容。
参照GFS 产生的TFSv1.0:
大专栏 “淘宝技术这十年”mark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQv/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center" alt="TFS 1.0"/>
4 自主研发的系统可在软件和硬件多个层次不断的优化。
在这个架构中:
• 每个 Data Server 运行在一台普通的 Linux 主机上
• 以 block 文件的形式存放数据文件(一般64M一个block )
• block 存多份保证数据安全
• 利用 ext3 文件系统存放数据文件
• 磁盘 raid5 做数据冗余
• 文件名内置元数据信息,用户自己保存TFS文件名与实际文件的对照关系 – 使得元数据量特别小。
淘宝 TFS 文件系统在核心设计上最大的取巧的地方就在,传统的集群系统里面元数据只有1份,通常由管理节点来管理,因而很容易成为瓶颈。而对于淘宝网的用户来说,图片文件究竟用什么名字来保存实际上用户并不关心,因此TFS在设计规划上考虑在图片的保存文件名上暗藏了一些元数据信息,例如图片的大小、时间、访问频次等等信息,包括所在的逻辑块号。而在元数据上,实际上保存的信息很少,因此元数据结构非常简单。仅仅只需要一个fileID,能够准确定位文件在什么地方。
由于大量的文件信息都隐藏在文件名中,整个系统完全抛弃了传统的目录树结构,因为目录树开销最大。拿掉后,整个集群的高可扩展性极大提高。实际上,这一设计理念和目前业界的“对象存储”较为类似,淘宝网 TFS 文件系统已经更新到 1.3 版本,
TFS1.3重点改善
心跳和同步性能、元数据存储在内存中,清理磁盘空间等
性能优化:
1 |
采用ext4文件系统 并且预分配文件 减少ext3等文件系统数据碎片带来的性能损耗; |
图片文件服务器
部署在TFS前端,用Apache实现,缩略图实时生成
1 避免后端图片服务器上存储的图片数量过多,大大节约了后台存储空间的需求
2 缩略图可实时生成,更加灵活
3 采用一级缓存和二级缓存,前面还有全局负载均衡的设置
淘宝网缓存策略:淘宝网在各个运营商中心点设有二级缓存,整体系统中心店设有一级缓存,加上全局负载均衡,传递到后端的TFS流量就已经非常均衡和分散了,对前端的响应性能也大大提升。淘宝大部分图片都尽量在缓存中命中,如果无法命中,则在本地服务器上查找手否存有原图,并根据原图生产缩略图,如果都没有命中,则考虑去后台TFS集群文件存储系统上调取。
1 |
st=>start: Start |
淘宝KV缓存系统Tair
TBStore 分布式算法实现
根据保存的Key关键字,对key进行Hash算法,取得Hash值,再对Hsah值与总Cache服务器数据取,找到服务器列表中下表为此值的Cache服务器。由Java Client API封装实现TBstore优缺点
它是基于Berkeley DB缓存系统的,而Berkeley DB在数据量超过内存的时候,就要往磁盘上写数据了,所以,它是可以做持久化存储的。但是一旦往磁盘写入数据,作为缓存的性能就大幅度下降
UIC (User Information Center)缓存系统 TDBM
数据全部放在内存中,改进了TDBM的集群分布方式,在内存利用率和吞吐量方面又做了大幅度提升
TDBM TBStore 的数据接口和用途都十分相似,二者合并推出即Key-Value缓存系统(Tair,Taobao Pair,Pair即Key-Value数据对)
1 Tair包括缓存和持久化两种存储功能。
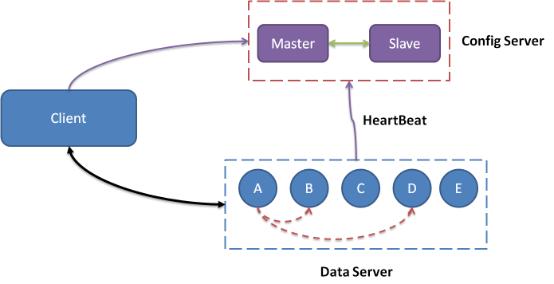
2 分布式系统:由一个中心控制节点Config Server和一系列服务节点Data server组成。
3 Config Server负责管理所有的Data Server,维护其状态信息。Data server对外提供各种数据服务,并以心跳形式将吱声的状况汇报给Config Server。
4 Config server是控制点,而且是单点,目前采用一主一备来保证其可靠性。所有Data Server 地位等价。
浴火重生
服务化
catserver和hesper 类目属性 服务化
高内聚低耦合 业务的拆分和耦合
中间件
High-Speed Service Framework实时调用的中间件(淘宝的HSF,高性能服务框架)
分布式服务框架HSF
分析分布式服务框架
基于OSGi实现分布式服务框架历程分布式消息中间件系统 一种是异步消息通知的中间件(淘宝的Notify)
分布式数据访问层TDDLTaobao data distribution layer
1 |
数据访问路由-将针对数据的读写请求发送到最合适的地方; |
稳定 “火车模型”
集群:能否集群受限于应用在水平伸缩上的支撑程度,而集群的规模通常会受限于调度、数据库、机房等
分工:涉及的主要有按功能和数据库的不同拆分系统等,如何拆分以及拆分后如何交互是需要面临的两个挑战。
负载均衡 根据QoS分配资源
Session框架
session介绍 可详见 图解HTTP读书笔记
解决session共享问题:
1 硬件负载,将用户请求分发到特定服务器
2 Session 复制,就是将用户的Session复制到集群内所有的服务器
缺点
成本较高;性能差,当访问量增大时,带宽增大,机器数量增多,网络负担成指数型上升
Tbsession
1 Session客户端存储,将session信息存储到客户端浏览器的cookie中
2 实现服务端存储,减少cookie使用,增强用户信息安全性,避免流浪器对cookie数量和大小的限制
3 session配置统一管理起来,集中管理服务端session和客户端cookie的使用情况,对cookie的使用做有效的监管
4 支持动态更新,session的配置动态更新
开放平台
Hadoop Memcached??
服务路由(外部可以获取内部信息)
写一个搞笑的httpAgent
服务接口标准化(统一方式的获得各种标准化信息)
对象文本化(JSON XML)
授权(外部合法的获取内部信息)
OAuth协议
[参考链接]《淘宝技术这十年》读书笔记
“淘宝技术这十年”的更多相关文章
- 《淘宝技术这十年》之LAMP架构的网站
本文节选自<淘宝技术这十年>一书,子柳(赵超)著,由电子工业出版社出版.作者的系列博文:从P1到P7--我在淘宝这7年 2003年4月7日,马云在杭州成立了一个神秘的组织.他叫来十位员工, ...
- 读《淘宝技术这十年》 总结下web架构的发展
关键词就两 分布式 缓存 分布式 数据库,应用服务器等的多节点部署,数据库的读写分离,剥离文件系统 缓存 数据缓存 静态页面缓存 php时代 最初LAMP起步 并将数据库做读写分离,拆分为主库+从库 ...
- 【转】淘宝技术牛p博客整理
转自:http://blog.csdn.NET/zdp072/article/details/19574793 淘宝技术委员会是由淘宝技术部高级技术人员组成的一个组织,共分为Java分会.C/C++分 ...
- 淘宝技术牛p博客整理
淘宝的技术牛人的博客http://blog.csdn.net/zdp072/article/details/19574793
- 淘宝技术发展(Java时代:脱胎换骨)
我的师父黄裳@岳旭强曾经说过,“好的架构图充满美感”,一个架构好不好,从审美的角度就能看得出来.后来我看了很多系统的架构,发现这个言论基本成立.那么反观淘宝前面的两个版本的架构,你看哪个比较美? 显然 ...
- 从Hadoop框架与MapReduce模式中谈海量数据处理(含淘宝技术架构) (转)
转自:http://blog.csdn.net/v_july_v/article/details/6704077 从hadoop框架与MapReduce模式中谈海量数据处理 前言 几周前,当我最初听到 ...
- 从Hadoop骨架MapReduce在海量数据处理模式(包括淘宝技术架构)
从hadoop框架与MapReduce模式中谈海量数据处理 前言 几周前,当我最初听到,以致后来初次接触Hadoop与MapReduce这两个东西,我便稍显兴奋,认为它们非常是神奇.而神奇的东西常能勾 ...
- 七天学会NodeJS (原生NodeJS 学习资料 来自淘宝技术团队)
NodeJS基础 什么是NodeJS JS是脚本语言,脚本语言都需要一个解析器才能运行.对于写在HTML页面里的JS,浏览器充当了解析器的角色.而对于需要独立运行的JS,NodeJS就是一个解析器. ...
- (转)从P1到P7——我在淘宝这7年
(一) 2011-12-08 [原文链接] 今天有同事恭喜我,我才知道自己在淘宝已经七周年了.很多人第一句话就是七年痒不痒,老实说,也曾经痒过,但往往都是一痒而过,又投入到水深火热的工作中去.回家之后 ...
随机推荐
- Linux-proc文件系统介绍
1.操作系统级别的调试 (1).简单程序单步调试 (2).复杂程序printf打印信息调试 (3).框架体系日志记录信息调试 (4).内核调试的困境 2.proc虚拟文件系统的工作原理 (1).Lin ...
- 让几个横向排列的浮动子div居中显示的方法
div设置成float之后,就无法使子div居中显示了,那么如何让几个横向排列的浮动的div居中显示呢,下面有个不错的方法,希望对大家有所帮助 div设置成float之后,在父div中设置text-a ...
- Entity Framework实现属性映射约定
Entity Framework Code First属性映射约定中“约定”一词,在原文版中为“Convention”,翻译成约定或许有些不好理解,这也是网上比较大多数的翻译,我们就当这是Entity ...
- JS 2019-12-03T15:53:23.000+08:00 转化为 YYYY MM DD
js时间格式转化 2019-12-03T15:53:23.000+08:00 转化为 YYYY MM DD var dateee = new Date(createTime).toJSON();var ...
- Debian8.8为普通用户添加sudo权限
1.进入root用户,su root 输入密码,我们首先修改 /etc/sudoers 文件的属性为可写权限# chmod +w /etc/sudoers2.编辑 vim /etc/sudoers,添 ...
- 系统学习Javaweb11----综合案例1
学习内容: 1.综合案例-需求说明 2.综合案例-需求分析 3.综合案例-需求实现-网页顶部部分 4.案例-需求实现-网页导航条 5.综合案例-需求实现-网页主体部分 6.综合案例-需求实现-网页主体 ...
- oBike退出新加坡、ofo取消免押金服务,全球共享单车都怎么了?
浪潮退去后,才知道谁在裸泳.这句已经被说烂的"至理名言",往往被用在一波接一波的互联网热潮中.团购.O2O.共享单车.共享打车.无人货柜--几乎每一波热潮在退去后会暴露出存在的问题 ...
- Opencv笔记(十三)——图像的梯度
目标 认识图像梯度.边界 学习函数cv2.Sobel(),cv2.Schar(),cv2.Laplacian() 原理 图像梯度可以把图像看成二维离散函数,图像梯度其实就是这个二维离散函数的求导.Op ...
- [HDU多校]Ridiculous Netizens
[HDU多校]Ridiculous Netizens 点分治 分成两个部分:对某一点P,连通块经过P或不经过P. 经过P采用树形依赖背包 不经过P的部分递归计算 树型依赖背包 v点必须由其父亲u点转移 ...
- FactoryBean 和 BeanFactory
大佬勿喷,如果有什么地方理解错了欢迎吐槽 一 .BeanFacory 首先来看看下边的代码 package com.lhf.beanfactory; public class SingleBean { ...