cs231n spring 2017 lecture13 Generative Models
1. 非监督学习
监督学习有数据有标签,目的是学习数据和标签之间的映射关系。而无监督学习只有数据,没有标签,目的是学习数据额隐藏结构。
2. 生成模型(Generative Models)
已知训练数据,根据训练数据的分布(distribution)生成新的样例。
无监督学习中的一个核心问题是估计分布。
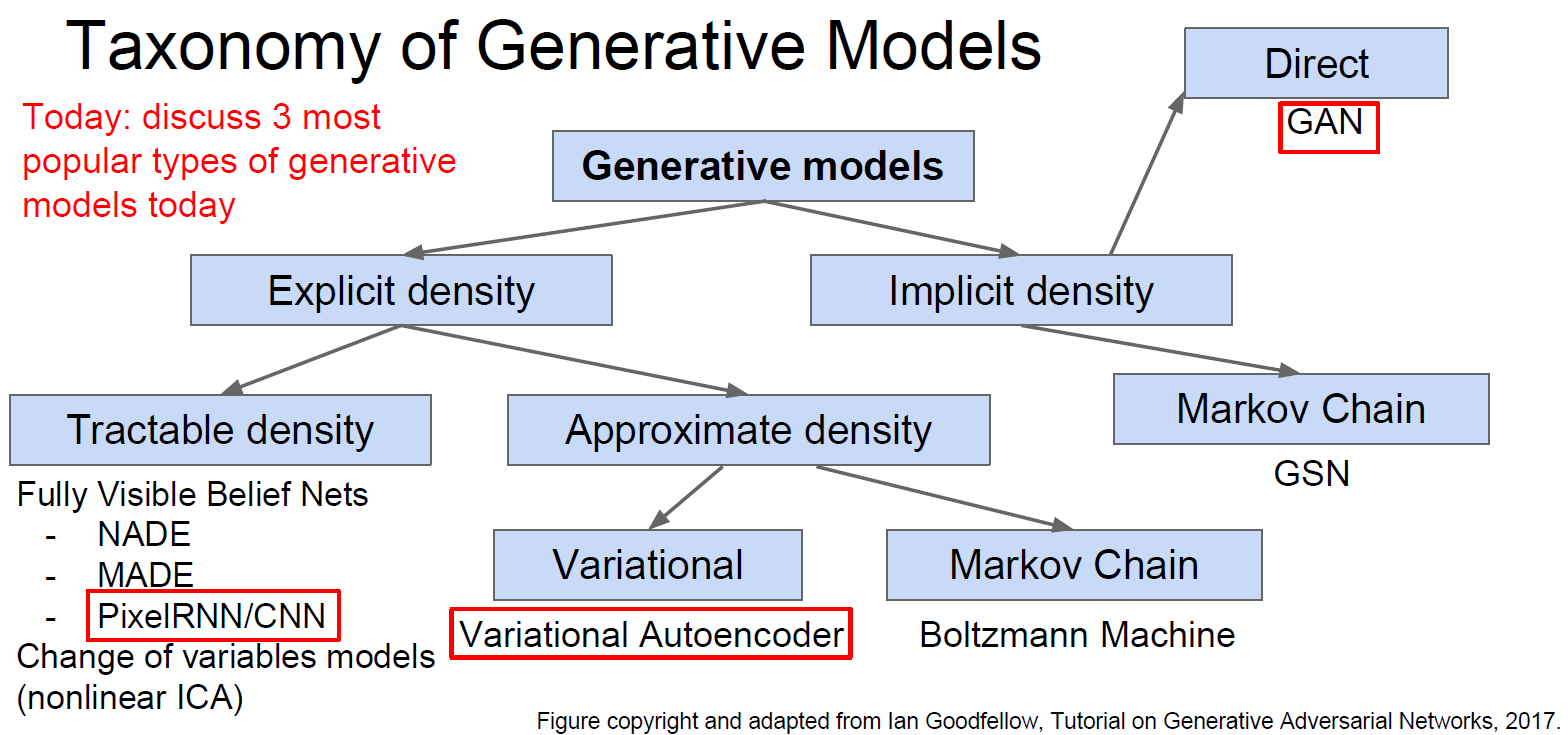
3. PixelRNN 和 PixelCNN
依次根据已知的像素估计下一个像素。

PixelRNN(van der Oord et al. NIPS 2016):利用RNN(LSTM)从角落开始依次生成像素。缺点是非常慢。

PixelCNN(van der Oord et al. NIPS 2016):利用CNN从角落开始依次生成像素。求像素的最大似然估计。比PixelRNN快,但依旧慢。
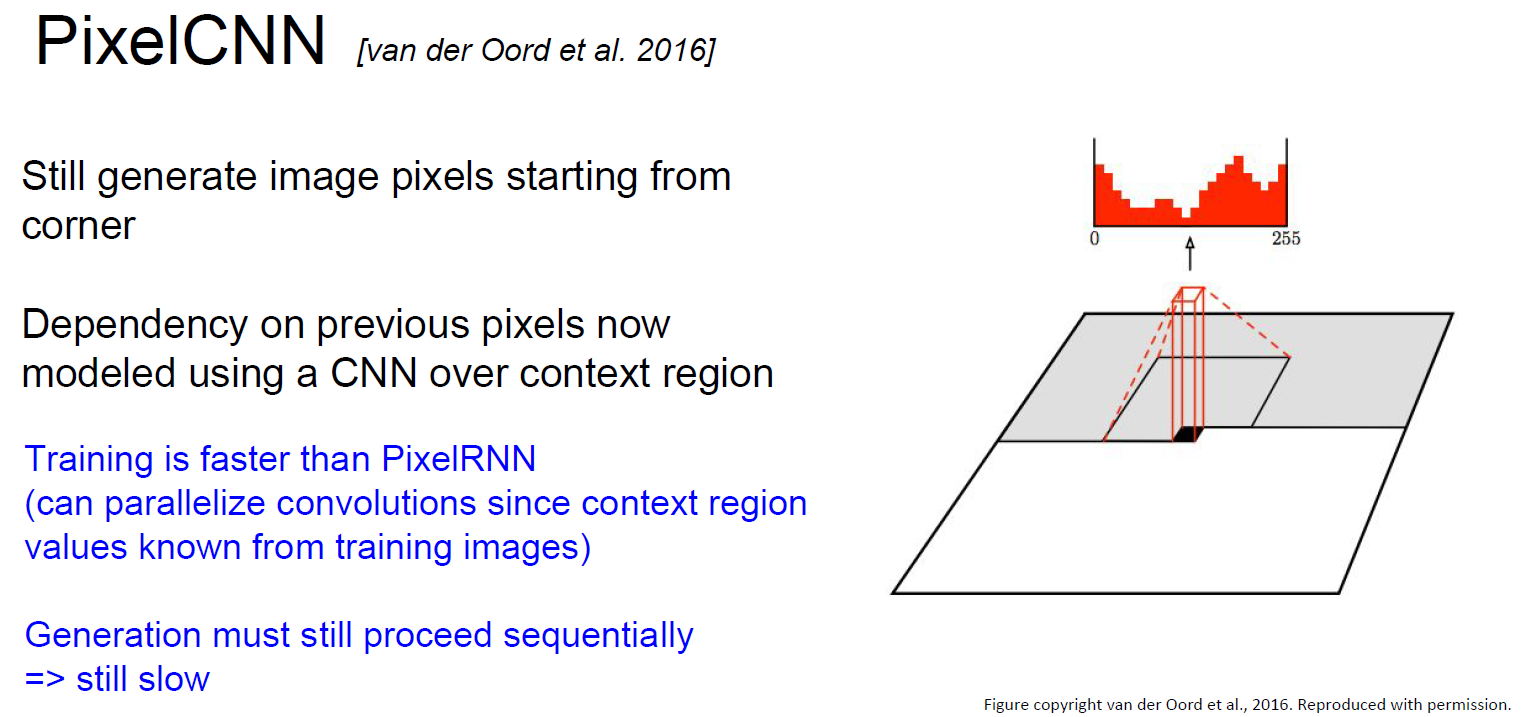
PixelRNN和PixelCNN的优点是可以显式地求出概率分布,并且给出评价尺度(evaluation metric),生成的结果也不错。缺点是慢。改进版本是PixelCNN++(Salimans et al. 2017)。
4. Variational Autoencoders (VAE)
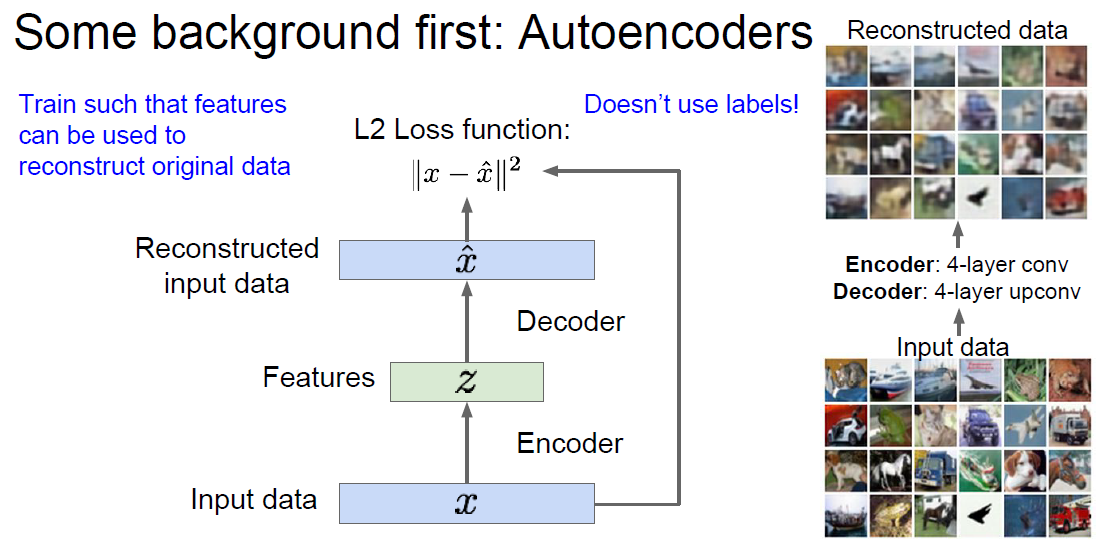
Autoencoder是一种从没有标签的训练数据学习低维度特征(lower-dimensional feature representation)的方法。最开始是用Linear+nonlinearity(sigmoid)的方法,后来人们用深度的全连接层,再后来人们用ReLU CNN。为什么要“低维度特征”?或者说为什么把输入的维度降低?目的是为了获得可靠的、不变的特征。
第一种用法是和监督学习配合使用。在训练阶段,可以再用一个Decoder把低维度特征解码成和输入类似的数据。这样可以建立损失函数。训练完成之后可以把Decoder扔掉,把Encoder出的特征当成某个监督学习的输入,预测出结果,建立Loss function。在有大量没有标签的训练数据和少量有标签的数据的情况下,这样做很有效。图中的 z 叫 “latent factors”。
第二种用法是生成新的数据。对于编码出的 z(“latent factors” )的分布 p(z),可以直接选择简单的概率分布,比如高斯。而对于条件概率 p(x|z),则是比较复杂的,用神经网络来模拟。训练的过程如下图所示,(推导过程完全没听懂。。。)。训练完了之后可以只用Decoder network,渐进地改变z的各个分量(比如z1表示微笑的程度,z2表示头的姿态,则可以生成各种头的姿态各种微笑程度的人脸),生成不同的样例x_hat。
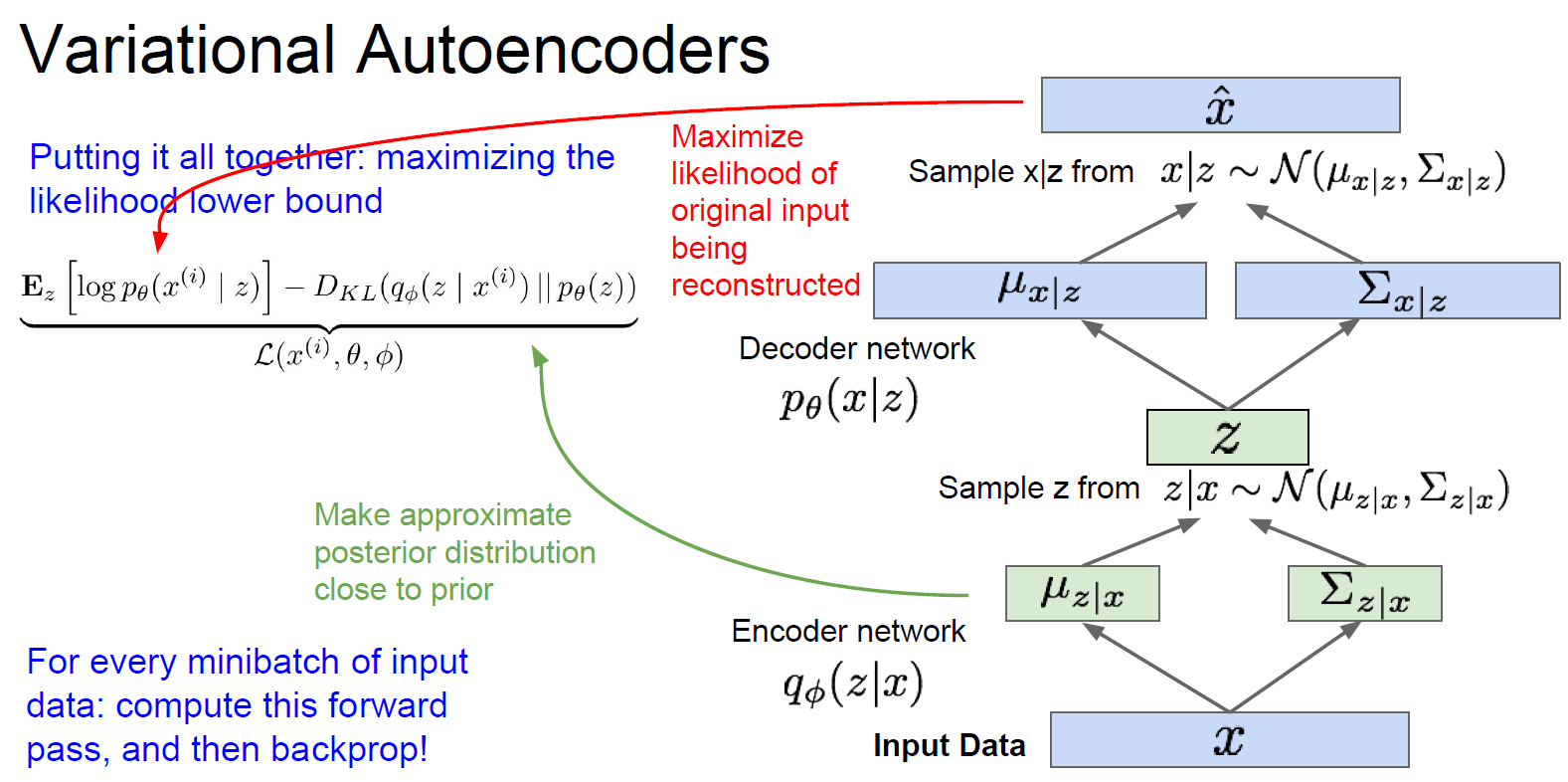
Variational Autoencoders的优点:生成模型的主要方法(principled approach);可以估计q(z|x)(没搞明白这里q是什么。。。),对于其他任务可能是很好的特征描述。缺点:最大化似然估计的下限,而不是直接最大化似然估计,从评估的角度说不如PixelRNN和PixelCNN;相比于GAN,生成的图片比较模糊,质量不高。
5. Generative Adversarial Networks (GAN) (Ian Goodfellow et al., "Generative Adersarial Nets", NIPS 2014)
不考虑显式地描述density function,而是根据对抗直接生成样例。我们没有办法直接从复杂的、高维度的训练集分布中生成样例,那么就先从简单的分布生成样例(比如随机噪音),然后从训练集分布学习把这个简单分布生成的样例转变成(transformation)符合训练集分布。神经网络就是用来描述这个复杂的transformation(神经网络的作用似乎一直就是用来描述高维度、非线性的某种函数、映射、转换等等)。该神经网络的输入是随机噪声,输出是符合训练集分布的样例。
GAN有两个网络,生成网络(generator network)和区分网络(discriminator network),生成网络尽一切努力生成图片欺骗区分网络,区分网络尽一切努力区分原图和生成的图。

具体的训练过程是先优化区分网络k次迭代,再优化生成网络一次迭代,然后不断重复。

训练完成之后,可以丢掉区分网络,只用生成网络来生成样例。
改进方案如下:

2017年是GAN的爆发年,出了成吨的相关研究。生成的样例越来越好。
GAN的优点:效果非常好。缺点:训练的过程不稳定,很需要经验和技巧;不能给出对得density function的估计。
6. 总结:生成模型的对比
PixelRNN和PixelCNN:显式的density model,优化似然函数,效果不错,低效、慢。
Variational autoencoders (VAE):优化似然函数的下限,latent representation很有用,inference queries,生成的图片的质量不够好。
Generative Adversarial Network (GANs):博弈的原理,生成的图片的质量超级好,难训练,no inference queries。
cs231n spring 2017 lecture13 Generative Models的更多相关文章
- cs231n spring 2017 lecture13 Generative Models 听课笔记
1. 非监督学习 监督学习有数据有标签,目的是学习数据和标签之间的映射关系.而无监督学习只有数据,没有标签,目的是学习数据额隐藏结构. 2. 生成模型(Generative Models) 已知训练数 ...
- cs231n spring 2017 lecture11 Detection and Segmentation 听课笔记
1. Semantic Segmentation 把每个像素分类到某个语义. 为了减少运算量,会先降采样再升采样.降采样一般用池化层,升采样有各种"Unpooling"." ...
- cs231n spring 2017 lecture9 CNN Architectures 听课笔记
参考<deeplearning.ai 卷积神经网络 Week 2 听课笔记>. 1. AlexNet(Krizhevsky et al. 2012),8层网络. 学会计算每一层的输出的sh ...
- cs231n spring 2017 lecture7 Training Neural Networks II 听课笔记
1. 优化: 1.1 随机梯度下降法(Stochasitc Gradient Decent, SGD)的问题: 1)对于condition number(Hessian矩阵最大和最小的奇异值的比值)很 ...
- cs231n spring 2017 Python/Numpy基础 (1)
本文使根据CS231n的讲义整理而成(http://cs231n.github.io/python-numpy-tutorial/),以下内容基于Python3. 1. 基本数据类型:可以用 prin ...
- cs231n spring 2017 lecture11 Detection and Segmentation
1. Semantic Segmentation 把每个像素分类到某个语义. 为了减少运算量,会先降采样再升采样.降采样一般用池化层,升采样有各种“Unpooling”.“Transpose Conv ...
- cs231n spring 2017 lecture9 CNN Architectures
参考<deeplearning.ai 卷积神经网络 Week 2 听课笔记>. 1. AlexNet(Krizhevsky et al. 2012),8层网络. 学会计算每一层的输出的sh ...
- cs231n spring 2017 lecture7 Training Neural Networks II
1. 优化: 1.1 随机梯度下降法(Stochasitc Gradient Decent, SGD)的问题: 1)对于condition number(Hessian矩阵最大和最小的奇异值的比值)很 ...
- cs231n spring 2017 Python/Numpy基础
本文使根据CS231n的讲义整理而成(http://cs231n.github.io/python-numpy-tutorial/),以下内容基于Python3. 1. 基本数据类型:可以用 prin ...
随机推荐
- iris数据集预测
iris数据集预测(对比随机森林和逻辑回归算法) 随机森林 library(randomForest) #挑选响应变量 index <- subset(iris,Species != " ...
- centos挂载磁盘
Aliyun实例为例 简单操作: 查看磁盘情况:fdisk -l 对数据盘进行分区,一般类似/dev/vdb这种为数据盘 输入fdisk /dev/vdb 对数据盘进行分区.根据提示,输入 n, p ...
- 干货分享,FPGA硬件系统的设计技巧
PGA的硬件设计不同于DSP和ARM系统,比较灵活和自由.只要设计好专用管脚的电路,通用I/O的连接可以自己定义.因此,FPGA的电路设计中会有一些特殊的技巧可以参考. 1. FPGA管脚兼容性设计 ...
- goweb-模板引擎
模板引擎 Go 为我们提供了 text/template 库和 html/template 库这两个模板引擎,模板引 擎通过将数据和模板组合在一起生成最终的 HTML,而处理器负责调用模板引擎并将引 ...
- 深入理解JVM - 垃圾收集器
垃圾回收主要是要解决3件事情: 那些内存需要回收? 如何回收? 什么时候回收? 那些内存需要回收 在强引用的情况下已经“死”了的对象就需要回收,在非强引用的情况下视情况回收.在java里面,几乎所有的 ...
- 记录华为、魅族手机无法打印 Log 日志的问题
http://yifeng.studio/2017/02/26/android-meizu-huawei-not-log/ 实测 MEIZU PRO 6 :打开[设置]中的[开发者选项],页面底部找到 ...
- PAT Advanced 1127 ZigZagging on a Tree (30) [中序后序建树,层序遍历]
题目 Suppose that all the keys in a binary tree are distinct positive integers. A unique binary tree c ...
- CSP模拟赛2游记
这次由于有课迟到30min,了所以只考了70min. 调linux配置调了5min,只剩下65min了. T1:有点像标题统计,但要比他坑一点,而且我就被坑了,写了一个for(int i=1;i< ...
- hdu2896&&3065
题:http://acm.hdu.edu.cn/showproblem.php?pid=2896 分析:ac自动机模板 注意细节,1.128个ascii码都要: 2.只要关键码含有只输出一个编号就行 ...
- Win10控制桌面图标显示
1.桌面鼠标右键,进入个性化 2.进入主题: 3.