Spark入门(二)--如何用Idea运行我们的Spark项目
用Idea搭建我们的Spark环境
用IDEA搭建我们的环境有很多好处,其中最大的好处,就是我们甚至可以在工程当中直接运行、调试我们的代码,在控制台输出我们的结果。或者可以逐行跟踪代码,了解spark运行的机制。因此我们选择了idea,当然Idea不是首选,当然也可以用其他工具。因为我们的Spark程序用scala和java写,需要有java环境来作为支撑。因此任何能够支撑java程序的开发工具,应该都能够搭建我们的Spark程序。我这里是MAC环境下,当然如果你是windows不用担心,这里只涉及到idea的操作,不涉及操作系统环境的更改,所以你无须担心,因为Idea在Mac下和windows下并无多大差别
第一步,下载插件,如果你只想用Java而不想用Scala,则可以跳过这一步
在preference中找到plugins,搜索scala,然后下载该插件
第二步,创建maven项目
第三步,导入scala的SDK,如果你只想用Java而不想用Scala,则可以跳过这一步
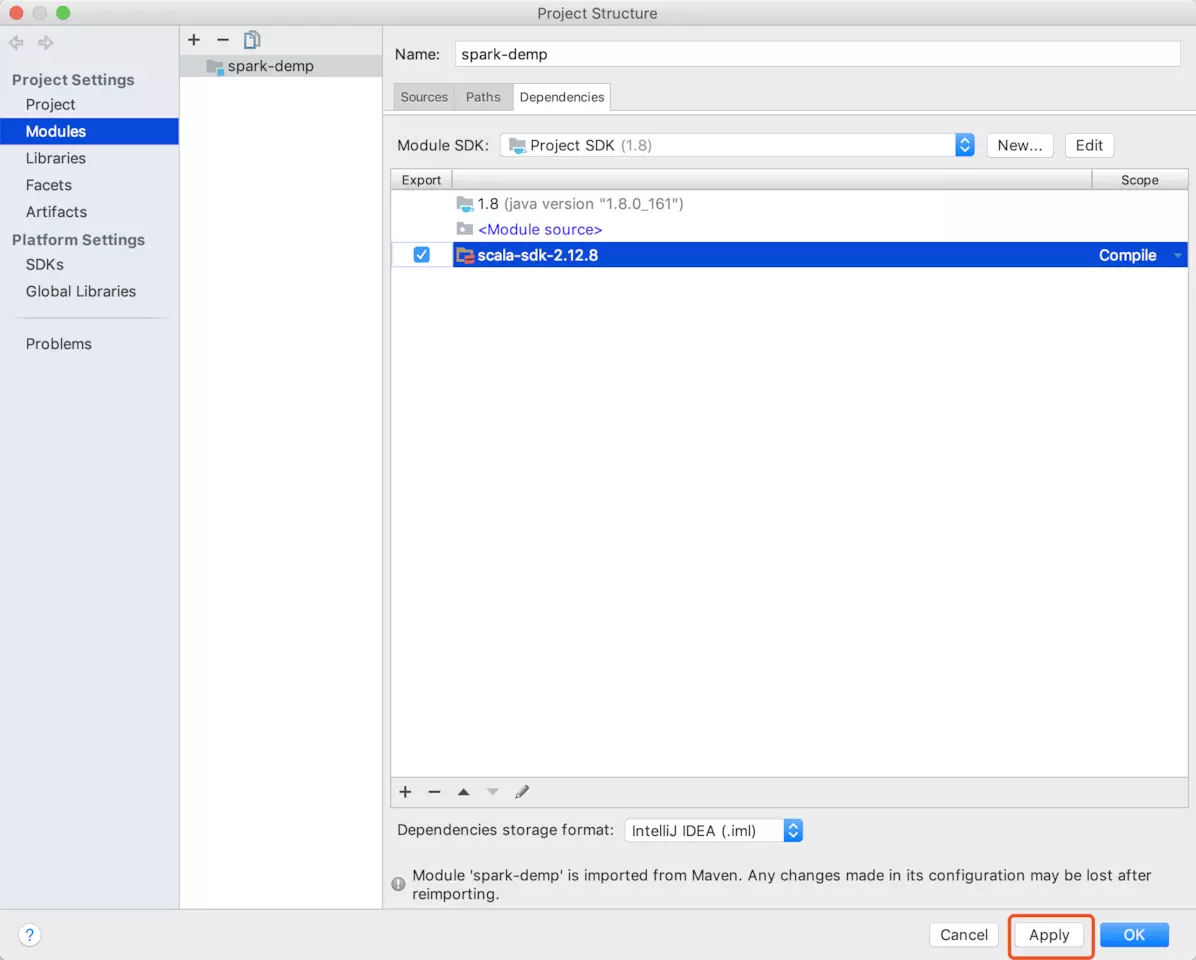
打开project structure
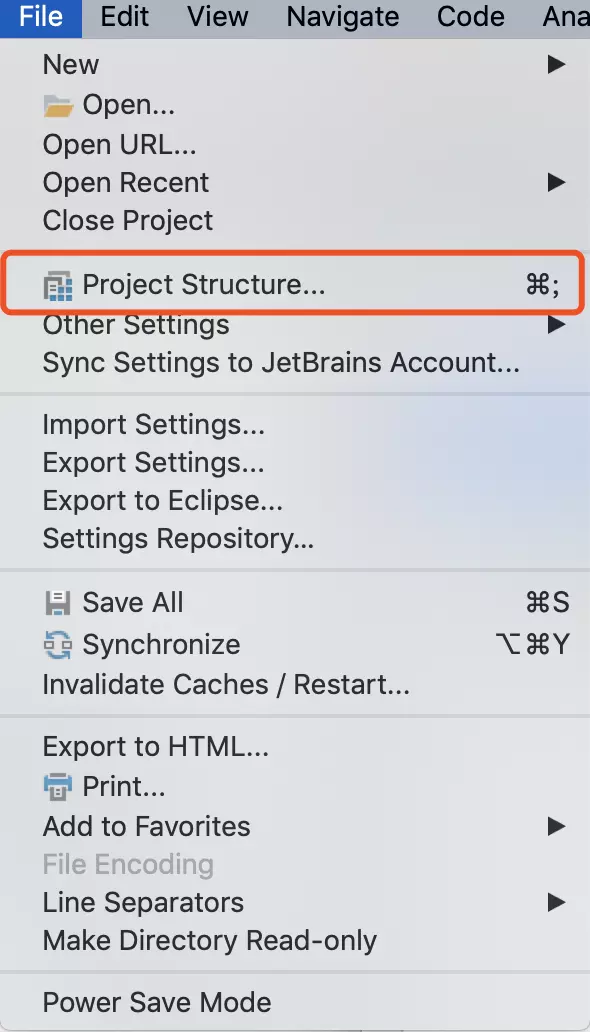
导入SDK
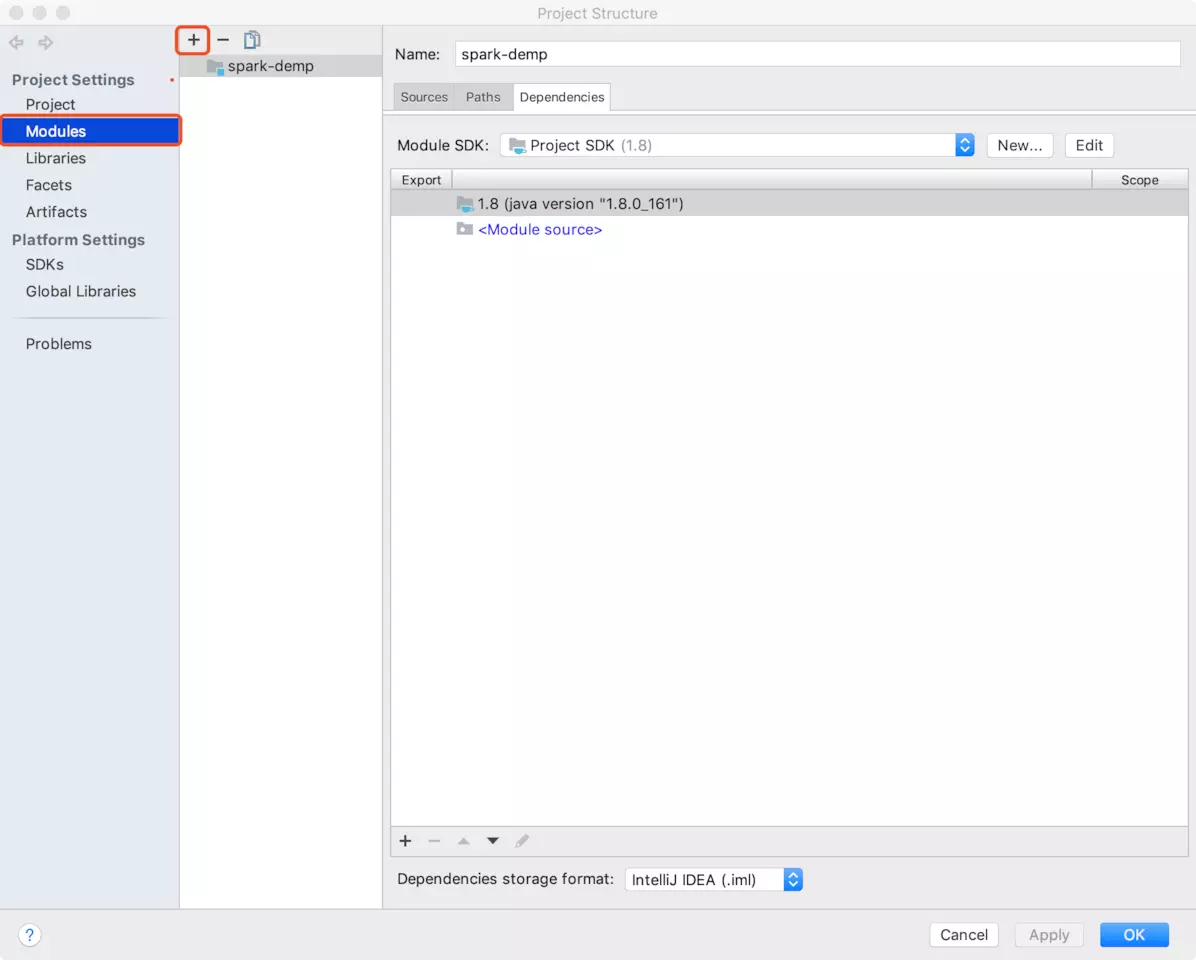
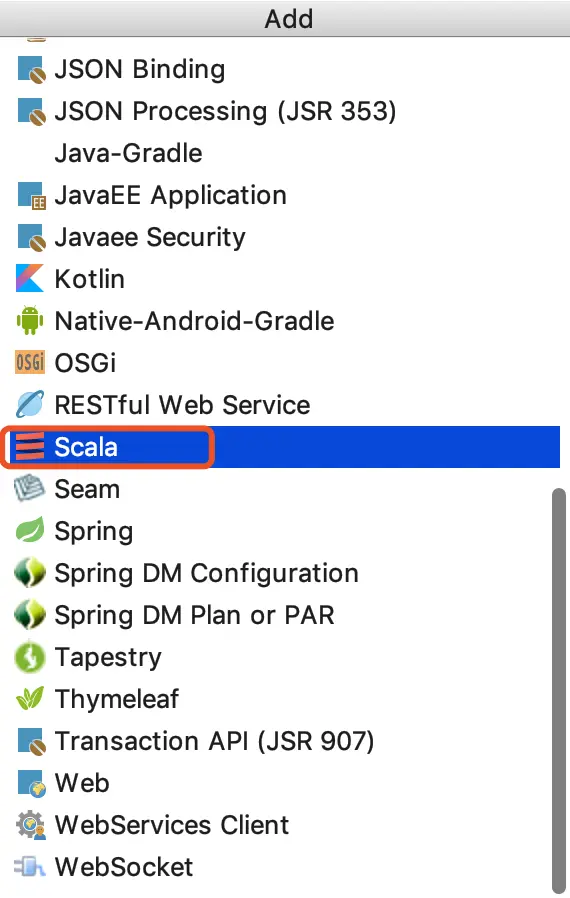
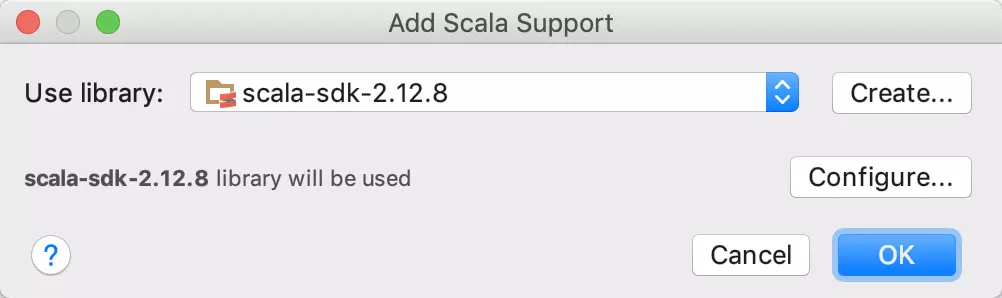
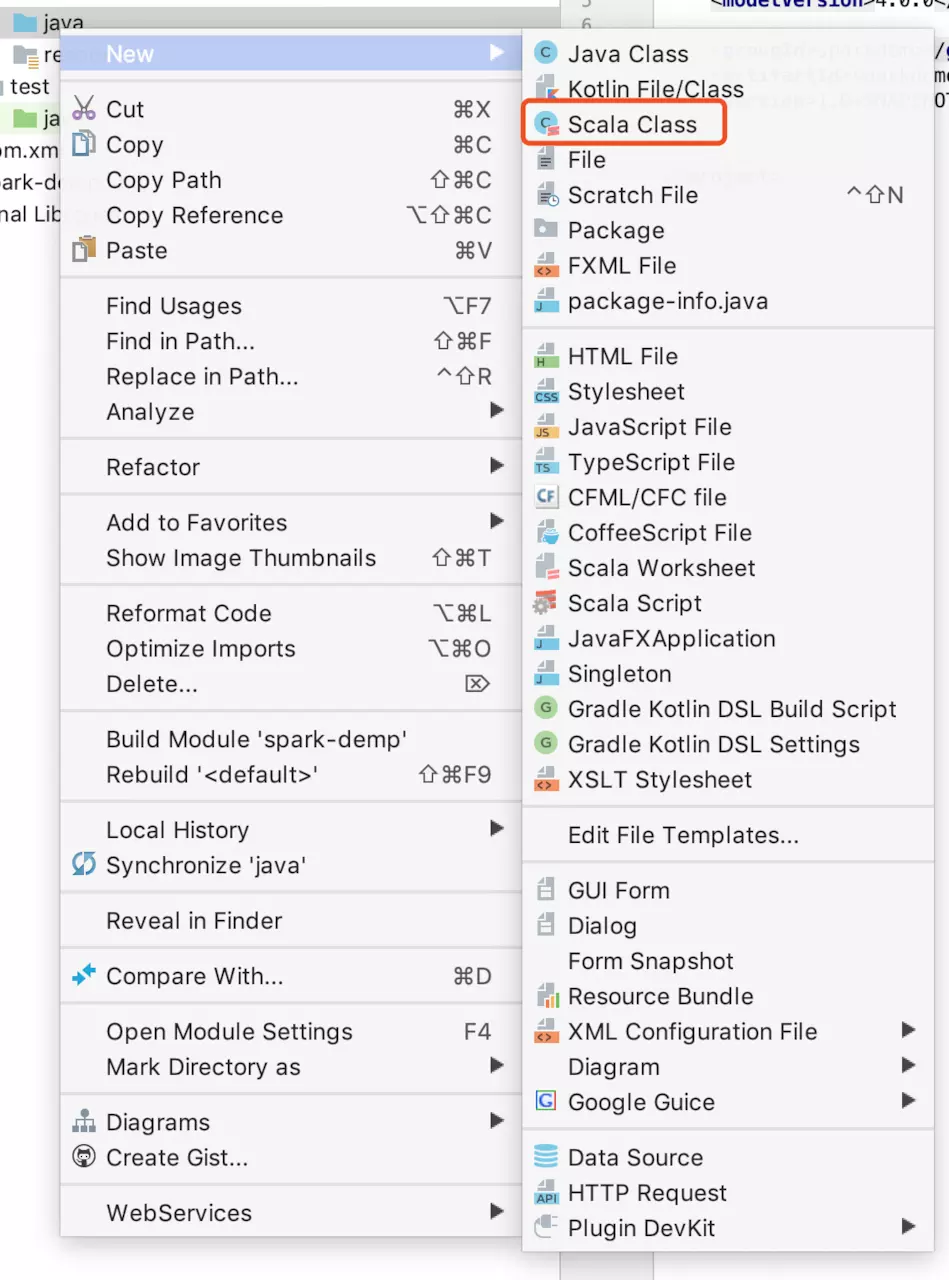
此时可以创建Scala的class文件了
第四步,在pom中导入插件和依赖
插件主要是帮助打包scala包,方便再spark平台上发布我们的程序。当然仅仅最开始我们尽可能将项目运行在idea中,而不需要发布。依赖是spark运行所必须的jar,其中spark的核心spark-core主要是用scala编写的,当然你也能够用java去使用。
在pom文件中导入
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>sparkdemo</groupId>
<artifactId>sparkdemo</artifactId>
<version>1.0-SNAPSHOT</version>
<build>
<finalName>HiveTest</finalName>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.8.4</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.11</artifactId>
<version>2.1.3</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.20</version>
</dependency>
</dependencies>
</project>
第五步,运行我们的第一个程序
当我们学习任何一项技术的时候,我们都有一个爱好,喜欢先输出Hello,World!在Spark中亦是如此,我们第一个项目也是Hello,World!当然很多人说,spark的Hello,World!应该是字数统计(即统计一本书的或者一个文件的单词数)。当然这也没错,毕竟spark的最核心的功能是大数据和机器学习,但是对一个初学者来说,我认为,不妨再简单些。
创建Scala文件
接下来可以开始写我们的第一个第一个程序。
首先创建一个SparkConf(),即spark的基础配置,主要设置了master为“local”即运行在本机而非集群,第二个是AppName。而后创建SparkContext,这里取名为sc和我们在spark-shell中默认的一致。最后为sc设置内容,即一个list,其中包含三句话。依次输出三句话
scala实现
package spark
import org.apache.spark.{SparkConf, SparkContext}
object HelloWorld {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("HelloWorld")
val sc = new SparkContext(conf)
val helloWorld = sc.parallelize(List("Hello,World!","Hello,Spark!","Hello,BigData!"))
helloWorld.foreach(line => println(line))
}
}
运行得到:
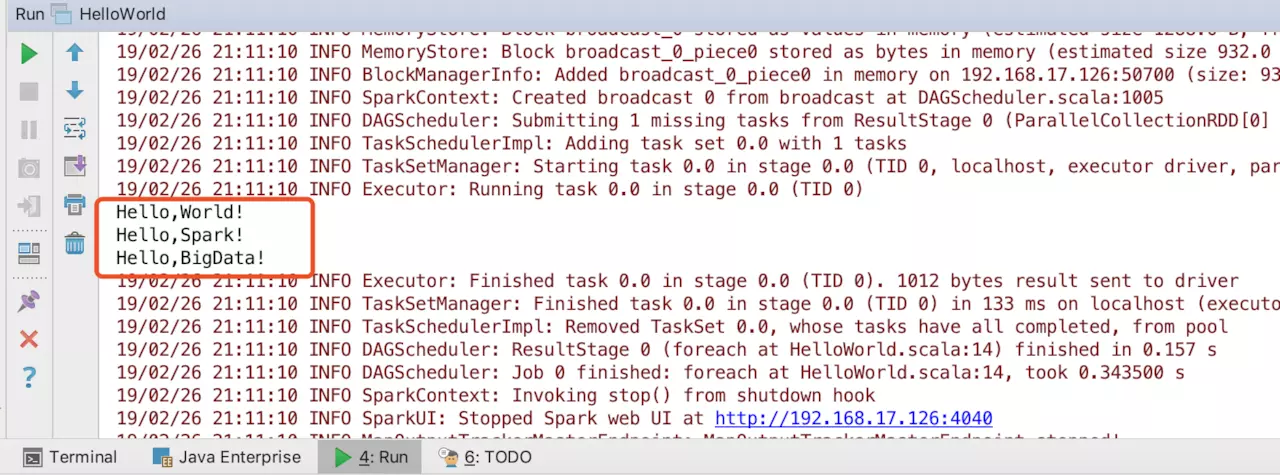
Hello,World!
Hello,Spark!
Hello,BigData!
java实现
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext; import java.util.Arrays; public class HelloWorldJava { public static void main(String[] args){ SparkConf conf = new SparkConf().setMaster("local").setAppName("HelloWorldJava"); JavaSparkContext sc = new JavaSparkContext(conf); JavaRDD<String> helloWorld = sc.parallelize(Arrays.asList("Hello,World","Hello,Spark","Hello,BigData")); System.out.println(helloWorld.collect()); } }
运行得到:
[Hello,World, Hello,Spark, Hello,BigData]
python实现
from pyspark import SparkConf,SparkContext
conf = SparkConf().setMaster("local").setAppName("HelloWorld")
sc = SparkContext(conf=conf)
helloWorld = sc.parallelize(["Hello,World","Hello,Spark","Hello,BigData"]).collect()
print(helloWorld)
运行得到:
['Hello,World', 'Hello,Spark', 'Hello,BigData']
至此我们就在scala、java、python中运行了我们的第一个spark程序。当然,我们可以选择自己最上手的语言去写spark程序,spark本身也非常良好地支持了这三种语言。因此不要让语言成为障碍,反而因此获得更多的选择。无论是java、scala还是python都能写出良好运行的spark程序
转自:https://juejin.im/post/5c752f87f265da2dbb123bc9
Spark入门(二)--如何用Idea运行我们的Spark项目的更多相关文章
- Spark入门实战系列--6.SparkSQL(下)--Spark实战应用
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .运行环境说明 1.1 硬软件环境 线程,主频2.2G,10G内存 l 虚拟软件:VMwa ...
- spark本地环境的搭建到运行第一个spark程序
搭建spark本地环境 搭建Java环境 (1)到官网下载JDK 官网链接:https://www.oracle.com/technetwork/java/javase/downloads/jdk8- ...
- Spark入门(一)--用Spark-Shell初尝Spark滋味
Spark-Shell的使用 执行scala命令的spark-shell 进入spark的sbin目录,打开键入 ./spark-shell 即可进入spark-shell的目录 spark-shel ...
- PyCharm入门第一步-——创建并运行第一个Python项目
创建项目 点击Create New Project 创建项目 输入自己的项目名,点击Create创建 创建文件 右键项目名创建python文件 创建一个HelloPython文件 输入print(&q ...
- 如何用eclipse运行导入的maven项目
1.配置jdk系统环境变量.找到安装的jdk的安装目录,新建系统环境变量,变量名为JAVA_HOME(作为一个引用),变量值为该路径. 找到Path,将%JAVA_HOME%/bin; 添加到变量值的 ...
- Spark入门实战系列--2.Spark编译与部署(上)--基础环境搭建
[注] 1.该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取: 2.Spark编译与部署将以CentOS 64位操作系统为基础,主要是考虑到实际应用 ...
- Spark入门实战系列--4.Spark运行架构
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 1. Spark运行架构 1.1 术语定义 lApplication:Spark Appli ...
- Spark入门实战系列--6.SparkSQL(中)--深入了解SparkSQL运行计划及调优
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 1.1 运行环境说明 1.1.1 硬软件环境 线程,主频2.2G,10G内存 l 虚拟软 ...
- openfire:Openfire源代码在eclipse中的运行配置 + 与spark结合进行二次开发
1.下载源代码:http://www.igniterealtime.org/downloads/source.jsp 2.把源代码解压出的openfire_src文件夹放至eclipse workpl ...
随机推荐
- Kintinuous解析
版权声明:本文为博主原创文章,未经博主允许不得转载. Kintinuous是Thomas Whelan在National University of Ireland Maynooth读博期间的工作,有 ...
- struts 2.1.8.1的sx:datetimepicker标签出现NaN错误的原因和解决办法
作者:Junsan.Jin 邮箱:junsanjin@gmail.com QQ:1305896503 本文原始地址:http://www.rsky.com.cn/Article/java/201 ...
- 93)PHP,session代码练习
(1)开启session Session_start(): (2)session值的设定: <?php session_start(); $_SESSION['name']='xiaohua'; ...
- java 内存溢出-与gc
感谢原作者 在日常中我们经常遇到这样的错误:java.lang.OutOfMemoryError: Java heap space. 但是除了heap space 的OutOfMemoryError, ...
- OpenCV Mat - 基本图像容器
Mat 在2001年刚刚出现的时候,OpenCV基于 C 语言接口而建.为了在内存(memory)中存放图像,当时采用名为 IplImage 的C语言结构体,时至今日这仍出现在大多数的旧版教程和教学材 ...
- C# 内置的类型转换方法
C# 提供了下列内置的类型转换方法: 序号 方法 & 描述 1 ToBoolean把类型转换为布尔型. 2 ToByte把类型转换为字节类型. 3 ToChar如果可能的话,把类型转换为单个 ...
- FileZilla相关配置说明
相关下载可以直接到官网,或者阿里云帮助:https://help.aliyun.com/knowledge_detail/36243.html?spm=5176.10695662.1996646101 ...
- CDC与HDC的区别以及相互转换
CDC是MFC的DC的一个类 HDC是DC的句柄,API中的一个类似指针的数据类型. MFC类的前缀都是C开头的 H开头的大多数是句柄 这是为了助记,是编程读\写代码的好的习惯. CDC中所 ...
- 国产ROM纷争升级 能否诞生终结者?
能否诞生终结者?" title="国产ROM纷争升级 能否诞生终结者?"> 相比iOS系统的低硬件高流畅,安卓系统就显得"逼格"低了许多.先不说 ...
- [CF1009F] Dominant Indices (+dsu on tree详解)
这道题用到了dsu(Disjoint Set Union) on tree,树上启发式合并. 先看了CF的官方英文题解,又看了看zwz大佬的题解,差不多理解了dsu on tree的算法. 但是时间复 ...