智慧树刷网课python脚本
0x00 写在前面
疫情期间肯定有很多小伙伴需要上网课,但是有些网课我们感觉十分的鸡肋,自己不感兴趣,又必须要学
所以我写了这个刷网课的小程序,一方面是锻炼自己的爬虫技术,另一方面也给同学们节约宝贵的时间
几点说明:
1.此程序只供学习交流,请勿用于商业用途
2.当前只支持“兴趣课”的刷课,其他类型的课程还不支持
3.程序尚不完善,但是原理相通,举一反三,欢迎交流
0x01 环境准备
python3.7+requests库+selenium库+火狐浏览器
python3.7和requests库的安装不必赘述 下面来讲一下selenium库,这也是我第一次用这个库,记录一下
因为目标网站是经过js渲染的,不使用selenium库很难抓取想要的数据,selenium库可以模拟浏览器进行操作,同时可以配合各大主流浏览器,十分好用
安装:
pip install selenium
官网:http://www.seleniumhq.org
中文文档:http://selenium-python-zh.readthedocs.io
selenium可以配合PhantomJS一起使用,PhantomJS可以创建无界面浏览器,使用起来要比浏览器高效,但是这回还是先从简单的用起来吧,而且调试还是很需要界面的
对于不同的浏览器,需要安装不同的驱动:
Chrome的驱动chromedriver 下载地址:http://chromedriver.storage.googleapis.com/index.html
Firefox的驱动geckodriver 下载地址:https://github.com/mozilla/geckodriver/releases/
IE的驱动IEdriver 下载地址:https://www.nuget.org/packages/Selenium.WebDriver.IEDriver/
我使用的是火狐浏览器,所以直接下载Firefox的驱动:
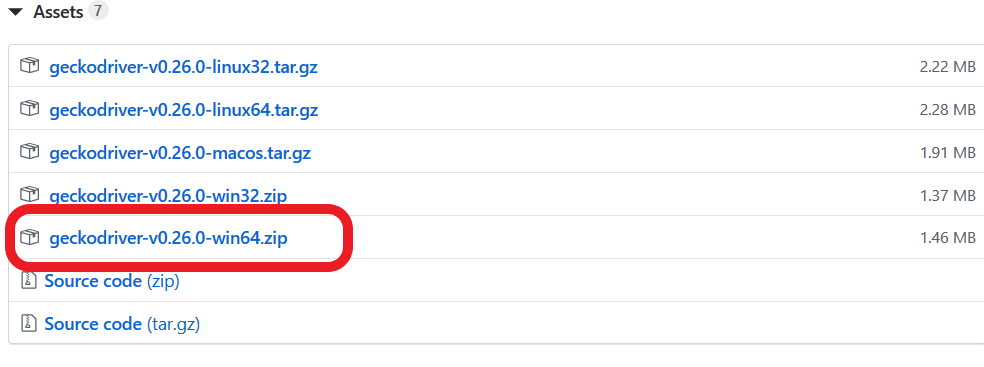
下载解压后,将geckodriver.exe添加到python的根目录下,其他浏览器也是一样,添加到python根目录下即可
0x02 核心原理
现在环境已经准备好了,开始研究刷课的原理
根据Firefox抓包可以发现:
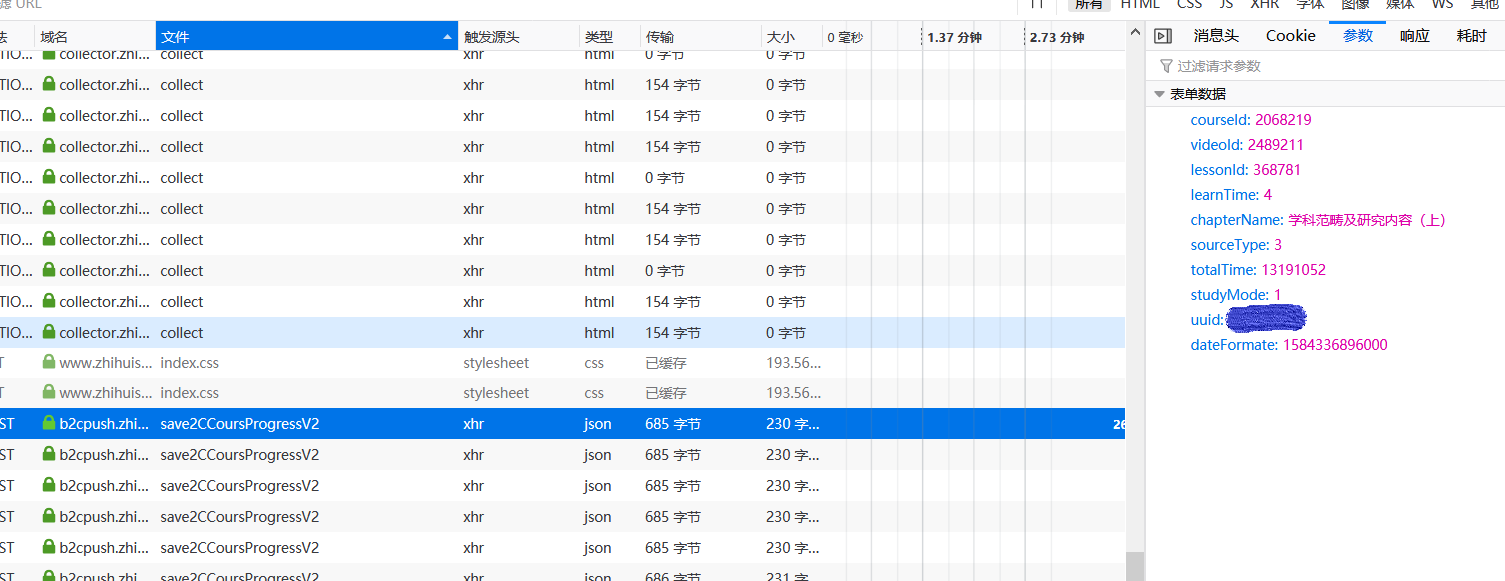
经过实验,我发现当每次用户离开当前界面(例如播放下一个视频、关闭网页)的时候,js都会向服务器发送一个名为save2CCoursProgressV2的post请求,这个包的参数是这样的:
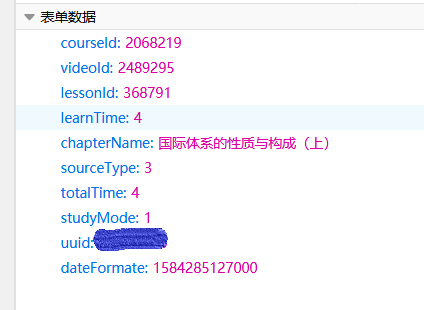
这些参数直接看名字就能知道是什么含义,最重要的参数就是learnTime和totalTime,应该是你观看视频的时间和待在当前界面的时间
所以只要我们构造这个save2CCoursProgressV2包,然后把相关的参数都填好,把learnTime和totalTime设置为一个很大的数,这样服务器就会认为你学习了很长很长时间
而且参数里面的uuid直接标注了用户的id,所以发这个包的时候甚至不需要cookie来认证,直接post就好了
但是需要注意的是,我们从哪里获取videoid和lessonid呢?如果id不对的话也是无法记录时间的
经过查找我发现,videoid并不是静态的存在网页中,js只会解析出当前播放的视频的videoid,这一点我会在后面的实现过程中详细说明
所以我们的工作还包括一个收集videoid和lessonid的过程
这就是本程序的核心原理,直接构造统计视频观看时长的数据包(其中相关参数需要收集),发送到服务器,从而避免浪费大量的时间来观看视频
0x03 实现过程
了解了实现的原理,就只差实现过程了
首先要初始化一个firefox浏览器:
browser = webdriver. Firefox()
尝试进入智慧树的学生主页:
browser.get('https://onlineh5.zhihuishu.com/onlineWeb.html#/studentIndex')
发现要模拟登陆,不过幸运的是,智慧树登陆不需要验证码,可以直接用selenium进行登陆,否则的话就需要拿到cookie再发送请求了:
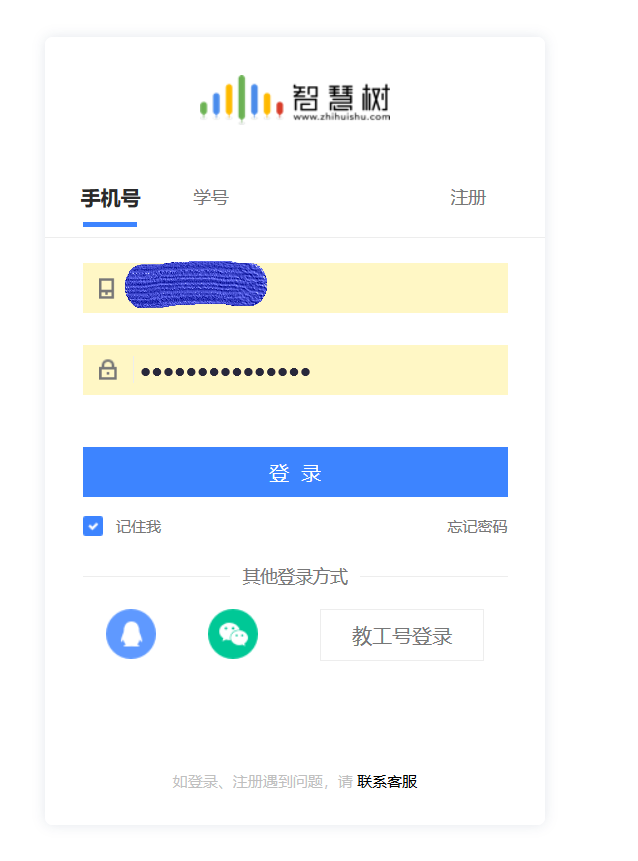
没有验证码,这一步就很简单,用selenium把用户名和密码填上,然后模拟浏览器去点击登陆按钮即可
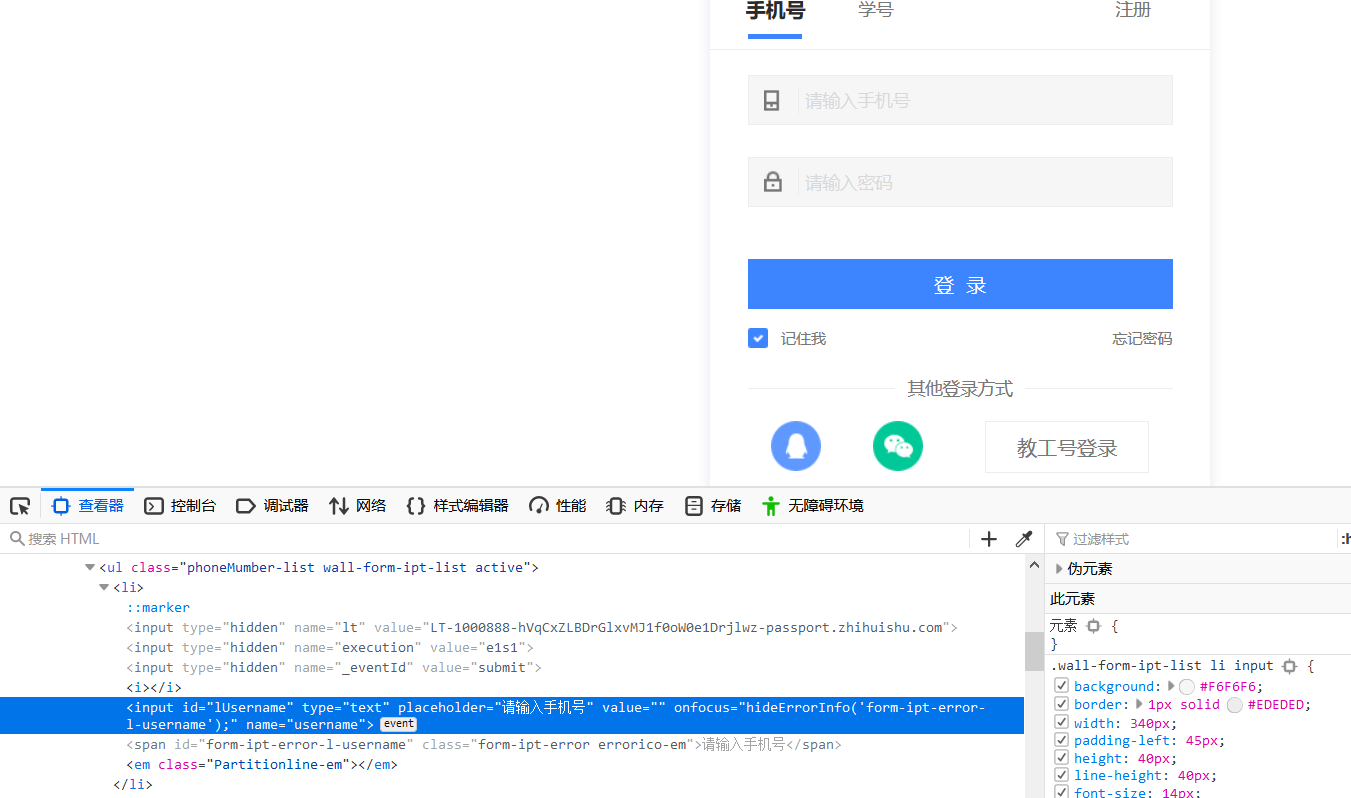
可以看到输入用户名这里,有一个id属性,值是 lUsername ,所以可以直接通过id定位用户名输入框,同理密码也是一样:
usrname=browser.find_element_by_id('lUsername') #定位输入框
password=browser.find_element_by_id('lPassword')
usrname.send_keys('XXXXXX') #输入自己的用户名和密码
password.send_keys('XXXXXX')
登陆按钮:

可以看到按钮的class属性为 wall-sub-btn 所以也可以直接定位 然后模拟点击:
signin=browser.find_element_by_class_name('wall-sub-btn').click()
做到这一步就可以直接进入学生主页了,可以看到自己选修的课程:
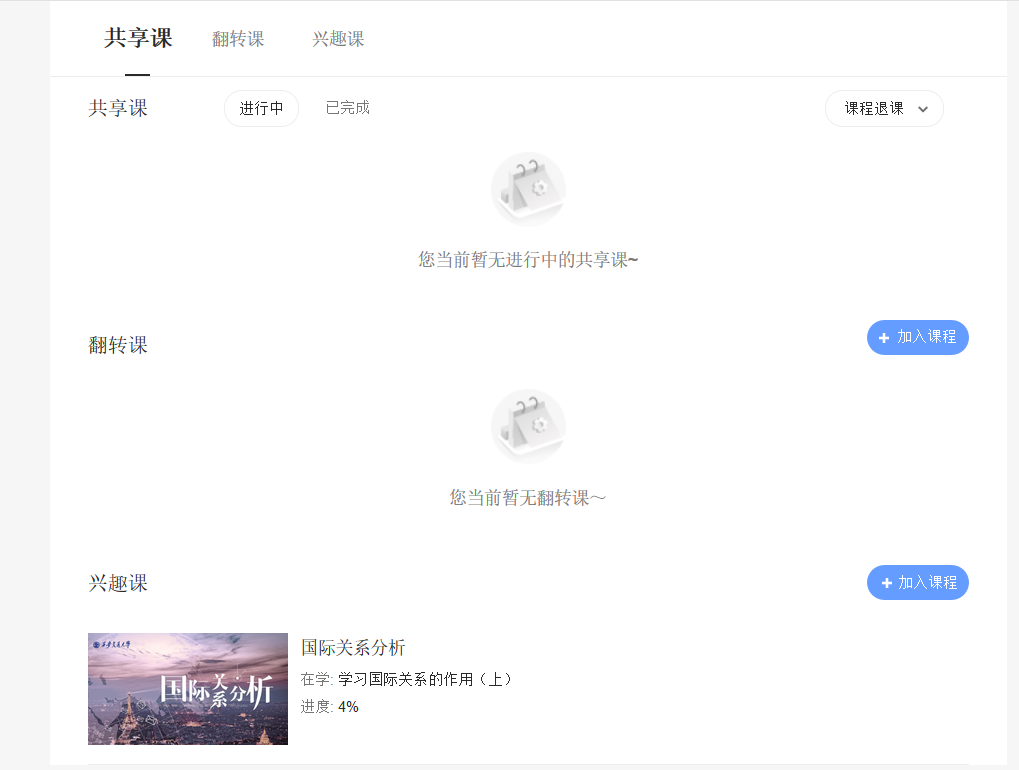
下一步就是点开我要上的课:
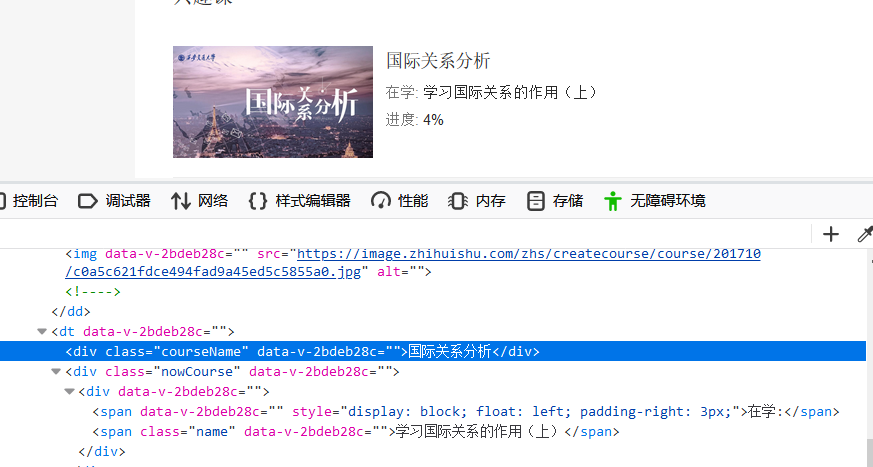
可以看到class属性值为 courseName 直接模拟点击就可以了:
watch=browser.find_element_by_class_name('courseName').click()
但是需要注意的是,在这个语句之前,需要加上一个等待时间,必须等到网页加载完成了之后才能点击,否则有可能根本就找不到这个按钮
等待的方法有很多种,我直接用了最简单暴力的sleep(因为其他的方法不会...)
time.sleep(5)
watch=browser.find_element_by_class_name('courseName').click()
等待五秒钟后再点击就好了,不过要是实在网速不行,5秒也是有可能失败的....
之后就会出现一个弹窗:

这里必须要把它点掉,也是和之前模拟点击按钮一样的操作
signin=browser.find_element_by_class_name('know').click()
点击完之后,就可以搜集我们想要的东西了(这里最好也加个sleep,给浏览器一点反应的时间)
首先是videoid,videoid怎么找呢?直接ctrl+F: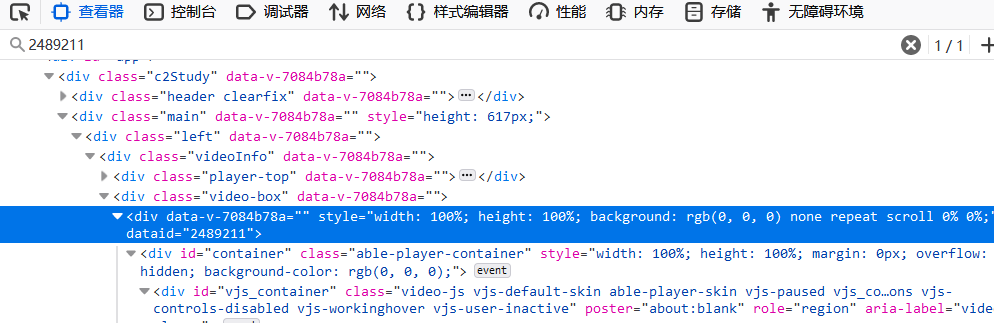
就可以定位到当前视频的videoid了,但是这个路径用之前找id属性或者class属性的话不是很好找,所以使用css选择器的方法 find_element_by_css_selector 定位到这里,
然后再用get_attribute方法得到dataid的值,也就是videoid
复制css选择器:

可以得到:.video-box > div:nth-child(1)
然后用这个值去定位,然后get参数即可:
videoid=browser.find_element_by_css_selector(".video-box > div:nth-child(1)").get_attribute("dataid")
现在有了videoid,那么lessonid在哪呢?
直接看右边的视频选择栏的代码,我们可以看到所有的lessonid都整整齐齐的写在这里:

所以我们只需要遍历每一个class="lessonItem"的模块,获取lessonid后点击这个视频,再获取这个视频的videoid,这样最关键的两个id我们就都可以获得了:
classlist=browser.find_elements_by_class_name('lessonItem')
for now in classlist:
classid=now.get_attribute('id')
classtitle=now.find_element_by_class_name("lessonName").text
now.click()
time.sleep(1)
videoid=browser.find_element_by_css_selector(".video-box > div:nth-child(1)").get_attribute("dataid")
这里需要注意的,是第一行和第四行的find方法有略微的不同,第一行element后面还有一个s,这样可以抓取到到一个列表,否则是选择第一个
然后就可以直接构造post请求发送save2CCoursProgressV2包了
ps:save2CCoursProgressV2包的最后一个参数是毫秒级时间戳,但是time方法获得的是秒级的时间戳,需要转化一下:
import time
t = time.time() #秒级时间戳
T=int(round(t * 1000)) #毫秒级时间戳
post请求(注意这里的url和之前的不一样,可以通过分析save2CCoursProgressV2包来获得):
post_url='https://b2cpush.zhihuishu.com/b2cpush/courseDetail/save2CCoursProgressV2'
post_data = {
'courseId': '', #courseid可以直接在当前url里面找到
'videoId':videoid,
'lessonId':classid,
'learnTime':'',
'chapterName':classtitle,
'sourceType':'',
'totalTime':'',
'studyMode':'',
'uuid':'XXXXX', #用户id,但不是用户名
'dateFormate':int(round(t * 1000)) #毫秒级时间戳
}
r=requests.post(post_url,post_data)
print(r.status_code) #输出状态码
这样就大功告成了!
0x04 最终代码
from selenium import webdriver
import time
import requests
post_url='https://b2cpush.zhihuishu.com/b2cpush/courseDetail/save2CCoursProgressV2'
browser = webdriver. Firefox()
browser.get('https://onlineh5.zhihuishu.com/onlineWeb.html#/studentIndex')
usrname=browser.find_element_by_id('lUsername')
password=browser.find_element_by_id('lPassword')
usrname.send_keys('xxxxxx') #用户名和密码
password.send_keys('xxxxxx')
signin=browser.find_element_by_class_name('wall-sub-btn').click()
time.sleep(5) #停一下 等页面加载完毕
watch=browser.find_element_by_class_name('courseName').click()
time.sleep(2)
signin=browser.find_element_by_class_name('know').click()
time.sleep(2)
videoid=browser.find_element_by_css_selector(".video-box > div:nth-child(1)").get_attribute("dataid")
classlist=browser.find_elements_by_class_name('lessonItem')
for now in classlist:
classid=now.get_attribute('id')
classtitle=now.find_element_by_class_name("lessonName").text
now.click()
time.sleep(1)
videoid=browser.find_element_by_css_selector(".video-box > div:nth-child(1)").get_attribute("dataid")
t = time.time()
post_data = {
'courseId':'', #可以根据url获得
'videoId':videoid,
'lessonId':classid,
'learnTime':'', #设置为足够大
'chapterName':classtitle, #视频标题
'sourceType':'',
'totalTime':'',
'studyMode':'',
'uuid':'xxxx', #uuid可以通过找其他save2CCoursProgressV2包来获得
'dateFormate':int(round(t * 1000)) #毫秒级时间戳
}
r=requests.post(post_url,post_data)
print(r.status_code)
0x05 总结
这个程序写的还是比较简陋的,只支持了“兴趣课”,其他的课程由于网页格式不一样,应该是不适用的,而且courseId还需要手动看url来获得:
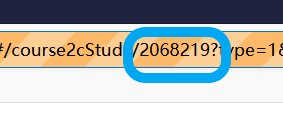
uuid也是通过查找save2CCoursProgressV2包获取的,不够智能化自动化,还需要好好打磨
若是学生选修了多门课程,那么在学生界面选择课程的语句也需要稍稍更改了,改成find_elements而不是find_element
不过这都是细节问题了,核心的登录、收集id信息、发送统计时长都做出来了,也亲测有效:

若是觉得效率不够,可以选择加多线程或者是PhantomJS来提高效率~~
这次学习到了很多selenium的用法,也是受益匪浅
智慧树刷网课python脚本的更多相关文章
- php编写刷网课自助下单系统(第三方支付实例)
此项目是由于本人刚刚入门php且在校代刷网课而编写的,由于在上课时间不方便接单,故特意写一个自助下单系统来实现客户自助下单.本项目主要实现以下功能:1.用户下单2.用户支付3.用户通过账号查询订单4. ...
- CSDN不限积分代下载,知网、万方、sci、IEEE论文代下载,智慧树、超星尔雅刷课
下载内容: 1.CSDN不限积分代下载. 2.知网.万方.sci.IEEE论文代下载. 3.超星尔雅,智慧树刷课. 注:由于本人手抖买一个CSDN会员,想挽回一点损失,所以创立了一个下载群,绝对不是骗 ...
- python网课自动刷课程序-------selenium+chromedriver
python的强大之处就在于有许多已经写好的功能库提供,这些库强大且易用,对于写一些有特定功能的小程序十分方便. 现在就用pyhton的selenium+谷歌游览器写一个可以自动刷课的程序,以智慧树上 ...
- 网课应该这么刷(油猴Tampermonkey脚本自动刷课)
懒人福利 首先有些人不想学怎么用脚本,满足你们,压缩包解压之后直接登录即可.戳我下载 脚本已经集成好了,登录即可刷课.章节测试还会自动答题呦,正确率高达97%呦. 油猴及脚本安装 油猴的脚本不知可以刷 ...
- 用Python来自动刷智慧树网站的网课
学校最近让看什么网课,智慧树网站的,太无聊了,写个脚本刷下,这里是用Python+selenium实现的,也可以用js脚本,更简单,但是我这里刚好最近在学python,就顺便练习下,说下有几个点, 1 ...
- 使用python的selenium库刷超星网课
网课很多看不完呀 所以动手做了一个基础的自动答题和下一节的程序 用到了python 3 selenium Chrome 如何自动化Chrome?https://www.cnblogs.com/eter ...
- [Windows] 智慧职教刷课软件(职教雨滴1.9更新完成)
(智慧职教刷课软件-职教雨滴)支持职教云(云课堂)的课程 2019年10月17日 16:19:57 增加支持资料库,MOOC 点击链接加入群聊[职教雨滴反馈群]:https://jq.qq.com/? ...
- 使用Python脚本分析你的网站上的SEO元素
撰稿马尼克斯德芒克 上2019年1月, Sooda internetbureau Python就是自动执行重复性任务,为您的其他搜索引擎优化(SEO)工作留出更多时间.没有多少SEO使用Python来 ...
- 推荐书单(网课)-人生/编程/Python/机器学习-130本
目录 总计(130本) 一.在读 二.将读 三.已读 非专业书单(77本) 四.已读 专业书单(53本) 五.已看网课(8个) 六.在看网课 一个人如果抱着义务的意识去读书,便不了解读书的艺术.--林 ...
随机推荐
- linux 下安装及查看java的安装路径
一.Linux下安装JDK 1.下载文件 从官网下载合适版本如:jdk-8u191-linux-x64.tar.gz 2.安装文件 1.在 /usr/ 目录下创建 java文件夹mkdir /usr/ ...
- Mac环境下安装Redis
转自:http://www.jianshu.com/p/6b5eca8d908b -安装 下载安装包 redis-3.0.7.tar.gz 官网地址:http://redis.io/download ...
- mysql挖掘与探索--表操作命令 1
1.登录数据库>mysql -u root -p 数据库名称 2.查询所有数据表>show tables; 3.查询表的字段信息>desc 表名称; 4.1添加表字段 alter t ...
- MSSS攝影大賽計劃書(第三版)
比賽內容:對香港的城市風景以及自然風光的攝影 預期成果: 提升同學對香港的認識,鼓勵學生走出大學學園去瞭解香港,同時豐富會員的課餘活動,培養同學的興趣愛好 比賽時間:4月1-15日 最後作品提交時間: ...
- 93)PHP,session代码练习
(1)开启session Session_start(): (2)session值的设定: <?php session_start(); $_SESSION['name']='xiaohua'; ...
- Java 内部类(成员内部类、局部内部类、静态内部类,匿名内部类)
一.什么是内部类? 内部类是指在一个外部类的内部再定义一个类.内部类作为外部类的一个成员,并且依附于外部类而存在的.内部类可为静态,可用protected和private修饰(而外部类只能使用publ ...
- 华为VS小米 营销手段有待继续强化
营销手段有待继续强化" title="华为VS小米 营销手段有待继续强化"> 对于大多数来说,希望看到强者愈强的戏码.比如:NBA里的N场连胜.苹果帝国千秋万载一统 ...
- Python 搭建webdriver环境遇到的问题总结
安装过程是参考<selenium2Python自动化测试实战>中Pythonwebdriver环境搭建章节 在安装过程中,遇到了一些问题,总结一下,为日后自己再遇到相同问题做个笔记以便查看 ...
- js javascript 获取url,获得当前页面的url,静态html文件js读取url参数
获得当前页面的url window.location.href 静态html文件js读取url参数 location.search; //获取url中"?"符后的字串 下边为转载的 ...
- APP内计费规范出台 手游乱收费现象能被遏制?
手游乱收费现象能被遏制?" title="APP内计费规范出台 手游乱收费现象能被遏制?"> 在一个混乱.无秩序的环境中竞争,虽然有可能不择手段地获取更多的利益,但 ...