Flink 操作链与任务槽
Operator Chains(操作链)
Flink出于分布式执行的目的,将operator的subtask链接在一起形成task(类似spark中的管道)。
每个task在一个线程中执行。
将operators链接成task是非常有效的优化:它可以减少线程与线程间的切换和数据缓冲的开销,并在降低延迟的同时提高整体吞吐量。
链接的行为可以在编程API中进行指定,详情请见代码OperatorChainTest。
开启操作链 和 禁用操作链的对比图(默认开启):
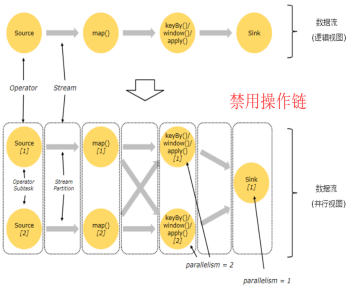
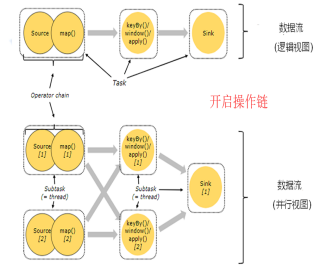
Flink默认会将多个operator进行串联,形成任务链(task chain)
注意: task chain 可以理解为就是 operator chain 只是不同场景下,称呼不同。
我们也可以禁用任务链,让每个operator形成一个task。
StreamExecutionEnvironment.disableOperatorChaining() 这个方法会禁用整条工作链
操作链其实就是类似spark的pipeline管道模式,一个task可以执行同一个窄依赖中的算子操作。
我们也可以细粒度的控制工作链的形成,比如调用dataStreamSource.map(...).startNewChain(),但不能使用dataStreamSource.startNewChain()
dataStreamSource.filter(...).map(...).startNewChain().map(...),需要注意的是,当这样写时相当于source和filter组成一条链,两个map组成一条链。
即在filter和map之间断开,各自形成单独的链。
代码:
package com.ronnie.flink.stream.test; import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /**
* 开启与禁用工作链时,输出的结果不一样。
* 当开启工作链时(默认启动),operator map1与map2 组成一个task.
* 此时task运行时,对于hello,flink 这两条数据是:
* 先打印 hello ---- 1 , hello->1 ---- 2
* 后打印 flink ---- 1 , flink->1 ---- 2
* 当禁用工作链时,operator map1与map2 分别在两个task中执行
* 此时task运行时,对于hello,flink 这两条数据是:
* 先打印 hello ---- 1 , flink ---- 1
* 后打印 hello->1 ---- 2 , flink->1 ---- 2
*
* 注:操作链类似spark的管道,一个task执行多个的算子.
*/
public class OperatorChainTest { public static final String[] WORDS = new String[] {
"hello",
"flink",
"spark",
"hbase"
}; public static void main(String[] args) {
// 设置执行环境, 类似spark中初始化sparkContext一样
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); // 关闭操作链..
env.disableOperatorChaining(); DataStreamSource<String> dataStreamSource = env.fromElements(WORDS); SingleOutputStreamOperator<String> pairStream = dataStreamSource.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
System.err.println(value + " ---- 1");
return value + "->1";
}
}).map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
System.err.println(value + " ---- 2");
return value + "->2";
}
}); // 还可以控制更细粒度的任务链,比如指明从哪个operator开始形成一条新的链
// someStream.map(...).startNewChain(),但不能使用someStream.startNewChain()。
try {
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
}
Task slots(任务槽)
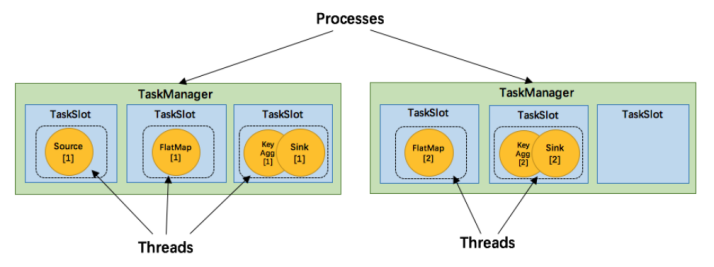
- TaskManager 是一个 JVM 进程,并会以独立的线程来执行一个task或多个subtask。
- 为了控制一个 TaskManager 能接受多少个 task,Flink 提出了 Task Slot 的概念。
- Flink 中的计算资源通过 Task Slot 来定义。每个 task slot 代表了 TaskManager 的一个固定大小的资源子集。
- 例如,一个拥有3个slot的 TaskManager,会将其管理的内存平均分成三分分给各个 slot。
- 将资源 slot 化意味着来自不同job的task不会为了内存而竞争,而是每个task都拥有一定数量的内存储备。
- 需要注意的是,这里不会涉及到CPU的隔离,slot目前仅仅用来隔离task的内存。
- 通过调整 task slot 的数量,用户可以定义task之间是如何相互隔离的。
- 每个 TaskManager 有一个slot,也就意味着每个task运行在独立的 JVM 中。
- 每个 TaskManager 有多个slot的话,也就是说多个task运行在同一个JVM中。
- 而在同一个JVM进程中的task,可以共享TCP连接(基于多路复用)和心跳消息,可以减少数据的网络传输。
- 也能共享一些数据结构,一定程度上减少了每个task的消耗。
- 如图中所示,5个Task可能会在TaskManager的slots中分布,图中共2个TaskManager,每个有3个slot。
Flink 操作链与任务槽的更多相关文章
- flink操作mysql
Flink读写mysql 如果是mvn项目的话,需要预先导入相应的包: <dependency> <groupId>org.apache.flink</groupId&g ...
- flink03-----1.Task的划分 2.共享资源槽 3.flink的容错
1. Task的划分 在flink中,划分task的依据是发生shuffle(也叫redistrubute),或者是并行度发生变化 1. wordcount为例 package cn._51doit ...
- PHP设计模式:类自动载入、PSR-0规范、链式操作、11种面向对象设计模式实现和使用、OOP的基本原则和自动加载配置
一.类自动载入 SPL函数 (standard php librarys) 类自动载入,尽管 __autoload() 函数也能自动加载类和接口,但更建议使用 spl_autoload_registe ...
- C++中的链式操作
代码编译环境:Windows7 32bits+VS2012. 1.什么是链式操作 链式操作是利用运算符进行的连续运算(操作).它的特点是在一条语句中出现两个或者两个以上相同的操作符,如连续的赋值操作. ...
- thinkphp查询构造器和链式操作、事务
插入 更新记录 查询数据 删除数据 插入数据----name这种用法,会去config.php中去寻找前缀,如果你定义了前缀tp,那么执行下条语句会查询对tp_data的插入操作 链式操作---> ...
- Flink资料(1)-- Flink基础概念(Basic Concept)
Flink基础概念 本文描述Flink的基础概念,翻译自https://ci.apache.org/projects/flink/flink-docs-release-1.0/concepts/con ...
- Apache Flink 分布式运行时环境
Tasks and Operator Chains(任务及操作链) 在分布式环境下,Flink将操作的子任务链在一起组成一个任务,每一个任务在一个线程中执行.将操作链在一起是一个不错的优化:它减少了线 ...
- Apache Flink - 分布式运行环境
1.任务和操作链 下面的数据流图有5个子任务执行,因此有五个并行线程. 2.Job Managers, Task Managers, Clients Job Managers:协调分布式运行,他们安排 ...
- Flink Program Guide (2) -- 综述 (DataStream API编程指导 -- For Java)
v\:* {behavior:url(#default#VML);} o\:* {behavior:url(#default#VML);} w\:* {behavior:url(#default#VM ...
随机推荐
- python表白代码1.0桃心输出
python爱心表达函数初级版本:def my_heart(a,b=2): print("\n".join(["".join([(a[(x-y) % len(a ...
- 网络编程之TCP三次握手,四次断开
目录 TCP三次握手 1:上图的名词解释 2:TCP三次握手过程 3:为什么不能改成两次握手? TCP三次握手 1:上图的名词解释 SYN:同步序号.它表示建立连接.TCP规定SYN=1时不能携带数据 ...
- linux下的文件操作
彻底删除文件 rm -rf + [文件目录 可相对可绝对] 是彻底删除而且linux无回收站 创建文件 touch + [文件名] 创建文件夹 mkdir + [文件夹名] 文件提权:chmod 77 ...
- 第3节 storm高级应用:2、storm与hdfs的整合工程环境准备;3、整合代码开发
======================================== 3. storm与hdfs的整合使用 3.1.功能需求: 实现随机发送订单数据,从计算订单的总金额,然后将订单中的数 ...
- [Tommas] ERP系统测试用例设计1(转)
问题: 1.如何进行ERP系统测试用例设计? 2.ERP系统测试用例设计过程? 3.ERP系统测试用例设计的方法? ERP系统本身是一种业务流程很复杂,单据报表众多,逻辑性很强的系统,质量保证方面很难 ...
- mysql 子查询问题
今天在做子查询的时候发现运行报错, 我的代码是select* from (....) device des ,我一直以为的是device是表名,然后dec是别名,后面问了同事才知道from(...)这 ...
- python+ selenium + webdriver的环境准备
web自动化安装 1.安装最新的selenium pip install -U selenium 2.安装chrom浏览器和chromdriver的下载 http://chromedriver.sto ...
- 第三单元总结:JML规格定义下的程序设计、验证与测试
JML语言及工具 JML语言理论 JML语言利用前置条件.后置条件.不变式等约束语法,描述了Java程序的数据.方法.类的规格,是一种契约式程序设计的实现工具. 常用的JML语言特性 \result: ...
- 学习Linux系统永远都不晚
作为一名机械专业毕业的学生,两年的工作经历实实在在地教会了我如何认清现实,让当初那个对机械行业无比憧憬的少年明白了自己选择的路有多艰难.由于我的父母都是工人,所以我比其他同龄人能更早地接触到工业的魅力 ...
- #$d#$a什么意思
#$d#$a什么意思 qjh.693111级分类:外语被浏览37次2013.05.12 满意答案 vgrwi 采纳率:50%12级 2013.05.13 回车换行 换成十进制就是 #13#10