“造轮运动”之 ORM框架系列(二)~ 说说我心目中的ORM框架
ORM概念解析
首先梳理一下ORM的概念,ORM的全拼是Object Relation Mapping (对象关系映射),其中Object就是面向对象语言中的对象,本文使用的是c#语言,所以就是.net对象;Relation Mapping则是关系映射,在数据库的系统中指的就是.net对象与数据库表之间的关系映射。
为什么.net对象与数据库表之间要进行关系映射呢?
答案当然是显而易见的,因为数据库表的结构与对象的结构非常的相似,如果将两者之间建立起映射关系,我们就可以很容易地在面向对象语言中像操作普通对象一样去进行数据库表的操作,那对程序员来说简直就是福音。那么这两者之间的关系由谁来建立呢,毕竟不能让它俩凭空去产生关系,当中要有“媒人”撮合,这个“媒人”就叫做ORM框架,也可以叫做数据库持久层框架。
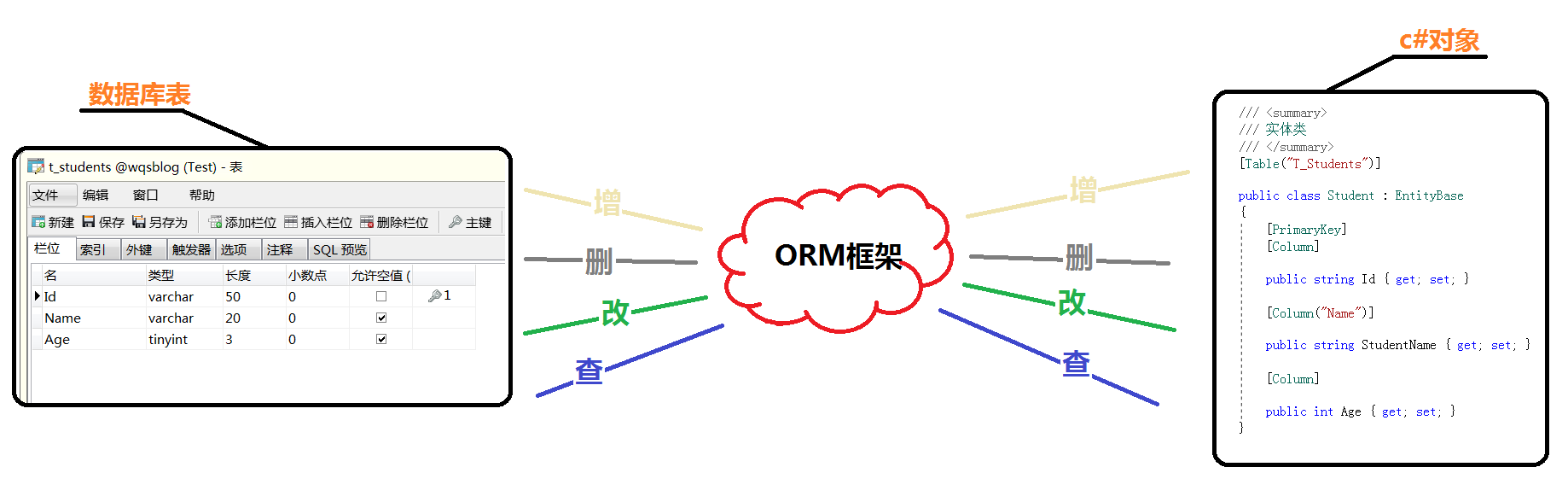
在上一篇 “造轮运动”之 ORM框架系列(一)~谈谈我在实际业务中的增删改查 中,谈了一下我遇到的增删改查,并分析了原生sql、Lambda to sql、存储过程等方式的利弊,在这其中我也慢慢地形成了自己对ORM框架的认识,也逐渐绘制出了一幅我心目中完美的ORM框架蓝图。
描绘蓝图之前先给我的ORM框架取个名字,叫做CoffeeSQL,这个名字的由来是因为我希望自己用了这个框架以后可以给我节省出工作中能享受一杯Coffee的时间~
1、实体映射
c#的对象想要与数据库表建立映射关系,那就要记录映射关系的配置信息,我更喜欢采用一种一目了然的方式来进行配置:直接在类的字段上标识Attribute。
基本使用方式如下代码所示:
/// <summary>
/// 实体类
/// </summary>
[Table("T_Students")]
public class Student : EntityBase
{
[PrimaryKey]
[Column]
public string Id { get; set; } [Column("Name")]
public string StudentName { get; set; } [Column]
public int Age { get; set; }
}
我们可以看到在这个实体类中我们使用了三个Attribute,分别为 TableAttribute(标识映射表)、 PrimaryKeyAttribute(标识主键)、CloumnAttribute(标识数据列),相信这些都很好理解。
2、lambda操作,增删改查,强类型
在一些最基础的信息增删改查功能中,对于单表的sql操作是非常频繁的,我建议使用lambda的形式操作,第一是因为方便,第二是因为单表操作Lambda TO SQL转化后的sql是最简便的,所以不用担心它的性能。
具体的代码操作如下:
1)增
//Add
dbContext.Add<Student>(new Student { Id = newId, StudentName = "王二", Age = });
2)删
//delete
dbContext.Delete<Student>(s => s.Id.Equals(newId));
3)改
//update
dbContext.Update<Student>(s => new { s.StudentName }, new Student { StudentName = name }) //更新字段
.Where(s => s.Id.Equals(newId)) //where条件
.Done();
4)查
//select
dbContext.Queryable<Student>()
.Select(s => new { s.StudentName, s.Id }) //字段查询
.Where(s => s.Age > && s.StudentName.Equals(name)) //where条件
.Paging(, ) //分页查询
.ToList();
3、原生sql操作,弱类型,非实体类字段的存储的方式 => 索引器
上面介绍的lambda表达式的操作方式只适用于单表的查询,如果需要进行联多表查询或者需要进行更复杂的查询,那么我更倾向于进行原生sql的查询。当然,原生sql的查询也提供结果映射到对象的功能,类似于Dapper的用法。
具体操作如下:
//原生sql查询用法
string complexSQL = "select xxx from t_xxx A,t_yyy B where xx = {0} and yy = {1}";
object[] sqlParams = new Object[] { DateTime.Now, };
var resList = dbContext.Queryable(complexSQL, sqlParams).ToList<Student>();
对上面的代码稍微进行一下解释,complexSQL 中的 {0} 和 {1} 是参数化查询参数的占位符,在原生sql的查询用法中你可以使用任意c#的基本变量去填充占位符,最终获得sql参数化查询的效果,用法非常方便。
当然你可能会困惑:假如我查询的结果中包含了不是Student对象中字段的值怎么办?
答案是,你可以用索引的方式将非Student对象中字段的值取出,下面做一个示范,假如你希望查出 xxx 字段,你可以这样做:
Student resList1 = resList[];
var segmentValue = (string)resList1["xxx"]; //查询结果中的任何字段值都可以以索引的方式查出,记得转换为字段的实际类型
是不是So Easy!
4、更复杂的sql逻辑,那得用存储过程
制造生产类的企业的业务逻辑离不开流程加表单,表单的查询与数据写入就是属于比较复杂的sql了。
但是这其实还不算什么,更复杂的是,由于现在流行的大数据概念,车间的主管们往往也想沾沾边,所以会在车间的大屏上展现各种数据统计的看板,这其中就涉及到巨多表的查询逻辑。曾经开发过一个看板功能,特地数了一下,单单一条sql就接近200行的代码量,一点都不夸张。像这种逻辑很复杂的查询,还可能涉及到依据不同条件执行不同sql的场景,我当然不会在高级语言中拼接原生sql了,因为那样容易把自己搞晕哦。这个时候就要祭出最后的大杀技——存储过程。
在CoffeeSQL中你可以这样使用存储过程:
using (ShowYouDbContext dbContext = new ShowYouDbContext())
{
string strsp = "xxx_storeprocedureName"; OracleParameter[] paras = new OracleParameter[]
{
new OracleParameter("V_DATE",OracleDbType.Varchar2,),
new OracleParameter("V_SITE",OracleDbType.Varchar2,),
new OracleParameter("V_SCREEN",OracleDbType.Varchar2,),
new OracleParameter("V_SHIFT",OracleDbType.Varchar2,),
new OracleParameter("V_CURSOR",OracleDbType.RefCursor)
}; paras[].Value = info.date;
paras[].Value = info.site;
paras[].Value = info.screenKey;
paras[].Value = info.shift;
paras[].Direction = ParameterDirection.Output;
DataSet ds = dbContext.StoredProcedureQueryable(strsp, paras).ToDataSet(); return ds;
}
这里的用法并没有做什么包装,值得一提的就是可以将查询结果转换为对象。当然,这是贯穿整个ORM框架的一大主要功能,无处不在。
5、数据库连接管理,一主多从
现如今大多数的数据库都不是单一部署的,比较流行的数据库部署方式是“一主多从”的方式,即一台数据库作为写入数据的数据库(主库),其他多台数据库作为读取数据的数据库(从库)去同步主库的数据,从而实现了读写分离的功能,降低了主库的访问压力,大大提高了数据库的访问性能。当然,我们现在所讨论的这个ORM框架就理所当然地要支持这种“一主多从”的数据库部署方式的数据库操作。
具体“一主多从”的数据库连接配置方式如下:
public class ShowYouDbContext : OracleDbContext<ShowYouDbContext>
{
private static string writeConnStr = "xxxxxxx_1";
private static string[] readConnStrs = new string[] { "xxxxxxxxx_2",
"xxxxxxxxx_3",
"xxxxxxxxx_4",
"xxxxxxxxx_5",
"xxxxxxxxx_6"
}; public ShowYouDbContext() : base(writeConnStr, readConnStrs)
{
}
}
对DBContext类对象进行构造时将数据库连接字符串当做构造参数传入即可,第一条为主库(写数据库)连接字符串,以后的都为从库(读数据库)连接字符串。
6、实体数据验证,作为数据格式规范的防线
实体数据验证的概念很好理解:一个数据表中的每一个字段都有其长度、大小等限制,那么每一个与数据表对应的实体也应当有相应的字段约束来作为数据格式规范的防线,让持久化到数据表中的数据符合其所规定的的格式,也就相当于货物在进入仓库前做一个安全检查。
我们可以像这样去配置一个实体类的数据验证规则:
[Table("B_DICTIONARY")]
public class Dictionary : EntityCommon
{
[Length(,)]
[Column]
public string Name { get; set; }
[Column]
public string Value { get; set; }
[Column]
public string Type { get; set; }
}
这个实体类中的Name字段就标识了一个LengthAttribute标签,规定了该字段的长度范围为1~50,如果不符合则会抛出异常。当然,实体数据的验证规则不止这一条,后期会根据需求再进行添加,或者用户可以根据自己的需求进行扩展。
7、事务的操作形式,个人习惯,喜欢把transaction明确写出来,不喜欢过度封装
事务是数据库系统中的重要概念,事务的特性是ACID(原子性、一致性、隔离性、持久性),当然这里不会去讨论事务的概念,我要展示的是在CoffeeSql中如何使用事务:
try
{
dbContext.DBTransaction.Begin(); dbContext.Update<Machine_Match_Relation>(d => new { d.Del_Flag }, new Machine_Match_Relation { Del_Flag = })
.Where(d => d.Screen_Machine_Id.Equals(displayDeviceId)).Done(); foreach(string bindDeviceId in bindDeviceIds)
{
dbContext.Add(new Machine_Match_Relation
{
Id = Utils.GetGuidStr(),
Screen_Machine_Id = displayDeviceId,
Machine_Id = bindDeviceId,
Creater = updater
});
} dbContext.DBTransaction.Commit();
}
catch(Exception ex)
{
dbContext.DBTransaction.Rollback();
throw ex;
}
有人会说为什么这里不封装一个方法,只要传入业务操作代码的委托Action就行了,当然可以,但是说实在的,真没必要,如果你喜欢就自己封装去吧。
8、可适配扩展多款不同的数据库
作为一个能跟的上潮流的ORM,当然得具备适配多种数据库的特性了,Oracle、Mysql、SqlServer等等数据库,想怎么适配就怎么适配。
//Mysql
public class WQSDbContext : MysqlDbContext<WQSDbContext>
{
public WQSDbContext() : base(mysqlConnStr)
{
this.OpenQueryCache = false;
this.Log = context =>
{
Console.WriteLine($"sql:{context.SqlStatement}");
Console.WriteLine($"time:{DateTime.Now}");
};
}
} //Oracle
public class WQSDbContext : OracleDbContext<WQSDbContext>
{
public WQSDbContext() : base(oracleConnStr)
{
this.OpenQueryCache = false;
this.Log = context =>
{
Console.WriteLine($"sql:{context.SqlStatement}");
Console.WriteLine($"time:{DateTime.Now}");
};
}
}
目前CoffeeSQL实现了两种数据库的扩展,Oracle与Mysql。当然,如果你还想适配更多的数据库的话,你也可以尝试扩展,只不过我目前用到的这两种数据库。
9、缓存功能,提高性能
还记得当初一次校招的面试,面试官问我:“你觉得ORM的速度快还是Ado.net的速度快?”
我傻傻地脱口而出:“那当然是Ado.net更快了,相比于ORM,它少了linq语句到sql的转换步骤,而且ORM还比直接使用Ado.net多了查询结果映射到对象的步骤。”
看面像和发量就知道这个面试官 心(老)地(奸)善(巨)良(滑),他和我对视了3秒,然后说:
“好,今天就到这,回去等通知吧!”
等通知的后果那也就显而易见了......

直到后来我深入地了解了ORM框架的原理才知道,那个问题并不是我回答的一句话那么简单,因为我忽略了ORM缓存。

CoffeeSql中也会有ORM缓存,ORM的缓存分为表缓存(二级缓存)与sql语句缓存(一级缓存):表缓存一般用于数据量较小且经常会进行查询操作的表,会将整个表的数据缓存到缓存介质中;sql语句缓存可以适用各种类型的表,它是以sql查询语句作为缓存键的。
当然,你如果并不想要知道太多其中的细节,在使用时你只需要像这样简单的配置:
(ORM缓存开关)
public class WQSDbContext : OracleDbContext<WQSDbContext>
{
public WQSDbContext() : base(oracleConnStr)
{
this.OpenTableCache = true;
this.OpenQueryCache = true;
}
}
(表缓存的实体配置)
[TableCaching]
[Table("B_DICTIONARY")]
public class Dictionary : EntityCommon
{
[Column]
public string Name { get; set; }
[Column]
public string Value { get; set; }
[Column]
public string Type { get; set; }
}
如果在实体类上标记TableCachingAttribute而且打开了表缓存,那么就会对当前的数据表进行全表数据的缓存。
要注意,表缓存一般只用在小数据量且查询频繁的表中。因为表缓存功能启用后会事先去将全表的数据扫描然后存储到本地缓存,直接在缓存中进行表数据的查询操作,所以如果你将那种数据量很大且查询并不是很频繁的表开启了表缓存,那你可以想象一下这个肯定会是一个得不偿失的行为。
以上的代码操作是我当初对CoffeeSQL的预想,当然,现在都成为了现实。以上的内容实际上就相当于CoffeeSQL的操作手册,因为上面的代码完全是按照实际的CoffeeSQL的框架操作来进行展示的。
有关于CoffeeSQL更详细的使用细节我会在源码的测试代码中给出,观众们可以移步去看源码:
https://gitee.com/xiaosen123/CoffeeSqlORM
本文为作者原创,转载请注明出处:https://www.cnblogs.com/MaMaNongNong/p/12896757.html
“造轮运动”之 ORM框架系列(二)~ 说说我心目中的ORM框架的更多相关文章
- “造轮运动”之 ORM框架系列(一)~谈谈我在实际业务中的增删改查
想想毕业已经快一年了,也就是大约两年以前,怀着满腔的热血正式跨入程序员的世界,那时候的自己想象着所热爱的技术生涯会是多么的丰富多彩,每天可以与大佬们坐在一起讨论解决各种牛逼的技术问题,喝着咖啡,翘着二 ...
- log4net保存到数据库系列二:独立配置文件中配置log4net
园子里面有很多关于log4net保存到数据库的帖子,但是要动手操作还是比较不易,从头开始学习log4net数据库日志一.WebConfig中配置log4net 一.WebConfig中配置log4ne ...
- Windows下USB磁盘开发系列二:枚举系统中所有USB设备
上篇 <Windows下USB磁盘开发系列一:枚举系统中U盘的盘符>介绍了很简单的获取系统U盘盘符的办法,现在介绍下如何枚举系统中所有USB设备(不光是U盘). 主要调用的API如下: 1 ...
- “造轮运动”之 ORM框架系列(三)~ 干货呈上
这一趴里面,我就来正式介绍一下CoffeeSQL的干货. 首先要给CoffeeSQL来个定位:最开始就是由于本人想要了解ORM框架内部的原理,所以就四处搜寻有关的博客与学习资料,就是在那个夏天 ...
- dubbo系列二、dubbo+zookeeper+dubboadmin分布式服务框架搭建(windows平台)
一.zookeeper配置中心安装 1.下载安装包,zookeeper-3.4.6.tar.gz 2.解压安装包,修改配置文件 参考zookeeper-3.4.6/conf/zoo_sample.cf ...
- Spring框架系列(二)--装配和注入Bean
企业日常开发中,几乎都是Spring系的框架,无论是SSM.还是现在大火的SpringBoot+JPA/MyBatis,使用最大的目的就是简化开发 基本模块: 核心容器:Beans.Core.Cont ...
- Quartz.NET开源作业调度框架系列(二):CronTrigger
CronTriggers比SimpleTrigger更加的灵活和有用,对于比较复杂的任务触发规则,例如"每个星期天的晚上12:00"进行备份任务,SimpleTrigger就不能胜 ...
- Quartz.NET开源作业调度框架系列(二):CronTrigger-转
CronTriggers比SimpleTrigger更加的灵活和有用,对于比较复杂的任务触发规则,例如"每个星期天的晚上12:00"进行备份任务,SimpleTrigger就不能胜 ...
- 二叉树系列 - 二叉搜索树 - [LeetCode] 中序遍历中利用 pre节点避免额外空间。题:Recover Binary Search Tree,Validate Binary Search Tree
二叉搜索树是常用的概念,它的定义如下: The left subtree of a node contains only nodes with keys less than the node's ke ...
随机推荐
- 201771010113 李婷华 《面向对象程序设计(Java)》第十一周总结
一.理论知识部分 第九章 集合 1.数据结构介绍: 线性结构:线性表,栈,队列,串,数组,文件.非线性结构:树,图. 散列表:又称为哈希表. 散列表算法的基本思想是:以结点的关键字为自变量,通过一定 ...
- STC8A8K64S4A12通过SPI接口操作基于ST7920的LCD12864液晶模块
文章地址:https://www.cnblogs.com/jqdy/p/12665430.html 1. 硬件连接 1.1 64引脚的STC8A8K64S4A12 使用的是最小核心板,所以引脚皆引出可 ...
- 测试开发专题:spring-boot统一异常捕获
java异常介绍 异常时相对于return的一种退出机制,可以由系统触发,也可由程序通过throw语句触发,异常可以通过try/catch语句进行捕获并处理,如果没有捕获,则会导致程序退出并输出异常栈 ...
- 【Hadoop离线基础总结】伪分布模式环境搭建
伪分布模式环境搭建 服务规划 适用于学习测试开发集群模式 步骤 第一步:停止单节点集群,删除/export/servers/hadoop-2.7.5/hadoopDatas,重新创建文件夹 停止单节点 ...
- asp.net mvc entityframework sql server 迁移至 mysql方法以及遇到的问题
背景: 我原来的项目是asp.net mvc5 + entityframework 6.4 for sql server(localdb,sql server),现在需要把数据库切换成mysql,理论 ...
- 如何在MATLAB下把模糊推理系统转化为查询表(转载)
如何在MATLAB下把模糊推理系统转化为查询表(原创) http://foundy.blog.163.com/blog/static/2633834420090212202156/?mode=edit ...
- iview input 禁止输入特殊字符 ,解决中文输入法中input把拼音输入
tips:解决了e.target中输入中文 会把拼音也输入的情况 1 html <FormItem label="角色名称" prop="roleName" ...
- java开发常见单词(复习整理)
开发中基本都能碰到,不止以下单词,后续会添加,javascript.html.mysql.spring.Linux中常用单词于此合并分类,特殊不常见不添加 访问修饰符4个--------------- ...
- MySQL 入门(5):复制
摘要 在这篇文章中,我将从MySQL为什么需要主从复制开始讲起,然后会提到MySQL复制的前提,bin log. 在这里会说明三种格式的bin log分别会有什么优缺点. 随后会讲到主从延迟方面的问题 ...
- nginx安装目录文件
nginx安装目录 conf 存放nginx的配置文件 在修改配置文件nginx.conf之前,一般先备份cp nginx.conf nginx.conf.bak html 存放前端文件的 默认带有首 ...