新闻网大数据实时分析可视化系统项目——19、Spark Streaming实时数据分析
1.Spark Streaming功能介绍
1)定义
Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams

2.NC服务安装并运行Spark Streaming
1)在线安装nc命令
yum install -y nc
2)运行Spark Streaming 的WordCount
bin/run-example streaming.NetworkWordCount localhost 9999
3)把文件通过管道作为nc的输入,然后观察spark Streaming计算结果
cat test.txt | nc -lk 9999
文件具体内容
hadoop storm spark
hbase spark flume
spark dajiangtai spark
hdfs mapreduce spark
hive hdfs solr
spark flink storm
hbase storm es
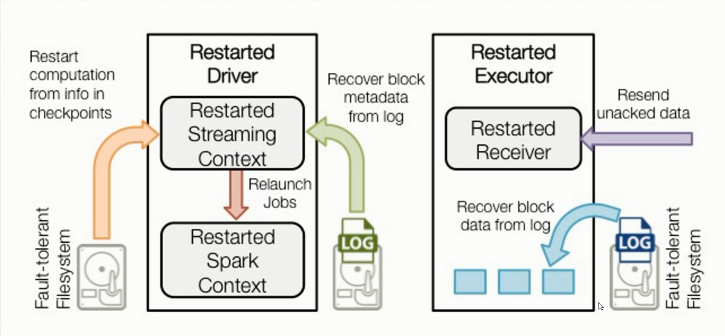
3.Spark Streaming工作原理
1)Spark Streaming数据流处理
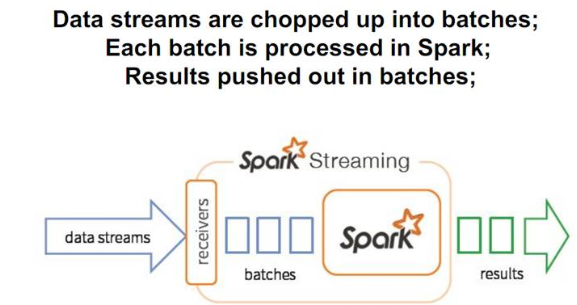
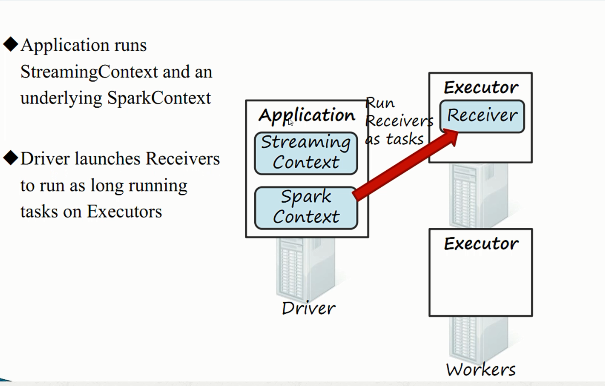
2)接收器工作原理
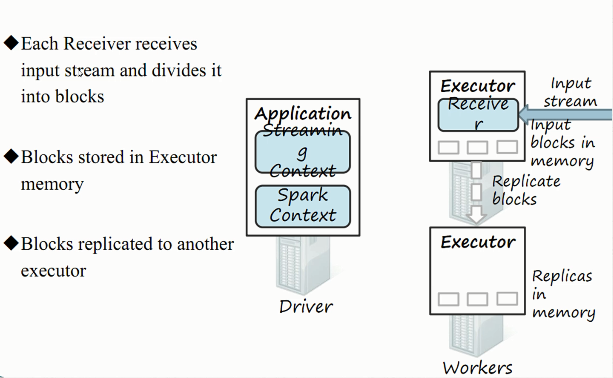
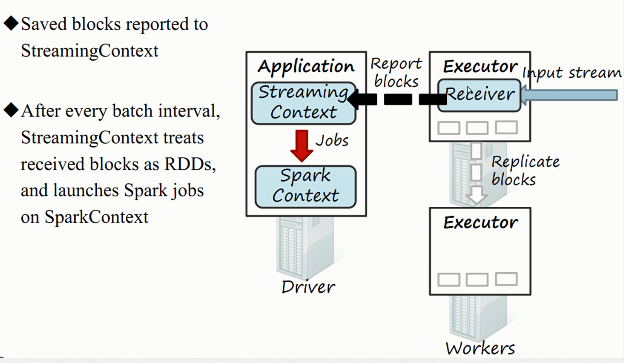
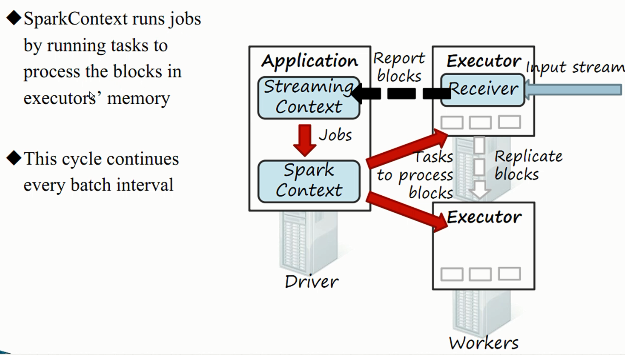
3)综合工作原理

4.Spark Streaming编程模型
1)StreamingContext初始化的两种方式
#第一种
val ssc = new StreamingContext(sc, Seconds(5))
#第二种
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
2)Spark Streaming socket代码
object NetworkWordCount {
def main(args: Array[String]) {
if (args.length < 2) {
System.err.println("Usage: NetworkWordCount ")
System.exit(1)
}
//创建StreamingContext,每秒钟计算一次
val sparkConf = new SparkConf().setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(1))
//监听网络端口,参数一:hostname 参数二:port 参数三:存储级别,创建了lines流
val lines = ssc.socketTextStream(args(0), args(1).toInt, StorageLevel.MEMORY_AND_DISK_SER)
//flatMap运算
val words = lines.flatMap(_.split(" "))
//map reduce 计算
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
5.Spark Streaming读取Socket流数据
1)spark-shell运行Streaming程序,要么线程数大于1,要么基于集群。
bin/spark-shell --master local[2]
bin/spark-shell --master spark://bigdata-pro01.kfk.com:7077
2)spark 运行模式

3)Spark Streaming读取Socket流数据
a)编写测试代码,并本地运行
object TestStreaming {
def main(args: Array[String]) {
if (args.length < 2) {
System.err.println("Usage: NetworkWordCount ")
System.exit(1)
}
val spark=SparkSession.builder().master("local[2]").setAppName("streaming").getOrCreate()
val sc = spark.SparkContext
val ssc = new StreamingContext(sc, Seconds(5))
//监听网络端口,参数一:hostname 参数二:port 参数三:存储级别,创建了lines流
val lines = ssc.socketTextStream("igdata-pro02.kfk.com", 9999, StorageLevel.MEMORY_AND_DISK_SER)
//flatMap运算
val words = lines.flatMap(_.split(" "))
//map reduce 计算
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
b)启动nc服务发送数据
nc -lk 9999
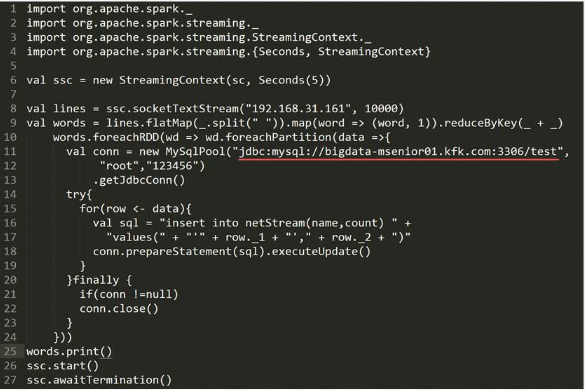
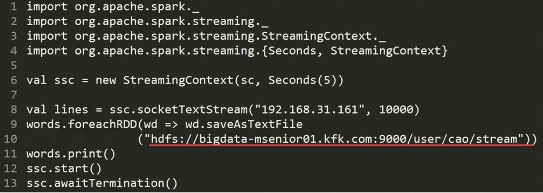
6.Spark Streaming保存数据到外部系统
1)保存到mysql数据库
2)保存到hdfs
7.Spark Streaming与Kafka集成
1)Maven引入相关依赖:spark-streaming-kafka
2)编写测试代码并启动运行
object StreamingKafka8 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[2]")
.appName("streaming").getOrCreate()
val sc =spark.sparkContext;
val ssc = new StreamingContext(sc, Seconds(5))
// Create direct kafka stream with brokers and topics
val topicsSet =Set("weblogs")
val kafkaParams = Map[String, String]("metadata.broker.list" -> "bigdata-pro01.kfk.com:9092")
val kafkaStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](
ssc, kafkaParams, topicsSet)
val lines = kafkaStream.map(x => x._2)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1L)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
3)启动Kafka服务并测试生成数据
bin/kafka-server-start.sh config/server.properties
bin/kafka-console-producer.sh --broker-list bigdata-pro01.kfk.com --topic weblogs
新闻网大数据实时分析可视化系统项目——19、Spark Streaming实时数据分析的更多相关文章
- 新闻网大数据实时分析可视化系统项目——2、linux环境准备与设置
1.Linux系统常规设置 1)设置ip地址 使用界面修改ip比较方便,如果Linux没有安装操作界面,需要使用命令:vi /etc/sysconfig/network-scripts/ifcfg-e ...
- 新闻网大数据实时分析可视化系统项目——18、Spark SQL快速离线数据分析
1.Spark SQL概述 1)Spark SQL是Spark核心功能的一部分,是在2014年4月份Spark1.0版本时发布的. 2)Spark SQL可以直接运行SQL或者HiveQL语句 3)B ...
- 新闻网大数据实时分析可视化系统项目——21、大数据Web可视化分析系统开发
1.基于业务需求的WEB系统设计 2.下载Tomcat并创建Web工程并配置相关服务 下载tomcat,解压并启动tomcat服务. 1)新建web app项目 创建好之后的效果 2)对tomcat进 ...
- 新闻网大数据实时分析可视化系统项目——15、基于IDEA环境下的Spark2.X程序开发
1.Windows开发环境配置与安装 下载IDEA并安装,可以百度一下免费文档. 2.IDEA Maven工程创建与配置 1)配置maven 2)新建Project项目 3)选择maven骨架 4)创 ...
- 新闻网大数据实时分析可视化系统项目——13、Cloudera HUE大数据可视化分析
1.Hue 概述及版本下载 1)概述 Hue是一个开源的Apache Hadoop UI系统,最早是由Cloudera Desktop演化而来,由Cloudera贡献给开源社区,它是基于Python ...
- 新闻网大数据实时分析可视化系统项目——8、Flume数据采集准备
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据:同时,Flume提供对数据进行简单处理,并 ...
- 新闻网大数据实时分析可视化系统项目——7、Kafka分布式集群部署
Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用.目前越来越多的开源分布式处理系统如Cloudera.Apache Storm.Spa ...
- 新闻网大数据实时分析可视化系统项目——4、Zookeeper分布式集群部署
ZooKeeper 是一个针对大型分布式系统的可靠协调系统:它提供的功能包括:配置维护.名字服务.分布式同步.组服务等: 它的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效.功能稳定的 ...
- 新闻网大数据实时分析可视化系统项目——14、Spark2.X环境准备、编译部署及运行
1.Spark概述 Spark 是一个用来实现快速而通用的集群计算的平台. 在速度方面, Spark 扩展了广泛使用的 MapReduce 计算模型,而且高效地支持更多计算模式,包括交互式查询和流处理 ...
随机推荐
- bootstrap中col-xs-*和col-sm-* 和col-md-*是怎么样对应的
在做布局时,有时窗体大小变化会出现非想要的效果. 栅格系统中的列是通过指定1到12的值来表示其跨越的范围 所以不会有col-**-15 最大也就是12<div class="col-s ...
- Java的下载与安装
下载Java 如果要是想聊天,那我们就需要腾讯QQ,先把它下载过来安装上,就可以聊天了,那如果是想要开发java程序呢,我们就需要下载一个开发工具包“jdk”,安装上就可以开发了.当然java是属于哪 ...
- Spring中@MapperScan注解
之前是,直接在Mapper类上面添加注解@Mapper,这种方式要求每一个mapper类都需要添加此注解,麻烦. 通过使用@MapperScan可以指定要扫描的Mapper类的包的路径,比如: @Sp ...
- Docker for windows修改默认镜像文件位置
docker版本为18.06 windows上安装的docker其实本质上还是借助与windows平台的hyper-v技术来创建一个Linux虚拟机,你执行的所有命令其实都是在这个虚拟机里执行的,所以 ...
- maven项目引用外部jar包的方法
问题描述: 有一个java maven web项目,需要引入一个第三方包gdal.jar,但是这个包是自己打包的,在maven中央库里面找不到该包,因此我采用传统的方式,将这个包拷贝到:项目名称\sr ...
- python合并大量ts文件成mp4格式(ps:上限是450,亲测)
import os #exec_str = r'copy /b ts/c9645620628078.ts+ts/c9645620628079.ts ts/1.ts' #os.system(exec_s ...
- python中的 dir()内置函数的作用以及使用方法
dir() 内置函数的作用 python 内置方法有很多,无论是初学者还是精通python 的程序员都不能全部即住所有的方法,这时候 dir() 方法就非常有用了,使用 dir()函数可以查看对象内的 ...
- listenTo - backbone.js
listenToobject.listenTo(other, event, callback) 让 object 监听 另一个(other)对象上的一个特定事件.不使用other.on(event, ...
- 119、Java中String类之通过isEmpty判断是否为空字符串
01.代码如下: package TIANPAN; /** * 此处为文档注释 * * @author 田攀 微信382477247 */ public class TestDemo { public ...
- express框架开发接口部署线上环境PM2
1.PM2介绍 PM2是一个线上环境下,用于启动nodejs进程守护的工具,用来保证服务的稳定及分摊服务器进程和压力. 2.下载安装 npm install pm2 -g => pm2 --v ...