利用Python爬取OPGG上英雄联盟英雄胜率及选取率信息
一、分析网站内容
本次爬取网站为opgg,网址为:” http://www.op.gg/champion/statistics”
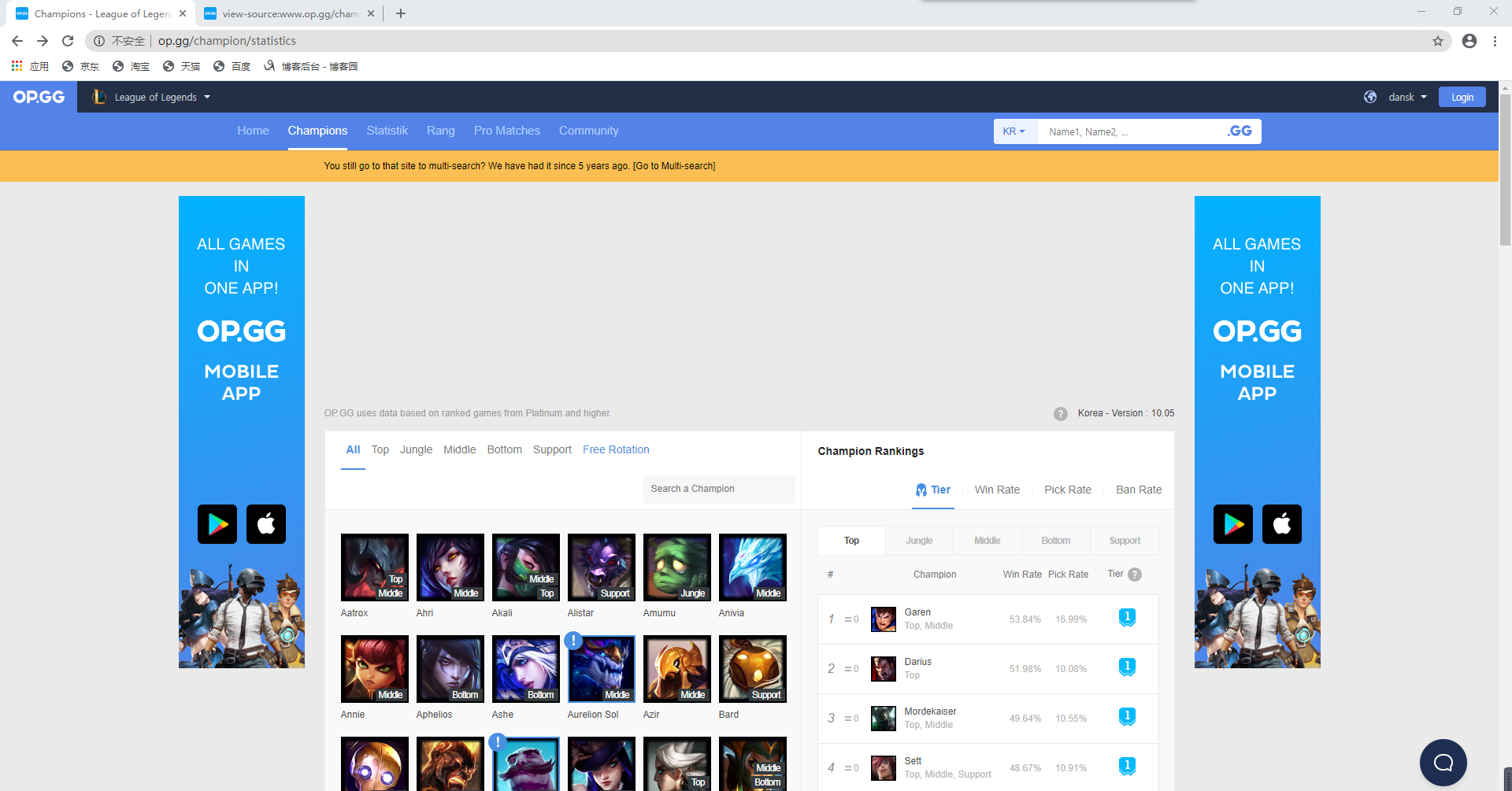
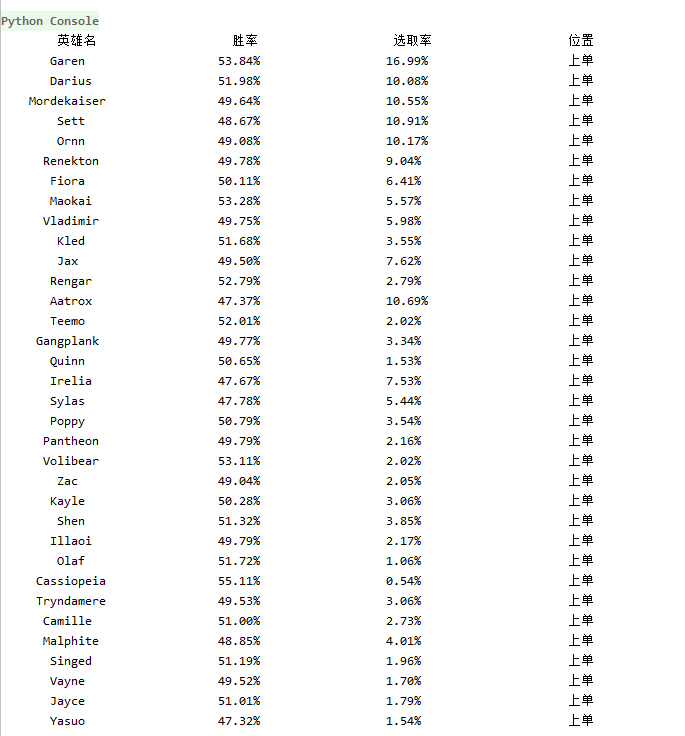
由网站界面可以看出,右侧有英雄的详细信息,以Garen为例,胜率为53.84%,选取率为16.99%,常用位置为上单
现对网页源代码进行分析(右键鼠标在菜单中即可找到查看网页源代码)。通过查找“53.84%”快速定位Garen所在位置
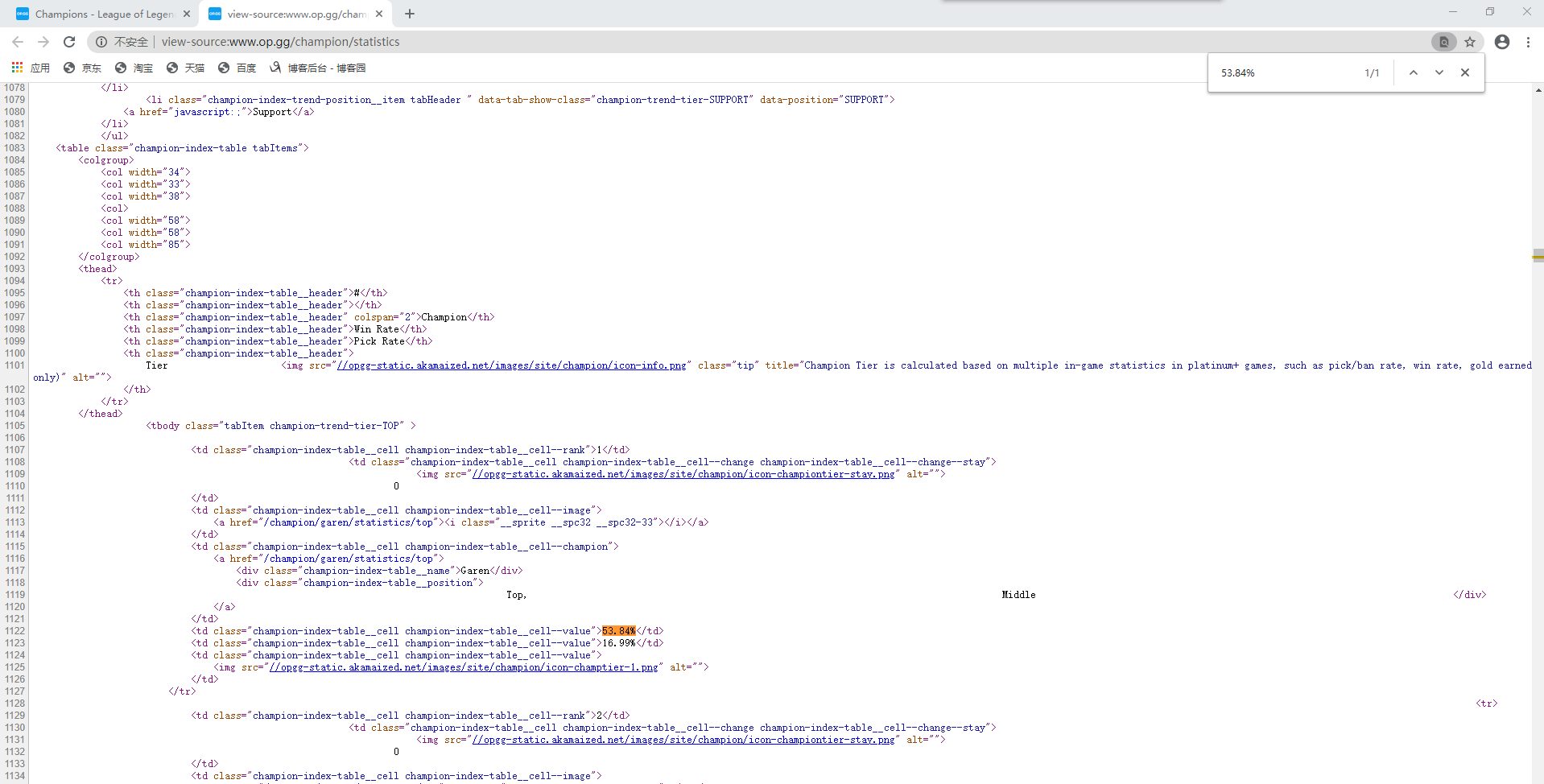
由代码可看出,英雄名、胜率及选取率都在td标签中,而每一个英雄信息在一个tr标签中,td父标签为tr标签,tr父标签为tbody标签。
对tbody标签进行查找

代码中共有5个tbody标签(tbody标签开头结尾均有”tbody”,故共有10个”tbody”),对字段内容分析,分别为上单、打野、中单、ADC、辅助信息
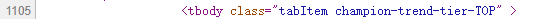

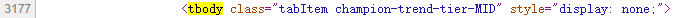

以上单这部分英雄为例,我们需要首先找到tbody标签,然后从中找到tr标签(每一条tr标签就是一个英雄的信息),再从子标签td标签中获取英雄的详细信息
二、爬取步骤
爬取网站内容->提取所需信息->输出英雄数据
getHTMLText(url)->fillHeroInformation(hlist,html)->printHeroInformation(hlist)
getHTMLText(url)函数是返回url链接中的html内容
fillHeroInformation(hlist,html)函数是将html中所需信息提取出存入hlist列表中
printHeroInformation(hlist)函数是输出hlist列表中的英雄信息
三、代码实现
1、getHTMLText(url)函数
def getHTMLText(url): #返回html文档信息
try:
r = requests.get(url,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text #返回html内容
except:
return ""
2、fillHeroInformation(hlist,html)函数

以一个tr标签为例,tr标签内有7个td标签,第4个td标签内属性值为"champion-index-table__name"的div标签内容为英雄名,第5个td标签内容为胜率,第6个td标签内容为选取率,将这些信息存入hlist列表中
def fillHeroInformation(hlist,html): #将英雄信息存入hlist列表
soup = BeautifulSoup(html,"html.parser")
for tr in soup.find(name = "tbody",attrs = "tabItem champion-trend-tier-TOP").children: #遍历上单tbody标签的儿子标签
if isinstance(tr,bs4.element.Tag): #判断tr是否为标签类型,去除空行
tds = tr('td') #查找tr标签下的td标签
heroName = tds[3].find(attrs = "champion-index-table__name").string #英雄名
winRate = tds[4].string #胜率
pickRate = tds[5].string #选取率
hlist.append([heroName,winRate,pickRate]) #将英雄信息添加到hlist列表中
3、printHeroInformation(hlist)函数
def printHeroInformation(hlist): #输出hlist列表信息
print("{:^20}\t{:^20}\t{:^20}\t{:^20}".format("英雄名","胜率","选取率","位置"))
for i in range(len(hlist)):
i = hlist[i]
print("{:^20}\t{:^20}\t{:^20}\t{:^20}".format(i[0],i[1],i[2],"上单"))
4、main()函数
网站地址赋值给url,新建一个hlist列表,调用getHTMLText(url)函数获得html文档信息,使用fillHeroInformation(hlist,html)函数将英雄信息存入hlist列表,再使用printHeroInformation(hlist)函数输出信息
def main():
url = "http://www.op.gg/champion/statistics"
hlist = []
html = getHTMLText(url) #获得html文档信息
fillHeroInformation(hlist,html) #将英雄信息写入hlist列表
printHeroInformation(hlist) #输出信息
四、结果演示
1、网站界面信息
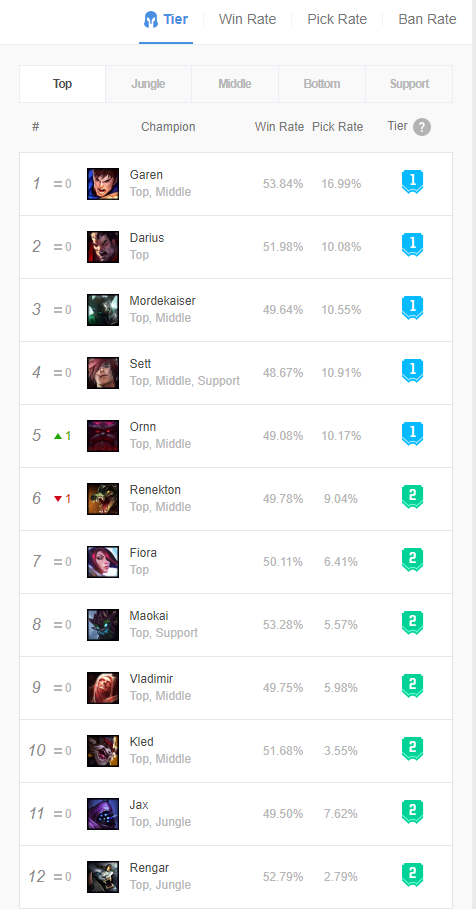
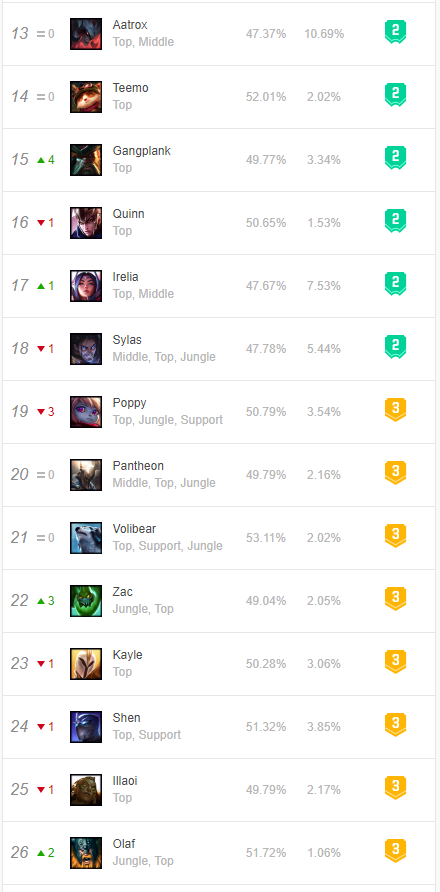

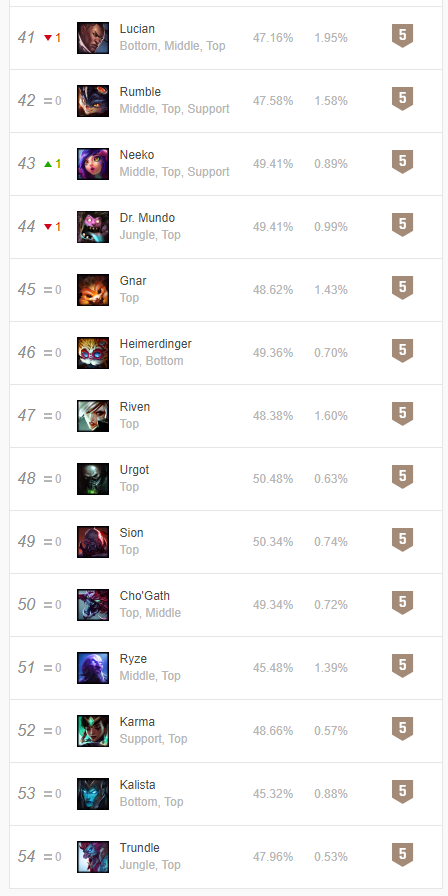
2、爬取结果

五、完整代码
import requests #导入requests库
import bs4 #导入bs4库
from bs4 import BeautifulSoup #导入BeautifulSoup库 def getHTMLText(url): #返回html文档信息
try:
r = requests.get(url,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text #返回html内容
except:
return "" def fillHeroInformation(hlist,html): #将英雄信息存入hlist列表
soup = BeautifulSoup(html,"html.parser")
for tr in soup.find(name = "tbody",attrs = "tabItem champion-trend-tier-TOP").children: #遍历上单tbody标签的儿子标签
if isinstance(tr,bs4.element.Tag): #判断tr是否为标签类型,去除空行
tds = tr('td') #查找tr标签下的td标签
heroName = tds[3].find(attrs = "champion-index-table__name").string #英雄名
winRate = tds[4].string #胜率
pickRate = tds[5].string #选取率
hlist.append([heroName,winRate,pickRate]) #将英雄信息添加到hlist列表中 def printHeroInformation(hlist): #输出hlist列表信息
print("{:^20}\t{:^20}\t{:^20}\t{:^20}".format("英雄名","胜率","选取率","位置"))
for i in range(len(hlist)):
i = hlist[i]
print("{:^20}\t{:^20}\t{:^20}\t{:^20}".format(i[0],i[1],i[2],"上单")) def main():
url = "http://www.op.gg/champion/statistics"
hlist = []
html = getHTMLText(url) #获得html文档信息
fillHeroInformation(hlist,html) #将英雄信息写入hlist列表
printHeroInformation(hlist) #输出信息 main()
如果需要爬取打野、中单、ADC或者辅助信息,只需要修改
fillHeroInformation(hlist,html)函数中的
for tr in soup.find(name = "tbody",attrs = "tabItem champion-trend-tier-TOP").children语句,将attrs属性值修改为
"tabItem champion-trend-tier-JUNGLE"、"tabItem champion-trend-tier-MID"、"tabItem champion-trend-tier-ADC"、"tabItem champion-trend-tier-SUPPORT"等即可
转载请声明原作者并附上原文链接!
利用Python爬取OPGG上英雄联盟英雄胜率及选取率信息的更多相关文章
- 利用python爬取58同城简历数据
利用python爬取58同城简历数据 利用python爬取58同城简历数据 最近接到一个工作,需要获取58同城上面的简历信息(http://gz.58.com/qzyewu/).最开始想到是用pyth ...
- 利用python爬取城市公交站点
利用python爬取城市公交站点 页面分析 https://guiyang.8684.cn/line1 爬虫 我们利用requests请求,利用BeautifulSoup来解析,获取我们的站点数据.得 ...
- 使用python爬取MedSci上的期刊信息
使用python爬取medsci上的期刊信息,通过设定条件,然后获取相应的期刊的的影响因子排名,期刊名称,英文全称和影响因子.主要过程如下: 首先,通过分析网站http://www.medsci.cn ...
- 没有内涵段子可以刷了,利用Python爬取段友之家贴吧图片和小视频(含源码)
由于最新的视频整顿风波,内涵段子APP被迫关闭,广大段友无家可归,但是最近发现了一个"段友"的app,版本更新也挺快,正在号召广大段友回家,如下图,有兴趣的可以下载看看(ps:我不 ...
- 利用Python爬取豆瓣电影
目标:使用Python爬取豆瓣电影并保存MongoDB数据库中 我们先来看一下通过浏览器的方式来筛选某些特定的电影: 我们把URL来复制出来分析分析: https://movie.douban.com ...
- 利用Python爬取朋友圈数据,爬到你开始怀疑人生
人生最难的事是自我认知,用Python爬取朋友圈数据,让我们重新审视自己,审视我们周围的圈子. 文:朱元禄(@数据分析-jacky) 哲学的两大问题:1.我是谁?2.我们从哪里来? 本文 jacky试 ...
- steam夏日促销悄然开始,用Python爬取排行榜上的游戏打折信息
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 不知不觉,一年一度如火如荼的steam夏日促销悄然开始了.每年通过大大小小 ...
- 利用python爬取王者荣耀英雄皮肤图片
前两天看到同学用python爬下来LOL的皮肤图片,感觉挺有趣的,我也想试试,于是决定来爬一爬王者荣耀的英雄和皮肤图片. 首先,我们找到王者的官网http://pvp.qq.com/web201605 ...
- Python爬取网站上面的数据很简单,但是如何爬取APP上面的数据呢
随机推荐
- [Windows] Access SMBIOS
SMBIOS architecture System Management BIOS (SMBIOS) is the premier standard for delivering managemen ...
- windows下面 apache 虚拟主机配置
<VirtualHost > ServerAdmin www.test2.com DocumentRoot "D:/PHP/Apache/htdocs/testSite2&quo ...
- 启动Tomcat报WEB-INF\lib\j2ee.jar jar not loaded异常的解决办法
今天加载工程时突然发现Tomcat报: 2010-7-1 12:11:38 org.apache.catalina.loader.WebappClassLoader validateJarFile 信 ...
- 【阅读笔记】rocketmq 概念与架构 (一)
介绍 rocketmq 框架与基本概念 1. 概念 1.1 namesrv(name server) 记录了 broker 集群信息,消息队列的信息以及 key-value 配置,见 RouteInf ...
- get请求直接通过浏览器发请求传数组或者list到后台
原文链接: http://blog.csdn.net/qq_27093465/article/details/76160419 感谢原作者 例如: http://localhost:27001/tes ...
- 谈谈Spring的IoC之注解扫描
问题 IoC是Inversion of Control的缩写,翻译过来即"控制反转".IoC可以说是Spring的灵魂,想要读懂Spring,必先读懂IoC.不过有时候硬着头皮 ...
- Contour等高线图代码
import matplotlib.pyplot as plt import numpy as np def f(x,y): # the height function return (1 - x / ...
- 烧钱时代终结!O2O还能玩啥花样?
最终的最终,饱受亏损.烧钱玩补贴等争议的美团还是追随滴滴/快的.赶集/58的步伐,与大众点评愉快的在一起了!美团和大众点评作为O2O行业的领军企业,都因为不堪忍受持续地投入却不见回报的模式而不得不放低 ...
- 用java实现的微信公众号爬虫
Published: 2016-11-23 In Spider. tags: Spider 版权声明:本文为博主原创文章,未经博主允许不得转载. 思路: 直接从chuansong.me爬取,由于微信公 ...
- 安卓权威编程指南 挑战练习 13.8 用于RecyclerView的空视图
当前,CriminalIntent应用启动后,会显示一个空白列表.从用户体验上来讲,即使crime列表 是空的,也应展示提示或解释类信息. 请设置空视图展示类似“没有crime记录可以显示”的信息.再 ...